
我们,包括我的团队以及我本人,都很恐惧重新部署!设想一下吧,我们不是在做一项新特性,而是必须要重新部署系统:版本管理、要求 scrum master 编写变更请求、对系统进行打包、跑到 IT 运维团队那里,请求他们帮着进行部署。到一天结束的时候,会发现燃尽图进度不理想,所有的利益相关方都会感到不爽。
作为一名软件工程师,非常不幸的一件事情在于软件是看不见摸不着的。它的这一特点,使得我们很难看到它所具有的漏洞。当在生产环境发现这些漏洞的时候,如果对其打补丁或进行热修复的话,将会导致费时费力的重部署。本文将会展示一些拿来即用的技巧,这些技巧能够帮助我们减少热修复部署的需要。
但是 Bug 无处不在
在作为软件工程师的职业生涯中,我看到过各种类型的错误,或者工程师所谓的“ bug ”。它们其实无处不在:在服务器端、在客户端、在浏览器上、在网络设备中!
Bug 不仅无处不在,它们还会带来一定的成本。发现它们、评估它们的影响以及对其进行修正(也就是调试的过程)都是成本高昂的。 NASA 曾经经历过史上成本最高的 bug 之一,1.25 亿美元消散在了火星稀薄的空气之中。
但是,“人都会犯错的”,NASA 项目的 JPL 主管 Tom Gavin 曾经这样说道。不幸的是,软件工程的本质特点让我们很难在开发的早期就探测到潜在的 bug。
我们可以采取一些措施,降低不必要的 bug 侵入到软件中的可能性。这能最小化热修复部署的风险。本文在三个方面讨论了这些措施:
- 开发期
- 部署之前
- 部署之后
开发期
从一个清晰的 Story 开始
一个好的 Story 对于什么是完成有着良好的定义,并且可以进行拆分。好的 Story 会在以下方面给团队带来帮助:
- 减少歧义性;
- 帮助团队理解 Story 的目的;
- 让开发过程更加快速;
- 支持更高质量的交付。
好的 Story 首先要有一个好的标题,通常格式如下:
作为一个 [角色],我想要 [活动], 以便于实现 [目标 / 价值]
接下来,它需要有一个完成状态的良好定义。完成状态的定义能够告诉工程团队每个可测试的场景,在这个 Story 可交付之前,必须要包含这些场景。完成状态的定义是由 product owner 编写的,并且会由其进行检查。
工程团队需要将任务进行拆分。列表中要包含构建该 Story 的技术步骤。需要注意的是,每一项任务应该在一天之内完成,这是一项任务完成时间的上限——如果做不到的话,那就要进行进一步地拆分。这样的话,product owner 能够更容易地跟踪进度,也能让团队感到有一种成就感。
而定义较差的 Story 一般会具有下面的特点:
- 不清晰,Story 的目标是什么?
- 缺少总体的样例。甚至连包含预期输出的简单样例都没有。
- 完成的定义模棱两可,不知道预期结果是什么。
例如,有一个 Story 是要对系统 A 进行变更的,但是没有提及这个变更会对同一团队维护的系统 B 产生影响。因此,就会出现 bug!但是,如果系统 B 是由其他的团队来维护的话,又该如何防止这种问题的出现的呢?我们稍后将会对其进行进一步的讨论。
不要匆忙了事的文化
这是除了 Story 定义之外,最重要的事情。我首先给你讲述一下我们的经历,我们是如何通过不那么急切行事,避免热修复部署的。
以前,我们在进行部署的时候,都会弥漫着一种紧迫感。其实就是在部署的那一天,希望包含尽可能多的 Story,我们为此感到了很大的压力。这样的结果就是对细节失去关注,我们经常需要重新部署。有时候,我们不得不部署三次来进行热修复,这真的让人非常尴尬。
但是,当我们开始按照稳健的节奏工作时,就发现很少再需要热修复部署了,当然偶尔会发生的安全缺陷除外。我们非常冷静地进行判断:如果某个 Story 无法进行全面充分的测试,那么在部署时就不会包含该 Story,我们会等待下一个周期。我们非常坚定地执行这个规则,因此很少需要重新部署。
最好是一次部署成功,而不是匆忙进行部署,却要失败好多次。
这里的关键在于分配优先级,那是怎么做的呢?
要事优先。不要让客户、商业方案、负责客服的家伙或者其他人告诉你“这个特性必须要立刻加到生产版本中”。对于这种情况,要想办法对他们说不。很可能出现的情况是,即便你交付了这个特性,它在几个月内也完全用不着。
但是,有些特性、修复以及缺陷确实需要快速响应,关键就是确定优先级!我们通常有四个层级的优先级:P0、P1、P2 和 P3。
如果有紧急的 Story,并且需要快速部署的话,那为其分配的优先级就是 P1。例如,如果修改了登录页的代码之后,潜在用户无法进行注册了,那么就要将这个 bug 考虑作为 P1 级别。
比 P1 更高的是 P0。P0 是非常、非常严重的问题。它可能会导致整个系统完全无法使用,可能会导致很多客户暴跳如雷,可能会让你的公司破产。如果这个问题需要你立即从床上跳起来去解决,那它就是我所说的这种类型。
P0 级别 bug 的一个样例就是系统在部署之后,所消耗的内存空间呈指数级增长,导致性能的下降,所有的用户均无法可靠地访问系统。这需要“紧急集合(all hands on deck)”式的响应,快速修正问题(但是不要恐慌)并尽可能快速地部署热修复版本。
P2 是针对当前 sprint 的,在 sprint 开始之前,所有 P2 的 Story 都经过了慎重地考虑,按照规划,它们需要包含在当前 sprint 之中。
比 P2 级别更低的是 P3,它能够等到规划未来 sprint 时再进行考虑。我们该怎样判断某个 Story 是 P3 呢?如果不部署所要求 Story, 有其他方式也能达到预期输出的话,那么这个 Story 就可以进行等待。P3 是默认的优先级。对于未规划的所有特性 /bug 修正的请求,都将其优先级定为 P3。
遵循上述的指导,我们有了更好的精神状态,在团队所编写的代码中,bug 也会更少。
好的编码实践
如果你有一个团队的话,要进行结对编程,至少偶尔要这样做。结对编程有利于知识的共享,新雇员要与团队中经验丰富的编码人员结对。通过这种方式,新雇员能够快速学习到系统中的知识,并且能够开始独立实现特性。有些公司则更进一步,将结对编程变成了常态,为两位开发人员只提供一台计算机,强迫他们进行结对编程。
编写良好的文档和良好的提交信息。有很多其他的技术能够指导我们编写更好的代码:不要硬编码值、使用整洁命名的变量,使代码易于阅读等等。寻找好的编码参考实践,并确保整个团队理解为什么使用它们以及如何使用它们。
还要考虑到物理因素。允许每个人按照其最高效的方式工作——如果有人觉得他们在晚上工作状态更好的话,那就让他们晚上工作。要照顾到人的各个方面——好的物理环境、具有安全感的工作文化以及健康的习惯,如保证好的夜晚睡眠质量,这些会让人压力更小,精力更充沛,有利于产生更好的产品。
质量控制
质量控制中最重要的一个方面就是测试。测试分为很多种:集成测试、单元测试、黑盒、白盒以及用户验收测试(user acceptance testing,UAT)。在测试方面,应该是没有谈判余地的。但令人遗憾的是,实际上,通常并非如此。
忽略测试意味着积累技术债。随着时间的推移,开发流程将会逐渐恶化,因为开发人员会担心他们的代码会对其他部分的代码造成破坏。即便测试都能通过,我们依然会持续地发现 bug,到底该如何避免 bug 的出现呢!Djikstra 曾经说过:
测试从来不能证明没有故障,它所做的只能是展现它们的存在。
希望我们能够意识到测试是做什么的,并且能够明白如果没有它的话,软件开发是不完整的。最好要衡量代码覆盖度。代码覆盖度能够探测到哪些代码已经测试过了,哪些还没有测试。从数学上来讲,代码覆盖度可以表示为:
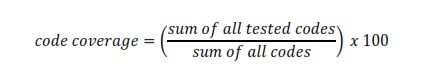
根据经验规则,覆盖度最好要达到 85% 或更高,测试至少要覆盖代码的 85%。
我们并不能保证达到 85% 的代码覆盖率就是没有 bug 的系统,我甚至不敢说代码覆盖度会意味着更少的 bug。不要产生误解,99.99% 的覆盖率并不代表系统少了99.99% 的bug。
与代码覆盖率同样重要的是应该将持续构建工具集成到代码库中,如Travis CI、Drone 或Codeship。这样的话,对分支的任何变化都会触发测试。如果测试通过的话,那么它将会我们构建一个包,CI 致力于最大化工作效率。
作为product owner,请不要在测试方面妥协!借助非常严格的测试,在生产环境测试我们的包的时候,曾经发现过P0 级别的bug。这是在准生产环境(staging environment)和生产环境下,运行测试2 到3 次之后才发现的。
对工作进行同步
在所有的利益相关方之间对工作进行同步是非常重要的,这些相关方包括:product owner、开发人员、scrum master 以及其他团队。实现工作同步的方式之一就是每天举行站会,这种会议会在每天的特定时间举行,每个人要讲述一下昨天做了什么,以及今天计划做什么。
如果你有远程团队成员的话,最好每天进行两次站立会议,一次在早上进行,另外一次在傍晚进行。通过这种方式,就能了解在远程的其他人计划做什么,并且能够在傍晚比较容易地得知其进度。
与之相关的另外一件事情就是跨团队的同步会议,这涉及到相关团队的成员。这个更大型的会议可以每两周举行一次,而不是每天都举行。比如,API 团队以及portal 管理团队之间所举行的会议就是这种类型,portal 管理团队会使用API 团队所开发的API。
站立会议还会进行一些关键性的讨论。如果会影响到相关团队的话,非常重要的一点就是尽可能多的通知相关成员。例如,如果要废弃数据库中的某一列,而这个列需要在多个应用间进行共享,那么提出废弃意见的人需要与其他相关的团队讨论该问题。
捕获更老的bug
你的系统可能已经存有bug,并且积累了一些技术债,这些问题可能会降低开发的速度,或者引起了客户的抱怨。针对这种情况,可以考虑规划整个sprint/ 星期都用来查找关键特性的各个组成部分,然后探讨如何一劳永逸地进行调试并移除bug。
在找到可能会有bug 的特性之后,在to-do 列表中将其记录下来,并为每个条目分配一个优先级。按照sprint 的方式,每次只处理其中一项。如果你的团队中开发人员的数量足够多的话,那么对其进行分而治之是不错的方案:一部分人处理这些琐事(调试),而另一部分人就可以进行正常的story。
我们曾经遇到过来自财务部门相关特性的“bug”,这个问题实际上是由他们自己的错误操作所导致的,例如将钱转到商户的账户之后,错误地点击了取消按钮,而不是完成按钮。为了取消这样的点击,我们需要对数据进行多步手动变更,这最终消耗了我们很多的精力。但是,在进行了两个sprint 的调试之后,我们再也不用进行这些令人郁闷的手动工作了,非常棒!我们已经忘记当时压力重重的状态了,当然,这样我们会更加开心!
自治
这是最后一件事情。强制开发人员从事某一项特性很可能会引入bug。开发人员应该自由选择从事某个新特性、进行研究还是修复某个bug,他们可以选择任意感兴趣的Story。
像Trello、Pivotal Tracker、Asana 这样的工具甚至原始的白板都可以列出当前sprint 要开发的所有特性,然后让大家自由选择他/ 她所感兴趣的Story。就团队来讲,只要Story 符合公司的当前目标,就没有必要由管理人员来分派工作——让大家自行分派任务。
PS:如果你对所有的 Story 都不感兴趣,那么对你来说,这是另外一个“Story”了,HR 也许会非常(不)高兴地找你聊聊。
但是,如果采用自治的策略,所有的人均不想开发某个特性的话,那么 product owner 需要进行讨论来解决这个问题。如果没人愿意做的话,那么需要结对来完成这个 Story。在采用自治策略的情况下,我还没有经历过所有的人均不想选择某个 Story 的场景。
部署之前
Pull 请求以及代码检查
在感觉完成某个 Story 的所有任务之后,你就可以提交一个 merge 请求或 pull 请求。对于具有多个互相关联团队的公司来讲,Pull 请求会更加重要一些。
Pull 请求就绪之后,Story 的状态将会变为“代码检查中”。如果所有的事情看起来都没有问题,那么就会进行合并,然后,如果需要测试的话,product owner 会在准生产环境手动测试 Story。
代码检查不应该包含在某个 Story 完成状态的定义中,就像测试也不应该包含在其中一样。代码检查和测试应该是软件工程师的第二天性(second nature)。所有的 Story 在部署前都要进行代码检查和测试!所以在 Story 完成状态的定义中将其添加进去是多余的。
负责检查的人不应仅关注细节的错误,如变量命名不当或缺少空格,检查者应该关注逻辑错误、如何提升当前代码的性能、可维护性、安全性等方面。
如果你的 Story 采用结对编程的话,那么应该由不和你结对的人来进行代码检查。但需要注意的是,如果采用结对编程依然在代码中出现了逻辑错误,那是一件很令人尴尬的事情,两个人的大脑依然会产生带有 bug 的代码确实很让人难堪。
部署时
部署的内容要小,频繁部署
将你团队的部署计划进行分解。应该考虑每周部署一小块内容,而不是每两周部署一大堆特性,如果可能的话,可以部署地更加频繁。
一次性部署很多 Story 会让用户验收测试耗费太多的时间,用户一般只会觉得“哦,这个特性很棒”,而不是对其进行全面地测试。
另外,如果在这个很大的部署包中出现了 bug,很难有效猜测 bug 产生的根本原因是什么。
在准生产环境测试,在公开环境测试
毫无疑问,更好更安全的方式是不要直接部署到生产环境中。我们应该在准生产环境进行 UAT。如果在准生产环境的测试中发现了带有 bug 的特性,那么就将其排除在部署包之外。
在所有的事情均准备就绪之后,就可以在一台生产环境的机器上进行 dry-run。dry-run 能够让新特性在生产环境中运行,但是不会影响到很多人。网络工程师通常会将系统引导到选定的机器上。如果在 dry-run 环境下出现失败的话,就不要部署这个包!
当你确定所有的事情都达到预期的时候,就可以要求网络工程师将其部署到所有的机器上,使其完全公开。
在部署到所有的机器上之后,邀请一位终端用户来进行再一轮的测试。当然,在很多情况下,这也许不太可行,那也没什么问题。但是,如果你的用户来自公司内部,那么可以选择其中的一位用户进行一下最终测试。
如果遵循上述的所有规则的话,我们很少会在生产环境下发现 bug,但是有些罕见的 bug 只会在生产环境下才会出现,我们曾经见过这种情况。所以,最后一分钟的测试时必要的。
部署之后
使用 bug 跟踪和监控系统
不要让客户成为第一个告诉你软件中存在 bug 的人。如今,我们可以非常容易地实现自己的 bug 跟踪系统,例如,在异常出现的时候,给开发人员发送一封 Email。
像 AppSignals、Raygun、NewRelic 这样的现代化工具都是可以使用的,不过它们通常会有一定的成本。也有一些很好的开源工具可用,不过你需要自行将它们组合起来,如 Munin、Telegraf、InfluxDB 和 Grafana。
通过使用这些工具,我们就能知道出现了某个 bug,而不需用户预先填充一个报告表单。
工作回顾
到此为止,即便不是所有的 Story,至少它们中的大多数都已经部署到了生成环境中。现在是进行快速工作回顾的好时机,与你的团队进行讨论,这包括 product owner、scrum master 以及其他的相关方,讨论一下最近这次部署哪些方面做得比较好,哪里出现了问题,如何在将来最小化错误的出现,以及如何提升团队的工作方式。
如果实现一个系统,允许开发人员在 sprint 的进行过程中就提交要讨论的回顾内容,那是很有用处的。通过这种方式,在进行回顾的时候,人们不用再浪费时间思考回顾点是什么,而是集中精力讨论所提交的内容。
甜点
作为 product owner,不妨好好犒赏一下你的团队,(例如)如果连续三次部署都没有出现热修复的话,领他们喝个咖啡、去餐馆吃顿饭或者给他们放一天假。这会帮助他们提升积极性,让他们产生 bug 更少的代码。这里有个魔咒:要满足工程师,先满足他们的胃。
保持优秀和开放的文化
bug 终究会出现, bug 的发现过程可能会是这样子的:
- 业务人员找到你,并且对你说“嘿,我发现了一个 bug。”
- “不,这不可能,这种事儿根本就不可能发生!”
- 不应该这样啊。
- 为什么会这样呢?
- 哦,我知道了,原来如此。
- 它是如何通过测试的呢?
- 对不起,这个特性不是我编写的!
在你的公司和团队中,保持一种开放的文化非常重要。
我们所能做到的就是尽可能减少错误出现的概率,而不是将其完全消除。如果你觉得其他的方式能够降低系统引入 bug 的可能性,从而能够避免热修复部署的话,请在评论区进行讨论。
我希望你们能够像我们一样,早就忘记了上一次热修复部署是什么时候的事情了。简而言之:因为出现 bug 所引起的电话呼叫越少,晚上就能睡得越安稳。
关于作者
 Adam Pahlevi的乐趣在于编写具有可读性和高性能的代码。目前,他就职于一家印度尼西亚 / 日本支付网关公司:Veritrans,并担任软件工程师。他曾经出版过图书并发表过很多文章,还担任过 workshop/ 技术大会的演讲者。他使用 Ruby 编程语言。
Adam Pahlevi的乐趣在于编写具有可读性和高性能的代码。目前,他就职于一家印度尼西亚 / 日本支付网关公司:Veritrans,并担任软件工程师。他曾经出版过图书并发表过很多文章,还担任过 workshop/ 技术大会的演讲者。他使用 Ruby 编程语言。
查看英文原文: The Way to No-Hotfix Deployment

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论