本文要点:
- 本文探讨了三个研究目标:测量推特用户采用匿名或假名的数量;测量在内容敏感性和用户匿名之间的相关性;以及确认是否有可能构建能够检测敏感推特账户的自动分类器。
- 为了测量推特用户匿名的流行程度, 他们从公开的 2010 年推特数据集中的 4170 万个账户中随机选取了 10 万个账户,并用 Amazon Mechanical Turk 进行标注。
- 为了评估内容敏感性和用户选择匿名的相关性,他们选择了若干广泛被认为敏感、有争议的主题类别。
- 研究人员在跨度为 5 年的不同时间点上使用了 3 个数据集。在所有的 3 个数据集中,不仅有匿名推特账户,还有跨越不同数据集而没有变化的匿名账户与敏感推特账户之间的关系。
_ _ 本文首先发表于《 IEEE Security & Privacy 》。对于如今的战略技术问题,《IEEE Security & Privacy》提供可靠的、同行评审的信息。为了迎接经营可靠、灵活企业的挑战,IT 管理人员和技术人员依靠 IT Pro 提供最先进的解决方案。
_ 本文首先发表于《 IEEE Security & Privacy 》。对于如今的战略技术问题,《IEEE Security & Privacy》提供可靠的、同行评审的信息。为了迎接经营可靠、灵活企业的挑战,IT 管理人员和技术人员依靠 IT Pro 提供最先进的解决方案。
互联网的急速膨胀引发出现了越来越多的在线社交网络和论坛。为了加入这些社交网络和论坛,用户一般必须创建一个账户并设立一个在线身份。各种社交网络和论坛通常在可接受的用户身份上有不同的要求。例如,脸书实施实名制,要求用户在创建账户时提供其真名。所述理由包括这样的政策会增强用户的责任感并提高了内容质量(有助于减少垃圾邮件、欺凌和黑客行为)。然而,倡导隐私人士声称实名制政策侵蚀了在线自由,因为这会把用户兴趣(通过其在线活动反映出来)和其名字联系在一起,从而生成一大堆信息。1
推特刚好相反,不要求用户提供真名,尽管其的确要求用户创建独特的假名。使用与真名无关的假名可以有效地让用户匿名(即对其他用户匿名,尽管没必要对服务供应商匿名)。不采用实名制政策使得推特成为流行的信息交换门户,用户们可以分享和获取信息而不会被识别。2,3
在线和离线匿名都已受到广泛的研究 4-6 。这里,我们特别关注在线社交网络中的匿名如何影响用户行为。我们对推特实施了大范围、数据驱动的分析,以确定用户匿名和其内容敏感性之间的相关性(如果要更多地了解我们使用的 3 个推特数据集,请参看原文的边栏)。我们也探讨了利用用户匿名模式帮助识别敏感内容的自动化系统的可行性。通过我们的工作,我们希望深入了解匿名在社会中的重要性和作用,以指导在现有及未来的在线社交网络中新隐私和匿名特征的开发,并在社交网络中发现潜在的敏感或有争议的话题。为了便于阅读,我们将在文中采用常用术语,而不是更隐晦的假名。
推特账户基本信息
每个推特账户包含 4 项主要信息:
- 用户提供详细个人信息的账户包括一个识别该账户的唯一混合了字母数字的 ID,这个称为显示名(screen name);一个名字字段,通常包含该用户的全名(姓氏 + 名字);一张个人资料照片;一个可以链接到另一个社交网络账户的地址。请注意,在账户中所提供的详细资料并不总是真实的,比如,姓名字段中可能名字是假的、姓氏是假的或两者都是假的。
- 用户发布的推文或消息列表。
- 朋友列表。当一个用户关注(follow)另一个用户或成为“朋友(friend)”时,其会收到来自另一个用户的推文更新。但这种关系是单向的,如果 Alice 是 Bob 的朋友,Bob 不一定是 Alice 的朋友。
- 关注者列表。其他收到来自该用户的推文更新的用户被称为“关注者(follower)”。
我们的工作
为了测量推特中匿名的普遍性,我们从公开的 2010 年推特数据集中的 4179 万个账户中随机选取了 10 万个账户。7 去掉所有被停用的账户、非英语账户(那些不以英语为偏好语言的账户)、垃圾邮件账户以及非活动或短期账户,我们把含有 50173 个推特账户的数据集用 Amazon Mechanical Turk(AMT)进行了标注。
标注推特账户
我们把每个推特账户的名字和显示名提供给 AMT 的工作人员,请他们来确定这两个字段是否只包含名字,或只包含姓氏,或两者都有,或两者都没有。工作人员也可以标注为不确定。在 AMT 标注的基础之上,我们把每个账户分配给下面几个类别中的其中一个:
- 匿名——推特账户中既没有姓氏也没有名字,还没有链接地址(因为链接地址可以指向一个部分或完全可识别用户的网页)
- 部分匿名——推特账户中有姓氏或者有名字,二者居其一
- 可识别的——有姓氏和名字的推特账户
- 无法分类的——只要不能被分到上述的类别中,比如有链接地址而无姓氏或名字的,或者是属于组织和公司的推特账户,都被归到这一类
请注意,用户分类中的噪音是难以完全除去的。例如,标注成匿名账户中的一小部分也许不完全如此,比如,用户提供的可识别的个人资料照片或用户推文公开了他们的身份。而且,可识别的账号中的一部分也许实际上是匿名的,因为这些用户提供的是假的姓氏和名字。
量化用户匿名
我们发现在所分析的账户中有 6% 是匿名的,因为这些账户的用户没有透露姓氏和名字。还有 20% 的账户是部分匿名的,只透露了姓氏或者名字。这意味着在线匿名是重要的,至少对 4 分之一的推特用户来说是这样的。同时,推特实名制的缺失也许是推特的强大卖点。在剩余的账户中,有 6% 是无法分类的,68% 是可识别的。当然,有些可识别的用户用的是假的姓氏和假的名字,因此,实际上是匿名的。这意味着在推特上没有完全披露自己身份的用户占 26% 可能有点低估了。
用户匿名和内容敏感性
为了评估内容敏感性和用户匿名之间是否相关,我们选择了几个主题类别,这些主题是被广泛地认为敏感或有争议的,包括色情、三陪服务、性取向、宗教和种族仇恨、在线毒品、枪支。为了对比,我们也选择了几个非敏感的主题类别,包括新闻网站、家庭娱乐、影视或戏剧、儿童或婴儿、生产家居用品的公司或组织。我们为每一类别确定了一些与众不同的搜索主题词,并且手工选取了在我们用那些主题词在推特上搜索时显示出的账户。
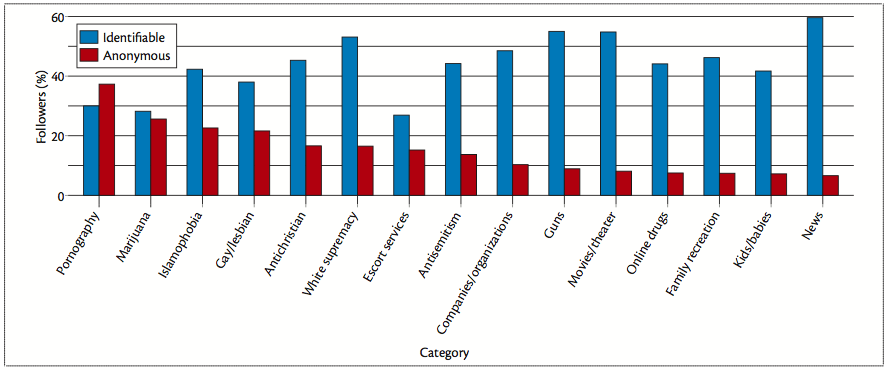
图 1 敏感和不敏感推特账号类别,按照匿名关注者所占的百分比从高到低排列
我们选择了 50 个跟敏感类别相关的推特账户,20 个跟非敏感类别相关的推特账户。图 1 展示了每个敏感和非敏感类别的匿名关注者所占的平均百分比。这些分类是根据匿名关注者所占的百分比从高到低排列的。
敏感类别的匿名用户所占的百分比最高,关注色情、大麻、伊斯兰恐惧症以及同性恋账户的用户至少占 21.6%,关注色情账户的远远超过其他匿名关注者,有 37.3% 之多。然而,某些敏感主题类别,比如白人之上和枪支这类的,在可识别的关注者中有着惊人的大比例。这显示出某些类别的敏感内容有保密性,而其他的则鼓励开放性。这个观察再次肯定内容敏感性是相当微妙和复杂的。
甚至非敏感的分类账户也有 6.6% 到 8.9% 的匿名追随者。这个观察证实用户不会仅仅为了关注敏感账户而创建匿名账户。为了避免维护多个账户,一个匿名用户也许会用同个账户同时关注敏感和非敏感的账户,于是在推特上泄露了其兴趣所在。
自动检测敏感账户
一种识别敏感账户的方法是指定敏感主题的分类,识别那些通常出现在这些主题讨论中的词汇,然后搜索使用这些词汇的推文和账户。然而,这个方法是非常主观的,因为它依赖人类来决定敏感主题和词汇。
另一种方法是对推文应用自动主题识别技术,比如 LDA(latent Dirichlet allocation,潜在狄利克雷分配)。这可以识别与这些敏感主题相关的账户。然而,这样的技术是资源高度密集型的,无法匹配推特的规模。8
因此,我们调查了我们观察到的用户匿名模式和他们与内容敏感性之间的联系是否可以用来开发一个有效的自动方式来识别推文中含有敏感内容的账户。这种方式会更好地推广到不可预见的主题,将不会受到语言特征的限制并且易于扩展。
我们首先考虑了自动确定账户是否匿名问题的一个子问题。我们依赖先前已经被标注的推特账户用于训练。因为匿名和可识别账户在姓氏和名字的构成上有不同之处,我们获取了美国人口普查和社会保障局的公开姓氏和名字列表。
但是,仅仅在名字列表中搜索,得到匿名和可识别的检测率很差。因此,我们从推特账户中提取了额外的可用信息,比如在公开名字列表中的姓氏和名字的流行等级;名字字符串遵循的结构约束(比如,“名 + 中间名 + 姓 ”),另外还有朋友的数量、关注者、推文等等。
利用这些提取的特征,我们训练了一个基于随机森林的匿名机器学习分类器,这个分类器能够精确地检测出匿名和可识别账户,精度超过 90%。然后,根据这个匿名分类器在之前已知的 70 个敏感和非敏感的账号中检测到匿名和可识别的关注者的比例,我们开发了一个基于支持向量机的敏感分类器,它可以区分敏感和非敏感的推特账户。
为了测试这个敏感分类器,我们爬取了推特上随机的 10 万个账户,这些账户有大约 4 亿 4 百万活跃的关注者。在标注了它们的关注者是匿名或是可识别之后,我们在这些账户上应用了这个分类器。
手工检查表明,被我们的分类器定义的敏感账户中,最主要的的确是在讨论多数人认为的敏感话题:色情、毒品和成人内容。然而,除了这些常见的嫌疑账户外,我们的方法发现很多账户跟社会性主题相关,这说明匿名具有很多不同的目的。
例如,我们识别出许多为同性恋、双性恋、变性人的权利摇旗呐喊的账户。对于很多人来说,披露自己的性取向是个敏感的问题,因此用户更倾向于匿名。我们发现了那些公开讨论婚姻和其他关系问题、分享个人感受或经历并解决健康问题的账户。匿名或许为人们提供了一个寻求支持和安慰的机会。
我们也发现了和严重厌食症、社交焦虑、抑郁和自杀倾向有关的账户。事实上,在其中的一些账户上,用户上传了其自残的照片。尽管这些账户有不同的目的,医疗机构正利用它们对那些需要帮助的人伸出援手。9
跟那些敏感主题有关账户的存在,以及它们有很多匿名关注者的事实支持了在我们这个社会中隐私和匿名是很重要的这个论点。
尽管我们识别推特敏感账户的新方法提供了一种可推广和客观的方式来了解内容敏感性,但是要改善用户在社交媒体内容上的隐私偏好和期望还需要更深入的研究。
比如,值得探索和量化在不同社交应用程序中有多少敏感性内容类别是一致的,以及有多少取决于该应用程序的特性(例如分享照片与消息传送)。我们希望我们的发现会对将来隐私政策的改善和新的隐私管控上有所帮助。
致谢
本文是在作者之前发表的两篇文章的基础上形成的,其中一篇是《在网上,没人知道你是条狗:社交网络匿名性的推文案例研究》(Proc. ACM Conf. Online Social Networks [COSN 14], 2014, pp. 83–94),另一篇是《在推特上寻找敏感账户:基于关注者匿名的自动化方法》(Proc. Int’l AAAI Conf. Web and Social Media [ICWSM 16], 2016, pp. 665–658)。
参考文献
- N. Lomas, “Facebook Users Must Be Allowed to Use Pseudonyms, Says German Privacy Regulator; Real-Name Policy ‘Erodes Online Freedoms,’” Techcrunch, 18 Dec. 2012; techcrunch.com/2012/12/18 /facebook-users-must-be-allowed-to -use-pseudonyms-says-german -privacy-regulator-real-name-policy -erodes-online-freedoms.
- A. Kavanaugh et al., “Microblogging in Crisis Situations: Mass Protests in Iran, Tunisia, Egypt,” Proc. Workshop Transnational Human-Computer Interaction (CHI 11), 2011; eventsarchive.org/sites/default/ les/Twi er%20Use%20 in%20Iran%20Tunisia%20Egypt .Kavanaugh.Final__0.pdf.
- E. Mustafaraj et al., “Hiding in Plain Sight: A Tale of Trust and Mistrust inside a Community of Citizen Reporters,” Proc. 6th Int’l AAAI Conf. Weblogs and Social Media (ICWSM 12), 2012, pp. 250–257.
- M.S. Bernstein et al., “4chan and /b/: An Analysis of Anonymity and Ephemerality in a Large Online Community,” Proc. 5th Int’l AAAI Conf. Weblogs and Social Media(ICWSM 11), 2011, pp. 50–57.
- D. Correa et al., “ e Many Shades of Anonymity: Characterizing Anonymous Social Media Content,” Proc. 9th Int’l AAAI Conf. Web and Social Media (ICWSM 15), 2015; socialnetworks.mpi-sws.org/papers/anonymity_shades.pdf.
- S.T. Peddinti et al., “Cloak and Swagger: Understanding Data Sensitivity through the Lens of User Anonymity,” Proc. 35th IEEE Symp. Security and Privacy, 2014, pp. 493–508.
- H. Kwak et al., “What Is Twi er, a Social Network or a News Media?,” Proc. 19th Int’l Conf. World Wide Web(WWW 10), 2010, pp. 591–600.
- B. Bi et al., “Scalable Topic-Speci c In uence Analysis on Microblogs,” Proc. 7th ACM Int’l Conf. Web Search and Data Mining (WSDM 14), 2014, pp. 513–522.
- J. Jashinsky et al., “Tracking Suicide Risk Factors through Twi er in the US,” Crisis, vol. 35, no. 1, 2014, pp. 51–59.
作者简介
Sai Teja Peddinti是谷歌安全和隐私小组的研究科学家。他的研究工作是在纽约大学攻读博士学位时期完成的。请通过 psaiteja@ google.com 与他联系。
Keith W. Ross是上海纽约大学工程与计算机科学系主任,纽约大学计算机科学与工程系 Leonard J. Shustek 讲座教授。 请通过 keithwross@nyu.edu 与他联系。
Justin Cappos是纽约大学 Tandon 工程学院的助教。请通过 jcappos@nyu.edu 与他联系。
查看英文原文: https://www.infoq.com/articles/user-anonymity-twitter
感谢冬雨对本文的审校。




