
做运维的同学都知道,运维一定离不开 Zabbix、Nagios 之类的监控软件。目前,类似的软件在监控和数据采集方面已经做到了极致,但是在报警处理上并没有很完美的解决方案,比方说,经常出现高质量报警湮没在海量报警之中等情况。本文不探讨监控系统的配置优化,只探讨监控系统按照它的逻辑发出报警之后我们该做点什么。
报警遇到的痛点
报警风暴,高质量报警湮没在海量报警之中;
出现报警后没人认领,需要在在工作的 IM 群中沟通;
运维人员进行运维操作必定会引起某些报警,会给不知道真相的同学带来困惑;
海量报警恢复之后,运维人员很难在第一时间知道还剩下哪些报警没有恢复;
MySQL 出现了慢查询报警,DBA 还需要登录数据库去查看;
有些报警优先级不高,明明可以白天处理的,却在晚上第一时间发出来;
同一个报警会反复报出来。
背景现状
云极星创作为综合性云服务提供者,既要做公有云的监控,也要负责私有云的监控。我们的研发团队已经建立了比较完善的 OpenStack 监控体系,并且使用了多种监控工具;因为云极星创的运维团队和客户分布在全国各地,所以该监控体系的物理位置也是分散。在公有云场景下,报警需要按照物理位置或者应用类型发给不同的运维同学、运营同学和管理层。在私有云场景下,报警也需要推送给相应的客户。当前,我们主要采用微信为主,短信为辅的报警方式。
使用微信的优缺点
使用微信的优点:
- 基本免费;
- 图文并茂、字节数限制较为宽裕;
- 微信客户端和服务器端交互方便。
使用微信的缺点:
- 可用度依赖腾讯的服务器,因此特意增加了对微信服务器接口的监控,发现接口有问题之后会发短信报警;
- 客户端需要保持联网,没有送达报告,因此系统提供汇总表功能。
优秀报警处理系统的三要素
- 在合适的时间发给合适的人;
- 尽可能的提供更多的信息,使得接警人员在不开电脑情况下第一时间能大概知道哪里出了问题;
- 减少围绕报警的人员沟通成本。
实施方案
架构概览
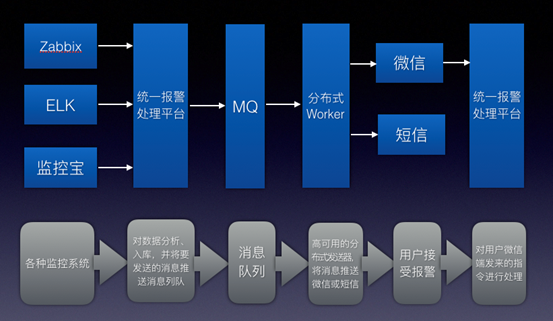
报警分类
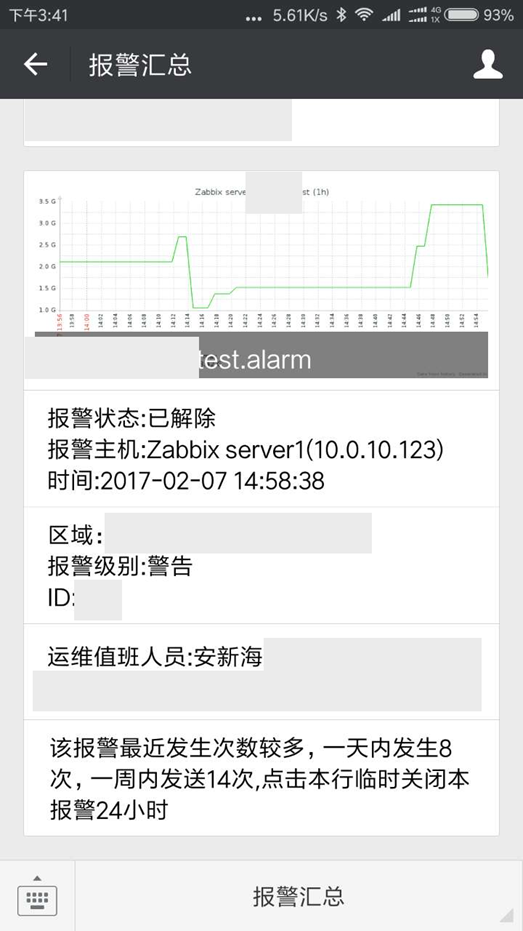
普通报警:根据排班表发送给值班的运维同学,低级别的报警会延时发给对应的应用开发。
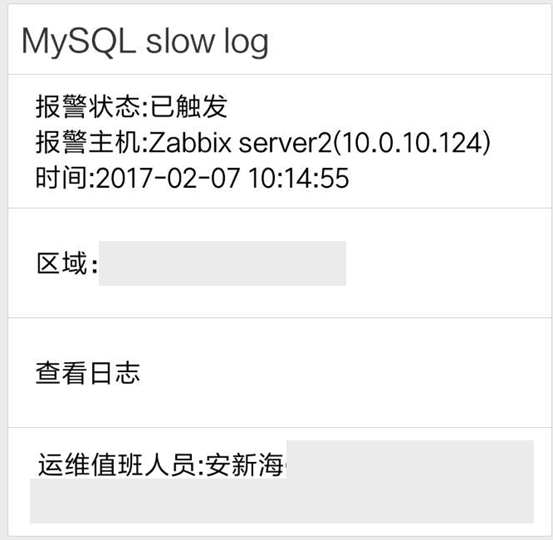
ELK 日志报警:用户在微信端可以查看
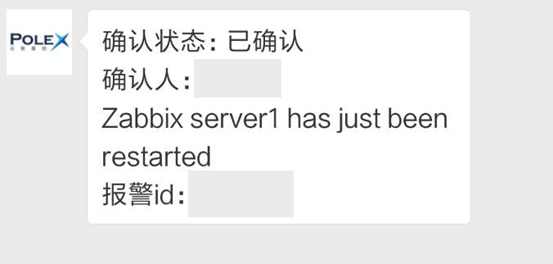
收到报警:确认、反馈和汇总
报警确认:当用户点击确认按钮之后,对应的人会收到确认信息。
报警处理结果反馈
汇总表:提供批量确认功能

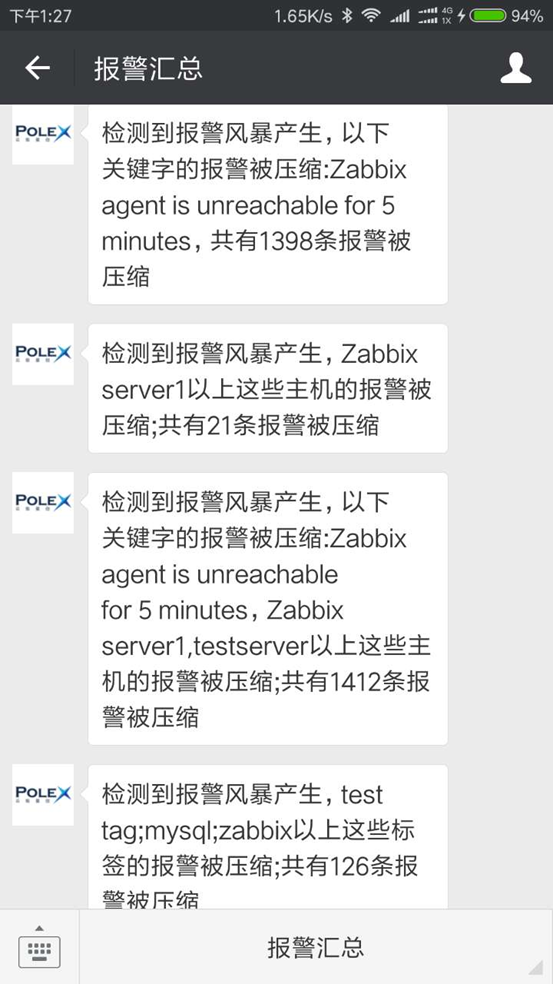
报警收敛
基于关键字、主机名、Tag 的复合报警收敛
报警升级
如果报警在一定时间没被确认也没有自动回复,会有一个报警升级动作

微信 vs 短信 两个平台
所有微信接口做了加密处理,防止非授权用户访问和关注公众号。
短信平台主要用来发送灾难级别的报警、微信 API 接口的报警,系统本身可用度的报警。
总结
1、系统使用的成果
云极星创之前使用的报警方案是邮件加短信的方式,在报警触发之后,运维交流群会有大量围绕报警的沟通,并且经常发生报警风暴,将短信发送平台堵塞,在本系统投入使用之后,基本上所有的沟通都在系统内进行。随着丰富的报警附加信息,减少了二线运维工程师在处理故障时候开机登录系统的次数。
2、研发历程
本系统开发历时半年左右,基本上随着云极星创的发展而发展壮大起来,初期的想法是因为各家短信发送平台随着国家打击电信诈骗的政策影响,变得越来越不好用,所以诞生了使用普及率非常高的微信来替代短信的想法。
第一个版本就是原封不动的推送 Zabbix 报警信息,随着公有云规模的不断扩大,报警不断增多,另外私有云客户也在不断的增加,需要接受报警的人员也越来越分散,围绕报警的沟通成本越来越高。
因此本系统的功能点都是围绕着我们运维同学在处理报警时候遇到的痛点进行开发而成。经过半年的发展,在我们内部已经将运维报警做成了运营的报警。
3、未来发展:
(1)、报警系统和工单系统以及 CMDB 做关联;
(2)、快速实现故障根因定位;
(2)、告警排行分析报表;
(备注:文中截图来自于预发布环境下的运维测试)
作者简介
安新海,云极星创高级运维工程师。十年军旅生涯,曾在解放军某部负责过大型云平台建设。退役后一直从事互联网云平台运维工作,擅长 Zabbix、OpenStack、VMware 等系统的运维、调优。
感谢木环对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论