
长期以来,传统关系型数据库占据了数据存储的大片江山。但是随着互联网 web2.0 网站的兴起,传统的关系数据库在应付 web2.0 网站,特别是超大规模和高并发的 SNS 类型的 web2.0 纯动态网站已经显得力不从心,暴露了很多难以克服的问题。NoSQL,泛指非关系型的数据库,由于其本身的特点得到了非常迅速的发展。
作为云计算领域大型厂商的 Azure 云,对 NoSQL 技术有一系列很好的支持。Azure 云将数据大概分为两种:运行时数据和分析数据。所谓运行时数据就是云计算应用在运行过程中产生的数据,比如购物车添加的某个商品,比如人力资源系统中员工信息以及股票交易系统里的股票买入卖出价格。所谓分析数据,则是通过对运行时数据进行分析后的数据,比如对用户购买数据进行分析后得到的市场预测或者用户购买行为建模数据。这些数据随着应用的运行不断积累,通常来讲要比运行时数据大得多。虽然这种分类不是那么清晰,但是业界通常用这种方式来选择是否使用NoSQL 技术。如下图所示:
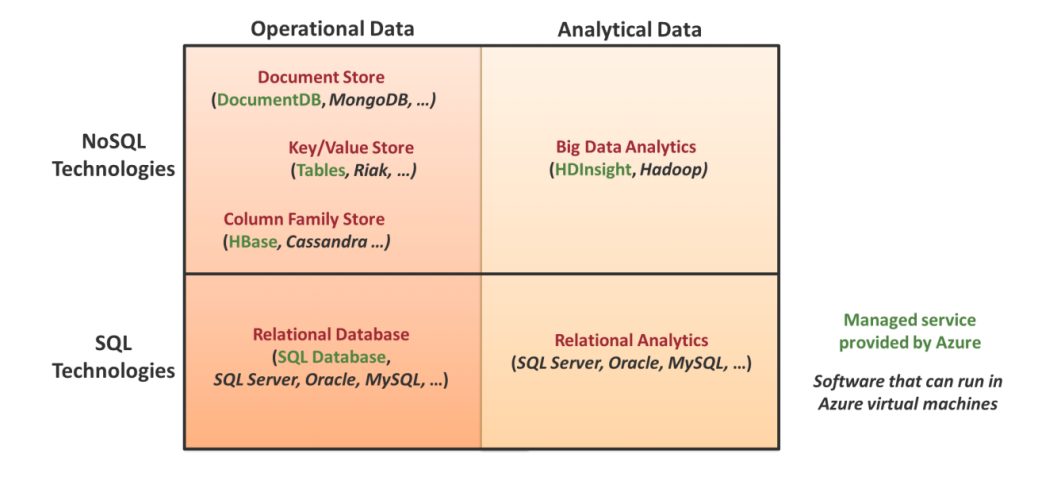
图中的绿色部分,就是Azure 云提供的数据库相关工具,而黑色部分则是可以运行在Azure 云上的其他数据库相关工具。在NoSQL 方面,Azure 可以提供如下服务:
文档存储
使用Azure 的DocumentDB,类似MongoDB。它包括了一系列由JSON 格式构成的文档。注意这里面的Document 跟以往微软Word 软件给出的Document 不是一个意思。下图给出了DocumentDB 的一个例子:
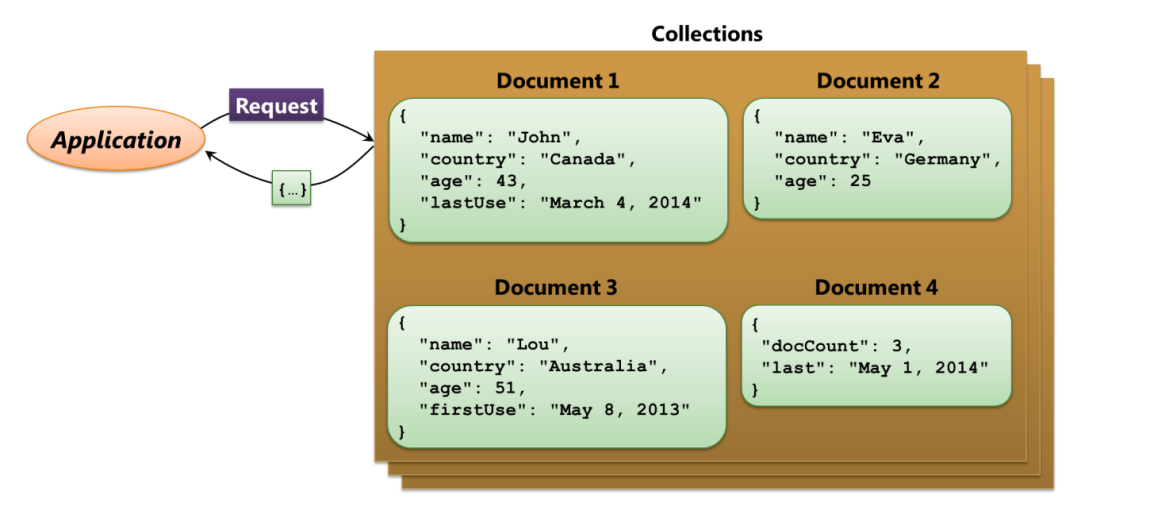
从例子可以看出,DocumentDB 跟关系数据库最大的区别,也是NoSQL 数据库的最大特点,就是它没有特定的Schema,并将全部的数据以字符串的形式存储。在访问数据的时候,通常通过NoSQL 给定的RESTful 接口进行增删查改数据,可一次提交一个或多个类似SQL 的查询语句。RESTful 接口支持的语言很多如.NET、Node.js、JavaScript 和Python 等。
跟大多数的NoSQL 数据库一样,DocumentDB 可以处理海量数据。其数据存储可以分布在多台机器,而且为了防止数据访问出错,DocumentDB 还对一份数据进行了多份备份。当然多备份通常意味着对数据更新和修改的成本会增加,这就需要开发者自己来权衡开发效率和开发效果了。DocumentDB 提供了四种数据访问格式:增强型,最慢但是可以保证数据的正确性。过期数据标注型,告诉开发者正在访问的数据是否过期,让开发者决定是否对数据进行更新。会话型,同一个应用内部可以保证数据的正确性,不保证跨应用的数据正确性。快速型,提供最快的数据访问速度,但是返回过期数据的概率也是最大的。
DocumentDB 是 Azure 的内置服务,用户无需安装就可以创建新的数据库和数据集合。并且它通过“运算能力单元”(Capacity Units)来保证在多租户的情况下单一用户的性能需要。此外 Azure 云存储还提供 MongoDB、RavenHQ 和 Redis 等其他 NoSQL 技术。
对于开发者来讲,从本地通过 Visual Studio 对 DocumentDB 进行访问是轻而易举的事情。他们只需要通过NuGet 包管理工具下载安装DocumentDB.NET 开发包,就可以从容地创建数据库和数据集合、修改JSON 文档以及查询等。如果开发者想要在一次transaction 中修改多个文档,则可通过服务端脚本来开发类似SQL Procedure 来完成,从一定程度商来讲,现代化的JavaScript 脚本取代了传统的T-SQL,使得开发者用起来更加得心应手。
关于DocumentDB 的入门教程可以参考Gaston Hillar 在Dobbs 给出的教程。
Key/value 存储
使用 Azure 的 Tables,类似 Riak,来满足快速访问大量数据的需求。比如一个电商应用,存储了大量的在线购物车。数据非常简单,就是用户感兴趣想要购买的商品列表。而且开发者对这些数据的操作也相对简单,就是对一个特定的购物车键值进行读和写。
这种情况下,不能使用传统的关系型数据库。因为它限制了购物车的数量。因此对于这种大规模简单数据的读写操作,Azure 云开发了 Tables 来帮助开发者更好的完成。
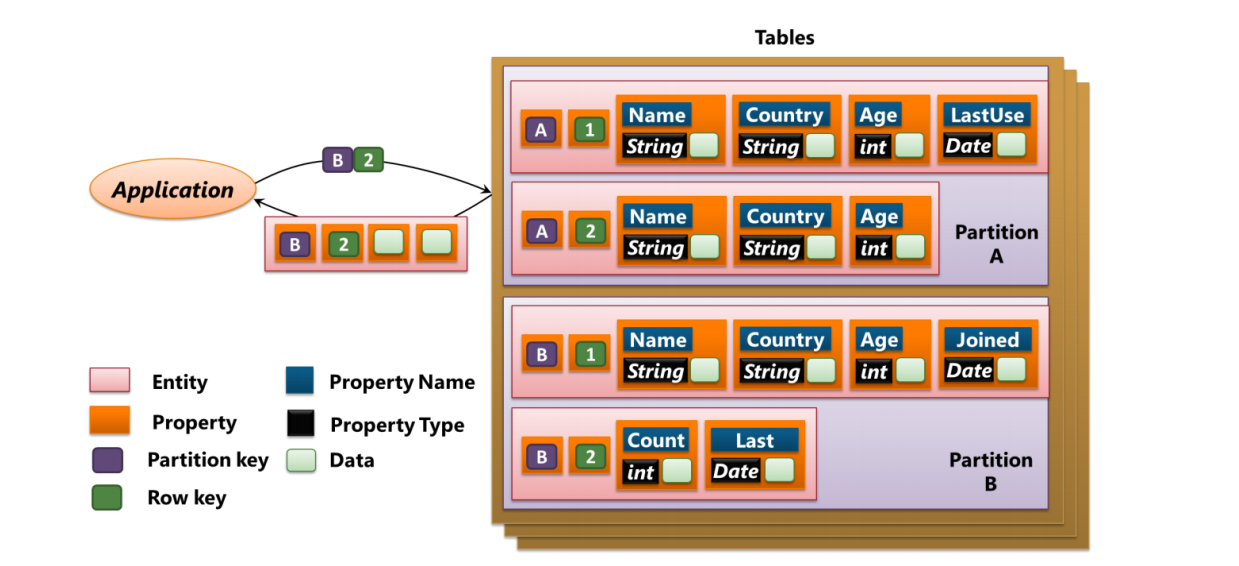
Key/Value 存储的思想很简单,根据一个特定的键值,来增删查改跟其相关的数据。在 Azure Tables 中,数据存储在分区中,每个分区存储一些实体,而实体则有属性。每个属性都有名字和类型比如整数或者字符和日期。每个实体都有一个属性是分区的 Key,整个这个分区的所有实体的该属性都是一样的值。每个实体还有另外一个属性行值,用来区分同一个分区内的各个实体。因此,开发者想要访问某一个实体,就可以通过分区 Key 和行 Key 来定位它。
如同其它的 NoSQL 数据库,Tables 没有 Schema 的概念。分区中的每个实体都可以包含不同数量的属性,只保留对应用最重要的部分数据。在上面图中的例子里,A1 所对应的实体可能包含名字、国籍、年龄以及上次登录的日期。而 A2 则只包括了名字、国籍和年龄。不管数据是什么类型的,Tables 都可以保证这些实体的快速访问。当然要注意的是,Tables 对数据的访问相对来讲比较简单,不提供存储过程或者出发这类功能。类似 DocumentDB,Tables 也对数据进行了多备份的处理,所以哪怕是几台机器失效,数据也会尽可能的被保护。此外,跟 DocumentDB 不同的是,Tables 对数据的一致性也有很好的处理,这意味着开发者总是会得到最后修改过的数据。Tables 还提供跨数据中心的存储,让开发者将数据存储在 Azure 不同地区的数据中心里,通过异步来更新数据的改动。
最后,Tables 最吸引人的地方,实际上是其低廉的价格。虽然这跟开发者选用的存储形式有关系,比如跨数据中心存储会稍微贵一些,但是整体上来讲是比 DocumentDB 要便宜的。这么便宜是因为基本上这都是一些存储费用,Tables 并不保证 CPU 资源。总之 Tables 这种 Key/Value 形式的存储非常简单、可扩展而且价格低廉,是很多应用开发的首选。
列对象存储
使用 Azure 的 HBase,类似 Cassandra。主要是为了应对这样的场景:之前使用了传统的关系型数据库,但是随着业务的增长,关系型数据库无法容纳这么多的数据。而经过研究发现这些数据很多都是稀疏的,即大部分字段都是没有值的。就可以使用列优先的数据库来进行存储。
再举一个例子,比如现在有个应用想要存储关于很多网页的数据。一行数据描述一个网页,每一列都是关于这个网页的一些信息。通常来讲,都会有很多行,因为网页很多,而且也会有很多列,因为网页的信息包含方方面面。但是大部分的字段都是空的,因为不是每个网页都包含了方方面面。如下图所示:
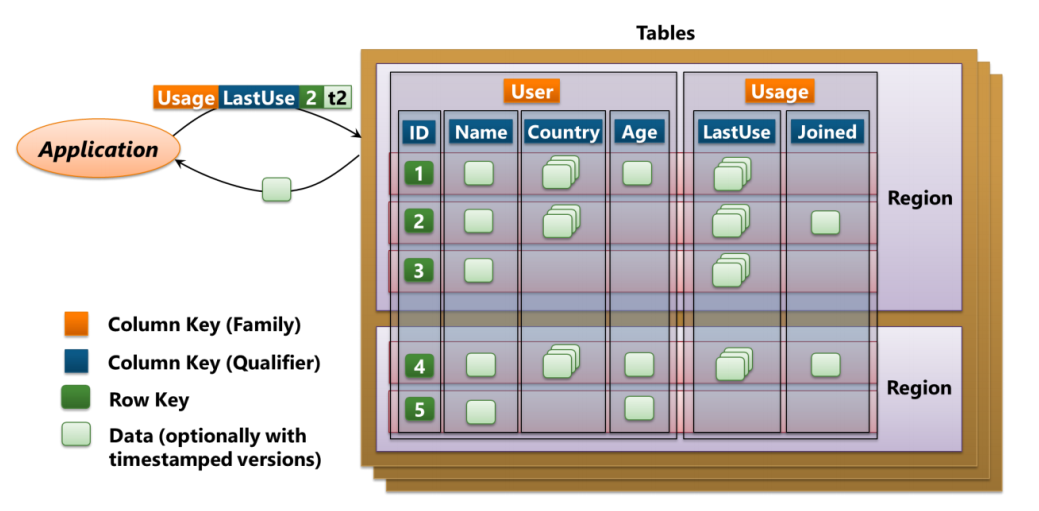
跟 Tables 不太一样的是,以列为先的 HBase,还是有一点点 Schema 的味道,将其称作“列组”。上面的例子还是存储了 Tables 里面同样的例子数据。列组使用一个特定的命名来区分彼此,组内则维持原有的列名字。注意,类似关系数据库,每一列不一定都被填满,但是这种独特的将列划分的组织形式,使得 HBase 能够将稀疏数据做进一步的处理和优化存储。跟 DocumentDB 和 Tables 不同,HBase 并没有以文档或者实体的形式来看待数据,而是只有当新的数据需要存储的时候,才会为某一行增加新的列。
HBase 跟传统数据库也有不同的地方,即存储的内容没有类型的区别,每个字段存储的都是 bytestring。而且每个字段都可以保留相当长的历史数据以及不同版本的数据,这对于需要访问先前数据的应用就有用了。此外,为了跨机器存储,HBase 还将不同的行组合起来形成 Region 区域,当然这对于应用开发者来讲是透明的。这就跟 DocumentDB 的容器和 Tables 中的分区不一样了,这些都是开发者在创建数据库的时候必须手动给定的。
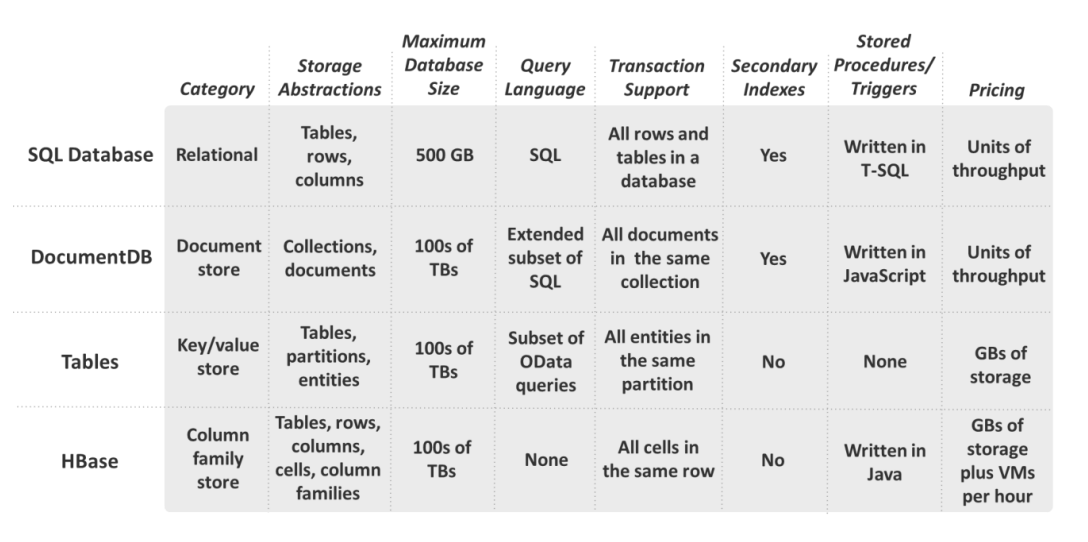
HBase 并不提供查询语言,应用只需提供列组、列名称和行 Key 就可以访问对应的数据,这种访问方式类似上面提到的 Key/Value Tables。下表给出了 Azure 云中支持的数据库类型的比较:
大数据分析
使用 Azure 的 HDInsight,类似 Hadoop。在大数据这个概念深入人心之前,应用开发者对数据所做的,就是保证应用的功能性。比如让用户完成购买、招聘新人、更新游戏排名榜之类的。但是,随着越来越多历史数据的积累,分析运行时数据的模式、趋势以及相关信息能够让开发者获得更进一步对应用的认识,获取第一手的评估资料。因此,Azure 云还为开发者提供了商业智能相关的数据库支持,如数据仓库等。对于分析数据来讲,传统的关系数据库技术就显得不是很合适了,因为这种数据可能并不能用关系来表示。
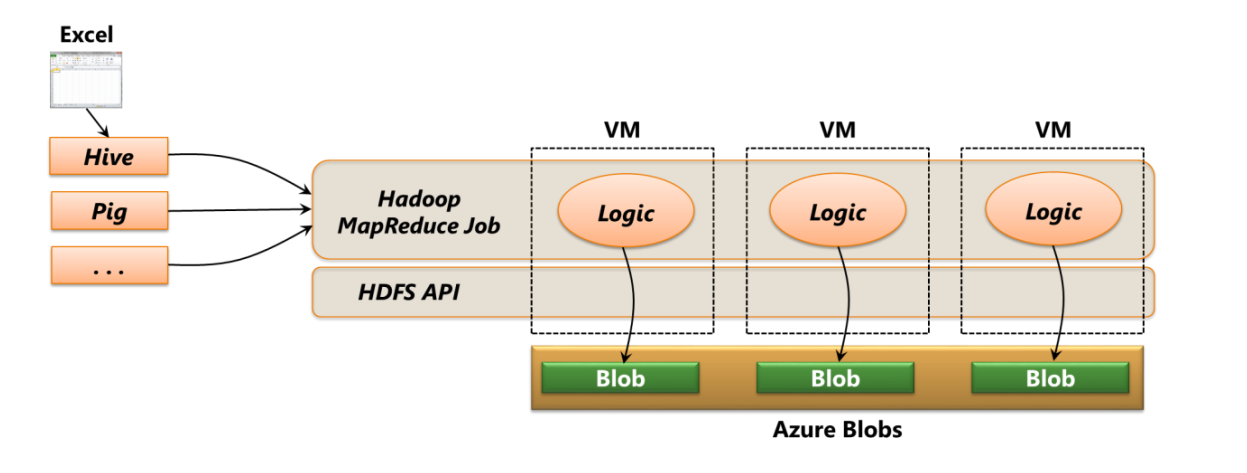
非常赞的是,开源的 Hadoop 软件给了我们分析这种数据的可能,Azure 包含了多种 Hadoop 相关技术,如下:
- HDFS:用来存储集群中大型二进制文件的文件系统;
- MapReduce:用来处理 HDFS 中数据的并行计算方法;
- Hive:提供类似 SQL 语言的 HiveQL 来查询数据;
- Pig:利用 Pig 脚本来创建分布式计算实例;
上述这些服务,被 Azure 云以 HDInsight 开发包的形式提供给开发者,如下:
结语
海量数据的今天,关系型数据库不再独霸天下,NoSQL 数据也成为了开发者开发应用过程中不可或缺的有力工具。Azure 云致力解决开发者遇到的数据操作问题,力争以最简单的封装来完成最复杂的需求。
感谢郭蕾对本文的策划和审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。

暂无签名

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论