【编者的话】A /B 测试曾在多个领域产生深远的影响,其中包括医药、农业、制造业和广告。 在软件开发中, A/B 测试实验提供了一个有价值的方式,来评估新特性对客户行为的影响。在这个系列中,我们将描述 Twitter 的 A/B 测试系统的技术和统计现状。
本文是该系列的第四篇,介绍了使用第二个控制降低假阳性的想法。
注:本文最初发布于 Twitter 博客,InfoQ 中文站获得作者授权,对文章进行了翻译。
正文
在前面的文章中,我们讨论了 A/B 测试如何帮助我们创新 ,我们的 A/B 测试框架 DDG 是如何实现的,以及一种检测分桶不平衡的技术。在本文中,我们将探索并打消使用第二个控制来降低假阳性的想法。
概率问题
A/B 测试其本质是建立在统计与概率框架之上的一种方法论;正因为如此,我们从实验得出的结论可能并不总是正确的。假阳性,或者说型 I错误,拒绝零假设,而它实际上是正确的——或者简单地声称观察到行为变化,而实际上抽样总体之间没有变化。假阴性,或者说型 II错误,接受零假设,而实际上它是不正确的——换句话说,声称我们没有在桶(bucket)之间观察到变化,而实际上抽样总体之间存在差异。
尽管不可能完全避免这两种类型的错误,但是一个设计良好的统计实验其目的应该是最小化这两种错误。当然,当你做决定发布 / 不发布的时候,这种不确定非常令人担忧,因为你不确定你观察到的这些变化是否为“真”。
本文将检验为了提防这些错误而使用两种控制桶(control bucket)的想法。我们将证明这会造成严重问题,证明在使用相同数量的数据时,构建单一的大控制是达到同一目标的优选、无偏差的方案。
使用第二个控制测试
A/A 测试是指没有任何变更应用到“实验桶 (‘treatment’ bucket)“的测试,能够有效构建两个控制。A/A 测试是一种非常有用的验证测试框架的工具。通常我们使用 A/A 测试验证工具整体的正确性:检查统计方法是否正确实施,核实”异常值检测(outlier detection)“没有明显问题,以及删除垃圾信息。A/A 测试同样可以用来确定,检测可预测指标变化所必需的流量。
Twitter 上的一些实验者提出运行 A/A/B 而不是 A/B 测试,以降低“有偏差的” 桶(bucket)导致的假阳性。A/A/B 测试除了提供控制(A1),实验者还将往实验中添加另一个控制组(A2)。
有两种方法可以使用两个控制桶。第一种方法是用 A2 来验证——如果 treatment 表明控制 A1和控制 A2 有显著差异,那么就是“真”;否则,它是假阳性而被丢弃。另一种方法是把 A2 当作替代控制,只要认为 A1 桶并不是良好的潜在总体样本。
我们的分析表明这两种方法不如这个方法:从两个控制中”池化(pooling)“流量,并把它处理成单一的大控制——换句话说,如果你流量有余,那就让你的控制桶两倍大。
第二控制背后的统计
我们考虑一下 A/A/B 测试可能的结果:实际上,零假设是真,treatment(B)没有影响。
如下,我们列出了三个桶显著结果的所有可能的组合。在 0.05 的显著性水平,有 95% 的可能性,A1 和 A2(左图)无显著差异。在剩下的 5% 中,一半概率 A1 将显著低于 A2,一半概率 A1 将高于 A2(中间和右边的图)。
鉴于 A1-A2-B 的关系,每个单元的数字是特定组合 A1 vs Treatment 和 A2 vs Treatment 的百分比。这些值是通过分析推导得出;你可以在附录中找到推导过程。
(点击放大图像)

接着,我们将检验使用两种控制的方法,并说明与将两个控制桶合并成单一的大控制相比,为什么它们是次优的。
方法1 分析:拒绝任何分歧
回想一下,第一种方法表明,如果将这个方法与每个控制进行比较,除非它被拒绝,否则我们接受零假设。同时我们也抛弃所有与控制不一致的结果。
控制将拒绝5% 的情况,并且要立即抛弃。
图1 最左边的表中,观察到在零假设条件下(行中的两个假阳性),两个控制都与 treatment 显著差异的概率仅占95% 中的0.49% + 0.49% = 0.98%,或者总体的0.93%。因此零假设的误拒绝率从5% 显著下降到1% 以下。
这是有代价的,使用两个控制(其中任何一个都可以导致实验者接受零假设)是一个更加严格的条件,将会在 B 确实偏离控制的情况下导致假阴性。通过引入这个限制,我们降低了品质,结果是导致假阴性概率急剧增加。
具体的假阴性率取决于 treatment 移动的指标数。以实例说明,我们在两个控制中考虑均值为0,标准偏差为1 的正态分布,在 treatment 中均值为0.04,标准偏差为1。下表列出的假阴性百分比,可以使用上文提出的相同方法分析推导得出。我们将这个方法与使用单一的控制和使用池化的控制进行比较。为了匹配方法1 的假阳性率,在这两种情况下 ,P 值均设为0.0093。
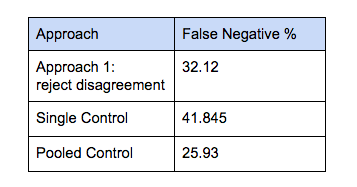
在所有的情况下,为了如此低的假阳性率,你将损失很高的假阴性。尽管方法1 比使用单一控制好,但是与将两个控制的流量合并到单一池化的大控制相比,方法1 产生更多的假阴性。
方法2 分析:选择“最好”的控制
使用两个控制的第二种方法是,找出哪种控制是潜在总体样本的最佳代表。由于我们将在观察到实验结果后识别出“最好”的控制,因此该方法会面临进退维谷的困境。这极其危险,也是彻底避免使用两个控制的最大原因。

然而,假设不是“靠直觉”在 A1 和 A2 之间挑选,我们是用分析来判断,哪种控制是潜在数据的更好代表。让我们仁慈一点,进一步假设(不切实际地)我们的分析师有权访问真实分布,并总可以正确地识别最佳控制。
我们模拟50000 对(A1,A2)桶,每对有10000 个符合标准正态分布的样本。在我们的模拟中,结果显示,2492(4.98%)对有统计上的显著差异均值。
根据分布,那么就可以绘制出模拟数据点,就很容易模拟出完美的“最佳控制”预言。对于每一对控制,我们只是挑选其均值更接近0 的控制。将其与池化的控制均值进行对比,池化的控制均值是两个控制均值的平均值——我们称之为“平均水平(average)”
这个案例令人失望,两个控制在统计上没有显著差异,因此实验者也就不能选出“最好”的控制。让我们只考虑观察到 A1 和 A2 之间有分歧的情况。从下图中我们看到 “best of 2”合理集中在0 附近。然而,尽管池化的控制图呈现出符合预期的单峰形状,“best of 2”战略形成双峰骆驼的双峰背。池化的控制方法的均值方差是4.81e-5,而 “best of 2”的均值方差则要高得多,达到1.45e-4。
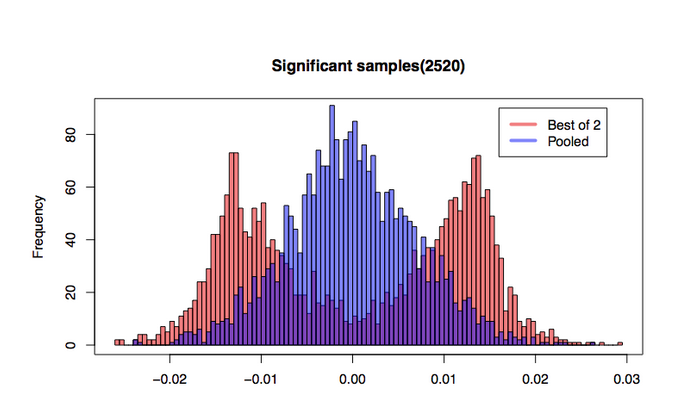
如果考虑到,为了让两种控制在统计上呈现出显著性差异,必须发生什么,那么我们就不会对 “best of 2”呈现出的形状感到惊讶。统计显著性是基于两种控制均值的差异进行计量的。差异越大,我们观察到它们就越不同。给定基于正态分布的样本均值(参见中心极限定理),对于任何差异 d,由于两种样本来自真均值的任意一侧,因此看到差异 _d_ 的概率要比均值都来自真均值同一侧的概率高。换句话说,如果你在两个控制之间看到很大的差异,那么可能是因为其中一个比真均值大(得多),而另一个比真均值小(得多)。与挑选任意一个极端相比,求均值将更接近真均值。
从该模拟中我们可以清晰看到,当这两个控制桶偏离时,池化它们将带来拥有较小方差分布的更好的均值评估,因此,甚至能比 100% 正确识别“最好”控制更可靠。池化控制在现实中更好实现,因为 100% 正确识别“最好”的控制是不可能的。
结论
加倍单个控制桶的大小,优先于使用两个控制桶实现两个独立的 _t_ 检验。使用两个控制,易使实验者带有偏误。如果实验者抵制偏误,只将第二控制用作验证工具,那么与池化控制相比,实验者将面对更高的假阴性概率。同样,相比只使用其中一个控制,池化控制会得到更好的真均值评估,并且不需要确定选择“最佳”控制的方法。实验者应该对建立“第二控制“的误导感到失望,以免犯错。
致谢
感谢本文合作者 Dmitriy Ryaboy 。我们还要感谢 Chris Said , Robert Chang , Yi Liu , Milan Shen , Zhen Zhu 和 Mila Goetz 以及 Twitter 的数据科学家,感谢他们珍贵的反馈意见。
编后语
《他山之石》是 InfoQ 中文站新推出的一个专栏,精选来自国内外技术社区和个人博客上的技术文章,让更多的读者朋友受益,本栏目转载的内容都经过原作者授权。文章推荐可以发送邮件到 editors@cn.infoq.com。
查看英文原文: Implications of use of multiple controls in an A/B test
感谢郭蕾对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




