XML 消息交换是大多数 web 服务的基础,包括 SOAP 和 REST 方式。使用 XML 导致了一些缺陷,包括性能的潜在问题,但是这也提供了抽象层,允许参与交换各方之间的松耦合。为了使松耦合真的起作用,你需要定义交换中的 XML 文档的结构,便于验证文档的正确性。W3C 的 XML Schema 定义语言(在本文后面部分简写为“模式”)是用于消息结构定义的最常用的方法。
大多数 web 服务不与 XML 文档直接交互,而是通过 web 服务工具包的数据绑定转换层。这方便了应用开发人员,因为这意味着他们可以直接使用选定编程语言的数据结构。但是数据绑定过程需要处理模式数据类型、结构和编程语言数据类型、结构之间的不匹配问题,这些都会为应用制造麻烦。如果你想要你的 web 服务提供一致的、平台兼容性(这也是使用 web 服务的首要意义所在),你需要设计模式定义以避免潜在的问题——或者至少意识到使用存在问题的模式的风险。
在本系列文章中,我们将探讨一下来自于模式和 web 服务数据绑定之间不匹配问题的各个方面。在第一篇文章中,我们从最基础的角度开始,看一看简单数据类型和相关的问题。
数字表示
数字是业务数据中最基本的类型。既然数字如此重要,你可能会认为模式在这一领域运转的很稳定和一致。从某种抽象意义上来说,的确是这样——但是当 web 服务工具包应用模式时,你仍然会遇到多种问题。
其中一个问题是内建模式数字类型的多样性。图 1 展示了本领域模式数据类型的组成部分。为了便于理解,运用特殊化方法——这棵树从上到下的分支走得越远,数据类型就越特殊化。在顶层,是 anySimpleType 类型,其下面是基本的数据类型 float、decimal 和 double。Float 和 double 是最终类型,符合 IEEE 对浮点书的标准定义,也提供了跨 web 服务的良好互操作性:每一个主流编程语言都支持 32 位浮点数字,匹配浮点数规范,支持 64 位浮点数字,匹配 double 模式规范,因此,web 服务工具包可以简单的把这些类型映射到原生语言类型。可能在特殊值(非数字、正无穷、负无穷、正零、负零)的编程语言文字表达上和模式之间有细微的区别,不过工具包可以很容易的处理转换。
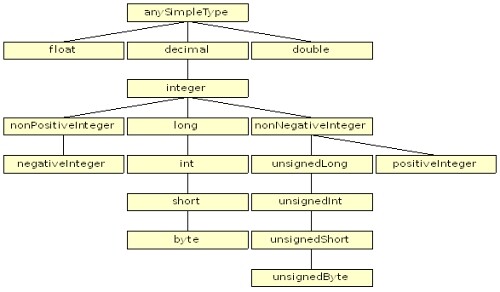
图 1. 模式数字类型
当你来到 decimal 分支的时候,你就会遇到问题。Decimal 本身被定义为一个任意长度小数位数的字符串,包括可选的正负号和小数点。Integer 是 decimal 的直接子节点,表示 decimal 的一个子集,包含可选的正负号,但不允许小数点。Integer 的子节点做了进一步约束,nonPositiveInteger 和 nonNegativeInteger 限制了其值大于零或者小于零,long 则把取值范围限制在 64 位 2 进制补码表示。Int、short 和 byte 进一步限制了范围,分别是 32 位、16 位和 8 位 2 进制补码表示,而 unsigned 各种变形则是同样位数的非负值。
所有主流编程语言支持匹配 long、int 和 short 模式类型的值,但是其他变形则有可能出现问题。举例来说,Java 不包含对应 unsignedLong 和 unsignedInt 的内建数据类型。Java web 服务框架一般使用特殊的类而不是原生类型来应付这种语言的缺失,但是这使得 web 服务接口多少有些笨拙,同时可能引起性能问题(因为计算时内建类型一般远远快于对象类型)。
甚至 decimal 和 integer 也会引起问题。大多数 Java 工具包使用标准的 java.lang.BigDecimal 和 java.lang.BigInteger 类来处理这些类型,导致了糟糕的性能,但是支持无大小限制的值。.Net 则使用 128 位固定长度的表示法,限制了值域(模式规范所许可的),但是提供了相对较好的性能。
模式数字类型令人困惑和不协调(比如,为什么存在 nonPositiveInteger 而没有 nonPositiveDecimal 类型?),一般只是用于某种语法上的便利(因为范围可以通过 simpleType 限制实现)。鉴于此,在你的模式定义中,最好避免使用大多数类型,特别是那些用于 web 服务的。尽量使用某些特定的类型(double 和 float 用于实数,long 和 int 用于整数),因为这些与编程语言的原生类型保持一致。如果你需要使用超过这些类型范围或者精度的值,请记住 decimal 和 integer 由于依赖实现可能无法提供你所想要的,你可以考虑使用字符串,在应用程序代码中处理这种转换。
时间问题
时间相关的值是使用模式的另一个常见问题来源。模式定义了九种独立的时间相关的数据类型,全部基于 Western Gregorian 日历形式。不像数字值,时间相关的类型彼此之间不是特殊化的关系——相反,它们都是直接继承自通用类型 anySimpleType。
应用最广泛的时间类型是 dateTime、date 和 time。这三种数据类型共享同一种表示形式,dateTime 最完整。下面是一个 dateTime 值的例子,我写这篇文章的当前时间是:“2008-09-08T15:38:53”。Date 使用相同的表示法,只是去掉了‘T’和后面的小时——分钟——秒(在本例中,剩下"2008-09-08"),time 值则去掉了“T”之前的所有东西,只保留小时——分钟——秒(“15:38:53”)。
到目前为止很简单,是吧?让人感到困难的地方在于这些值的实际解释。日期和时间根据你所在的地点而变,也就是时区。举例来说,当我在新英格兰州写这篇文章时,比格林尼治时间提前 12 小时,比太平洋西部时间(美国西海岸所用时区)提前 19 小时。当前时间的 dateTime 值是"2008-09-08T15:38:53",西雅图时间则是"2008-09-07T20:38:53"。
很多程序需要指定日期和时间,允许把一个值关联到另一个。模式通过允许使用附加时区提示的手段满足这种需求。这种时区提示既可以使用字母‘Z’表明是格林尼治时间,也可以使用相对格林尼治时间的偏移量。因此,所有 dateTime 值(和很多其他变形)都可以用于指示同一时间:“2008-09-08T15:38:53+12:00”、"2008-09-07T20:38:53-08:00"或者 “2008-09-08T03:38:53Z”。
但是模式并不强制你指定时区提示,没有这种限制,日期 / 时间只能被解释为世界上任意地区的准确时间。对于某些程序,这种性质可能恰好是你想要的——举例来说,某人的生日日期通常被视为一个特定的日子而不管是哪个地区,同样的,人们以世界各地的当地时间为准庆祝罗马制新年——但是对于其他程序,就会产生大麻烦。考虑电话会议的例子,所有参与各方都需要调整会议时间到本地时间。
不幸的是,模式不允许你区分何时需要完全指定的日期 / 时间、何时需要无分区的值(至少不是通过 web 服务工具包解释的方式——你可以使用 simpleType 限制,但通常会被工具包忽略)。因此模式在这一点上的含糊不清意味着工具包需要处理存在和不存在时区提示的两种值。
这种处理两种值的需求在解释阶段让人很头痛,特别是因为编程语言一般基于绝对时间值实现 date/time 类型。没有办法把缺少时区提示的模式值正确的转化为绝对时间。当然,这无法阻止工具包处理类似值。在大多数情况下,他们把这些值当作本地时区值转化,这通常也是你所期望的——但是,当它不是时,由此导致的问题很难定位。
由于时区造成的问题对于 date 类型特别麻烦。多数情况下,人们认为日期是日历上的一个固定刻度。举例来说,当你签署法律文件时,你一般会写上日期。如果你同意一个新项目,一般会有一个计划完成日期(通常都是空想)。买东西时有时需要出示驾照表明年龄,店员会查看你的生日日期,并与年龄限制作比较。在所有这些情况下,日期被认为具有日期分辨功能,时区之间的差别被忽略了。但是,模式日期类型使用相应的时区提示,如 dateTime 和 time 类型。这种做法分割了模式日期和常用日期。一般来说,这会通过把日期转化为 00:00(午夜,一天的开始时刻)时间表示法来解决,不管是什么时区。但是如果你把日期值使用本地时区打印出来,你可能会发现它与文档里最初指定的值不同。
如果模式分别定义了带有时区提示和不带时区提示的日期\时间类型,应用程序就会易于挑选其所需的。否则,工具包难以处理一个模式上存在缺陷的日期 / 时间表示法。Java 的 JAXB 2.0 采用了可能是最综合的办法来处理这个问题,通过一个特殊的类(javax.xml.datatype.XmlGregorianCalendar)来处理所有模式日期 / 时间类型。这种方法保存了表示法的所有细节,只是把解释过程交给了开发人员。其他工具包一般使用缺省办法,例如假定是本地时区。
既然有这么难解的问题,最好的处理办法是只为那些完全指定时区提示的值使用日期 / 时间类型,并保证生成的所有文档都包含时区提示。大多数 web 服务工具包会自动为你生成时区提示,所以最后一步很简单。要求输入文档也使用时区提示则困难些,特别是因为文档会经过多步处理。如果你想要不陷入错误的转化假定所引起的问题中,最好的解决办法是在模式表达中使用字符串类型,这样的话,web 服务工具包会把值传递给你的应用程序代码,而不会解释其值。
如果你需要无时区的日期 / 时间值(如生日日期),最好也使用字符串类型。从提供一个精确表示的角度看,这不是很令人满意,但是避免了 web 服务工具包把无分区的值解释成本地时区。
引用
应用程序内部使用的数据结构经常包含组件之间的多个连接,包括交叉引用和间接关联。另一方面,XML 天生是树形结构的。在 XML 中,通过包含可以很容易的表示一对多的关系,但是表示其他关系则困难。甚至是一对多关系也效率低下。考虑一个文档列举了顾客的订单历史,每一订单都有对应的付款和发送地址,但是这些地址通常是重复的。如果你对每一份订单都插入地址,则最终文档里会有大量冗余信息。
引用可以用于解决 XML 树形结构的限制。引用的思想是在 XML 文档中定义事物一次,包含一个唯一标识码。每当其他数据想要使用该定义时,使用标识码创建一个引用。
模式直接支持两种引用。第一,使用 ID 类型,定义元素标识符,可以使用 IDREF 或者 IDREFS 类型从文档中任意处关联。ID/IDREF 关联的优点是非常简单——标识符就是名字,任何类型的元素都可以在模式中定义 ID 值。缺点是使用全局上下文,因此没办法说某个 IDREF 使用的值肯定采用特定元素类型定义,用作 ID 值的名字在文档中必须唯一(即使是跨类型的元素)。一些 web 服务工具包支持使用 ID/IDREF 关联来表示数据结构内部的引用(包括 JAX-WS/JAXB 2.0,Apache Axis2 使用 JiBX 数据绑定时),其他工具包(如.Net、Axis2 使用 ADB)则不是,把 IDREF 值简单的当作文本字符串。
模式支持的第二种引用是 key/keyref 关联。ID/IDREF 关联使用数据类型定义,key/keyref 关联则是模式定义的结构组成部分。这允许 key/keyref 关联比 ID/IDREF 更具有表现力,包括定义 key 值唯一的上下文环境。但是,因为 key/keyref 关联的设计意图更倾向于文档验证而不是结构化,它们太复杂,数据绑定框架一般也不会用于做 XML 数据和数据结构之间的转化。
因此,如果你想在 XML 文档中插入关联并由 web 服务工具包处理,唯一的办法就是 ID/IDREF。一些工具包现在直接支持这种关联,其他的则只是把标识符看做字符串,但是你可以编写应用程序代码来交叉引用标识符和值、构建自己的关联。
结论
在本文中,我们探讨了在 web 服务中使用最常用数据类型时会遇到的问题。除了本文提到的还有很多其他模式数据类型(一共 42 种!),其中一些会引起其它问题。总的来说,使用 web 服务模式定义的最好办法是避免使用过度特殊化的类型(除了那些匹配常用编程语言类型的数字类型),当你想完全控制这些值时,你可以使用字符串类型转换这些值。
值得一提的是,虽然本文中讨论的一些问题可以通过数据绑定框架处理的更好一些,但是很多问题来源于模式本身。特别是,数据 / 时间类型难以使用,甚至可能因为缺少时区和非时区之间的区别来导致错误。虽然可以像 JAXB 那样使用 XmlGregorianCalendar 类把这种混乱交给用户处理,但这实在不是一种解决办法。
关于作者
Dennis Sosnoski 是一名基于 Java 的 SOA 和 web 服务领域的顾问和培训讲师。他在软件开发领域工作超过 30 年,近 10 年专注于服务器端的 XML 和 Java 技术。Dennis 是开源项目 JiBX XML 和相关 JiBX/WS 框架的主要开发人员,也是 Apache Axis2 web 服务框架的开发者。同时,他也是 JAX-WS 2.0 和 JAXB 2.0 的专家组成员。有关他的培训和咨询服务请登陆网站 http://www.sosnoski.co.nz 。
给 InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。




