
注意力机制是一个构建网络的思路,也是 Transformer 模型的核心。
注意力是人类认知功能的重要组成部分,指人的心理活动对外界一定事物的指向和集中。在大模型中也有注意力机制。比如神经网络语言模型面对一个由 n 个单词组成的句子时,不同位置的单词,重要性是不一样的。因此,需要让模型“注意”到那些相对更加重要的单词,这种方式称之为注意力机制,也称作 Attention 机制。
简单来说,注意力机制要做的事情就是:找到最重要的关键内容。它对网络中的输入(或者中间层)的不同位置,给予了不同的注意力或者权重,然后再通过学习,网络就可以逐渐知道哪些是重点,哪些是可以舍弃的内容了。
2017 年,谷歌发布《Attention is All You Need》,这也是关于注意力机制最经典的论文。在这篇论文中,谷歌提出了一个新型神经网络架构——Transformer,它完全基于注意力机制,省去了循环层和卷积层。并在 2014 年 WMT 英德翻译任务中达到 28.4 BLEU,比现有的最佳结果(包括集成部分)提高了 2 个 BLEU 以上。结果表明,Transformer 可以很好地将其推广到其他任务,不论是大量还是有限的训练数据。
2018 年,OpenAI 发布了 GPT,谷歌发布了 BERT,两大模型都是基于 Transformer 结构构建的——GPT 是基于 Transformer Decoder 结构和无监督预训练方法实现的生成式预训练语言模型,BERT 是基于 Transformer Encoder 结构的预训练语言模型。
随着近几年 AIGC 技术的爆火以及 ChatGPT 成为现象级应用,Transformer 正以井喷的势头快速发展,基于 Transformer 架构打造的模型数量激增,并将 Transformer 的热度推上了新的高峰。
然而近日,Eppo 初创公司的工程师 Evan Miller 在 Twitter 上表示,他发现注意力机制有一个存在了 8 年的 Bug,所有 Transformer 模型(GPT、LLaMA 等)都会受到影响。虽然研究人员上个月隔离了该错误,但他们忽视了一个简单的解决方案。
Miller 在一篇博客中详细阐述了该 Bug,并提出了修复方案。Miller 表示,他在跟 Pytorch 和 biblatex 的一连串交锋中败下阵来。虽然如此,他还是想向大家解释当前这代 AI 模型如何在关键位置出现差一错误,并导致每一个 Transformer 模型都难以压缩和部署。
以下是 Mille 的博客原文,经编译。
这个 Bug 有多重要?
大家发现这个公式中的差一错误了吗?
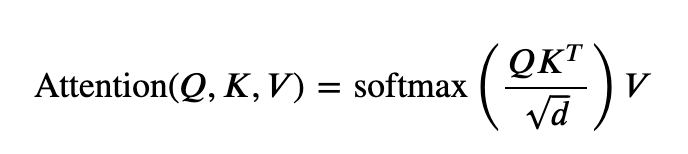
首先,我们来聊聊为什么这个差一错误这么重要。ChatGPT 的效果不是挺好吗,老兄,你在闹什么呢?其实我第一次察觉有问题,是在认真阅读关于量化的研究论文时。大语言模型的探索者们正尝试将其塞进 Mac Mini、Raspberry Pi,甚至是越了狱的家用智能恒温器。
但 AI 从业者都知道,如今限制最大的因素就是 RAM 容量。无论是在云端还是边缘,RAM 占用量越小、能做的事情就越多。大语言模型拥有几十亿的权重参数,如果我们能想办法帮这些参数成功瘦身,那完全可以写出更好的诗歌、生成更好的综述文章,或者加快人类末日到来的脚步——具体要看大家怎么应用了。
RAM 负责存储信息。这好像是废话,但大家先别急。信息属于负对数概率,代表我们需要用多少个 bit 来存储事物。如果数字流具备高度可预测性,例如总是处于有限的范围之内,那么我们要使用的存储 bit 量就可以更少。而如果一串数字毫无可预测性,包括偶尔甚至会出现极其巨大的数字,那我们就需要更多位二进制数字对其做编码。
而这正是大语言模型的真实情况。出于种种或明确、或含糊的原因,Transformer 模型会包含这些异常权重,用本不必存在的臃肿体态来应对那些发生概率极低、极低的情况。但奇怪的是,似乎没人在意这件事:不对吧,这类罕见异常值与我们之前所认为的、关于构建良好神经网络的一切知识都背道而驰。关于这些异常值,人们已经写过不少论文,也在制定各种“瘦身”方案用更少的 0 和 1 对其做编码。顺带一提,直接使用比例和偏差整量化会导致性能大幅下降,所以还得想点更好的办法。
目前关于这个问题的最佳分析,来自高通 AI 研究团队发表的论文《量化 Transformers:通过让注意力头什么都不做来消除离群值》(https://arxiv.org/abs/2306.12929)。作者将这些离群值追溯到了注意力机制中的 Softmax 函数,之前没人认为这个看似无辜的指数器居然拥有如此野蛮的峰度。其实研究人员马上就要发现其中的差一错误了,但此刻他们可能是在意大利度假,否则怎么就没人回复我发过去的邮件提议呢?于是乎,我只能用最传统的方式向国际学术界发出呼吁。
如果大家读过链接中的论文,请直接忽略他们给出的建议。我知道这话讲得不客气,但裁剪之后的 Softmax 带有一个旋转的零梯度,而他们的门控注意力建议虽然可行,却要靠引入数百万个新参数来解决一个实质上仅是增量失败的问题。这里明显有个简单且直观的解决方案,但从我接触过的相关讨论来看,似乎没人想到要尝试。
好吧,关于这个愚蠢的错误,我已经介绍得够多了。现在咱们来看看 Softmax 函数,还有它在注意力机制里惹出了怎样的麻烦。
Softmax 惹出了什么麻烦?
要想明确解释这个 Bug,大家先得真正理解注意力机制是干什么的。大多数数值 Bug 源自程序员把方程给弄错了。但如果错误不出在代码上、而是出在数学上时,我们就必须先搞清当前方程的来源和它的预期效果,然后才能加以修复。
为此,我不得不认真阅读了大约 50 篇 arXiV 文章才逐渐理清思路。关于这个问题的讨论,我们先从所谓“输入嵌入”入手,这是一个浮点向量,表示输入字符串中的一个单词。
这个向量似乎正随着模型的逐年发展而越来越长。例如,Meta 最近的 LlaMA 2 模型使用的嵌入向量长度为 3204,其半精度浮点计算结果为 6 KB 以上。是的,这仅仅对应词汇表中的一个单词,而词汇表通常要包含 3 到 5 万个单词条目。
现在,如果大家跟我一样是对内存极为吝惜的 C 程序员,那肯定会考虑:为什么这帮 AI 蠢货非要用 6 KB 空间来表达这种双字节信息?如果总词汇量不超过 216=65384,那我们只需要 16 个 bit 就能表示一个条目了,对吧?
确实,人家 Transformer 其实也是这么干的:它将输入向量转换成相同大小的输出向量,而最终的 6 KB 输出向量会对预测当前 token 之后的下一 token 所需要的全部内容进行编码。
Transformer 每个层的工作,其实就是把信息添加到原始单字向量当中。这就是残差连接的意义所在:整个注意力机制只是向原始的两个字节的信息添加补充材料,通过分析更多上下文来证明当前文本中的“pupil”是指某位学生、而不该直译为瞳孔。把注意力机制重复个几十次,模型就掌握了英语及其承载的一切广泛内容。
现在,Transformer 会将输出向量乘以一个矩形矩阵,再将生成的词汇长度向量填充到 Softmax 当中,最后把这些指数输出视为下一个 token 概率。这确有合理性,但大家都知道其中仍有问题。一切广受尊重的模型都承认这种输出概率在所偏差,需要在具体实现中通过采样机制来隐藏 Softmax 过度代表低概率的事实。
引入采样确实可行。毕竟输出步骤中的 Softmax 将为我们提供词汇表内每个单词的梯度,在没有更好结果可用的情况下,确实可以先遵循拿来主义。
但我想说的是,就没必要非把不相干的东西搅和在一起。Transformer 的输出 Softmax 与注意力机制的内部 Softmax 用途完全不同,所以我们最好别跟后者硬靠,或者至少该对分母做点科学调整⛱️。
Softmax 到底是什么?
那么,Softmax 到底是什么?它源自统计力学,代表一种根据能级预测状态分布的方法:
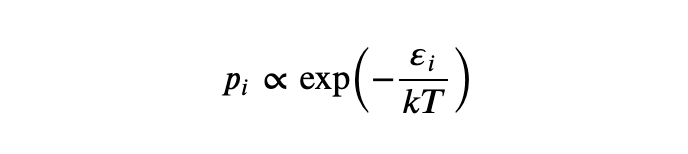
在掌握了它之后,经济学家们意识到,如果人们的线性效用函数中的噪声项恰好遵循 Gumbel 分布,那么某人选择某个条目的概率就将与效用输入的指数成正比:

这就为 Softmax 在多项逻辑函数中赋予了生命力。我在读研究生时曾亲手推导过这个 Hessian 矩阵,想通过编码用线性固定效应将其运行在 GPU 上。据我所知,之前和之后都没人蠢到做这样的尝试。说了这么多,就是想告诉大家我跟 Softmax 函数还真就有那么点缘分。
Softmax 其实是一种“作弊码”,能够将实数值映射到总和为 1 的概率上。它在物理学中的效果相当好,在经济学上有点虚;而在机器学习领域,它已经成为离散选择当中的有效手段。
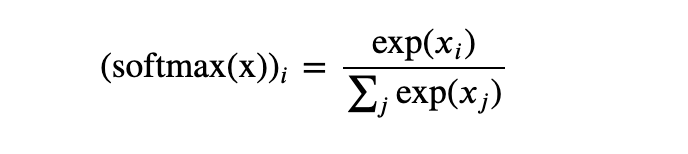
这也是 Softmax 的核心机制:它要求在各种可行方案间做出选择,包括粒子选择能级状态、也包括消费者选择心仪的汽车。也就是说,如果一个 Softmax 机制根本不打算做选择,那就应该做出修改,否则 Softmax 一定会在处理真实数据时发生扭曲。
回到大语言模型这个话题上,此类扭曲的一种实际表现,就是对非语义 token(比如逗号)进行重点加权,而这就变成了那些难以压缩的离群值,致使模型很难被部署在边缘场景当中。高通 AI 研究院的报告发现,大语言模型中有超过 97%的异常激活发生在空白和标点位置。
具体是怎么出错的?
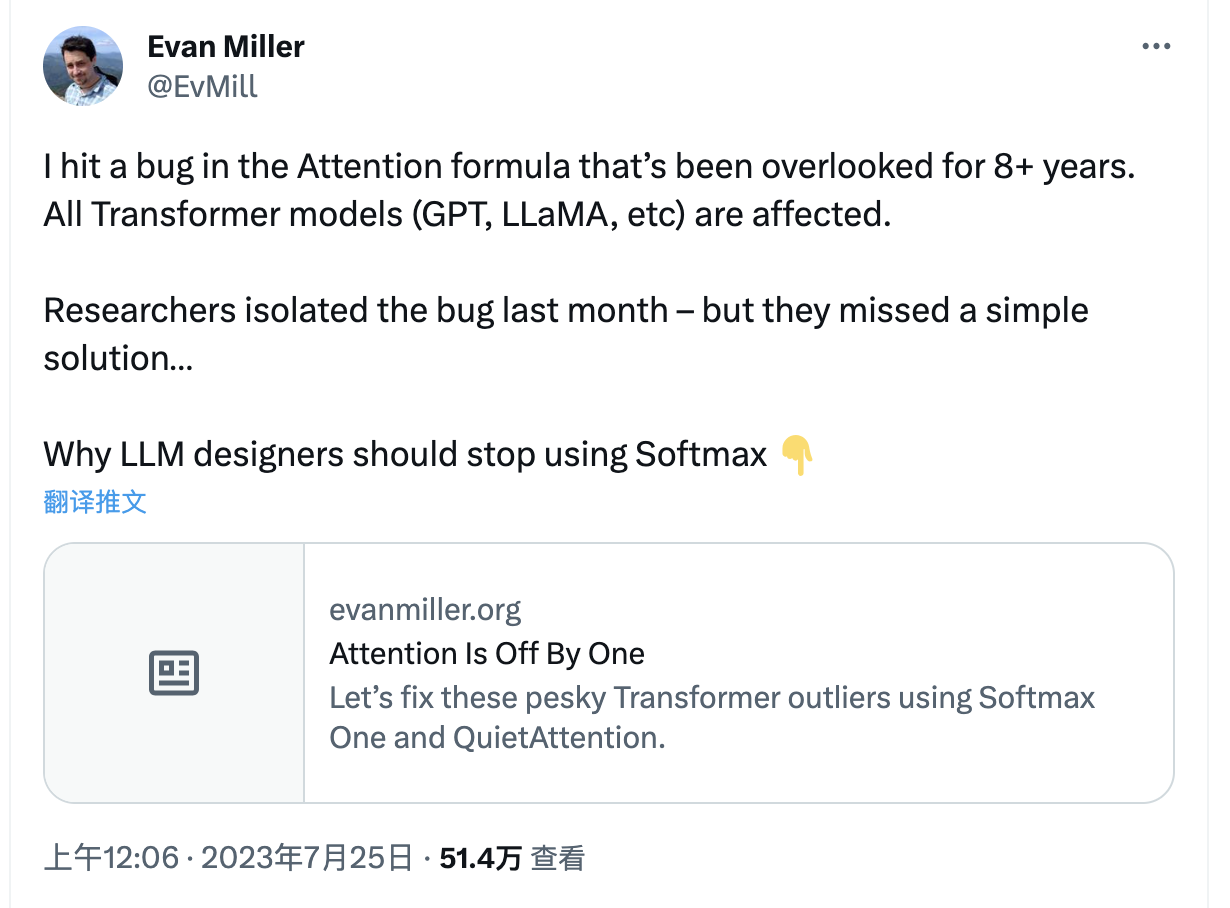
下面我们深入研究一下 Softmax 在注意力机制中如何起效,看看是哪里出了问题。仍然是这个等式:

分解一下:在仅解码器模型中(即 ChatGPT 之后的所有模型),Q、K 和 V 都来自同一输入序列。虽然它们会在期间被以不同方式投影,所以彼此间并不相同,但在每一层中,它们都始于相同的已注释(已添加)嵌入向量。
现在,𝑄𝐾𝑇在寻找不同位置上 token(嵌入)向量之间的相关性,这实际上会构建一个相关性(点积按 1/√𝑑‾‾缩放)值的方形矩阵,其中每行和每列对应一个 token 位置。方形矩阵中的每一行都经过 Softmax 的处理,得出概率以作为 V 矩阵中各值向量的混合函数。混合概率后的 V 矩阵将被添加至输入向量中,再被传递至神经网络内做进一步处理。
多头注意力会在每个层中都经历这个过程,完成多次处理。它基本上就是将嵌入向量划分成几个部分,每个头使用整个微量中的信息来注释输入向量中的一个(不重叠)部分。简单来讲,就是 Head 1 向 Segment 1 添加信息,Head 2 向 Segment 2 添加信息,依此类推。
但使用 Softmax 的问题在于,即使没有什么信息可以添加到输出向量当中,它也会迫使各注意力头进行注释。所以在离散选择中使用 Softmax 效果拔群,但在可选注释(即输入到加法中)则不太理想。其中,多头注意力又会进一步加剧问题,这是因为专用头往往比通用头更想要“通过”,反而带来了不必要的噪声。
说到这里,是不是该直接让 Softmax 下课走人?当然不至于,它在大多数情况下都运行良好,唯一的小 Bug 也只是让注意力头没法“乖乖闭嘴”。所以我提出了一个很小也很直观的调整建议,自从注意力机制在 2014 年被发明出来,这个办法就一直在每个人的眼皮子底下。
大家准备好了吗?
修复方案
现在,让我们有请睽违已久、经过改造的 Softmax Super-Mod 闪亮登场:
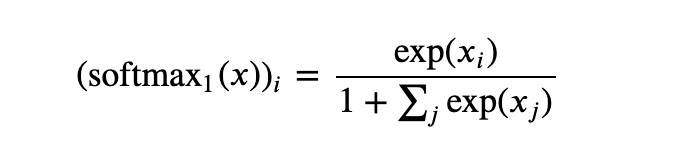
感觉也没什么了不起?是的,我只是在分母处加了个 1。这就是让整个向量朝着零挪动了一点点,而这将在注意力之后的归一化过程中得到补偿。
修改后的主要区别在于负极限,当 x 中的条目明显小于零且模型试图回避一次注释时,其表现将与原始 Softmax 的行为有所不同。先来看原始 Softmax:
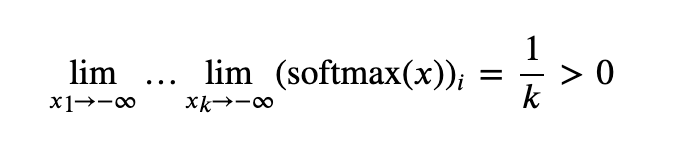
以下则是经过改进的新 Softmax 1:
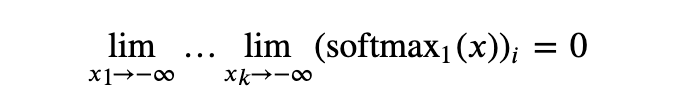
原始 Softmax 将始终发出相同的总权重;Softmax 1 看似区别不大,但在负半轴中设有一处“逃生通道”。再次强调,这里的关键在于数学问题,而非数值问题。进一步提高精度并不能拯救 Softmax,所有 transformers 均受此影响。
Softmax 1 还有其他一些特性。因为它的导数是正值,所以我们始终拥有非零梯度;它的和在 0 到 1 之间,因此输出不会失控。该函数还具备以下属性,即输出向量中的相对值不变:

最初我本想把这个函数命名为 Ghostmax,因为这里的 x 中有个额外的零值条目(即 exp(0)=1),而 V 矩阵中有一个会衰减结果的零向量。但别担心,这些不是重点。
虽然 Softmax 1 看似平平无奇,但我有 99.44%的把握相信它能解决离群反馈循环的量化问题。
我们将这种改进机制称为 QuietAttention,因为它允许注意力头保持安静:

大家很快就可以测试起来了。只要在每个输入上下文中添加一个零向量作为前缀,并确保所选择的神经网络不会添加任何偏差(包括位置编码),那么零向量应该就能原封不动通过,并在每个后续的 Softmax 分母中都加上一个单位。这样,也就不用再纠结什么梯度代码了。
但这种方法要求重新训练模型,所以请先别急着在 Raspberry Pi 上尝试。希望大家能分享关于权重峰度和激活无穷范数多轮运行后的实际影响,我想把这些数字整理成表格,供 arXiV 上发表的新论文使用。
原文链接:




