
之前已经参加过几次 QCon 峰会,不过今年 QCon 2014 上海峰会对我来说比较特别,不再只是一名听众,而是第一次登台演讲。感觉的确不太一样,一来是身份从听众变成了讲师,二来是因为成了讲师,让我接触到更多的业内朋友,也遇到了更多的提问、咨询。会后已经有一段时间了,还有朋友提出想了解更多的技术知识。看来会上行云流水的半个小时,未能把一个技术点讲述明白,我想还是总结一下,让技术圈朋友们对 Bitmap 这个技术点加深点理解。
一、背景
a) 历史的困惑
每个技术点背后都有一系列业务的故事,透过我这次讲的 Bitmap,我们可以看到历史上始终困扰营销领域的一个核心问题。著名广告大师约翰•沃纳梅克提出:我知道我的广告费有一半浪费了,但遗憾的是,我不知道是哪一半被浪费了 (翰•沃纳梅克,始创第一家百货商店“沃纳梅克氏”,被认为是百货商店之父;同时也是第一个投放现代广告的商人)。为什么会出现这样的浪费呢?我个人觉得还是对营销所面向的人群理解不透彻导致的。因此,营销领域一直期待技术系统能够提供一种能力,可以高速、灵活的、从海量用户中,找出最合适的那一部分。
b) 时代的曙光
需求的背后,是技术的不断进步。最近几年,信息技术的突飞猛进,给解决问题带来了一线曙光。大数据处理技术和系统,已经渗透到当今每一个行业和业务职能领域,成为重要的生产因素。人们对于海量数据的挖掘和运用,预示着新一波生产率增长和消费者盈余浪潮的到来。使用各种各样新型的技术武器(Hadoop、Spark、Storm 等等开源工具),我们近乎完美的捕捉到这个时代的浪潮:将人群的属性分析、行为分析、甚至是心理分析深入到相当精深的地步。
c) 业务驱动力
业务需求对技术的要求是永无止境的。我们需要更好的工具:
- 更快速的分析,一次任务就需要个把小时,甚至需要一天,数据的产出,无法支持我们业务的快速调整。
- 更灵活的分析工具,应该比 Oracle 或者 IBM 的 BI 系统更好,我们需要有多维交叉的计算能力,而不只是简单的几种统计数字。
- 更轻量级的系统,动辄几十台服务器组成的 Hadoop 集群,我们真是无法负担啊,成本太高昂了。
二、现有技术分析
a) 硬币的两面
我们最初非常仰仗 Hadoop,不过后来发现 Hadoop 不是银弹,核心的问题不是 Hadoop 出了错,而是我们对 Hadoop 的本质理解稍显片面。Hadoop 是一种高吞吐量系统,其设计和实现中采用了小操作合并,基于操作日志的更新等提高吞吐量的技术。硬币的两面在使用过程中逐步显现:高吞吐量和低延迟是两个矛盾的目标。既然要低延迟,上 Storm,上 Redis。在 2011 年,我们在 Hadoop 的批处理的基础上,为我们的统计平台增加了实时计算能力。下面这张图,大约反映了一种典型的架构系统:如何使用两种流派的计算系统解决计算问题。
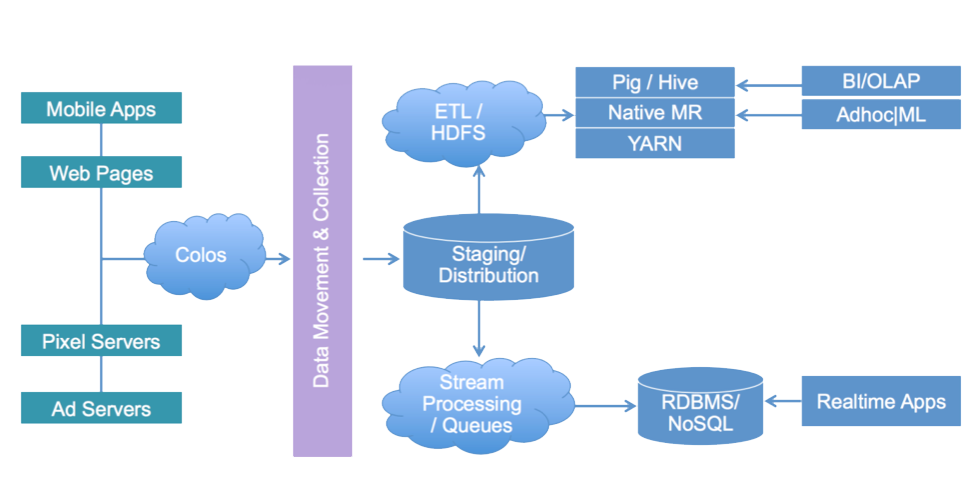
看似完美的解决了高吞吐量和低延迟的矛盾,但是,核心业务问题没有得到解决:业务人员需要在海量数据中,使用多维交叉的方式,不断计算手里的数据。批量处理还是需要几个小时,甚至一天才能出一批数据。流式处理只能算当前的数据,历史数据无法回朔。
b) 白天鹅:传统技术的缺陷
看待硬币的两面是一种视角,这也许是一种平庸的视角。如果不看硬币,把硬币当做金属,寻找、发现、创造一种新的铸造硬币的方法,又是另外一种视角。2012 年,我们跳出了传统的视角(例如 Hadoop、或者 Storm 的改造),重新观察我们的问题。经过分析,我们得到一个结论:我们需要做的,是创造第三种计算方式,而不是继续在两种计算方式中挖潜。
如果我们把传统系统看作白天鹅,并把高速的、灵活的多维交叉分析当作飞行的目标,我们应该看看白天鹅为什么飞得累,飞得慢?
第一个技术障碍是高 I/O 开销,包括磁盘 I/O 和网络 I/O 两种主要开销。传统的数据存储都是以行的方式存储在磁盘文件中,而传统的文件系统又都是为大文件连续读写做优化的。假如我们要做多维交叉分析,我们分析一下系统的运作过程:
- 根据查询需求,定位到数据在某些文件。
- 从文件系统中提取文件。这里产生了磁盘开销。
- 如果是分布式系统(例如普遍使用 Hadoop),这里产生了高昂的网络传输开销。
- 然后需要按行的方式,从文件中提取数据。这里会碰到一个非常隐蔽的问题,每行数据中会有大量的信息对本次查询无任何意义(可能造成非常巨大且不幸的浪费)。
第二个技术障碍是计算相对低效。传统计算中,把大量的 CPU 和内存放到了数据装载,数据过滤等等(上面的浪费就是例子)。
新一代的计算体系的设计重点是降低整体 IO,并尽量让计算资源用在真正有价值的点上。
c) 从白天鹅到黑天鹅
我们用了三种法宝克服上面的缺陷,以提高整体计算效率:
- 预处理:尽量降低低效的文件读取在整个计算过程中的比重。
- 压缩:使用高压缩比的压缩算法将需要计算的数据压缩到最小(同时不影响计算精度)。
- 内存计算:将计算需要的全量数据全部一次性装载入内存,这样可以最大程度的将 CPU 的计算能力用于业务计算。
那么到底是哪只黑天鹅将以上的优点集于一身内?它就是 Bitmap。
三、Bitmap 的秘密
a) Bitmap 如何做到多维交叉计算的?
Bit 即比特,是目前计算机系统里边数据的最小单位,8 个 bit 即为一个 Byte。一个 bit 的值,或者是 0,或者是 1;也就是说一个 bit 能存储的最多信息是 2。
Bitmap 可以理解为通过一个 bit 数组来存储特定数据的一种数据结构;由于 bit 是数据的最小单位,所以这种数据结构往往是非常节省存储空间。比如一个公司有 8 个员工,现在需要记录公司的考勤记录,传统的方案是记录下每天正常考勤的员工的 ID 列表,比如 2012-01-01:[1,2,3,4,5,6,7,8]。假如员工 ID 采用 byte 数据类型,则保存每天的考勤记录需要 N 个 byte,其中 N 是当天考勤的总人数。另一种方案则是构造一个 8bit(01110011)的数组,将这 8 个员工跟员工号分别映射到这 8 个位置,如果当天正常考勤了,则将对应的这个位置置为 1,否则置为 0;这样可以每天采用恒定的 1 个 byte 即可保存当天的考勤记录。
综上所述,Bitmap 节省大量的存储空间,因此可以被一次性加载到内存中。再看其结构的另一个更重要的特点,它也显现出巨大威力:就是很方便通过位的运算(AND/OR/XOR/NOT),高效的对多个 Bitmap 数据进行处理,这点很重要,它直接的支持了多维交叉计算能力。比如上边的考勤的例子里,如果想知道哪个员工最近两天都没来,只要将昨天的 Bitmap 和今天的 Bitmap 做一个按位的“OR”计算,然后检查那些位置是 0,就可以得到最近两天都没来的员工的数据了,比如:
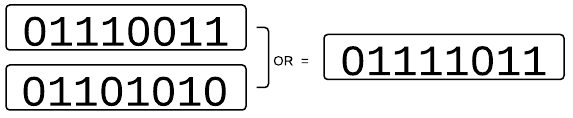
再比如,我们想知道哪些男员工没来?我们可以在此结果上再“And”上一个 Bitmap 就能得到结果。
b) Bitmap 如何做到高速运算的?
回忆一下前面,浪费的有两个部分:其一是存储空间的浪费,Bitmap 比文件强多了,但是仍然有浪费的嫌疑。它需要保存到外部存储(数据库或者文件),计算时需要从外部存储加载到内存,因此存储的 Bitmap 越大,需要的外部存储空间就越大;并且计算时 I/O 的消耗会更大,加载 Bitmap 的时间也越长。其二是计算资源的浪费,计算时要加载到内存,越大的 Bitmap 消耗的内存越多;位数越多,计算时消耗的 cpu 时间也越多。
对于第一种浪费,最直觉的方案就是可以引入一些文件压缩技术,比如 gzip/lzo 之类的,对存储的 Bitmap 文件进行压缩,在加载 Bitmap 的时候再进行解压,这样可以很好的解决存储空间的浪费,以及加载时 I/O 的消耗;代价则是压缩 / 解压缩都需要消耗更多的 CPU/ 内存资源;并且文件压缩技术对第二种浪费也无能为力。因此只有系统有足够多空闲的 CPU 资源而 I/O 成为瓶颈的情况下,可以考虑引入文件压缩技术。
那么有没有一些技术可以同时解决这两种浪费呢?好消息是有,那就是 Bitmap 压缩技术;而常见的压缩技术都是基于 RLE(Run Length Encoding,详见 http://en.wikipedia.org/wiki/Run-length_encoding )。
RLE 编码很简单,比较适合有很多连续字符的数据,比如以下边的 Bitmap 为例:
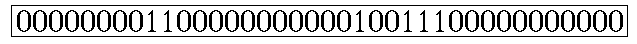
可以编码为 0,8,2,11,1,2,3,11
其意思是: 第一位为 0,连续有 8 个,接下来是 2 个 1,11 个 0,1 个 1,2 个 0,3 个 1,最后是 11 个 0(当然此处只是对 RLE 的基本原理解释,实际应用中的编码并不完全是这样的)。
可以预见,对于一个很大的 Bitmap,如果里边的数据分布很稀疏(说明有很多大片连续的 0),采用 RLE 编码后,占用的空间会比原始的 Bitmap 小很多。
同时引入一些对齐的技术,可以让采用 RLE 编码的 Bitmap 不需要进行解压缩,就可以直接进行 AND/OR/XOR 等各类计算;因此采用这类压缩技术的 Bitmap,加载到内存后还是以压缩的方式存在,从而可以保证计算时候的低内存消耗;而采用 word(计算机的字长,64 位系统就是 64bit)对齐等技术又保证了对 CPU 资源的高效利用。因此采用这类压缩技术的 Bitmap,保持了 Bitmap 数据结构最重要的一个特性,就是高效的针对每个 bit 的逻辑运算。
常见的压缩技术包括 BBC(有专利保护),
WAH( http://code.google.com/p/compressedbitset/)
和 EWAH( http://code.google.com/p/javaewah/ )。在 Apache Hive 里边使用了 EWAH。
c) Bitmap 在大数据计算上的能力?
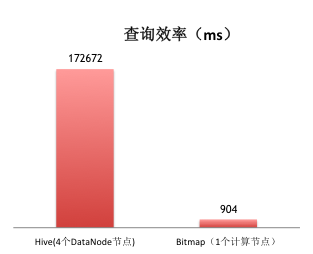
我们用一个 TalkingData Analytics 中用户留存的例子来看 Bitmap 如何做到用户回访的统计。比如想知道某个应用,昨天新增的用户中,有多少人今天又开启了应用(次日留存)。使用过 Hive 的工程师,不难理解下面语句的含义:

同时,我们使用 Bitmap 技术后,同样实现上述的计算,对比测试显示出效率的差异是巨大的:
d) 引入 Bitmap 技术后,分析系统可能的处理流程大体是什么样的?
- 数据收集系统收集设备上传数据,然后分发给实时处理系统和批量处理系统;
- 实时系统采用自有计数器程序,或者基于 Storm 之类中间件的计数器程序,计算各类简单计数器,然后批量(比如 30s 或者 1min)更新到 Redis 或者 HBase 之类的存储;前端供应计数器类数据的服务通过访问后台计算器程序或者是计数器存储来给报表系统提供服务;
- 批量系统对该批的数据按用户进行去重生成 / 修改某天 / 某个应用的活跃用户 Bitmap,同时可以根据需要,将机型、地域、操作系统等等各种数据提炼成属性 Bitmap,备用。
- 报表中针对分析需要,提取各种 Bitmap(用户、属性……Bitmap),高效的利用 CPU/ 内存,通过组合 And/Or/Not 等基础计算,最终完成多维交叉计算功能,反馈客户结果。
四、黑天鹅的未来
TalkingData 提供给客户大数据下高速的多维交叉计算能力,还只是一个开始。在大数据时代,技术的发展必将推动业务的进化。TalkingData 的未来在于提供客户更快速、更便捷、更灵活的数据服务。黑天鹅也遇到了更多的问题,需要逐一解决。
a) 内存映射文件
比如即便用了优化的压缩技术,Bitmap 从文件中迁移到内存中的速度相对来说还是短板。例如系统构建初期,我们曾经把 Bitmap 存储在 Mysql 中,感觉还不错,不过随着数据量的增加,随机读的问题越来越严重:大约一次查询中,90% 的时间全部被 Mysql 占去(某些开销是挺浪费的,例如 Mysql 一次 SQL 的执行计划,怎么都需要 1ms 左右)。下一步,我们计划采用“内存映射文件”技术来解决这个问题。
内存映射文件与虚拟内存有些类似,通过内存映射文件可以保留一个地址空间的区域,同时将物理存储器提交给此区域,只是内存文件映射的物理存储器来自一个已经存在于磁盘上的文件,而非系统的页文件,而且在对该文件进行操作之前必须首先对文件进行映射,就如同将整个文件从磁盘加载到内存。
由此可以看出,使用内存映射文件处理存储于磁盘上的文件时,将不必再对文件执行 I/O 操作,这意味着在对文件进行处理时将不必再为文件申请并分配缓存,所有的文件缓存操作均由系统直接管理,由于取消了将文件数据加载到内存、数据从内存到文件的回写以及释放内存块等步骤,使得内存映射文件在处理大数据量的文件时能起到相当重要的作用。
b) 分布式 Bitmap 计算
可以预见到的第二个 Bitmap 计算的难题是:我们有可能遇到“需要非常巨大的计算能力才能解决的问题”。举个简单的例子,假如一个客户想看几年的数据指标,那么有可能需要提取出成千上万个,甚至几十万个 Bitmap,放到内存中进行计算,这是相当恐怖的要求。
TalkingData 第一代 Bitmap 计算引擎,虽然利用了诸如“Fork-join”技术最大程度的利用 CPU/ 内存,但是遇到上面的计算要求,肯定还是力不从心。第二代 Bitmap 计算引擎,采用分布式计算:把一个需要非常巨大的计算能力才能解决的问题分成许多小的部分,然后把这些部分分配给许多计算机进行处理,最后把这些计算结果综合起来得到最终的结果。
请大家注意一下 Bitmap 天生的特性,其实一个 Bitmap 代表了一个集合,同时它支持的计算中,就是集合计算中的“And/OR/Not”。大家可以在这个 wiki 上复习一下“集合代数”的知识。
http://zh.wikipedia.org/wiki/ 集合代数
这里面有一些给分布式 Bitmap 计算提供了理论基础,下面这张图表达的是分配律:
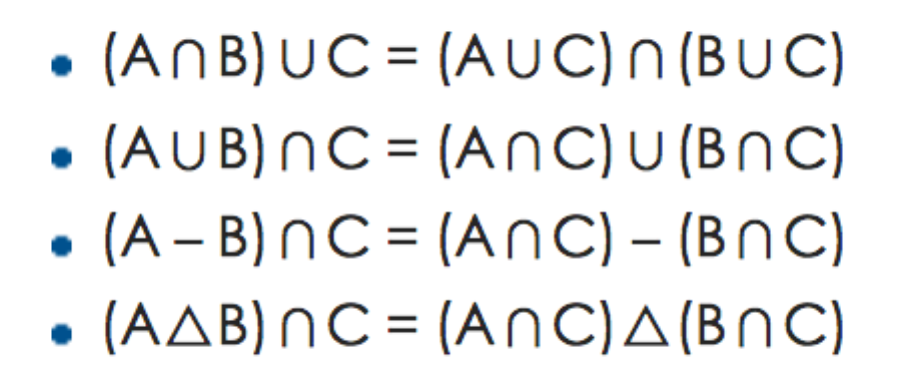
假如我们有三个集合,分别是 A(去过美国的游客),B(去过中国的游客),C(使用 IOS 设备的游客)。现在业务人员要求找出,既去过美国,又去过中国,同时又使用 IOS 设备的游客。最直接的计算是:(A∩B)∪C,但是假如我们在分布式系统的视角下,我们可以分拆后的计算是:(A∪C)∩(B∪C),可以在两台计算节点上分别计算,再汇总到中心节点获得最后结果。基于这些集合代数计算的原理,我们可以把复杂的多维交叉分析,分解成很多小单元计算,分配到不同的服务器上计算,再做汇总计算得到结果。
原理简单,但是执行起来还是有很多困难的,比如数据倾斜、分拆计算优化、在高并发下解决负载均衡……
任重道远!
总结
当我最近阅读 30 年前的 Paper 的时候,我发现科学领域的宽广和深度。大约在 30 年前,天体物理学家利用基数计算(Bitmap 就是一种基数计算)来解释恒星数据,除此以外,还有时间序列分析和频谱分析。我们今天研究某个产品在时间上的规律,还有一个人群使用产品的频率特征,不就是这些计算科学在商业世界的再实践吗?
从历史观的角度来看,这些计算科学很早就已经存在,而现代多数程序员由于需要学习各种各样的 IDE、语言,忽视了这些基础算法的学习和实践,要持续、有效地发展个人和团队,后者恰恰更重要。Bitmap 技术不但让我们支持了业务的发展,也证明了我们走在一条正确的路上:透过现象看本质,从基础的算法出发,吸收各种技术流派的思想,创造属于自己的技术,反馈和服务于技术社区。这就是 TalkingData 的技术底蕴。
感谢郭蕾对本文的策划和审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论