
【编者按】推荐系统在各种系统中广泛使用,推荐算法则是其中最核心的技术点,InfoQ 接下来将会策划系列文章来为读者深入介绍。推荐算法综述分文五个部分,本文作为第一篇,将会简要介绍推荐系统算法的主要种类。其中包括算法的简要描述、典型的输入、不同的细分类型以及其优点和缺点。在第二和第三篇中,我们将会详细介绍这些算法的区别,让你能够深入理解他们的工作原理。
注:本文翻译自 Building Recommenders ,InfoQ 中文站在获得作者授权的基础上对文章进行了翻译。
本文是推荐算法综述的第二部分。在第一篇文章中,我们简要介绍了推荐算法主要种类及其特点。在本文中,我们将会详细介绍协同过滤推荐算法以及其优点和缺点,这样大家就能深入理解其运行原理。
协同过滤(CF)推荐算法通过在用户活动中寻找特定模式来为用户产生有效推荐。它依赖于系统中用户的惯用数据,例如通过用户对其阅读过书籍的评价可以推断出用户的阅读偏好。这种算法的核心思想就是:如果两个用户对于一些项的评分相似程度较高,那么一个用户对于一个新项的评分很有可能类似于另一个用户。值得注意的是,他们推荐的时候不依赖于项的任何附加信息(例如描述、元数据等等)或者用户的任何附加信息(例如喜好、人口统计相关数据等等)。CF 的方法大体可分为两类:分别为邻域和基于模型的方法。邻域方法(即基于内存的 CF)是使用用户对已有项的评分直接预测该用户对新项的评分。与之相反,基于模型的方法是使用历史评分数据,基于学习出的预测模型,预测对新项的评分。通常的方式是使用机器学习算法,找出用户与项的相互作用模型,从而找出数据中的特定模式。
基于邻域的 CF 方法意在找出项与项之间的联系(基于项的 CF),或者用户与用户之间的联系(基于用户的 CF)。
- 基于用户的 CF 通过找出对项的偏好与你相似的用户从而基于他们对于新项的喜好来为你进行推荐。
- 基于项的 CF 会向用户推荐与用户喜欢的项相似的项,这种相似是基于项的共同出现几率(例如用户买了 X,通时也买了 Y)。
首先,在做基于项的协同过滤之前,我们先通过例子来看一下基于用户的协同过滤。
假设我们有一组用户,他们表现出了对一组图书的喜好。用户对一本图书的喜好程度越高,就会给其更高的评分,范围是从 1 到 5。我们来通过一个矩阵来展示它,行代表用户,列代表图书(图 1)。

图 1:用户对图书的评分。所有的评分范围从 1 到 5,5 代表喜欢程度最高。第一个用户(行 1)对第一个图书(列 1)的评分是 4。空的单元格代表用户未给图书评价。
使用基于用户的协同过滤方法,我们首先要做的是基于用户给图书作出的评价计算出用户之间的相似度。让我们从一个单一用户的角度考虑这个问题,看图 1 中的第一行。要做到这一点,常见的做法是将使用包含了用户喜好项的向量(或数组)代表每一个用户。相较于使用多样化的相似度量这种做法非常直接。在这个例子中,我们将使用余弦相似性。当我们把第一个用户和其他五个用户进行比较时,就能直观地看到他和其他用户的相似程度(图 2)。对于大多数相似度量,向量之间相似度越高,代表彼此更相似。本例中,第一个用户与两位其他用户非常相似,有两本共同书籍,与另两位用户的相似度低一些,只有一本共同书籍,而与最后一名用户完全不相似,没有一本共同书籍。
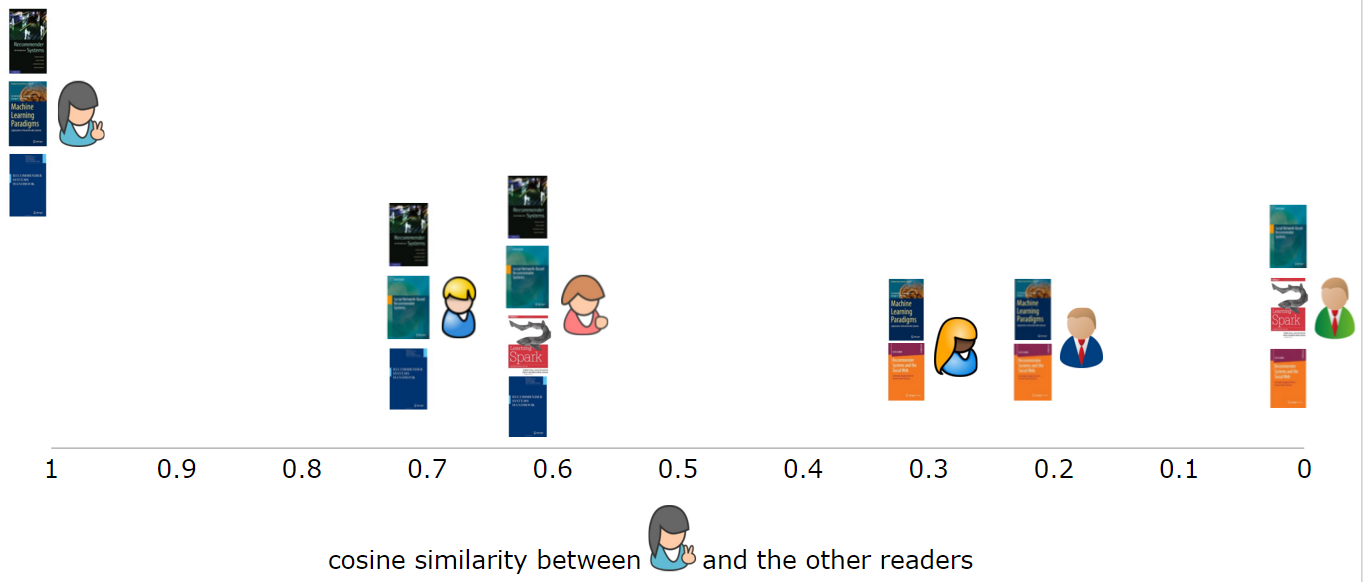
图 2:第一个用于与其他用户的相似度。可以使用余弦相似性在一个单一维度绘制用户之间的相似度。
更一般地,我们可以计算出每个用户的相似性,并且在相似矩阵中表示它们(图 3)。这是一个对称矩阵,这意味着对它进行数学计算会有一些有用的特性。单元格的背景颜色表明用户相似度的高低,更深的红色表示他们之间更相似。

图 3:用户间的相似矩阵。用户之间的相似度基于用户对所读图书的评价数据的相似度
现在我们使用基于用户的协同过滤方法准备好了为用户生成推荐。在一般情况下,对于一个给定的用户,这意味着找到最相似的用户,并推荐这些类似的用户欣赏的项,并根据用户相似度对其进行加权。我们先来看第一个用户,为他们生成一些推荐。首先,我们找到了与第一个用户最相似的另一用户,删除用户已经评价过的书籍,给最相似用户正在阅读的书籍加权,然后计算出总和。在这种情况下,我们计算出 n=2,表示为了产生推荐,需要找出与目标用户最相似的两个用户。这两个用户分别是 2 和 3(图 4)。然后,第一个用户已经评价了 5 和 1,所产生的推荐书是 3(4.5 分)和 4(3 分)。
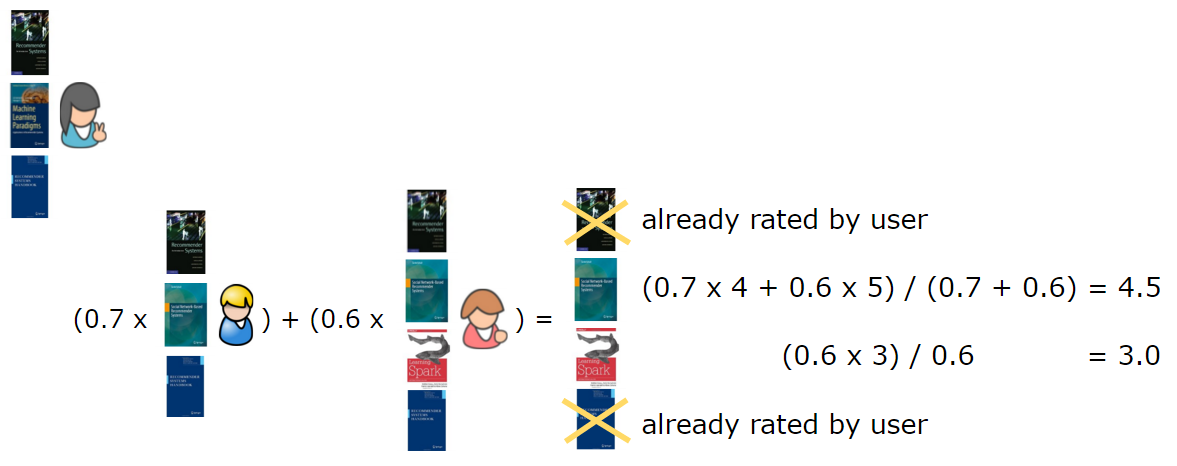
图 4:为一个用户进行推荐。我们将选取最相似的两个用户所评价的书,进行加权,然后推荐加权分数最高且目标用户未评价过的图书。
通过基于用户的协同过滤让我们对协同过滤有了一定的理解。接着让我们再看一个例子,基于项的协同过滤。同样地,我们以评价过一些书籍的一组用户为基础(图 1)。
类似于基于用户的协同过滤,在基于项的协同过滤中,我们要做的第一件事也是计算相似矩阵。然而,这一次,我们要看的是项,而非用户的相似性。类似地,我们要计算出一本书和其它书的相似性,我们将使用评价过一本书的用户向量(或数组)表示这本图书,并比较他们的余弦相似性函数。在第一列的第一本书,最类似于第五列的第五本书,因为评价他们的用户大致相同(图 5)。第三本书有两个相同的评价用户,第四和第二本书只有一个共同评价用户,而最后一本书是不认为是相似的,因为同它有没有共同的评价用户。
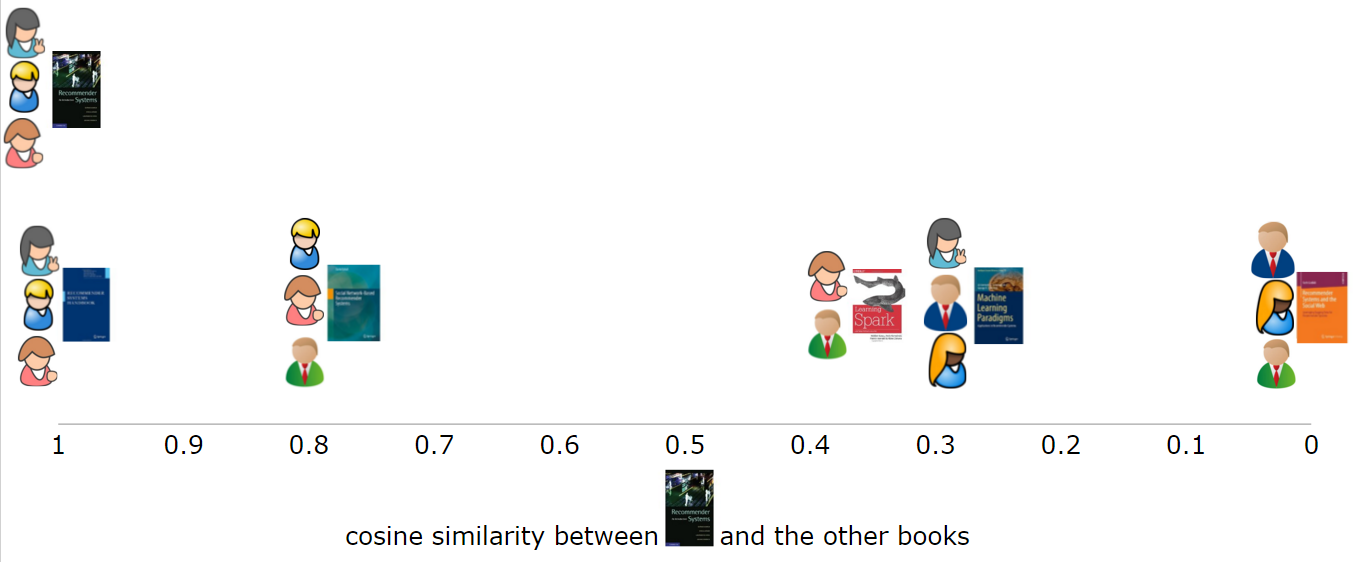
图 5:第一个图书和其它图书的对比。图书用评价过它们的用户表示。使用相似值(0-1)表示相似度。两本书越相似则相似值越高
为了更充分地显示结果,我们可以显示表示所有图书之间相似度的相似矩阵(图 6)。同样地,单元格背景颜色的深浅表示相似度的高低,颜色越深表明相似度越高。

图 6:书的相似矩阵
现在,我们已经知道了图书之间的相似度,我们可以为用户进行推荐。在基于项的方法中,我们采用被用户评价过的项,推荐和被采取项最相似的项。在我们的例子中,第一个用户首先将被推荐第三本书,其次是第六本书(图 7)。另外,我们只推荐和用户已经评价过图书最相似的前两本书。
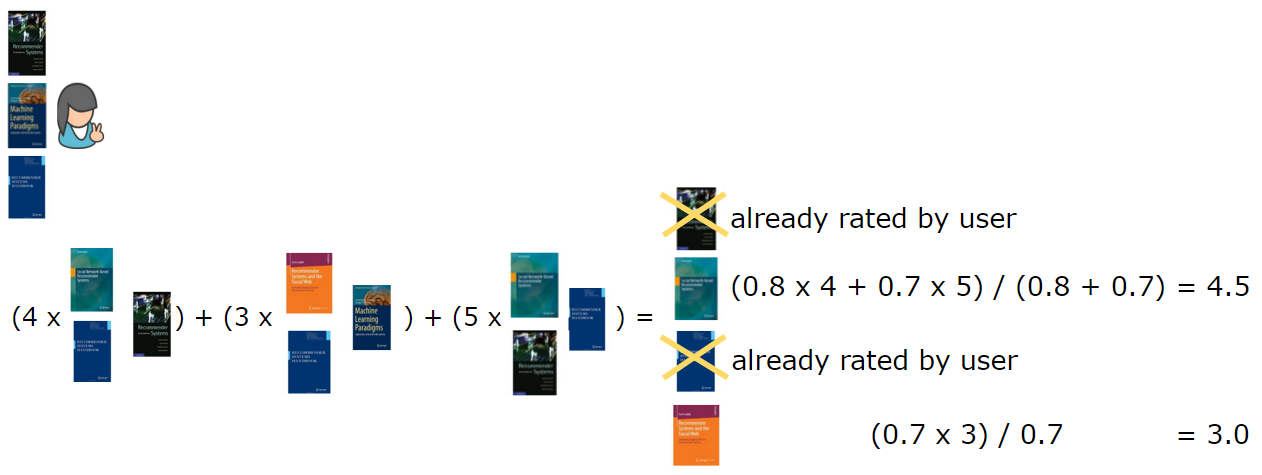
图 7:为用户进行推荐。我们选取他们评价过的图书,找出与他们最相似的前两本书,进行加权,然后推荐给用户加权分最高且他没有读过的书。
鉴于基于用户和基于项的协同过滤的描述听起来非常相似,有趣的是它们可以产生不同的推荐结果。即使在我们这里给出的简易的例子中,即使使用的数据相同,这两种方法产生对于同一用户产生的推荐结果也不相同。当你构建推荐系统的时候,这两种协同过滤方式都是值得考虑的。即使将这两种方式描述给非专家听,它们听起来也非常相似,在实践中,他们可以产生不同的结果,为用户提供了不同的体验。
邻域方法由于其简单性和效率具有相当的知名度,同时也是由于它们有产生准确的和个性化的推荐的能力。然而,它们也有一些可扩展性的限制,因为在用户数量和项的数量增长的情况下,它们需要一个相似度的计算(基于用户或项)。在最坏的情况下,这种计算的时间复杂度可能是 O(m*n),但在实践中的情况稍微好一点 O(m+n),部分原因是由于利用了数据的稀疏度。虽然稀疏有助于可扩展性,它也对基于邻域的方法提出了一个挑战,因为我们的用户仅仅对庞大数量项中的很少一部分进行了评分。例如,在 Mendeley,我们有数以百万计的文章而一个用户可能只读了其中几百篇文章。两个读过 100 篇文章的用户有一篇相同文章的概率(共 5000 万篇文章)是 0.0002。
基于模型的方法可以帮助克服一些基于邻域的方法的局限性。它不像基于邻域的方法,使用用户项评分直接预测新的项。基于模型的方法会在使用评分去学习预测模型的基础上,去预测新项。一般的想法是使用机器学习算法建立用户和项的相互作用模型,从而找出数据中的模式。在一般情况下,基于模型的 CF 被认为是建立 CF 推荐系统的更先进的算法。有许多不同的算法可用于构建模型并基于这些模型进行预测,例如,贝叶斯网络、聚类、分类、回归、矩阵分解、受限玻尔兹曼机等等。这些技术在为了最终赢得 Netflix 奖的解决方案中扮演了关键角色。Netflix 发起了一个竞赛,从 2006 年到 2009 年提供一百万美元奖金,颁发给产生的推荐比他们自己的推荐系统精确 10% 以上的推荐系统团队。成功获奖的解决方案是 Netflix 研发的一个集成(即混合)了超过 100 种算法模型,这些算法模型都采用了矩阵分解和受限玻尔兹曼机。
矩阵因子分解(如奇异值分解,奇异值分解 + +)将项和用户都转化成了相同的潜在空间,它所代表了用户和项之间的潜相互作用(图 8)。矩阵分解背后的原理是潜在特征代表了用户如何给项进行评分。给定用户和项的潜在描述,我们可以预测用户将会给还未评价的项多少评分。
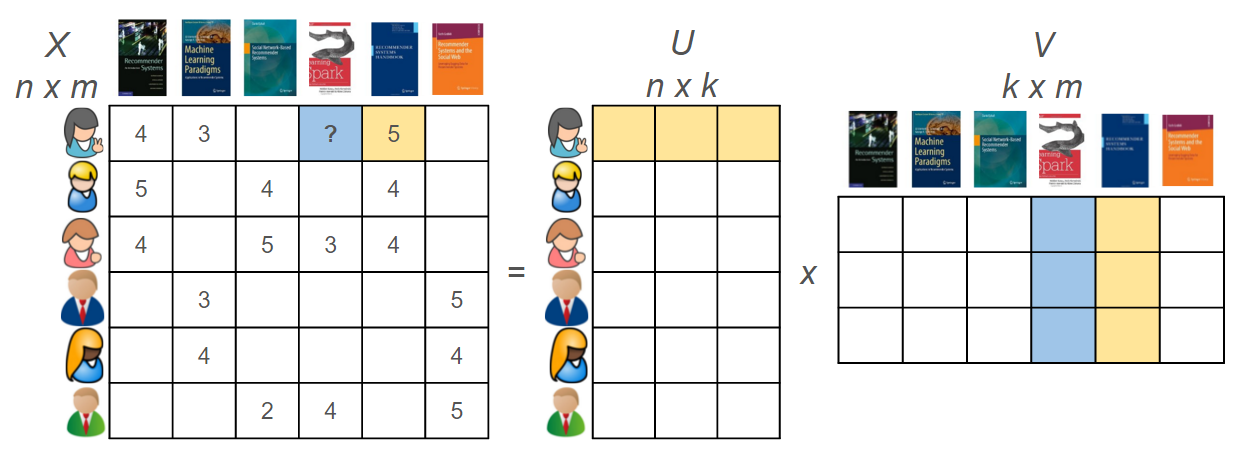
图 8:矩阵分解表示。用户偏好矩阵可以被分解成一个用户主题矩阵乘以一个主题项矩阵。
在表 1 中,我们概述了基于邻域和基于模型的协同过滤方法的主要优点和缺点。由于它们仅依赖于用户的惯用数据,协同过滤方法需要最低限度专业工程的努力,以产生足够好的结果,但是,他们也有局限性。例如,CF 倾向于推荐流行的项,很难推荐给有独特口味的人(即感兴趣的项并没有产生足够多的惯用数据)。这被称为流行性偏见,它通常是用基于内容的过滤方法。CF 方法的一个更重要的限制是我们所称的“冷启动问题”,系统是不能够给没有(或非常少)惯用活动的用户进行推荐,又名曰新用户问题,或推荐新项问题。新用户的“冷启动问题”可以通过流行性和混合方法进行解决,而新项问题可以通过使用基于内容的过滤或 multi-armed bandits(即探索利用)进行解决。我们将在下一篇文章中讨论上述方法中的一些方法。
在这篇文章中,我们讨论了三种基本的协同过滤的实现方法。基于项、基于用户和基于矩阵分解之间的差异是很微妙的,很难简单明了地解释它们。了解它们之间的差异将有助于你选择最适合你的推荐算法。在接下来的文章中,我们会继续更加深入地介绍一些流行的推荐算法。
查看英文原文: Overview of Recommender Algorithms – Part 2
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 (已满),InfoQ 读者交流群(#2))。
(已满),InfoQ 读者交流群(#2))。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论