Bill Vorhies 是 Data Science Central 的编辑部主任,自 2001 年以来一直当数据科学家和商业预测建模师。
Bill Vorhies 不久前写了一篇文章《 AI 背后的数据科学》,他分享的观点很新颖,经作者授权,InfoQ 翻译并发布。
对于那些对 AI 感兴趣但还没有深入研究的传统数据科学家,下面是对数据科学技术的简要概述,这些数据科学技术在通俗报纸中被称为人工智能(AI)。
Data Science Central 与其他人已经撰写了相当多的关于构成 AI 的各种类型的数据科学的文章。但是 Bill Vorhies 仍然听到很多人询问关于 AI 的问题,好像它就是单一的实体。他表示,不是这样的。AI 是一个数据科学技术的集合,在这一点上,开发甚至都没有特别好地集成,或易于使用。然而,在这些领域中,他们仍然取得了很大的进步,并受到了大众媒体的关注。
这篇文章并不是一个深入的研究,而是进行粗略的介绍,以便你了解这领域的研究进展和发展趋势。如果你是一位传统数据科学家,读过一些文章,但仍然没有把这些拼图拼起来建立全面的认识,你可能会发现这是一种整合你当前的知识,甚至发现你想关注哪个目标并致力于此的方式。
以下是正文。
AI 只是数据科学部件的总和
构成 AI 的数据科学“部件”分为以下几类。这里有所重叠,但都是详细的主题,你会在媒体上看到。
- 深度学习
- 自然语言处理
- 图像识别
- 强化学习
- 问答机
- 对抗性训练
- 机器人
这些都是独立的学科(好吧,深度学习的类别实际上还包含一些其他)。AI 只是这些部件的总和。它们只是由一大批创业公司和主要参与者创造的一些真正奇妙的应用非常松散地结合在一起。当它们一起工作时,例如 Watson、或 Echo/Alexa、或者在使用自驾车,那么它们应该可以超过组成它们的部分的总和,然而情况并非如此。如何集成这些不同技术仍然是最大的挑战之一。
我们的 AI 必须做什么?
当向初学者解释这一点时,我总是认为,从 AI 需要具备什么类似人类能力的拟人化描述开始的话,还是有所帮助的。
- 观看:这是定格画面和视频图像的识别。
- 听取:通过文本或口头语言接收输入。
- 说话:以相同的语言或甚至外语有意义地响应我们的输入。
- 像人类一样做出决定:提供建议或新知识。
- 学习:根据其环境中的更改来改变其行为。
- 移动:以及操作物理对象。
您可以立即开始看到,当今新兴的 AI 许多商业应用,只有这些能力中的一部分。但我们期待的是,未来有更复杂的应用能具备几乎所有这些能力。
今天出现的许多 AI 的商业应用程序只需要这些功能中的一些。但是我们期待的更复杂的应用程序将需要几乎所有这些。
将人类能力转换为数据科学
这里确实有点凌乱。这些能力中的,每个不一定与其基础数据科学一一对应。但是,要真正了解现今 AI 正在发生着什么,理解数据科学如何与这些要求相匹配是最重要的。作为一张图解,它们的匹配或多或少像这样的:

深度学习发生了什么?
您可能已经注意到,我们的图表中缺少“深度学习”。这是因为它是上面讲到的递归神经网络和卷积神经网络的汇总类别。人工神经网络(ANNs)是自 80 年代以来的最高水平,并且一直是用于解决标准分类和回归问题的标准数据科学机器学习工具包的一部分。
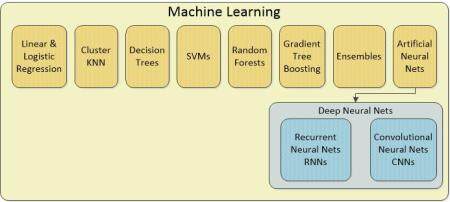
最近发生的事情是,我们大量增加并行处理,使用 GPU(图形处理单元)而不是传统的英特尔芯片,允许我们实验的 ANN 有几十个甚至超过一百个隐藏层的版本。这些隐藏层就是我们为什么将这些类型成为“深度”的原因,因此也就成了“深度学习”的说法。添加隐藏层意味着乘法计算的复杂性,这就是为何我们不得不等待硬件赶上我们的雄心。
至少有 27 种不同类型的 ANN,但最重要的是卷积神经网络(CNN)和递归神经网络(RNN),没有它们,图像识别和自然语言处理将是不可能的任务。
数据科学的简要讨论
要公正对待这些基础数据科学技术,就需要阅读多篇文章。在本文中,我们将给你最简略描述,以及一些能查看更为完整信息的链接。
卷积神经网络(CNN): CNN 是所有类型的图像和视频识别、面部识别、图像标记的核心,并可在帮助自动驾驶在行人中识别停车标志。它们非常复杂,难以训练,而你不需要指定具体的功能(像猫有毛皮、尾巴、四条腿等那样),你需要在一个 CNN 上按字面意思展示数百万猫科的示例就可以成功。海量的训练数据是一个巨大的障碍。有关 CNN 的更多信息,请查看深度学习的大败笔:正确答案,错误原因。
递归神经网络(递归): RNN 是自然语言处理(NLP)的中心,也是游戏和类似的逻辑问题的中心。与CNN 不同,它们将信息处理为时间序列,其中每个随后的数据片段在某种程度上依赖于之前的片段。它可能不明显,但语言属于此类别,因为下一个字符或下一个字在逻辑上与前一个字符相关。RNN 可以工作在字符、字或甚至长段级别,这使得它们能够完美提供可预期的长篇回答您的客户服务问题。RNN 处理文本问题的理解以及形成复杂的响应,包括翻译成外语。计算机能够赢得国际象棋和围棋,RNN 功不可没。阅读这篇文章递归神经网络:AI 凳子的第三条最不明显的腿来查看更多关于RNN 的参考信息。
生成式对抗神经网络(GANN): CNN 和RNN 都受到同样问题的困惑,即需要庞大的、繁重的数据量以便训练,要么识别停车标志(图像),要么了解如何回答您关于如何打开该帐户(语音和文本)的问题。GANN 能够保证显著减少训练数据并提高精度。他们通过互相较量。这里有一个好故事,关于训练卷积神经网来识别假法国印象派的艺术赝品。简而言之,一个CNN 被真正的法国印象派画作来训练,所以它应该认识真品。其他对抗性CNN,称为生成式对抗神经网络,实际上被赋予创造印象派绘画赝品的任务。
CNN 通过将像素值转换为复杂的数值向量来执行图像识别的任务。如果你向后运行它们,那就是从随机数值向量开始,它们可以创建一个图像。在这种情况下,NN 生成赝品创造图像,试图欺骗尝试学习如何检测赝品的 CNN。他们互相较量,直到生成器(赝品制造者)产生的图像如此完美,以至于 CNN 无法将它们从原件和已经扳平的两个对抗网络区分出来。同时,设计用于确定来自赝品的原件的 CNN 已经在检测赝品方面进行了极好的培训,而没有对数百万伪造的法国印象派大师进行训练这一不切实际的要求。总之,它们就是从其所在的环境中学习。
问答机(QAM): QAM,是我们为像 IBM 的 Watson 之类起的一个相当不起眼的名字。这些都是海量知识库,经过训练,可以在其知识库中找到独特关联,并为它们以前从未见过的复杂问题提供答案。当普通搜索返回您潜在答案的列表时,QAM 必须返回单一的最佳答案。
这是一个 NLP 和复杂搜索的混搭,其中 QAM 构建关于问题的可能含义的多个假设,并且基于加权证据算法返回最佳响应。
QAM 需要人类加载大量关于需要研究的主题的数据,并且人类必须训练并维护知识库。然而,一旦建立完成,它们已被证明是在癌症检测(与 CNNs 结合)领域的专家、医学诊断、发现材料和化学品的独特组合,甚至教高中学生如何编程。总之,无论有大量的知识需要专家解释,QAM 可以是大脑或至少是我们 AI 的关联记忆。查阅这三篇文章: Watson 究竟是什么?、最新的Watson 能够做什么?以及使用Watson 启动新的AI 业务和服务30 个有趣的想法可以看到一些优秀的参考。
强化学习系统(RLS)
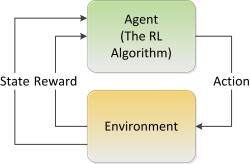
RLS 是一种训练系统以识别对其环境直接响应的最佳结果的方法。这里没有单一的算法,而是一组定制应用程序。 RNN 可以用作 RLS 中的一种类型的“代理”。RLS 是自驾车和类似设备的核心技术,不需要语言界面。本质上,这是机器可以从中学习并记住在特定情况下采取的最佳行动的方法。当你的自驾车决定黄灯亮起时停车,而不是通过,一个 RLS 被用来创造学习的行为。阅读强化学习和人工智能来查看更多相关信息。
机器人
机器人领域对于 AI 是重要的,因为它是 AI 数据科学在现实世界中显现的主要方式。大多数机器人是简单和非常复杂的工程。机器人技术背后的 AI 主要是强化学习。
脉冲神经网络(又名神经拟态计算)
通常,我们第二代 AI 主要是基于硬件进步,使我们能够使用算法,如在以前根本不可行的神经网络。但所有这一切都在迅速发展,我们正处于进入第三代 AI 的前沿。
第三代 AI 将基于脉冲神经网络,也称为神经拟态计算,因为它试图更密切地模仿人类大脑实际工作的方式。改变的核心是围绕这样的事实:脑神经元不经常彼此通信,而是在信号的峰值。挑战是找出一个消息在这个电子脉冲应该如何编码。
到目前为止,研究尚处于中期阶段。我只知道它在商业应用的两个实例。可能有更多的秘密应用仍然不为人知。很多投资和科研工作者涌入这一新世界。它还需要一种全新类型的芯片,这将意味着另一场硬件革命。
当这一天来临时,我们有如下的期望:
- 它们可以从一个来源学习,并应用到另一个。它们可以对其所在的环境进行概括。
- 它们可以记住。任务一旦学会,可以回忆并能应用于其他数据。
- 它们更节能,开辟了一条小型化的道路。
- 它们从自己的环境中学习,没有监督,只有很少的例子或观察。这些使它们能够进行快速学习。
要了解更多关于脉冲神经网络的信息,请参阅这两篇文章:超越深度学习:第三代神经网络和更多关于第三代脉冲神经网络的文章。
跟上 AI 的发展
跟随这些技术和这两个趋势来与 AI 俱进:
- AI 的商业化,目前由于它(第二代)的存在,使得一切实际上几乎和专业一样快速,而且大量初创公司涌入这一市场。有可能会像美国在 20 世纪 20 年代的电气化一样普遍。
- 注意脉冲神经网络的进步,使这一切都更令人惊叹。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




