介绍
作为数据科学家,我们平时的工作是使用各种机器学习算法从数据中提取可操作的信息。其中大多数是有监督学习问题,因为你已经知道目标函数是什么。给出的数据有很多细节能帮助你实现最终目标。
虽然无监督学习是一项十分复杂的挑战,但是它有许多优点。它有潜力解决以前无法解决的问题,在机器学习和深度学习领域得到了大量的注意力。
这篇文章的目的是直观地介绍一下无监督学习,以及它在现实生活中的应用。
注意——阅读这篇文章需要读者具有一定深度学习基础,并且了解机器学习的概念。如果还没有掌握基础知识,可以阅读以下参考文献:
下面就让我们进入正题吧!
为什么要用无监督学习?
机器学习项目中的典型方法是以有监督的方式设计的。我们告诉算法该做什么和不该做什么。这是一个解决问题的通用结构,但是它从两个方面限制了算法的潜力:
- 算法受到监督信息的偏见的约束。没错,算法是自己学会的如何完成这项任务。但是,算法在解决问题时无法去考虑其他可能出现的情况。
- 由于学习在监督下进行,为算法创建标签需要花费巨大的人力。手动创建的标签越少,算法可以用于训练的数据就越少。
为了以一种智能的方式来解决这一问题,我们可以采用非监督学习算法。非监督学习直接从数据本身得到数据的性质,然后总结数据或对数据分组,让我们可以使用这些性质来进行数据驱动的决策。
让我们用一个例子来更好地理解这个概念。比如说,银行想要对客户进行分组,以便他们能向客户推荐合适的产品。他们可以通过数据驱动的方式来完成这件事——首先通过客户的年龄对客户进行细分,然后从这些分组中得到客户的特性。这将有助于银行向客户提供更好的产品推荐,从而提高客户满意度。
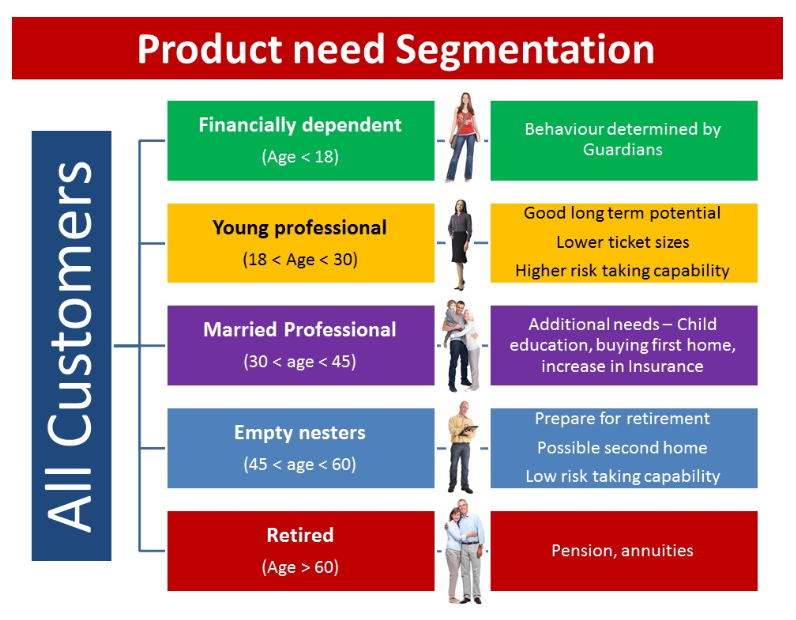

无监督深度学习范例研究
在这篇文章中,我们将介绍一个基于非结构化数据的无监督学习的范例研究。深度学习技术通常在处理非结构化数据时能力最强。因此,我们以深度学习在图像处理领域的应用为例,来理解这个概念。
定义问题——如何整理照片库
现在,我的手机里有 2000 张照片。如果我是一个自拍狂,照片的数量很可能是这个数字的 10 倍。挑选这些照片是一场噩梦,因为基本上每三张照片中就有一张对我来说是无用的。我相信大多数人都有同样的问题。
理想情况下,我想要的是一个能够整理照片的应用程序,可以让我随时浏览大部分照片。这样我也可以知道我目前有多少类照片。
为了更清楚地了解这个问题,我尝试自己对照片进行分类。以下是我总结的情况:
- 首先,我发现我的照片库中有三分之一都是网络趣图(感谢 WhatsApp 的可爱的朋友们)。

- 我个人也会收集一些在 Reddit 上看到的有趣的回答或分享。


- 至少有 200 张照片,是我在著名的DataHack Summit会议上,和随后去喀拉拉的旅行中拍摄的,也有一些是同事分享给我的。

- 也有一些照片记录了会议期间的白板讨论内容。

- 还有一些截图记录了代码错误,需要内部团队讨论。使用后必须清除它们。

- 我还发现了一些“个人隐私”图像,如自拍、合影和几个特殊场景。它们数量不多,但它们是我珍贵的财产。

- 最后,有无数张“早上好”、“生日快乐”和“幸福的排灯节”的海报,我想方设法把它们从照片库中删除。但是不管我怎么删除它们,它们还是会出现!


在下面的章节中,我们将讨论一些我想出的解决这个问题的方法。
方法一:基于时间分类
最简单的方法是按照时间来整理照片。每一天都可以有不同的文件夹。大多数照片浏览应用程序均使用这种方法(如谷歌照片应用程序)。

这样做的好处是,当天发生的所有事件都会被存储在一起。这种方法的缺点是它太普通了。每一天,我都可能拍摄郊游的照片,同时把有意思的回答截图下来,等等。它们会混在一起,这完全没有达到我的目的。
方法二:基于位置分类
一个相对较好的方法是根据拍摄地点整理照片。例如,每次照相,我们都可以记录照片拍摄的地方。然后,我们可以根据这些位置——无论是国家、城市还是地区,按照我们想要的区域粒度来制作文件夹。这种方法也被许多照片应用程序所使用。

这种方法的缺点在于它的想法过于简单。我们如何定义一张搞笑图片,或者一张卡通图的位置?而它们在我的照片库中占有相当大的份额。所以这种方法也不够巧妙。
方法三:提取照片的语义信息,并用它来定义我的照片库
到目前为止,我们所看到的方法大多依赖于和照片同时获得的元数据。整理照片的一种更好的方法是从图像本身中提取语义信息并智能地使用这些信息。
让我们把这个想法分成几个部分。假设我们有多样性类似(如上所述)的照片。我们的算法应该捕捉哪些趋势?
- 拍摄的是自然场景图像还是人工生成的图像?
- 照片里有文字材料吗?如果有的话,我们能识别出它是什么吗?
- 照片中有什么不同的物体?它们的结合能确定照片的美感吗?
- 照片里有人吗?我们能认出他们吗?
- 网络上有相似的图像可以帮助我们识别图像的内容吗?
因此,我们的算法应该能理想地捕捉这个信息,而不需要明显的标记,并用它来整理、分类我们的照片。理想情况下,最终的应用程序界面应该是这样的:

这种方法就是以“无监督的方式”来解决问题。我们没有直接定义我们想要的结果。相反,我们训练一个算法为我们找到这些结果。我们的算法以智能的方式对数据进行了总结,然后在这些推论的基础上尝试解决这个问题。很酷,对吧?
现在你可能想知道,我们该如何利用深度学习来处理无监督的学习问题?
正如我们在上面的案例研究中看到的,通过从图像中提取语义信息,我们可以更好地了解图像的相似性。因此,我们的问题可以表述为:我们该如何降低图像的维度,使我们可以从这些编码表示重建图像。
我们可以利用一个深度学习网络结构——自编码器。
自动编码器的思想是,训练它从学习到的特征来重构输入。亮点在于,它用一个很小的特征表示来重构输入。
例如,一个设置编码维度为 10 的自动编码器,在猫的图像上训练,每一张图像大小为 100×100。所以输入维数是 10000,而自动编码器需要用一个大小为 10 的矢量表示输入所有信息(如下图所示)。

一个自动编码器从逻辑上可以分为两个部分:编码器和解码器。编码器的任务是将输入转化成一个低维表示,而解码器的任务是从低维表示重构输入。
这是对自编码器的高度概括,下一篇文章中我们将仔细解读自编码器的算法。
虽然这一领域的研究正在蓬勃发展,但目前最先进的方法也无法轻松解决工业层面的问题,我们的算法想真正“投入工业使用”还需几年时间。
在 MNIST 数据集上进行无监督深度学习的代码详解
现在我们已经基本了解了如何使用深度学习解决无监督学习问题,下面我们要把学到的知识运用在现实生活的问题中。这里,我们以 MNIST 数据集为例,MNIST 数据集一直是深度学习测试的必选数据集。在解读代码之前,让我们先了解一下问题的定义。
原始问题是确定图像中的数字。数据库会给出图像所含数字的标签。在我们的案例研究中,我们将尝试找出数据库中相似的图片,并将它们聚成一类。我们将通过标签来评估每个类别的纯度。你可以在 AV 的 DataHack 平台下载数据——“识别数字”实践问题。
我们会测试三种无监督学习技术,然后评价它们的表现:
- 直接对图像进行 KMeans 聚类
- KMeans + 自编码器
- 深度嵌入式聚类算法
在开始实验之前,确保你已经在系统中安装了 Keras。(可参考官方安装指南。)我们将用TensorFlow 作为后台,所以你要确保配置文件中有这一项。如果没有,按照这里给出的步骤进行操作。
我们需要用到 Xifeng Guo 实现的 DEC 算法开源代码。在命令行输入如下命令:
git clone https://github.com/XifengGuo/DEC-keras
cd DEC-keras
你可以打开一个 Jupyter Notebook,跟着下面的代码一起操作。
首先我们需要导入所有必需的模块。
%pylab inline
import os
import keras
import metrics
import numpy as np
import pandas as pd
import keras.backend as K
from time import time
from keras import callbacks
from keras.models import Model
from keras.optimizers import SGD
from keras.layers import Dense, Input
from keras.initializers import VarianceScaling
from keras.engine.topology import Layer, InputSpec
from scipy.misc import imread
from sklearn.cluster import KMeans
from sklearn.metrics import accuracy_score, normalized_mutual_info_score
下面我们将种子的值设为一个受限随机数。
# To stop potential randomness
seed = 128
rng = np.random.RandomState(seed)
现在设置数据的工作路径,方便后续访问。
root_dir = os.path.abspath('.')
data_dir = os.path.join(root_dir, 'data', 'mnist')
读入训练和测试文件。
train = pd.read_csv(os.path.join(data_dir, 'train.csv'))
test = pd.read_csv(os.path.join(data_dir, 'test.csv'))
train.head()
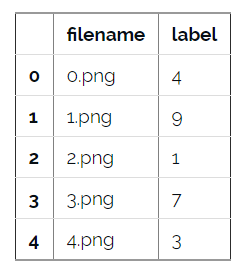

在这个数据库中,每个图片都有类标,这在非监督学习中并不常见,这里,我们用这些类标来评估无监督学习模型的表现。
现在让我们把数据显示成一张图片:
img_name = rng.choice(train.filename)
filepath = os.path.join(data_dir, 'train', img_name)
img = imread(filepath, flatten=True)
pylab.imshow(img, cmap='gray')
pylab.axis('off')
pylab.show()

随后我们读入所有图片,将它们存储成一个 numpy 矩阵,创建训练和测试文件。
temp = []
for img_name in train.filename:
image_path = os.path.join(data_dir, 'train', img_name)
img = imread(image_path, flatten=True)
img = img.astype('float32')
temp.append(img)
train_x = np.stack(temp)
train_x /= 255.0
train_x = train_x.reshape(-1, 784).astype('float32')
temp = []
for img_name in test.filename:
image_path = os.path.join(data_dir, 'test', img_name)
img = imread(image_path, flatten=True)
img = img.astype('float32')
temp.append(img)
test_x = np.stack(temp)
test_x /= 255.0
test_x = test_x.reshape(-1, 784).astype('float32')
train_y = train.label.values
我们将训练数据分成训练集和测试集。
split_size = int(train_x.shape[0]*0.7)
train_x, val_x = train_x[:split_size], train_x[split_size:]
train_y, val_y = train_y[:split_size], train_y[split_size:]
K-Means
我们首先直接对图像使用 K-Means 聚类,将其聚成 10 类。
km = KMeans(n_jobs=-1, n_clusters=10, n_init=20)
km.fit(train_x)
KMeans(algorithm='auto', copy_x=True, init='k-means++', max_iter=300,
n_clusters=10, n_init=20, n_jobs=-1, precompute_distances='auto',
random_state=None, tol=0.0001, verbose=0)
现在我们已经训练了模型,下面看一下它在验证集上的表现如何。
pred = km.predict(val_x)
我们将使用归一化互信息(NMI)分数来评估我们的模型。
互信息是聚类结果和人工分类之间依赖程度的对称性度量。它基于聚类纯度 PI 的概念,通过将 Ci 与 M 中的所有手动分类进行比较,衡量单个聚类 Ci 的质量,即 Ci 与 Mj 中相同目标的最大数量。因为 NMI 是归一化的,所以我们可以使用它来比较聚类个数不同的聚类结果。
NMI 公式如下:


normalized_mutual_info_score(val_y, pred)
0.4978202013979692
K-Means + AutoEncoder
现在,我们不直接使用 K-Means,我们首先用自编码器降低数据维度,提取有用信息,再将这些信息传递给 K-Means 算法。
# this is our input placeholder
input_img = Input(shape=(784,))
# "encoded" is the encoded representation of the input
encoded = Dense(500, activation='relu')(input_img)
encoded = Dense(500, activation='relu')(encoded)
encoded = Dense(2000, activation='relu')(encoded)
encoded = Dense(10, activation='sigmoid')(encoded)
# "decoded" is the lossy reconstruction of the input
decoded = Dense(2000, activation='relu')(encoded)
decoded = Dense(500, activation='relu')(decoded)
decoded = Dense(500, activation='relu')(decoded)
decoded = Dense(784)(decoded)
# this model maps an input to its reconstruction
autoencoder = Model(input_img, decoded)
autoencoder.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input_1 (InputLayer) (None, 784) 0
_________________________________________________________________
dense_2 (Dense) (None, 500) 392500
_________________________________________________________________
dense_3 (Dense) (None, 500) 250500
_________________________________________________________________
dense_4 (Dense) (None, 2000) 1002000
_________________________________________________________________
dense_5 (Dense) (None, 10) 20010
_________________________________________________________________
dense_6 (Dense) (None, 2000) 22000
_________________________________________________________________
dense_7 (Dense) (None, 500) 1000500
_________________________________________________________________
dense_8 (Dense) (None, 500) 250500
_________________________________________________________________
dense_9 (Dense) (None, 784) 392784
=================================================================
Total params: 3,330,794
Trainable params: 3,330,794
Non-trainable params: 0
_________________________________________________________________
# this model maps an input to its encoded representation
encoder = Model(input_img, encoded)
autoencoder.compile(optimizer='adam', loss='mse')
现在训练自编码器模型:
train_history = autoencoder.fit(train_x,train_x, epochs=500, batch_size=2048, validation_data=(val_x, val_x))
Train on 34300 samples, validate on 14700 samples
Epoch 1/500
34300/34300 [==============================] - 2s 60us/step - loss: 0.0805 - val_loss: 0.0666
...
Epoch 494/500
34300/34300 [==============================] - 0s 11us/step - loss: 0.0103 - val_loss: 0.0138
Epoch 495/500
34300/34300 [==============================] - 0s 10us/step - loss: 0.0103 - val_loss: 0.0138
Epoch 496/500
34300/34300 [==============================] - 0s 11us/step - loss: 0.0103 - val_loss: 0.0138
Epoch 497/500
34300/34300 [==============================] - 0s 11us/step - loss: 0.0103 - val_loss: 0.0139
Epoch 498/500
34300/34300 [==============================] - 0s 11us/step - loss: 0.0103 - val_loss: 0.0137
Epoch 499/500
34300/34300 [==============================] - 0s 11us/step - loss: 0.0103 - val_loss: 0.0139
Epoch 500/500
34300/34300 [==============================] - 0s 11us/step - loss: 0.0104 - val_loss: 0.0138
pred_auto_train = encoder.predict(train_x)
pred_auto = encoder.predict(val_x)
km.fit(pred_auto_train)
pred = km.predict(pred_auto)
normalized_mutual_info_score(val_y, pred)
0.7435578557037037
从结果可以看到,将自编码器与 K-Means 结合起来,算法效果比仅使用 K-Means 的效果要好。
DEC
最后,我们看一下 DEC 算法的实现。DEC 算法将聚类和自编码器放在一起训练以取得更好的效果。(论文: Junyuan Xie, Ross Girshick, and Ali Farhadi. Unsupervised deep embedding for clustering analysis. ICML 2016. )
"""
Keras implementation for Deep Embedded Clustering (DEC) algorithm:
Original Author:
Xifeng Guo. 2017.1.30
"""
def autoencoder(dims, act='relu', init='glorot_uniform'):
"""
Fully connected auto-encoder model, symmetric.
Arguments:
dims: list of number of units in each layer of encoder. dims[0] is input dim, dims[-1] is units in hidden layer.
The decoder is symmetric with encoder. So number of layers of the auto-encoder is 2*len(dims)-1
act: activation, not applied to Input, Hidden and Output layers
return:
(ae_model, encoder_model), Model of autoencoder and model of encoder
"""
n_stacks = len(dims) - 1
# input
x = Input(shape=(dims[0],), name='input')
h = x
# internal layers in encoder
for i in range(n_stacks-1):
h = Dense(dims[i + 1], activation=act, kernel_initializer=init, name='encoder_%d' % i)(h)
# hidden layer
h = Dense(dims[-1], kernel_initializer=init, name='encoder_%d' % (n_stacks - 1))(h) # hidden layer, features are extracted from here
y = h
# internal layers in decoder
for i in range(n_stacks-1, 0, -1):
y = Dense(dims[i], activation=act, kernel_initializer=init, name='decoder_%d' % i)(y)
# output
y = Dense(dims[0], kernel_initializer=init, name='decoder_0')(y)
return Model(inputs=x, outputs=y, name='AE'), Model(inputs=x, outputs=h, name='encoder')
class ClusteringLayer(Layer):
"""
Clustering layer converts input sample (feature) to soft label, i.e. a vector that represents the probability of the
sample belonging to each cluster. The probability is calculated with student's t-distribution.
# Example
```
model.add(ClusteringLayer(n_clusters=10))
```
# Arguments
n_clusters: number of clusters.
weights: list of Numpy array with shape `(n_clusters, n_features)` witch represents the initial cluster centers.
alpha: parameter in Student's t-distribution. Default to 1.0.
# Input shape
2D tensor with shape: `(n_samples, n_features)`.
# Output shape
2D tensor with shape: `(n_samples, n_clusters)`.
"""
def __init__(self, n_clusters, weights=None, alpha=1.0, **kwargs):
if 'input_shape' not in kwargs and 'input_dim' in kwargs:
kwargs['input_shape'] = (kwargs.pop('input_dim'),)
super(ClusteringLayer, self).__init__(**kwargs)
self.n_clusters = n_clusters
self.alpha = alpha
self.initial_weights = weights
self.input_spec = InputSpec(ndim=2)
def build(self, input_shape):
assert len(input_shape) == 2
input_dim = input_shape[1]
self.input_spec = InputSpec(dtype=K.floatx(), shape=(None, input_dim))
self.clusters = self.add_weight((self.n_clusters, input_dim), initializer='glorot_uniform', name='clusters')
if self.initial_weights is not None:
self.set_weights(self.initial_weights)
del self.initial_weights
self.built = True
def call(self, inputs, **kwargs):
""" student t-distribution, as same as used in t-SNE algorithm.
q_ij = 1/(1+dist(x_i, u_j)^2), then normalize it.
Arguments:
inputs: the variable containing data, shape=(n_samples, n_features)
Return:
q: student's t-distribution, or soft labels for each sample. shape=(n_samples, n_clusters)
"""
q = 1.0 / (1.0 + (K.sum(K.square(K.expand_dims(inputs, axis=1) - self.clusters), axis=2) / self.alpha))
q **= (self.alpha + 1.0) / 2.0
q = K.transpose(K.transpose(q) / K.sum(q, axis=1))
return q
def compute_output_shape(self, input_shape):
assert input_shape and len(input_shape) == 2
return input_shape[0], self.n_clusters
def get_config(self):
config = {'n_clusters': self.n_clusters}
base_config = super(ClusteringLayer, self).get_config()
return dict(list(base_config.items()) + list(config.items()))
class DEC(object):
def __init__(self,
dims,
n_clusters=10,
alpha=1.0,
init='glorot_uniform'):
super(DEC, self).__init__()
self.dims = dims
self.input_dim = dims[0]
self.n_stacks = len(self.dims) - 1
self.n_clusters = n_clusters
self.alpha = alpha
self.autoencoder, self.encoder = autoencoder(self.dims, init=init)
# prepare DEC model
clustering_layer = ClusteringLayer(self.n_clusters, name='clustering')(self.encoder.output)
self.model = Model(inputs=self.encoder.input, outputs=clustering_layer)
def pretrain(self, x, y=None, optimizer='adam', epochs=200, batch_size=256, save_dir='results/temp'):
print('...Pretraining...')
self.autoencoder.compile(optimizer=optimizer, loss='mse')
csv_logger = callbacks.CSVLogger(save_dir + '/pretrain_log.csv')
cb = [csv_logger]
if y is not None:
class PrintACC(callbacks.Callback):
def __init__(self, x, y):
self.x = x
self.y = y
super(PrintACC, self).__init__()
def on_epoch_end(self, epoch, logs=None):
if epoch % int(epochs/10) != 0:
return
feature_model = Model(self.model.input,
self.model.get_layer(
'encoder_%d' % (int(len(self.model.layers) / 2) - 1)).output)
features = feature_model.predict(self.x)
km = KMeans(n_clusters=len(np.unique(self.y)), n_init=20, n_jobs=4)
y_pred = km.fit_predict(features)
# print()
print(' '*8 + '|==> acc: %.4f, nmi: %.4f <==|'
% (metrics.acc(self.y, y_pred), metrics.nmi(self.y, y_pred)))
cb.append(PrintACC(x, y))
# begin pretraining
t0 = time()
self.autoencoder.fit(x, x, batch_size=batch_size, epochs=epochs, callbacks=cb)
print('Pretraining time: ', time() - t0)
self.autoencoder.save_weights(save_dir + '/ae_weights.h5')
print('Pretrained weights are saved to %s/ae_weights.h5' % save_dir)
self.pretrained = True
def load_weights(self, weights): # load weights of DEC model
self.model.load_weights(weights)
def extract_features(self, x):
return self.encoder.predict(x)
def predict(self, x): # predict cluster labels using the output of clustering layer
q = self.model.predict(x, verbose=0)
return q.argmax(1)
@staticmethod
def target_distribution(q):
weight = q ** 2 / q.sum(0)
return (weight.T / weight.sum(1)).T
def compile(self, optimizer='sgd', loss='kld'):
self.model.compile(optimizer=optimizer, loss=loss)
def fit(self, x, y=None, maxiter=2e4, batch_size=256, tol=1e-3,
update_interval=140, save_dir='./results/temp'):
print('Update interval', update_interval)
save_interval = x.shape[0] / batch_size * 5 # 5 epochs
print('Save interval', save_interval)
# Step 1: initialize cluster centers using k-means
t1 = time()
print('Initializing cluster centers with k-means.')
kmeans = KMeans(n_clusters=self.n_clusters, n_init=20)
y_pred = kmeans.fit_predict(self.encoder.predict(x))
y_pred_last = np.copy(y_pred)
self.model.get_layer(name='clustering').set_weights([kmeans.cluster_centers_])
# Step 2: deep clustering
# logging file
import csv
logfile = open(save_dir + '/dec_log.csv', 'w')
logwriter = csv.DictWriter(logfile, fieldnames=['iter', 'acc', 'nmi', 'ari', 'loss'])
logwriter.writeheader()
loss = 0
index = 0
index_array = np.arange(x.shape[0])
for ite in range(int(maxiter)):
if ite % update_interval == 0:
q = self.model.predict(x, verbose=0)
p = self.target_distribution(q) # update the auxiliary target distribution p
# evaluate the clustering performance
y_pred = q.argmax(1)
if y is not None:
acc = np.round(metrics.acc(y, y_pred), 5)
nmi = np.round(metrics.nmi(y, y_pred), 5)
ari = np.round(metrics.ari(y, y_pred), 5)
loss = np.round(loss, 5)
logdict = dict(iter=ite, acc=acc, nmi=nmi, ari=ari, loss=loss)
logwriter.writerow(logdict)
print('Iter %d: acc = %.5f, nmi = %.5f, ari = %.5f' % (ite, acc, nmi, ari), ' ; loss=', loss)
# check stop criterion
delta_label = np.sum(y_pred != y_pred_last).astype(np.float32) / y_pred.shape[0]
y_pred_last = np.copy(y_pred)
if ite > 0 and delta_label < tol:
print('delta_label ', delta_label, '< tol ', tol)
print('Reached tolerance threshold. Stopping training.')
logfile.close()
break
# train on batch
# if index == 0:
# np.random.shuffle(index_array)
idx = index_array[index * batch_size: min((index+1) * batch_size, x.shape[0])]
self.model.train_on_batch(x=x[idx], y=p[idx])
index = index + 1 if (index + 1) * batch_size <= x.shape[0] else 0
# save intermediate model
if ite % save_interval == 0:
print('saving model to:', save_dir + '/DEC_model_' + str(ite) + '.h5')
self.model.save_weights(save_dir + '/DEC_model_' + str(ite) + '.h5')
ite += 1
# save the trained model
logfile.close()
print('saving model to:', save_dir + '/DEC_model_final.h5')
self.model.save_weights(save_dir + '/DEC_model_final.h5')
return y_pred
# setting the hyper parameters
init = 'glorot_uniform'
pretrain_optimizer = 'adam'
dataset = 'mnist'
batch_size = 2048
maxiter = 2e4
tol = 0.001
save_dir = 'results'
import os
if not os.path.exists(save_dir):
os.makedirs(save_dir)
update_interval = 200
pretrain_epochs = 500
init = VarianceScaling(scale=1. / 3., mode='fan_in',
distribution='uniform') # [-limit, limit], limit=sqrt(1./fan_in)
#pretrain_optimizer = SGD(lr=1, momentum=0.9)
# prepare the DEC model
dec = DEC(dims=[train_x.shape[-1], 500, 500, 2000, 10], n_clusters=10, init=init)
dec.pretrain(x=train_x, y=train_y, optimizer=pretrain_optimizer,
epochs=pretrain_epochs, batch_size=batch_size,
save_dir=save_dir)
...Pretraining...
Epoch 1/500
...
Epoch 494/500
34300/34300 [==============================] - 0s 8us/step - loss: 0.0086
Epoch 495/500
34300/34300 [==============================] - 0s 8us/step - loss: 0.0086
Epoch 496/500
34300/34300 [==============================] - 0s 9us/step - loss: 0.0085
Epoch 497/500
34300/34300 [==============================] - 0s 9us/step - loss: 0.0085
Epoch 498/500
34300/34300 [==============================] - 0s 9us/step - loss: 0.0086
Epoch 499/500
34300/34300 [==============================] - 0s 8us/step - loss: 0.0085
Epoch 500/500
34300/34300 [==============================] - 0s 8us/step - loss: 0.0085
Pretraining time: 183.56538462638855
Pretrained weights are saved to results/ae_weights.h5
dec.model.summary()
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
input (InputLayer) (None, 784) 0
_________________________________________________________________
encoder_0 (Dense) (None, 500) 392500
_________________________________________________________________
encoder_1 (Dense) (None, 500) 250500
_________________________________________________________________
encoder_2 (Dense) (None, 2000) 1002000
_________________________________________________________________
encoder_3 (Dense) (None, 10) 20010
_________________________________________________________________
clustering (ClusteringLayer) (None, 10) 100
=================================================================
Total params: 1,665,110
Trainable params: 1,665,110
Non-trainable params: 0
_________________________________________________________________
dec.compile(optimizer=SGD(0.01, 0.9), loss='kld')
y_pred = dec.fit(train_x, y=train_y, tol=tol, maxiter=maxiter, batch_size=batch_size,
update_interval=update_interval, save_dir=save_dir)
...
Iter 3400: acc = 0.79621, nmi = 0.77514, ari = 0.71296 ; loss= 0
delta_label 0.0007288629737609329 < tol 0.001
Reached tolerance threshold. Stopping training.
saving model to: results/DEC_model_final.h5
pred_val = dec.predict(val_x)
normalized_mutual_info_score(val_y, pred_val)
0.7651617433541817
DEC 算法与上述两种方法相比,效果最好。研究人员发现,进一步训练 DEC 模型可以达到更高的性能(NMI 高达 87)。
查看英文原文: Essentials of Deep Learning: Introduction to Unsupervised Deep Learning (with Python codes)
感谢冬雨对本文的审校。




