
物联网领域近期如火如荼,互联网和传统公司争相布局物联网。作为物联网领域数据存储的首选时序数据库也越来越多进入人们的视野, 早在 2016 年 7 月,百度云在其天工物联网平台上发布了国内首个多租户的分布式时序数据库产品 TSDB。
上一周我们发过时序数据库的存储篇:百度无人车和天工物联网都使用了时序数据库,但是你有多了解时序数据库?
前文提到时序数据是一个写多读少的场景,对时序数据库以及数据存储方面做了论述,数据查询和聚合运算同样是时序数据库必不可少的功能之一。如何支持在秒级对上亿数据的查询分组聚合运算成为了时序数据库产品必须要面对的挑战。
本文会从时序数据库的查询以及聚合运算角度展开,最后会从如何解决时序数据的查询问题入手深入分析。
1. 时序数据的查询
用户对时序数据的查询场景多种多样,总的来说时序数据的查询分为两种:原始数据的查询和时序数据聚合运算的查询。
前者是对历史高精度时序数据的查询,查询结果粒度太细,并不利于发现其规律性,趋势性;也不适合展现给用户,主要用于大数据分析的元数据。
后者主要用来对数据做分析,例如 dashboard 等 UI 工具使用聚合查询展示数据分析结果。通常数据分析的查询范围广,查询的数据量大,从而导致查询的延时比较高,而往往分析工具又要求查询延时低,大数据量低延时是时序数据查询面临的主要问题,本文主要探讨聚合分析查询的优化。
2. 时序数据的查询的优化
从前文可了解到,时序数据的存储主要包含单机和分布式存储。时序数据根据分片规则(通常使用 metric+tags+ 时间范围),将分片存储在单机或者分布式环境中。聚合运算查询时,根据查询条件查询所有的数据分片,所有的分片按照时间戳合并形成原始数据结果,当查询条件包含聚合运算时,会根据采样窗口对数据进行聚合运算,最后返回运算结果。
数据聚合运算查询延时的计算可以粗略的描述如下:
聚合运算查询:数据分片的查询合并 + 聚合运算 + 数据返回
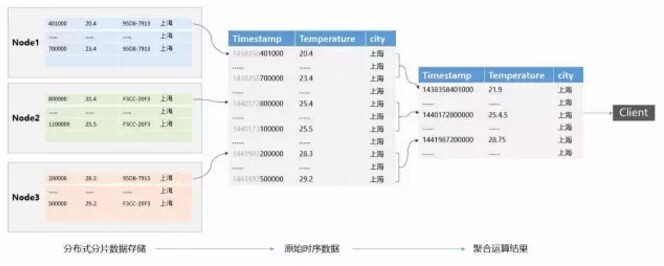
图 1 时序数据查询流程
针对聚合运算的查询可以从两个方向进行优化:分布式聚合查询和数据预处理。分布式聚合查询通过并发使用多个节点并行查询和计算来提高性能,减少了分片查询以及聚合运算的时间,保证了时序数据分析结果秒级返回。而数据预处理则是通过空间换时间的思路,将数据根据查询规则预先计算,查询时直接返回少量的聚合运算结果来保证更低的查询延时。时序数据库可以分别从二种方式进行查询优化,本文之后主要针对数据预处理做深入分析。
3. 时序数据查询的预处理
时序数据的预处理根据实时性可以分为二种:批处理和流式处理。
批处理
批处理是使用 pull 的方式查询时序原始数据,预先进行聚合运算获取数据结果写入时序数据库,当进行聚合查询时直接返回预处理后数据结果。时序数据库定期轮询规则,根据采样窗口创建预处理任务,任务根据规则信息形成多个任务队列。队列内任务顺序执行,队列间任务并发执行,多任务队列保证了多租户对计算资源共享。
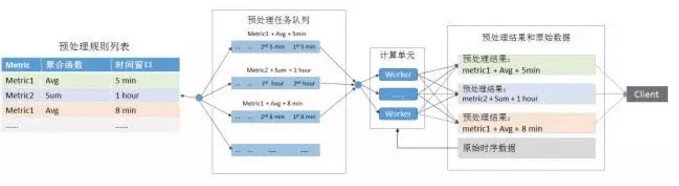
图 2 批处理
预处理任务的执行主要分为二种环境:单机环境以及分布式环境。
单机环境:任务调度模块逻辑相对简单,调度模块通过进程内消息或者轮询多个任务队列,顺序获取队列内未执行的预处理任务,提交任务到线程池执行。
分布式环境:多个计算节点共享任务队列,对预处理任务进行抢占执行,能够支持计算节点的线性扩展,分布式环境可以包含多种实现。
- 消息队列方式: 时序数据库轮询预处理规则,创建预处理任务时,添加任务消息到消息队列,同时设置消息分组,相同的规则使用相同的分组。计算节点消费任务消息,组内消息顺序执行,组外消息并发执行。
- 一致性 hash 方式:多个计算节点通过一致性 hash 算法,形成一个一致性 hash 环,预处理任务根据分片算法(使用规则信息)将相同的任务队列提交到相同的计算节点,保证任务队列顺序执行。
- 调度模块方式: 由调度模块统一进行任务队列的调度,相同规则任务提交到相同的计算单元,保证其顺序执行。
流式处理
流式处理框架同样能够支持对数据流做聚合运算,不同于批处理方式,时序数据需要路由到流式处理框架例如 Spark,Flink 等,当数据时间戳到达采样窗口时,在内存中实时计算,写入时序数据库。
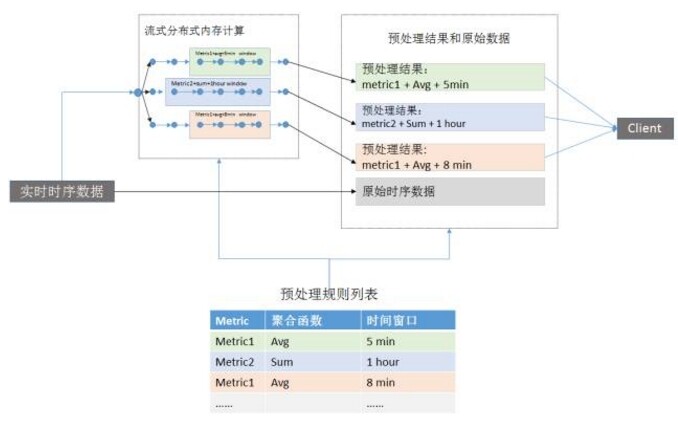
图 3 流式预处理
流式处理属于分布式内存计算,相同的采样窗口数据需要在同样的计算单元中聚合运算,因此需要将相同数据流映射到相同的计算单元,数据流任务调度是流式处理需要解决的核心问题。
- 中心化的调度:由调度模块统一调度数据流,将相同的数据流使用同一的计算单元处理。
- 一致性 hash 方法:通过使用分片 (使用规则信息),将相同的预处理规则数据流映射到相同的计算单元来保证内存数据计算的正确性。
批处理的优点是支持对历史时序数据的处理,实现简单。但是批处理具有查询数据量大,非实时的缺点。流式处理的优点是数据实时计算,无需查询原始数据。但是流式处理需要特殊处理写入的历史数据,也需要处理运算过程中崩溃的计算单元。批处理和流程处理各有优缺点,通常时序数据库需要结合二种方式对数据进行预处理。
4. 真实用例 OpenTsdb 时序数据库
OpenTsdb 当前最新版本并不支持数据预处理,但是在 OpenTsdb 的 RoadMap 中可以看到,在 OpenTsdb2.4 以及后续版本中准备使用新的 API 来支持,主要使用批处理以及流式处理。
批处理:根据采样窗口,定时查询原始数据进行聚合运算,存储计算结果。
流式处理:结合 Spark、Flink 等流式处理框架,对时序数据流做实时计算。
OpenTsdb 期望预处理能够提供用户更加高效的查询体验,同时解决大数据查询计算时系统崩溃的问题。
InfluxDB 时序数据库
InfluxDB 支持 CQ(continous query) 的功能,CQ 通过定期 pull 原始时序数据进行计算,将计算结果存储在内部特殊 metric 中。用户通过创建 CQ 来实现对数据预处理,InfluxDB 的 CQ 主要参数包含:聚合函数名称、储存 metric 的名称、查询度量的名称、采样时间窗口以及标签索引。
SELECT <function[s]> INTO <destination_measurement> FROM <measurement> [WHERE <stuff>] GROUP BY time(<interval>)[,<tag_key[s]>]
5. 结束语
使用预处理能有效的降低采样聚合函数查询对系统的瞬时查询压力,实现数据计算一次多次查询,同时也能有效的降低查询延迟,提高用户体验。百度天工时序数据库平台也早在 2016 年末就推出了预处理功能,满足了物可视对聚合查询高频和低时延的需求。但是对大量原始数据的查询,时序数据库依然会遇到性能、高延时等挑战,后续文章将会对此做深入分析。
注 1:来源
注 2:来源

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论