纽约时报有很多内容生成系统,我们使用第三方数据来编写故事。另外,我们有 161 年的新闻行业积累和 21 年的在线内容发布经验,所以大量的在线内容需要被搜索到,并提供给不同的服务和应用使用。
另一方面,有很多服务和应用需要访问到这些内容——搜索引擎、个性化定制服务、新闻种子生成器,以及其他各种前端应用,如网站和移动应用。一旦有新内容发布,就要在很短的时间内让这些服务访问到,而且不能有数据丢失——毕竟这些内容都是有价值的新闻。
在这篇文章里,我们将详细介绍我们是如何基于 Apache Kafka 解决上述问题的。我们把这个系统叫做发布管道(Publishing Pipeline)。这篇文章主要关注后端的系统,我们会介绍如何使用 Kafka 保存纽约时报的文章,以及如何使用 Kafka 和 Steams API 将发布的内容实时推送给各种应用。下面是总体的架构图,具体细节稍后详述。
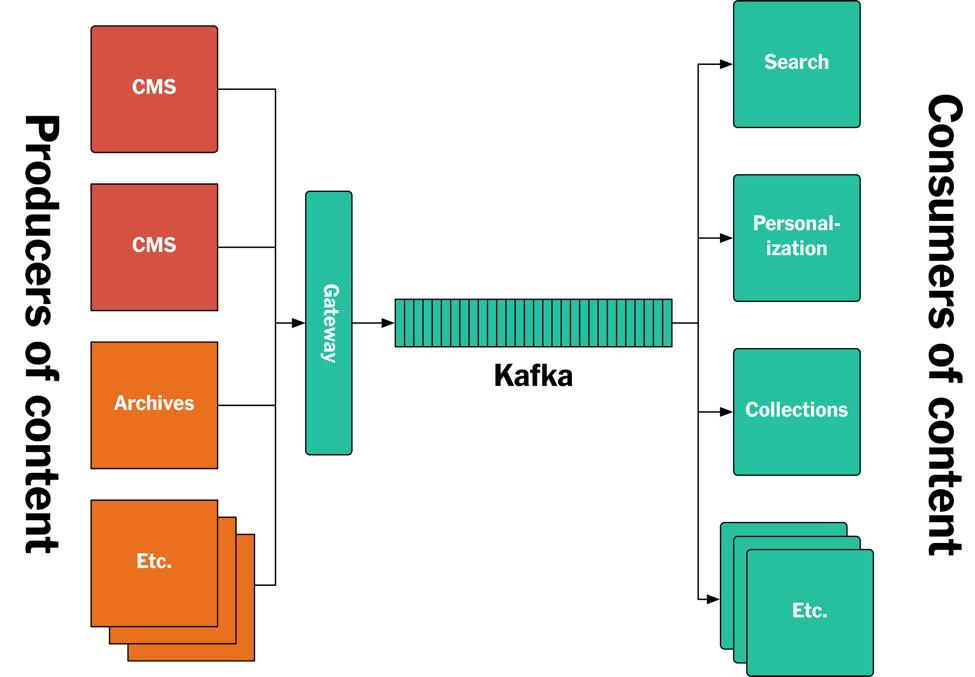
访问已发布内容的后端系统有着各种不同的需求。
-
我们有一个服务专门为网站和移动应用提供实时内容,所以在内容发布之后,它需要立即访问到这些内容。
-
我们还有一些服务用于提供内容清单。有些清单是手动编辑的,有些则是通过查询获得的。对于通过查询获得的清单来说,一旦有符合查询条件的内容发布,就需要被包含在清单里。而如果已发布的内容经过修改后不再符合查询条件,就要从清单里移除。我们还要支持对查询条件本身进行修改,比如创建新的清单,而要新建清单就需要访问之前发布的内容。
-
我们的 Elasticsearch 集群为网站提供了搜索服务。我们对延迟没有很高的要求,比如在内容发布后的一两分钟内搜索不到新内容不算是个大问题。不过,搜索引擎仍然要访问之前发布的内容,因为一旦 Elasticsearch 的 schema 定义发生变更,或者修改了搜索摄取管道,就需要对所有内容进行重新索引。
-
我们还有一个个性化定制系统,它只对最新的内容感兴趣。在个性化定制算法发生变化后,需要重新处理这些内容。
在一开始,我们为这些应用提供了 API,让它们直接访问已发布的内容,或者让它们订阅种子,一旦有新内容发布,它们就会收到通知。
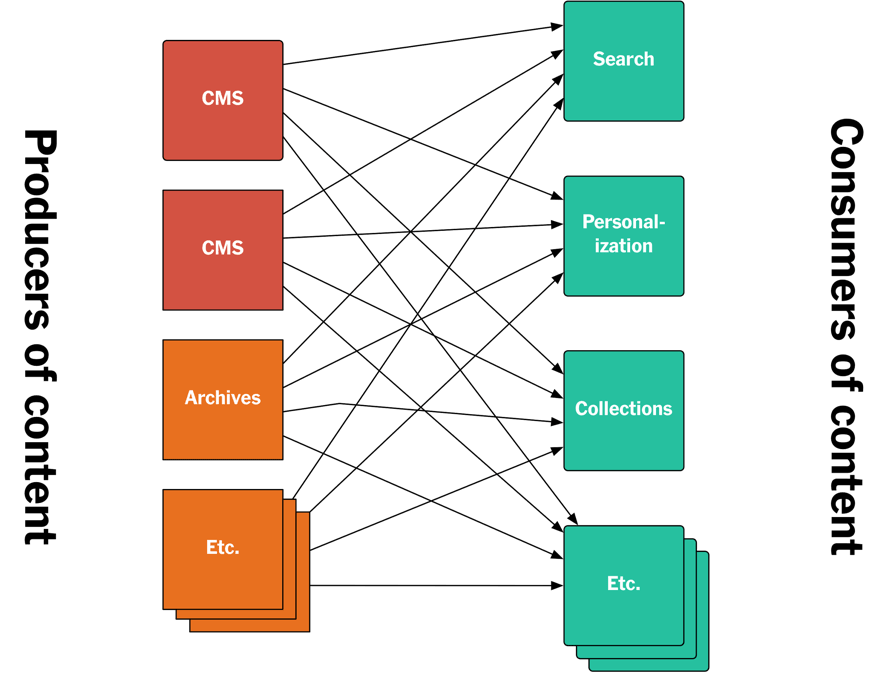
这种典型的基于 API 的解决方案存在很多问题。
不同的 API 是由不同的团队在不同的时期以不同的方式开发出来的。端点存在差异,语义存在差异,甚至连参数也存在差异。虽然我们可以试着去解决这些问题,但那需要协调各个团队,耗时耗力。
这些系统都定义了自己的 schema,同一字段在不同的系统里叫法不一样,而同一名字的字段在不同的系统里表示的却是不同的意思。
另一个问题是,要访问到之前发布的内容是很困难的。大部分系统并没有提供内容流,因为它们使用的数据库不支持这一特性。虽然内容都保存在数据库里,但大量的 API 调用相当耗时,而且会给 API 服务带来不可预料的负载。
基于日志的架构
我们即将介绍的是一种基于日志的架构。Martin Kleppmann 在“ Turning the database inside-out with Apache Samza ”中提到了这一架构方案,后来在“ Designing Data-Intensive Applications ”中有了更为详细的描述。“ Log: What every software engineer should know about real-time data’s unifying abstraction ”则提到了将日志作为一种通用的数据结构的说法。对于我们来说,我们的日志就是 Kafka,所有发布的内容按照时间顺序添加到 Kafka 主题上,其他服务通过消费日志来访问这些内容。
传统的应用使用数据库保存数据,尽管数据库也有很多优点,但从长远来看,管理数据库会成为一种负担。首先,变更数据库 schema 就很棘手。增加或移除字段并不难,但这些变更需要以暂停服务为代价。我们也无法自由地更换数据库。大部分数据库不支持流式变更,尽管我们可以获得数据库快照,但这些快照很快就会过时。也就是说,我们难以创建衍生存储,比如搜索引擎使用的索引,因为索引里必须包含所有文章内容,而且一旦有新内容发布就要重建索引。虽说我们可以让客户端同时将内容发送给多个存储系统,但这样仍然无法解决一致性问题,因为有的写入会失败。
从长远来看,数据库最终会变成一个复杂的单体。
基于日志的架构可以解决这些问题。一般来说,数据库保存的是事件的结果或状态,而日志保存的是事件本身。我们可以基于日志创建任何我们想要的数据存储,这些数据存储就是日志的物化视图,它们包含的是派生的内容,而非原始内容。如果要更改数据存储的 schema,只要创建一个新的数据存储,然后从头到尾再消费一遍所有的日志就可以了,然后把旧的数据存储扔掉。
一旦使用日志作为事实的来源,就没有必要再使用中心数据库了。每一个系统都可以创建属于自己的数据存储,或者说物化视图,它只包含该系统所必需的数据,而且为该系统提供了特定的格式。这就简化了数据库在架构中的角色,更贴合每一个应用的需求。
另外,基于日志的架构也简化了访问内容流的方式。对于传统的数据库来说,访问整个数据转储(比如快照)和访问“实时”数据(比如种子)是两种不一样的操作。而对于日志来说,它们并不存在差别。你可以从任意的偏移量处开始消费日志,从起始位置也好,从中间开始也好,甚至从末尾也可以。也就是说,如果你要重新创建数据存储,只要根据需要重新消费日志即可。
基于日志架构的系统在部署方面也有很多优势。在虚拟机里进行无状态服务的不变模式部署已经成为一种常见的方式。重新部署整个实例可以避免很多问题。因为有了日志,我们现在可以进行有状态系统的不变模式部署。因为我们可以从日志中重新创建数据存储,所以每次在部署变更的时候都可以获得新的数据存储。
为什么 Google 的 PubSub 或 AWS SNS/SQS/Kinesis 无法解决这些问题
Kafka 一般有两种应用场景。
Kafka 常被用作消息代理,用于数据分析和数据集成。Kafka 在这方面有很多优势,不过 Google PubSub、AWS SNS/SQS/Kinesis 也能解决这些的问题。这些服务都支持多个消费者和多个生产者,可以跟踪消费者的消费状态,消费者在宕机的时候不会出现数据丢失。在这些场景里,日志只是消息代理的一种具体实现而已。
但在基于日志的架构里,情况就不一样了。这个时候日志就不只是单纯的实现细节那么简单了,而是变成了核心功能。我们有以下两点需求:
- 我们需要通过日志永久地保留所有事件,否则就无法随意创建我们需要的数据存储。
- 我们需要按照一定顺序消费日志,因为乱序处理关联性事件会得到错误的结果。
目前也只有 Kafka 能够满足这两个需求。
Monolog
Monolog 是我们的新内容发布源,其他系统把创建的内容以追加的方式写到 Monolog。创建的内容在进入 Monolog 前会经过一个网关,网关会检查流经的内容是否符合我们定义的 schema。

Monolog 里包含了自 1851 年以来发行的所有内容,它们按照发行时间进行排序。也就是说,消费者可以从任意时间点开始消费这些内容。如果需要消费所有的内容,就从头开始(也就是从 1851 年开始),或者根据需要只消费那些更新过的部分。
举个例子,我们有一个服务负责提供内容清单,比如某个作者发布过的内容、与某个科学主题相关的内容,等等。这个服务会从起始位置开始消费 Monolog,然后构建内容清单。我们还有另外一个服务,它只提供最新发布的内容清单,所以它不需要永久的数据存储,它只需要过去几个小时的日志数据。它会在启动的时候消费最近几个小时的日志,并在内存里维护一个最新内容的清单。
我们按照规范化形式将内容发送给 Monolog,每一部分内容都被当成一个单独的消息写入 Kafka。例如,图片和文章是分开发送的,因为多篇不同的文章可能包含同一张图片。
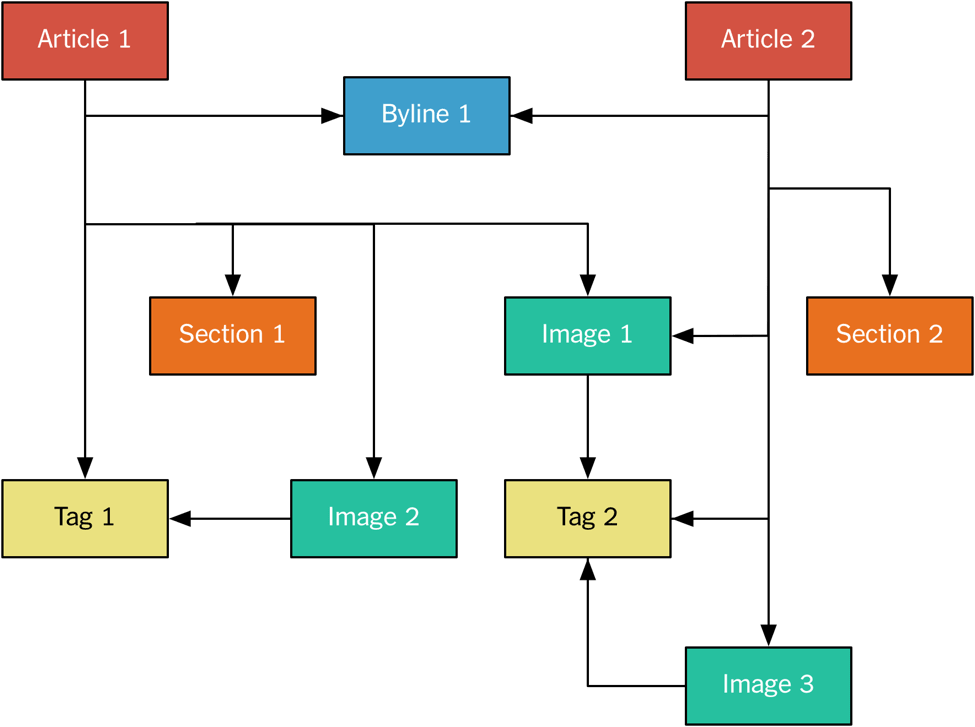
这与关系型数据库里的规范化模型很相似,图片与文章之间是多对多关系。
在上一例子中,我们有两篇文章引用了其他内容。例如,标题行是单独发布的,然后又被其他两篇文章引用。所有的内容都使用 **nyt://article/577d0341-9a0a-46df-b454-ea0718026d30** 这种格式的 URI 来标识。我们有一个原生浏览器可以查看这些 URI,只要单击这些 URI 就可以看到它们的 JSON 表示,而内容本身则以 protobuf 格式保存在 Monolog 上。
Monolog 实际上是 Kafka 上的一个主题,它只包含一个分区,因为我们想要保持消息的全局顺序。这样可以保证顶层内容的内部一致性——如果我们在一篇文章里添加了一张图片,同时又添加了一些文字,这些文字引用了这张图片,那么我们就要确保图片的位置应该在新增文字之前。
实际上,内容是按照拓扑的方式进行排序的,如下图所示。
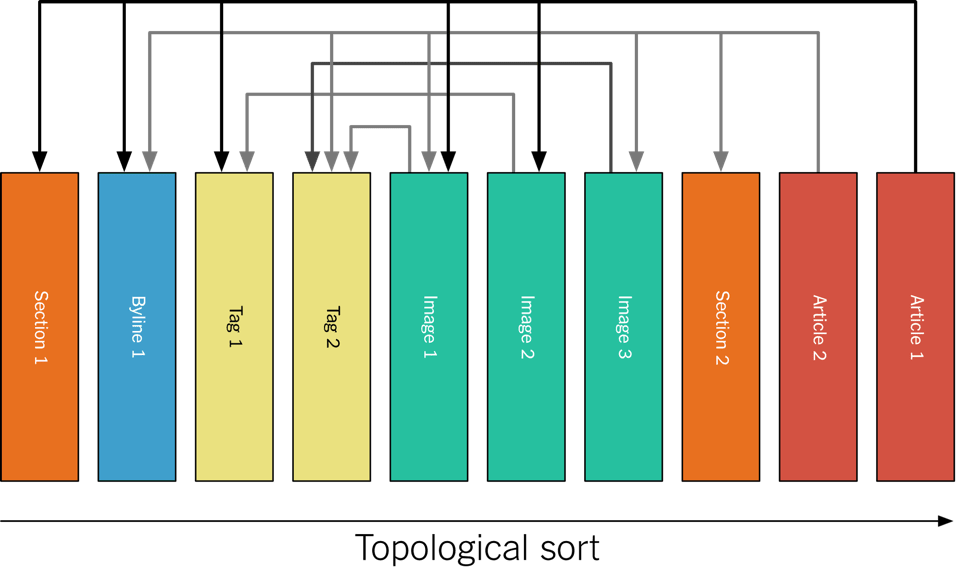
因为主题只包含了一个分区,所以所有内容都保存在同一个磁盘上(Kafka 的存储机制就是这样的)。不过这对于我们来说不是问题,因为我们所有的内容都是文字,到现在总量都没超过 100GB。
规范化日志和 Kafka Streams API
Monolog 满足了部分应用程序的需求,这些应用需要规范化的数据视图,但对于其他一些应用程序来说就不是这么回事了。比如,为了将数据索引至 Elasticsearch,就需要非规范化的数据,因为 Elasticsearch 不支持多对多的关系映射。如果要通过图片说明来搜索文章,这些图片的说明性文字就必须被包含在文章对象里。
为了支持这种数据视图,我们也准备了一套非规范化的日志。在这些日志里,顶层的内容及其所有依赖项都被打包发布。例如,在发布 Article 1 的时候,日志消息里不仅包含了这篇文章,也包含了相关的图片和标签。

Kafka 消费者客户端从日志里消费消息,再添加到 Elasticsearch 索引里。在发布 Ariticle 2 的时候,这篇文章的所有相关内容也会被打包在一起,即使有些图片可能已经在 Ariticle 1 里出现过。

如果文章的依赖项发生变化,整篇内容就会被重新发布。比如,如果更新了 Image 2,那么 Article 1 就会再次被添加到日志里。

我们使用一个叫作 Denormalizer 的组件来创建非规范化日志。
Denormalizer 是一个使用了 Kafka Streams API 的 Java 应用程序。它消费 Monolog 的消息,并在本地为每一篇文章保留了一份最新的版本,包括对文章的引用。随着内容不断地发布和更新,本地存储也会持续更新。一旦有顶层内容发布,Denormalizer 就会从本地存储中收集所有的依赖项,把它们打包写到非规范化日志中。如果某个顶层内容的依赖项发生了变化,Denormalizer 就会重新发布整个包。
非规范化日志不需要全局的顺序保证,我们只要确保同一篇文章的不同版本是按照一定顺序写入日志就可以了。所以我们可以使用分区,让多个消费者同时消费这些分区。
Elasticsearch 示例
下图展示了我们构建的后端搜索服务,我们使用了 Elasticsearch。
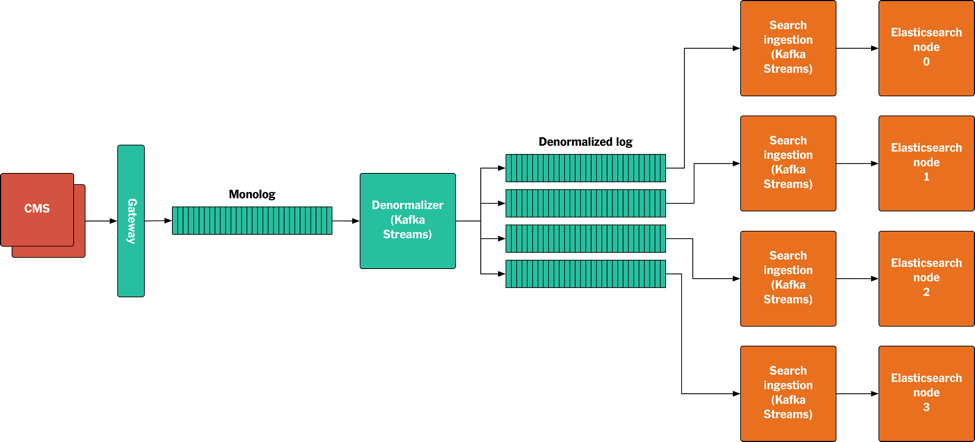
整个数据流程是这样的。
-
CMS 发布或更新内容。
-
内容以 protobuf 二进制的方式发送到网关。
-
网关验证内容,并把它写入 Monolog。
-
Denormalizer 从 Monolog 消费日志,如果是顶层内容,就从本地存储中收集所有依赖项,再打包写入非规范化日志中。如果是被引用的内容,那么所有与之相关的顶层内容也会被写入非规范化日志。
-
Kafka 分区器根据顶层内容的 URI 来分区。
-
所有的搜索节点通过调用 Kafka Streams API 来访问非规范化日志,每个节点读取一个分区,把消息包装成 JSON 对象,再添加到 Elasticsearch 索引里,最后再写到指定的 Elasticsearch 节点上。在进行索引重建的时候,我们把复制功能关闭,这样可以加快索引速度,在构建好索引后再把复制功能打开。
实现
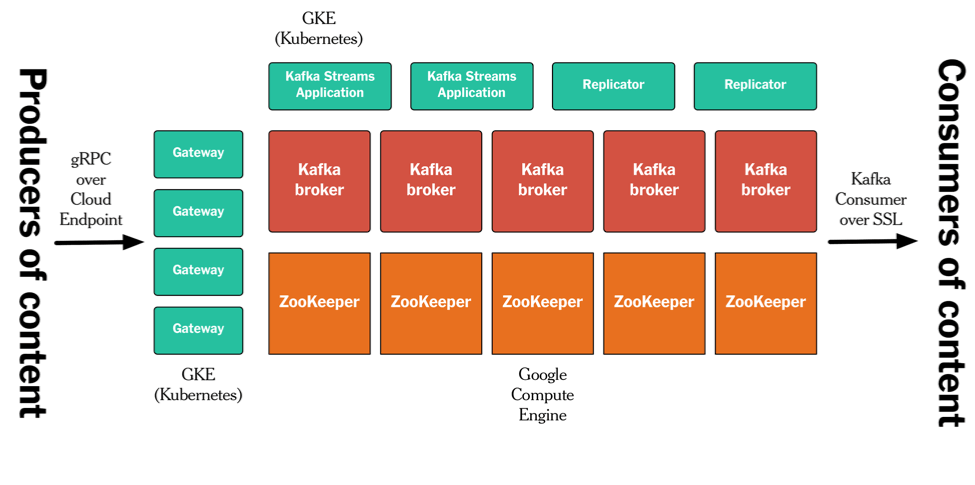
我们的发布管道部署在 Google Cloud Platform 上。我不打算在这篇文章里描述具体的细节,不过下图给出了它的整体架构情况。我们在 GCP Compute 上运行 Kafka 和 ZooKeeper,其他的组件——网关、Kafka 副本节点和 Denormalizer 则运行在容器里。我们使用了基于 gRPC 和 Cloud Endpoint 的 API,并使用 SSL 认证和授权确保 Kafka 的安全。
结论
我们花了将近一年时间在我们的新架构上,现在它已经运行在生产环境中。不过现在还只是个开始,我们还有很多其他系统也需要迁移到这个架构里。新架构有很多优势,但这对于开发者来说也是一次重大的思维转变,他们需要从传统数据库和发布订阅模型转向新的数据流模型。为了让这些优势发扬光大,我们需要改变我们的开发方式,还要花很多精力构建工具和基础设施,让开发变得更简单。
查看英文原文: Publishing with Apache Kafka at The New York Times
感谢杜小芳对本文的审校。




