
命令和查询责任分离(CQRS)是由Greg Young 提出的一种将系统的读(查询)、写(命令)操作分离为两种独立子系统的架构模式。命令通常是异步执行的,并存储在一个事务型数据库中,而读操作则通常是最终一致的,并且数据来自于解正规化的视图。
本文在此提出并为读者展示一种为CQRS 系统创建一套RESTful API 的方式。这种方式结合了HTTP 的语义、REST API 基于资源的风格,并能够处理分布式计算的某些问题,例如最终一致性和并发性。
此外我们还提供了一套原型API ,它建立于Greg Young 编写的 m-r CQRS 原型之上,后者也被称为SimplestPossibleThing。m-r 可以认为是 CQRS 原型的事实标准,它鼓舞了许多团队采用并创建 CQRS 系统。虽然这个 m-r 原型很简单,但它已经能够展示在现实世界中使用 RESTful CQRS 系统的某些机遇和挑战了。
我们在将下一部分审阅 m-r 的领域模型,随后对相关特性的 API 设计进行一些探索。最后,我们将对一些所做的选择展开讨论,并且讨论一些 RESTful m-r 的概念和理论内容。
m-r 领域
m-r 模型是一个经过简化的库存管理系统的领域模型,你可以创建新库存物品(假设它是某种类型的产品),重命名或取消激活(即 _ 逻辑删除 _)它们。被取消激活的物品将不再为用户所见,而所有活动的物品都可以被获取,并且能够看到每个物品的所有细节。你也能够增加或减少这些库存物品,指定所加入或减少的物品数据。换句话说,在建立库存量之后,就可以开始使用这个系统了。
用户将通过同步的查询来查看物品列表或是物品细节,对于物品状态的修改将通过命令来实现。在现实世界中,命令应该是异步执行的,但由于代码中使用了内存中的事件总线(Event Bus)及事件处理函数,因此在最终实现中命令都是同步执行的。
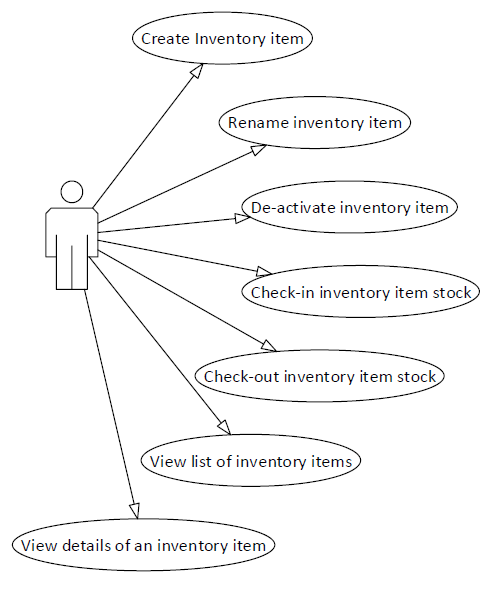
m-r 模型实现了 CQRS:命令和查询被分别存储在不同的地方,并且各自由系统中完全不同的部分进行处理。
除了 CQRS 之外,m-r 也使用了事件溯源(Event Sourcing)作为它的持久化机制。在这种方式中,对于领域模型的修改会被捕获为一系列的事件,这些事件会按照它们被调用的顺序存储起来。为了获取某个模型的当前状态,需要将所有事件按照它们发生的顺序进行重播。换句话说,模型中实体的状态信息是不会被持久化的。举例来说,如果我们创建了一个库存物品,随后将它重命名两次,那么我们将会得到一个 InventoryItemCreated事件和两个InventoryItemRenamed事件,这些事件都会被保存在事件存储(Event Store)中。
事件是连续的,并且每个事件都带有一个版本号,用以在并发时进行检查。举例来说,如果某个库存物品在版本 2 的基础上进行重命名,但正好有另一个重命名发生在同一个物品上,并使它的当前版本变为 3,那么这种情况就会导致并发异常。
命令与领域事件通常是一对一的关系,当 _ 调用 _ 了某个命令之后,领域模型会发起并存储一个事件。领域事件是事件溯源的基石,它和跨多个边界上下文(bounded context)的事件不同,往往粒度更细,并且只包括所需的最小数量的信息。因此,它并不是一个适合于在不同的边界上下文之间进行集成的工具。除了使用一个进程内的事件总线之外,m-r 还用到了一个内存中的事件存储。这个存储本质就是一个哈希表,它使用模型的 id 作为键,并且持续跟踪模型中发生的任何事件。
如欲了解 CQRS 和事件溯源的更多信息,你可以阅读 Greg Young 的这本迷你书。
创建一套上层的REST API
如果你倾向于先去感受一下最终的实现,可以在这里看一下一个目前(暂时性)可运行的原型。我们鼓励你使用fiddler 或者浏览器自带的开发工具去检查一下这个简单的示例中的HTTP 请求。在 GitHub 上可以找到包括这套 API 和一个基本的 Angular 应用的源代码。不过我们还是要强调,它的实现方式和使用的技术并非关键所在,读者更应该关注于设计方式及 HTTP 的展现。
公开领域的构造
对于这个 API 层来说,最重要的责任是将底层的领域建模为资源,并通过 HTTP 语义暴露出来。在这个过程中,API 层将创建一个公共领域,它由资源(以及它们的唯一标识符 ->URL)以及输入和输出的消息所构成。底层的领域越简单,这个公开领域和底层领域的相似程度就越高。
(单击图片以放大)

在这个例子中,我们创建的公开领域与底层的领域还是比较相似的,但即使是这种简单的领域,我们也不能够直接将底层的领域暴露出去:这可能造成领域的内部实现被泄漏出去,而且领域内部也不一定包含API 层所需的全部属性。比方说,所有的内部命令都会用一个_ 整数_ 来表示并发时所需的版本号,而在公开领域中则用_ 字符串_ 表示这个属性。我们稍后将会使用这个属性作为ETag,而根据HTTP 规格要求,ETag 必须是不透明的。
简单来说,我们所创建的公开领域表现了内部的领域类,但又不完全相同。这种公开领域通常被称为一个视图模型(Vide Model)。这个术语并不太准确,因为这种表达方式感觉上对公开领域有些排斥,将它视为一种“哑”模型,因此我们倾向于使用一个新术语“输出模型”(output model)。它将被应用到输入和输出消息中(命令和输出模型)。
资源
我们很自然地想到应该有一个 InventoryItem资源,因此我们将领域中的这个单根实体暴露为一个单独的资源,可以用 **/api/InventoryItem方便地进行表示。每个库存物品将用/api/InventoryItem/{id}** 进行表示,m-r 使用了全局唯一标识符(GUID)作为 Id。
使用这个单独的根对象就可以完整的表现我们的领域了。还有一种方式是使用 **/api/InventoryItem/{id}/Stock** 这个资源作为添加和删除库存量(即签入或移除物品)的方法。从本质上说它们没有什么高下之分,无非是哪种方式能够更好地表现资源而已。由于第一种方式更加简便,因此我们就使用这种方式。
(单击图片以放大)

查询
我们需要两个查询: GetInventoryItems和GetInventoryItemDetails。这里我们将通过两个 GET 方法 **/api/InventoryItem和/api/InventoryItem/{id}** 暴露出这两个查询功能。
GetInventoryItems方法能够获取仅包含了物品名称和Id的一个列表,它会根据ACCEPT头决定返回 JSON 或是 XML(ASP.NET Web API 能够支持这一功能)。如果某个资源适合于缓存,那么所有的 GET 请求都有可能返回缓存数据。GetInventoryItems返回InventoryItemListDataCollection作为输出消息。虽然可以通过数据内容的哈希生成 ETag,不过这里我们选择将列表中每一项的Id和名称进行哈希后得到的结果作为 ETag 返回给客户端(例如浏览器)。客户端可以选择将资源缓存起来,并针对 ETag 使用If-Non-Match进行条件请求。我们选择将资源的max-age设为 0,因此客户端的 GET 会始终使用条件请求,不过也可以选择设置一个人为的过期时间。
GET /api/InventoryItem HTTP/1.1 Accept:application/json, text/plain, */* Accept-Encoding:gzip,deflate,sdch If-None-Match:"LdHipfxR7BsfBI3hwqt2BLsno8ic98KmrIA1y67Nnw4="
返回结果
HTTP/1.1 304 Not Modified ETag: "LdHipfxR7BsfBI3hwqt2BLsno8ic98KmrIA1y67Nnw4="
GetInventoryItemDetails方法会返回某个库存物品的细节,包括Id,Name和CurrentCount属性,最后一项属性记录了当前的库存数量。虽然内部领域的读取模型(read model)包含了版本号,但如果将某个数值类型的版本号直接作为 ETag 会产生安全性问题,因为客户端可以轻易地猜出下一个数值。因此,我们选择了使用高级加密标准(AES)对版本号进行加密后,作为InventoryItemDetails方法的 ETag 输出。
为每个操作都重新实现 ETag 对于 API 层来说有些负担过重,因此我们定义了一个IConcurrencyAware接口:
public interface IConcurrencyAware { string ConcurrencyVersion { get; set; } }
每个支持 ETag 的输出模型都要实现这个接口,当 API 层看到某个输出模型支持这个接口时,就会读取版本号并设置 ETag 值。另一方面,当 API 层对条件式 GET 请求进行响应时,会将生成的 ETag 与客户端在If-None-Match头中传入的值进行比较。所有这些操作都可以通过一个单独的全局 filter 实现:ConcurrencyAwareFilter。
需要注意的是,添加、删除或者重命名某个库存物品时应该使物品列表的缓存失效。请看下面的例子(条件式 GET 请求的逻辑是在浏览器端完成的,不需要特别编写代码实现):
GET /api/InventoryItem HTTP/1.1 If-None-Match:"CWtdfNImBWZDyaPj4UjiQr/OrCDIpmjVhwp8Zjy+Ok0="
返回结果是一个状态码为 200 的完整响应,并且包含了一个新的 ETag 值:
HTTP/1.1 200 OK Cache-Control:max-age=0, private Content-Length:68 ETag:"0O/961NRFDiIwvl66T1057MG4jjLaxDBZaZHD9EGeks=" Content-Type:application/json; charset=utf-8; domain- model=InventoryItemListDataCollection; version=1.0.0.0; format=application%2fjson; schema=application%2fjson; is-text=true ...
请注意 Content-Type 头包含了额外的参数,这是对于“媒体类型的五种级别”(或者简称 5LMT)概念的一种实现,这种方式不是将所有信息都塞到一个单独的令牌(token)中,而是使用不同的参数来表达对用户有用的不同级别的数据,能够表达不同级别的有用信息。下文会对这个主题做进一步的讨论。
命令
查询通常会映射到 GET 方法,而命令则需要映射到 POST、PUT、DELETE 和 PATCH 方法。将 HTTP 谓词映射到 CRUD 操作是一种流行的观念,但在真实世界中很少能够将谓词和数据库操作一一对应。实际上,REST API 并不在对持久化存储之上的一个简单封装,相反,它是指引用户去了解业务领域、操作与工作流的一扇门。因此它必须能够不依赖于特定的谓词去表达某个维度的意图。
一种常见的方式是使用远程过程调用(RPC)风格的资源,例如 **/api/InventoryItem/{id}/rename**。虽然它看上去确实去除了对某种谓词的依赖,但它违反了 REST 面向资源的表现能力。我们需要记住,资源是一个名词,HTTP 谓词则表示动词和动作,而自描述的消息(REST 的宗旨之一)则是表达其它维度信息和意图的手段。实际上,在 HTTP 消息中所包含的命令就应该足以描述任何人为的操作了。但是,完全依赖于请求体中的消息也有它自己的问题,因为请求体通常是作为流传递的,要在辩认出它的具体操作之前获取整个请求体有时是不可能做到的,而且这也不是一种明智的做法。这里,我们将展示一种基于 5LMT 中的第 4 级别(即领域模型)处理请求的方式,命令的类型将包含在Content-Type头中的某个参数内。
PUT /api/InventoryItem/4454c398-2fbb-4215-b986-fb7b54b62ac5 HTTP/1.1 Accept:application/json, text/plain, */* Accept-Encoding:gzip,deflate,sdch Content-Type:application/json;domain-model=RenameInventoryItemCommand
这样就能够将请求正确地输送给服务端相应的处理方法了。那这种方式是否将过多的信息泄露给客户端了呢?并非如此。输入输出消息的 schema(以及名称)是公开领域的一部分,客户端必须能够完整地访问到它,因此它们依赖于 schema 也是在我们所预期的。
至于客户端的实现只用了最少量的代码,这里使用了一个AngularJS的装饰(decorator_)_ 封装了 **$http服务,它能够读取这个原型的返回内容,并且能够在Content-Type** 头中加入额外的参数信息。只要保持 JavaScript_ 构造函数 _ 的名称不变就没有问题。
我们已经解决了辨认当前正被调用的方法的问题,接下来需要将命令按照语义映射到相应的 HTTP 谓词。在将命令映射到谓词时,选择正确谓词的关键不仅仅在于语义,同样要考虑幂等性(至于谓词的安全性则无需顾忌,因为任何一个命令谓词都是不安全的)。PUT、PATCH 和 DELETE 是幂等的,而 POST 则不是幂等的(多次调用一个幂等的谓词的结果与仅调用一次是相同的)。
CreateInventoryItemCommand
从 CRUD 范式的角度来说,CreateInventoryItemCommand很自然地适用于 POST 方法。(这里只显示重要的头信息)
POST /api/InventoryItem HTTP/1.1 Content-Type:application/json;domain-model=CreateInventoryItemCommand {"name": "CQRS Book"}
返回的响应如下:
HTTP/1.1 202 Accepted Location: http://localhost/SimpleCQRS.Api/api/InventoryItem/ 109712b9-c3d5-4948-9947-b07382f9c8d9
该操作将在 location 头信息中返回这个将被创建的库存物品(因为所有操作都是异步执行的)的 URL 地址。
DeactivateInventoryItemCommand
如同前文所述,取消激活库存物品就代表一次逻辑删除。此外,删除操作是幂等的,因为多次删除一个库存物品的效果和一次删除是一样的。因此我们将使用 DELETE 选项作为取消激活某个物品的方式(该方法带有一个空的方法体)。
DELETE /api/InventoryItem/f2b75f21-001a-4eed-b8f3-35bf5e4e9b0d HTTP/1.1 Content-Type:application/json;domain-model=DeactivateInventoryItemCommand {}
返回的响应如下:
HTTP/1.1 202 Accepted
虽然也可以在方法体中传递 id,但在 URL 中已经提供了 id 信息。DeactivateInventoryItemCommand构造函数的唯一职责是正确地设置domain-model这个参数。
RenameInventoryItemCommand
RenameInventoryItemCommand比起其它命令来说更有趣一点。首先,重命名一个库存物品也就是进行修改,因此使用 PUT 谓词是最合适的。另一方面,如果你正在重命名某个物品时,你的同事也在尝试将其重命名为另一个名字的话会怎样呢?这就是一个并发问题。HTTP 通过If-Unmodified-Since和If-Match提供了对资源进行并发修改时的保护机制。因为我们使用了 ETag,因此就相应地设置If-Match:
PUT /api/InventoryItem/f2b75f21-001a-4eed-b8f3-35bf5e4e9b0d HTTP/1.1 Content-Type:application/json;domain-model=RenameInventoryItemCommand If-Match:"DL1IsUoH709K+N5TXFzlQeQI5arO8r/U0SzXcRhuXLc=" {"newName": "CQRS Book 1"}
AngularJs的 controller 会传递 ETag 值,并传入模型中,之后在条件式 PUT 请求时进行使用。如你所见,ETag**** 的值仅仅是对领域模型中版本号的一种表现,但我们对其进行加密以满足 HTTP 规格的需要。服务端获取到这个值之后进行解密并还原成版本号的数值。如果版本号不匹配,领域模型就会抛出一个ConcurrencyException异常,在 API 层的ConcurrencyExceptionFilterAttribute类捕获到这个异常之后,会以 HTTP 语义的方式表现该异常。
HTTP/1.1 412 Precondition Failed
这个例子很好地说明了 HTTP 的并发如何与 CQRS 的并发检查机制相结合。
CheckInItemsToInventoryCommand 和 RemoveItemsFromInventoryCommand
这两个命令就更加有趣了。我们将往库存中加入或删除一些物品。从某方面来说,这种操作是对库存物品的数量进行更新,因此可以将其实现为一个 PUT(也许 PATCH 更合适)方法。但因为这两个命令并非幂等(比如说,调用 CheckInItemsToInventoryCommand 两次应该添加两次库存),因此最适合的谓词实际上是 POST。
客户端将在Content-Type头信息中的参数中设置领域模型的名称,如同我们之前所见的一样。
POST /api/InventoryItem/f2b75f21-001a-4eed-b8f3-35bf5e4e9b0d HTTP/1.1 Content-Type:application/json;domain-model=CheckInItemsToInventoryCommand {"count": "230"}
返回的响应是一样的:
HTTP/1.1 202 Accepted
HTTP 的其它方面
实现 HTTP 的一些其它方面也会带来一些好处,HEAD 也是一个重要的谓词,它的响应结果和 GET 方法一样,但返回的响应体中不包括任何内容。我们为所有 GET 资源都实现了 HEAD 谓词,例如:
HEAD /api/InventoryItem HTTP/1.1 Accept:application/json, text/plain, */* Accept-Encoding:gzip,deflate,sdch
将返回
HTTP/1.1 200 OK
ETag: "LdHipfxR7BsfBI3hwqt2BLsno8ic98KmrIA1y67Nnw4="
具体在实现中会将 HEAD 请求转向给 GET 方法的处理函数,而框架本身会在最后负责移除返回的内容。这一系列实现都是自动触发的,因此在响应中可以正确地获得 ETag。
另一个需要实现的重要谓词是 OPTIONS,这个谓词可以用以生成 API 文档,不过我们这里只是简单的返回该资源支持的所有谓词:
OPTIONS /api/InventoryItem/f2b75f21-001a-4eed-b8f3-35bf5e4e9b0d HTTP/1.1
它将返回如下内容:
HTTP/1.1 200 OK Allow: GET,POST,OPTIONS,HEAD,DELETE,PUT Content-Length: 46 Content-Type: application/json; charset=utf-8; domain-model=String%5b%5d; version=4.0.0.0; format=application%2fjson; schema=application%2fjson; is-text=true ["GET","POST","OPTIONS","HEAD","DELETE","PUT"]
请注意,响应中的Allow头对于 OPTIONS 请求来说是必须的。不过 HTTP 规格本身并没有指定 OPTIONS 响应体中具体写法,因此我们就将允许的谓词作为一个字符串数组返回(注意,在 domain-model 参数中的String[]是经过UrlEncoded方法编码的结果)。可以利用这个谓词生成符合各种 schema 和语言需求的 API 文档。
除了这些方法之外的任何调用都会返回一个 _ 方法未找到(method not found)_ 或者 405 状态码,ASP.NET Web API 自身已经实现了这一功能:
PUT /api/InventoryItem HTTP/1.1 {}
它将返回:
HTTP/1.1 405 Method Not Allowed Allow: POST,GET,HEAD,OPTIONS {"message":"Http Method not supported"}
讨论
这一部分将详细叙述某些理论概念,以及我们的决定中一些比较困难,或者可能引起争议的部分。
可选的并发检查
在 m-r 最初的实现中,所有命令(除了CreateInventoryItemCommand,它已经隐式地包含了值为 0 的版本号)都包含一个整数型的CurrentVersion字段。而这个版本中将它们修改为可选的(即 C#中的可空类型)。
在一方面,服务端应该负责保证自身状态的完整性。因此它不能、也不应该依赖于客户端所提供的版本号。并发检查是作为一个特性提供给客户端的,而不是服务端用以保证模型完整性的机制。如果客户端关心并发行为,那它就可以选择性地发送版本号,这已经通过在 ETag 中的加密信息提供给它们了。要记住的是,并发检查与服务端的事件版本号是不同的概念,后者是服务端的内部实现机制。
另一方面,对于某些操作来说,并发检查是没有意义的。举例来说,如果两个客户端在同一时间(调用CheckInItemsToInventoryCommand方法)添加了 20 个库存物品,并且它们都具有版本号 n,那么其中有一个命令就会失败,但这种失败是不必要的,因为我们确实需要添加 40 个物品。这种问题在高访问量的情况下会被放大。想象一下,如果大量的用户涌入亚马逊网站去购买哈利波特的最新一期,在多数情况下他们都会遇到并发问题。
在 HTTP 中执行 PUT(和 PATCH)操作时会认为并发是一个可选的检查,这一点并非偶然。虽然并发检查可以异步执行,但我们需要尽力保证它必须同步执行,因此当我们返回状态码 202(已接受)时,就代表服务端已经确认了没有并发冲突情况的产生。
媒体类型的五种级别(5LMT)和创建新的媒体类型
在社区里常见的一种做法是创建新的媒体类型,通常称为打造新的媒体类型。举例来说:
Content-Type:application/vnd.InventoryItemListDataCollection.1.0.0.0+json;
这种使用非正规的方式表示某个媒体类型的子类型已经成为了一种通用的实践(已经实际上成为一种约定了),它将子系统分解为一些特定的、或者是正式的元素,并通过 + 号连接在一起。已经有些经过注册的媒体类型使用了这种约定,例如application/rss+xml和application/atom+xml。这两个示例处于媒体类型级别中的第 3 级别(或者叫做 schema 级别),而 application/xml 则处于第 2 级别(format 级别)。某种意义上说,application/atom+xml就是一种application/xml类型,它们使用相同的 format,而前者还指明了会使用 ATOM schema。
虽然这一约定会在未来版本的 HTTP 规格中得到认可,但它并未解决媒体类型不断增长的问题。首先,使用任何未注册的媒体类型都是 HTTP 规格所不提倡的,使用以上类型的Content-Type值也是一样。实际上,如果我们需要在所有 API 中为五个不同媒体级别的任意组合都注册一种媒体类型,那互联网号码分配局(IANA)恐怕需要发动一大批人去专门从事这个规模巨大的任务了。另一方面,许多客户端系统使用基于 dictionary 的媒体类型去处理这种请求,它们将不能够应付新创建的媒体类型。
因此使用 5LMT 能够允许现有的客户端继续按照之前的方式正常工作,而更先进的客户端则可以利用更高级别的信息,它们都是作为独立的实体提供的。
通过一个公开的领域保护内部领域是关键所在
将服务端的内部实现进行抽象对客户端来说是非常重要的。如同之前所述,为较小的领域所创建的公开领域和内部领域会比较相似,但即使是在 m-r 这个示例中,我们也不能够将内部领域直接暴露出来,而必须创建一个独立的模型,它表现了客户端能够接收和交互的信息。
我们还应该将公开领域文档化,并展现给客户端。这一方面的进展值得关注,因为已经有各种不同的方法和实践开始露出水面了(从 WADL 到 Swagger、RAML 和 RestDown 等等)。
结论
不仅通过一套 REST API 暴露 CQRS 是可能的,而且 HTTP 语义的丰富性也使得我们能够在它的基础上编写一套流畅而有效的 API。整个流程包括创建一个由命令和查询(输入输出消息)组成的公开领域,以及能够处理并发和缓存的各种资源。此外,我们还需要将内部领域的查询和命令映射为 HTTP 谓词,并且使用状态码以表现状态转换和异常。使用 5LMT 将有助于创建完全 RESTful,而不是远程过程调用风格的资源。所有这些都可以通过一个很小但可以运行的原型应用进行展现,该原型是通过 ASP.NET Web API 和 AngularJS 实现的。
关于作者
 Ali Kheyrollahi 是一位解决方案架构师、作者、博主、开源软件的作者和贡献者,目前任职于伦敦的一家大型电子商务企业。他对 HTTP、Web API、REST、DDD 和概念模型抱有极大的热情。而在处理实际的业务问题上又坚持实用性。他在这一行已有 12 年以上的经验,并在多个优秀企业工作过。他对于计算机视觉和机器学习领域有着深厚的兴趣,并且已经发布了多篇论文。在之前,他曾是一名医师,并作为一名非专科医生工作了 5 年。可以在这里找到他的博客,此外他在 twitter 上也非常活跃,可以通过 @aliostad 关注他。
Ali Kheyrollahi 是一位解决方案架构师、作者、博主、开源软件的作者和贡献者,目前任职于伦敦的一家大型电子商务企业。他对 HTTP、Web API、REST、DDD 和概念模型抱有极大的热情。而在处理实际的业务问题上又坚持实用性。他在这一行已有 12 年以上的经验,并在多个优秀企业工作过。他对于计算机视觉和机器学习领域有着深厚的兴趣,并且已经发布了多篇论文。在之前,他曾是一名医师,并作为一名非专科医生工作了 5 年。可以在这里找到他的博客,此外他在 twitter 上也非常活跃,可以通过 @aliostad 关注他。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论