遗留代码经常是腐臭的,每个优秀的开发者都想把它重构。而进行重构的一个理想的先决条件是,它应该包含一组单元测试用例,以避免产生回归缺陷。但是为遗留代码编写单元测试可不是件容易的事,因为它经常是一团糟。要想为遗留代码编写有效的单元测试,你大概得先把它重构一下。但要重构它,你又需要单元测试来确保你没有破坏任何功能。这种状况相当于要回答是先有鸡还是先有蛋。这篇文章通过分享一个我曾参与过的真实案例,描述了一种可以安全地重构遗留代码的方法。
问题描述
在这篇文章中,我将用一个真实案例来描述测试与重构遗留系统的有效实践。这个例子的代码由 Java 编写,不过这个实践对其它语言也是适用的。我将原始场景稍做了些改动以免误伤无辜,并稍做简化以便让它更容易被理解。这篇文章所介绍的实践帮助我重构了近期我所参与的一个遗留系统。
这篇文章并不打算介绍单元测试与重构的基本技巧。你可以通过阅读相关书籍以学习该主题的更多内容,如 Martin Fowler 的《重构:改善既有代码的设计》及 Joshua Kerievsky 的《重构与模式》。相对而言,这篇文章的内容将描述一些真实场景中的复杂性,我也希望它能够为解决这些复杂性提供一些有用的实践。
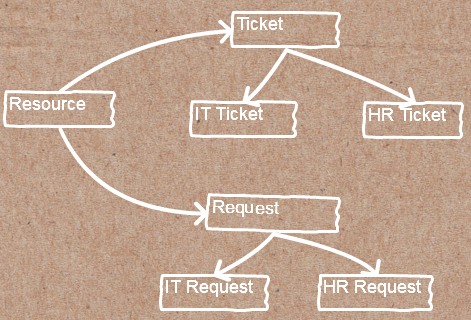
在这个案例中我将描述一个虚构的资源管理系统,其中资源指的是可指派给其任务的某个人。可以为某个资源指派一个 HR 票据(ticket)或者 IT 票据,也可以为某个资源指派一个 HR 请求或 IT 请求。资源经理可以记录某个资源处理某项任务的预计时间,而资源本身可以记录他们在某个票据或请求上工作的实际时间。
可以用饼图的方式表示资源的使用情况,图中同时显示了预计时间与实际花费的时间。
好像不太复杂嘛?不过,真实的系统能够为资源分配多种类型的任务,当然从技术上讲这也不是多么复杂的设计。但当我初次看到系统的代码时,我感觉自己似乎看到了一件老古董,从中看得出代码是如何从开始逐步进化的(或者不如说是退化的)。在一开始,这一系统仅能用来处理请求,之后才加入了处理票据以及其它类型任务的功能。某位工程师开始编写代码以处理请求:首先从数据库中获取数据,随后按照饼图的方式显示数据。他甚至没有考虑过要将信息组织为合适的对象:
class ResourceBreakdownService {
public Map search (Session context) throws SearchException{
//omitted twenty or so lines of code to pull search criteria out of context
and verify them, such as the below:
if(resourceIds==null || resourceIds.size ()==0){
throw new SearchException(“Resource list is not provided”);
}
if(resourceId!=null || resourceIds.size()>0){
resourceObjs=resourceDAO.getResourceByIds(resourceIds);
}
//get workload for all requests
Map requestBreakDown=getResourceRequestsLoadBreakdown (resourceObjs,startDate,
finishDate);
return requestBreakDown;
}
}
我相信你肯定被这段代码里的坏味道吓到了吧?比方说,你大概很快就会发现search并不是一个有意义的名称,还有应该使用 Apache Commons 类库中的CollectionUtils.isEmpty()方法来检测一个集合,此外你大概也会疑惑该方法返回的 Map 对象到底包含了些什么?
别着急,坏味道陆续有来。接下来的一位工程师继承了先人的衣钵,按照相同的方式对票据进行了处理,以下就是修改后的代码:
// get workload for all tickets
Map ticketBreakdown =getResourceRequestsLoadBreakdown(resourceObjs,startDate,
finishDate,ticketSeverity);
Map result=new HashMap();
for(Iterator i = resourceObjs.iterator(); i.hasNext();) {
Resource resource=(Resource)i.next();
Map requestBreakdown2=(Map)requestBreakdown.get(resource);
List ticketBreakdown2=(List)ticketBreakdown.get(resource);
Map resourceWorkloadBreakdown=combineRequestAndTicket(requestBreakdown2,
ticketBreakdown2);
result.put(resource,resourceWorkloadBreakdown)
}
return result;
先不管那糟糕的命名、失衡的代码结构以及其它任何代码美观度上的问题了。这段代码中最坏的味道就是它返回的Map对象了,这个Map对象完全是个黑洞,里面塞满了各种数据,但又不会提示你里面究竟包含的是什么。我只能编写了一些调试代码,将 Map 中的内容循环打印出来后,才看懂了它的数据结构。
在这个示例中,{} 代表一个 Map,=> 代表健值映射,而[] 代表一个集合:
{resource with id 30000=> [
SummaryOfActualWorkloadForRequestType,
SummaryOfEstimatedWorkloadForRequestType,
{30240=>[
ActualWorkloadForReqeustWithId_30240,
EstimatedWorkloadForRequestWithId_30240],
30241=>[
ActualWorkloadForReqeustWithId_30241,
EstimatedWorkloadForRequestWithId_30241]
}
SummaryOfActualWorkloadForTicketType,
SummaryOfEstimatedWorkloadForTicketType,
{20000=>[
ActualWorkloadForTicketWithId_2000,
EstimatedWorkloadForTicketWithId_2000],
}
]
}
这个糟糕的数据结构使得数据的编码与解码逻辑在直观上非常冗长乏味,可读性很差。
集成测试
希望我已经让你认识到这段代码确实是非常复杂的。如果在开始重构之前让我首先解开这团乱麻,然后理解每一行代码的意图,那我非疯了不可。为了保持我的心智健全,我决定采用一种自顶向下的方式来理解代码逻辑。也就是说,我决定首先尝试一下这个系统的功能,进行一些调试,以了解系统的整体情况,而不是一上来就直接阅读代码,并试图从中推断出代码的逻辑。
我所使用的方法与编写测试代码完全相同,传统的方法是编写小段的测试代码以验证每一段代码路径,如果每一段测试都通过,那么当所有的代码路径组织在一起之后,方法能够按照预期方式工作的机会就很高了。但这种传统方式在这里行不通, ResourceBreakdownService简直就是一个“上帝类”,如果我仅凭着对系统整体情况的一些了解就对这个类进行分解,很可能会造成很多问题 – 在遗留系统的每个角落里都有可能隐藏着众多不为人知的秘密。
我编写了以下这个简单的测试,它反映了我对整个系统的理解:
public void testResourceBreakdown(){
Resource resource=createResource();
List requests=createRequests();
assignRequestToResource(resource, requests);
List tickets=createTickets();
assignTicketToResource(resource, tickets);
Map result=new ResourceBreakdownService().search(resource);
verifyResult(result,resource,requests,tickets);
}
注意一下 **verifyResult()这个方法,我首先循环式地将 result 的内容打印出来,以找出其中的结构,随后verifyResult()** 方法根据这个结构对结果进行验证,确保其中包含了正确的数据:
private void verifyResult(Map result, Resource rsc, List<Request> requests,
List<Ticket> tickets){
assertTrue(result.containsKey(rsc.getId()));
// in this simple test case, actual workload is empty
UtilizationBean emptyActualLoad=createDummyWorkload();
List resourceWorkLoad=result.get(rsc.getId());
UtilizationBean scheduleWorkload=calculateWorkload(rsc,requests);
assertEquals(emptyActualLoad,resourceWorkLoad.get(0));
assertEquals(scheduleWorkload,resourceWorkLoad.get(1));
Map requestDetailWorkload = (Map)resourceWorkLoad.get(3);
for (Request request : requests) {
assertTrue(requestDetailWorkload.containsKey(request.getId());
UtilizationBean scheduleWorkload0=calculateWorkload(rsc,request);
assertEquals(emptyActualLoad,requestDetailWorkload.get(request.getId()).get(0));
assertEquals(scheduleWorkload0,requestDetailWorkload.get(request.getId()).get(1));
}
// omit code to check tickets
...
}
用临时方案绕过障碍
以上测试用例看起来简单,但实际却隐含了许多复杂性。首先,ResourceBreakdownService().search方法与运行时紧密相关,它需要访问数据库、其它服务,或许还有些不为人知的依赖项。而且和许多遗留系统一样,这个系统也没有建立任何单元测试的架构。为了访问运行时服务,唯一的选择就是启动整个系统,这不仅造成巨大的开销,而且也带来了很大的不便。
ServerMain类启动了整个系统的服务端功能,这个类也是个老古董了,你完全可以从中观察到它的进化过程。这个系统的编写时间已经超过 10 年了,当时还没有 Spring 、 Hibernate 这些东西, JBoss 和 Tomcat 也才刚刚冒头。因此那些勇敢的先驱们不得不手工打造了许多工具,他们创建了一个自制的集群、一个缓存服务、一个连接池以及其它许多东西。之后他们在某种程度上引入了 JBoss 和 Tomcat(但不幸的是他们仍然保留了那些手工艺品,导致了现在的代码中存在着两种事务管理机制以及三种连接池)。
我决定将ServerMain复制到TestServerMain类中,但运行TestServerMain.main()方法产生了以下失败信息:
org.springframework.beans.factory.BeanInitializationException: Could not load
properties; nested exception is
java.io.FileNotFoundException: class path resource [database.properties] cannot
be opened because it does not exist
at
org.springframework.beans.factory.config.PropertyResourceConfigurer.
postProcessBeanFactory(PropertyResourceConfigurer.java:78)
好吧,它还挺灵活!我随意拿了个database.properties文件,把它放到测试类的文件夹中并再次运行测试。但这一次程序又抛出了下面的异常:
java.io.FileNotFoundException: .\server.conf (The system cannot find the file specified)
at java.io.FileInputStream.open(Native Method)
at java.io.FileInputStream.<init>(FileInputStream.java:106)
at java.io.FileInputStream.<init>(FileInputStream.java:66)
at java.io.FileReader.<init>(FileReader.java:41)
at com.foo.bar.config.ServerConfigAgent.parseFile(ServerConfigAgent.java:1593)
at com.foo.bar.config.ServerConfigAgent.parseConfigFile(ServerConfigAgent.java:1720)
at com.foo.bar.config.ServerConfigAgent.parseConfigFile(ServerConfigAgent.java:1712)
at com.foo.bar.config.ServerConfigAgent.readServerConf(ServerConfigAgent.java:1581)
at com.foo.bar.ServerConfigFactory.initServerConfig(ServerConfigFactory.java:38)
at com.foo.bar.util.HibernateUtil.setupDatabaseProperties(HibernateUtil.java:207)
at com.foo.bar.util.HibernateUtil.doStart(HibernateUtil.java:135)
at com.foo.bar.util.HibernateUtil.<clinit>(HibernateUtil.java:125)
看起来只要找到 server.conf 文件就可以了,但这种方式让我有些不爽。仅仅才编写了一个简单的测试用例,就暴露出了代码中的一个问题。正如HibernateUtil的名字所建议的,它仅仅关心数据库信息,而这些信息应该都由database.properties文件提供,为什么还需要访问用以配置服务端启动信息的server.conf文件呢?这里似乎暗示代码散发出坏味道了:当你感觉到自己如同在读一本侦探小说,不断地问“为什么”的时候,这就意味着代码是糟糕的。如果我再多花一些时间完整地看一下ServerConfigFactory、HibernateUtil和ServerConfigAgent这些类,大概能够找到让HibernateUtil直接使用database.properties的方法吧。但那个时候的我已经心烦意乱了,始终没法让程序启动。顺便说一句,这里有一种处理它的临时方案,这把武器就是 AspectJ :
void around():
call(public static void com.foo.bar.ServerConfigFactory.initServerConfig()){
System.out.println("bypassing com.foo.bar.ServerConfigFactory.initServerConfig");
}
让我用直白一点的方式为不了解 AspectJ 的读者介绍一下以上代码的含义吧:当运行时准备调用ServerConfigFactory.initServerConfig()方法,让它打印出一条信息,然后跳过该方法的执行并直接返回。听起来好像是某种 hack,但它大大降低了开销。遗留系统中充斥着问题与谜团,与其打交道的每一时刻都得采取些策略。眼下,从客户满意度这点看来,对我来说最有意义的事情就是修复这个资源管理系统中的缺陷,并改善它的性能。其它方面的代码整理并不是我的当前目标,但我已记住了这个问题,我决定之后再回来处理ServerMain中的问题。
接下来,在每一处HibernateUtil需要读取server.conf文件的地方,我都强制让它从database.properties中进行读取。
String around():call(public String com.foo.bar.config.ServerConfig.getJDBCUrl()){
// code omitted, reading from database.properties
}
String around():call(public String com.foo.bar.config.ServerConfig.getDBUser()){
// code omitted, reading from database.properties
}
接下来的工作你大概能猜到了,如果使用临时方案会比较方便又显得自然,那就使用它。而如果有现成的 mock 对象可以使用,那么就重用它们。举例来说,TestServerMain.main()方法在某一时刻会产生如下错误:
- Factory name: java:comp/env/hibernate/SessionFactory
- JNDI InitialContext properties:{}
- Could not bind factory to JNDI
javax.naming.NoInitialContextException: Need to specify class name in environment
or system property, or as an applet
parameter, or in an application resource file: java.naming.factory.initial
at javax.naming.spi.NamingManager.getInitialContext(NamingManager.java:645)
at javax.naming.InitialContext.getDefaultInitCtx(InitialContext.java:288)
这是由于 JBoss 命名服务未启动造成的,虽然我也可以使用相同的 hack 技术作为临时方案,但InitialContext是一个庞大的 Javax 接口,它包含了数量众多的方法,我可不想把每个方法都用 hack 方式给补完,那实在太冗长了。我很快发现 Spring 里已经包含了一个 mock 的SimpleNamingContext类了,那么就把它放到测试里去试试:
SimpleNamingContextBuilder builder = new SimpleNamingContextBuilder();
builder.bind(“java:comp/env/hibernate/SessionFactory”,sessionFactory);
builder.activate();
经过几次反复的修改后,我终于能够成功地运行TestServerMain.main()方法了。它比起ServerMain来说要简单许多,不仅 mock 了许多 JBoss 的服务,而且完全避免了集群管理的麻烦。
创建构造块
TestServerMain连接了某个真实的数据库,而遗留系统往往会在存储过程、甚至是触发器中隐藏了各种出人意料的逻辑。基于对系统整体情况的考虑,我认为在当前状况下试图理解数据库中的所有奥秘、并以此创建一个伪造的数据库是一个不明智的选择,因此我决定仍然在测试用例中访问真实的数据库。
这些测试用例必须保证它们能够重复运行,以确保我对产品代码所做的任何小改动都能够通过测试。每一次运行,测试用例都会在数据库中创建资源与请求。与单元测试的习惯作法不同的是,有时你并不希望在每次运行之后对测试用例所创建的各种数据进行清理。我们目前为止所做的测试与重构练习更像是一次实地考查的探索——通过对遗留系统进行测试的方式来学习它的功能。为了确保一切功能都像预期一样工作,你也许需要在数据库中检查由测试用例所创建的数据,或者需要在运行时使用这些数据。这就意味着测试用例每一次运行时都要在数据库中创建新的唯一实体,以避免与其它测试用例相冲突。最好能编写一些实用工具类以方便地创建这些实体。
以下是一个创建资源的简单构造块:
public static ResourceBuilder newResource (String userName) {
ResourceBuilder rb = new ResourceBuilder();
rb.userName = userName + UnitTestThreadContext.getUniqueSuffix();
return rb; }
public ResourceBuilder assignRole(String roleName) {
this.roleName = roleName + UnitTestThreadContext.getUniqueSuffix();
return this;
}
public Resource create() {
ResourceDAO resourceDAO = new ResourceDAO(UnitTestThreadContext.getSession());
Resource rs;
if (StringUtils.isNotBlank(userName)) {
rs = resourceDAO.createResource(this.userName);
} else {
throw new RuntimeException("must have a user name to create a resource");
}
if (StringUtils.isNotBlank(roleName)) {
Role role = RoleBuilder.newRole(roleName).create();
rs.addRole(role);
}
return rs;
}
public static void delete(Resource rs, boolean cascadeToRole) {
Session session = UnitTestThreadContext.getSession();
ResourceDAO resourceDAO = new ResourceDAO(session);
resourceDAO.delete(rs);
if (cascadeToRole) {
RoleDAO roleDAO = new RoleDAO(session);
List roles = rs.getRoles();
for (Object role : roles) {
roleDAO.delete((Role)role);
}
}
}
ResourceBuilder是创建者模式与工厂模式的一个实现,你可以以方法链接的形式使用它:
ResourceBuilder.newResource(“Tom”).assignRole(“Developer”).create();
其中包含了一个打扫战场的方法delete(),在这次重构练习的早期,我并没有非常频繁地调用delete()方法,因为我经常启动整个系统并添加一些测试数据以检查饼图是否正确显示。
UnitTestThreadContext类非常有用,它保存了某个特定于线程的 Hibernate Session 对象,并且为你打算创建的实体提供了唯一字符串作为名称前缀,以此保证实体的唯一性。
public class UnitTestThreadContext {
private static ThreadLocal<Session> threadSession=new ThreadLocal<Session>();
private static ThreadLocal<String> threadUniqueId=new ThreadLocal<String>();
private final static SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy/MM/
dd HH_mm_ss_S");
public static Session getSession(){>
Session session = threadSession.get();
if (session==null) {
throw new RuntimeException("Hibernate Session not set!");
}
return session;
}
public static void setSession(Session session) {
threadSession.set(session);
}
public static String getUniqueSuffix() {
String uniqueId = threadUniqueId.get();
if (uniqueId==null){
uniqueId = "-"+dateFormat.format(new Date());
threadUniqueId.set(uniqueId);
}
return uniqueId;
}
…
}
完成重构
现在我终于可以启动一个最小化的可运行架构,并执行这个简单的测试用例了:
protected void setUp() throws Exception {
TestServerMain.run(); //setup a minimum running infrastructure
}
public void testResourceBreakdown(){
Resource resource=createResource(); //use ResourceBuilder to build unique resources
List requests=createRequests(); //use RequestBuilder to build unique requests
assignRequestToResource(resource, requests);
List tickets=createTickets(); //use TicketBuilder to build unique tickets
assignTicketToResource(resource, tickets);
Map result=new ResourceBreakdownService().search(resource);
verifyResult(result);
}
protected void tearDown() throws Exception {
// use TicketBuilder.delete() to delete tickets
// use RequestBuilder.delete() to delete requests
// use ResourceBuilder.delete() to delete resources
接下来我又编写了多个更复杂的测试用例,并且一边重构产品代码一边编写测试代码。
有了这些测试用例,我就可以将ResourceBreakdownService那个上帝类一点点进行分解。具体的细节就不必多啰嗦了,市面上已经有许多优秀书籍指导你如何安全地进行重构。为了本文的完整性,以下是重构后的结构图:

那个恐怖的“数组套 Map 再套数组再套 Map……”数据结构现在已经组织为新的ResourceLoadBucket类了,它的实现用到了组合模式。它首先包含了某个特别级别的预计完成时间和实际完成时间,下一个级别的完成时间将通过 aggregate()方法聚合之后得到。最终的代码干净了许多,而且性能也更好。它也暴露了隐藏在原始代码的复杂性中的一些缺陷。当然,我也同时改进了我的测试用例。
在整个练习中,我始终坚持从系统的整体方向进行思考的原则,我从这个方向开始了重构之路,并始终保持正确的方向。那些相对于手头上的任务来说不太重要的问题就用临时方案绕过它。此外,我建立了一个具有最小可行性的测试架构,让我的团队也可以使用它继续重构其它一些领域。在测试构架中依然保留了一些 hack 的部分,因为从业务的角度来说没有太大的必要去清理它们。我所获的不仅是重构了一块非常复杂的功能区域,并且加深了对遗留系统的理解。将遗留系统当作一件易碎的瓷器并不会使你感觉更安全,只有大胆地深入它的内在并进行重构,才能使你的遗留系统在未来也能够继续它的使命。
关于作者
 Chen Ping 住在中国上海,她于 2005 年计算机硕士毕业后,曾分别就职于朗迅与摩根士丹利,目前在 HP 担任开发经理一职。工作之余,她还喜欢学习一些中医知识。
Chen Ping 住在中国上海,她于 2005 年计算机硕士毕业后,曾分别就职于朗迅与摩根士丹利,目前在 HP 担任开发经理一职。工作之余,她还喜欢学习一些中医知识。




