
 该本章首次发布于 Computer杂志,在此由 InfoQ&IEEE Computer Society__ 为您呈现。
该本章首次发布于 Computer杂志,在此由 InfoQ&IEEE Computer Society__ 为您呈现。
目前的高性能计算系统(High-performance computing systems, HPC 系统)是为能高效地执行浮点密集型工作而设计 1。HPC 系统主要用于科学模拟,这些模拟有着高计算密度、高本地化和常规化分区数据结构等特性。这些应用需求推动着处理器设计往更快的 SIMD(单指令,多数据)架构单元和不断降低访问延迟的深层缓存层次结构方向发展。
在系统级别,内存和互连带宽比峰值计算性能的增长速度要慢得多,但是规则性和本地化减轻了该问题的影响。与此同时,不断新兴的处理器架构也推动着应用开发往不断探索它们自身特性的实现上发展。
尽管如此,来自新兴领域的应用却有着不规则性,比如:生物信息学、社区发现、复杂网络、语义数据库、知识发现、自然语言处理、模式识别和社交网络分析等。通常情况下,它们使用基于指针的数据结构,如:不平衡树、非结构网格和图像。虽然这些数据结构大部分都是并行的,但在空间和时间上有着比较差的本地化。有效地分割这些数据结构是一个非常大的挑战。另外,这些数据结构通常在应用程序执行过程中动态变化,比如:添加或删除图象中一个节点。
复杂的高速缓存层次结构对于这类不规则应用来说是效率很差的。系统性能主要由片外带宽决定,该带宽用于系统内存访问本地数据,以及网络访问其他节点上的数据。这种情况下,单一的控制线程往往无法提供足够的并发来调用所有可用带宽。因此,多线程体系结构通常会通过以下几种方式尽量容忍,而不是降低内存访问延迟。比如:在多线程间切换,不断产生内存引用,以及最大限度提高带宽利用率。
研究动机
Cray XMT 是多节点超级计算机,专门设计用于开发和执行不规则的应用程序 2。它的架构基于三大“支柱”:全局地址空间、细粒度同步和多线程。
XMT 是一个分布式内存共享(Distributed Shared Memory ,DSM)系统,它的全局共享地址空间以很细的粒度均匀地分布在不同节点的内存上。每个节点都集成了一个 ThreadStorm 定制处理器,然后以循环为基础切换于众多硬件线程之间。该方法允许系统容忍访问本地节点内存所带来的系统延迟的同时,也容忍访问远程节点内存所带来的网络延迟。
与最新 HPC 系统不同的是,XMT 提供了一个系统范围的编程模型,从而在不需要优化本地化的情况下,简化了需要占用大量内存应用的执行。就算现代 HPC 系统集成了类似图像处理单元(GPUs)的多线程架构,它们还是更适合规则型应用。目前为止,它们的设计并不能容忍访问其它节点内存所带来的延迟。在很多情况下,它们甚至无法容忍访问同一节点中其它处理器内存所带来的延迟。另外,协调内存访问和最优化带宽使用率需要对数据进行分区以及大量的编程工作。
西北太平洋国家实验室的 CASS-MT 项目目前正在为不规则应用研究大型多线程架构。我们将展示多线程架构中的一个分类,并讨论它们与 Cray 的联系。然后我们会提出一些改进方法来演进这些架构,评估出 XMT 未来的可能设计。该设计将在每个节点集成多核的同时,完成对下一代网络互连的集成。最后,我们将展示远程引用聚集的硬件机制集成如何优化网络利用率。
多线程架构
多线程处理器可以同时处理来自同一管道内不同控制进程的指令。有两种基本类型的多线程处理器:其中一类是只从循环中的单一进程发出指令,另一类是从同一循环内的多个进程发出指令。
许多先进的无序超标量处理器,如 IBM Power6 和 Power7 或最新的 Intel Nehalem 和 Sandy Bridge 架构,都支持同步多线程技术(Simultaneous multithreading technique,SMT)。SMT 保持所有内核中多个线程处于活跃状态:处理器识别每个独立指令,然后将它们同时发送给内核中的多个执行单元,从而保持处理器资源的高利用率。
每个时钟周期从单一线程发出指令的多线程处理器,称做 _ 临时多线程处理器 _,不同线程间交替来保持管道(通常按顺序)填满及避免拥塞。临时多线程可以是粗粒度(块多线程)或细粒度的(指令 / 周期交错)。
块多线程只有当指令产生具有长期延迟的拥塞时才从一个线程切换到另一个,比如,高速缓存丢失了对片外存储器的访问请求。Intel 的 Montecito 就使用了块多线程技术。
交错多线程以循环为基础来交换线程。Cray XMT 中的 ThreadStorm 处理器,以及 Tera MTA 和 Cray MTA-2 中的前身都是使用交错处理器。Sun UltraSPARC T1、T2 和 SPARC T3 中的 SPARC 内核也采用了交错式多线程模式。
UltraSPARC T1 含有 8 个内核,每个内核有 4 个线程。T2 同样拥有 8 个内核,但却有双倍的执行单元和线程数量,来允许它在每个时钟周期从 8 个线程中的两个同时发出指令。而 SPARC T3 则在 UltraSPARC T2 的基础上加倍了内核数量。这些内核每个周期从不同的线程发出指令。当具有长延迟事件发生时,它们会将产生该事件的线程从调度表中删出,直到该事件完成为止 3。
与此同时,GPU 还集成了多线程调度块(弯曲或波阵面),它能有效地在 SIMD 执行单元中切换以容忍长延迟的内存操作 4。GPU 拥有数百个浮点单元和大量内存带宽,并有片上内存对常用数据的访问进行优化。但目前的 GPU 被设计为拥有私有内存的加速器,更适合常规的工作负荷。
通常基于缓存的处理器在不规则应用中会因为不可预测的内存访问遇到大量的缓存缺失。一般说来临时多线程架构会更适合这些应用,因为它们可以在内存子系统负载或写数据时切换到其它就绪线程来容忍长延迟内存访问,因此它们不需要缓存来降低访问延迟。
Cray XMT 架构
Cray XMT 含有双插槽酷龙 AMD 服务节点,及定制的多线程计算节点,每个节点有一个 ThreadStorm 处理器。该系统可以扩展到带有 128T 共享内存的 8192 个计算节点。然而,目前最大的系统只有 512 个计算节点。
所有 ThreadStorm 都是 64 位 VLIW(极长指令字)处理器,它含有一个内存单元,一个算术运算单元和一个控制单元。它在 128 个细粒度的硬件流间以周期为基础互相切换以容忍由内存访问而产生的拥塞。
在运行时,系统将软件线程映射到硬件流,其中包括一个程序计数器,一个状态字,一组目标和异常寄存器,以及 32 个通用寄存器。所有指令管道都有 21 个阶段。根据设计,如果前一个指令还未退出管道,处理器就不会从同一个硬件流中发出新指令。
因为内存操作长于 21 个周期,所以处理器支持超前,允许同一硬件流每 21 个周期发出独立指令。编译器将为每个指令识别其是否超前,并且可支持多达 8 个指令。因此每个硬件流可以同时拥有多达 8 个挂起存储器,最多为整个处理器挂起 1024 个内存操作。而内存操作可以在无序中完成。
ThreadStorm 有一个 64KB,4 路关联指令缓存来探索代码位置,并以所谓的 500MHz 频率来执行。
处理器通过点对点的 HyperTransport 通道联接到互连网络上。网络接口控制器(Network Interface Controller,NIC)不执行任何聚合操作,由单一的网络数据包封装所有存储器操作。其网络子系统基于 Cray SeaStar2 互连 5,其拓扑是个 3D 的环面。
每个 ThreadStorm 内存控制器管理多达 8GB 的 128 位宽 DDR(Double Data Rate,双倍数据比率)RAM,并拥有一个 128KB、4 路关联访问缓存来降低访问延迟。应用通过共享内存抽象访问系统内存:系统可以通过任意一个 ThreadStorm 处理器连接到网络,直接将操作加载或保存到任意物理内存空间。
系统以 64B 粒度争夺内存来分配逻辑顺序数据到接有不同处理器的物理内存。不论应用将用到多少个处理器,数据都会几乎均匀地被分配到整个系统所有节点的内存上。
与 64 位内存字相关的:
- 全空锁位;
- 一个指针转发位,发送包含指针而非数据的存储位置,允许自动生成一个新的内存引用;以及
- 两个陷阱位可以发出信号说明该存储位置存储或加载地址。
ThreadStorm 可每秒最多生成 500 万个内存引用(Mref/s),这意味着:每个时钟周期就有一个引用。尽管如此,MC 可以承受高达 100Mref/s 的 DDR RAM,而 SeaStar2 NIC 可达 140Mref/s。对于有 128 个节点的系统,其内存操作延迟在~68 周期(达到本地内存控制器的高速缓存)和~1200 周期(错失最远远程内存控制器的高速缓存)之间。
近期推出的 Cray XMT2 中的处理器架构并没有改变。唯一的显著改动的新特性就是更高的本地内存带宽,还有使用 DDR2 插槽和一个额外的内存通道,以及提高了本地内存访问延迟(约一倍)等。
与其它架构的对比
与其它多线程架构相比,比如:GPU 或 UltraSPARC 处理器,XMT 在开发和执行需要大量内存空间的不规则应用上更加灵活,尤其在数据分析上。
GPU 和 UltraSPARC 处理器
除了拥有数千个线程,GPU 还有大量的内存带宽。然而,为了最大化内存使用率,应用程序需以规则的模式访问内存。为了允许 MC 合并多个内存操作到一个单一的大型内存事务中,运行于同一 SIMD 单元里的线程实际上应该访问顺序内存位置,或至少,应将内存位置归划到同一内存段。如果内存操作访问不同的内存段,他们就要请求多个事件(最坏的情况就是每个操作请求一个事件),从而造成了内存带宽的浪费。换句话说,地址带宽明显比数据带宽慢得多。
在某些情况下,可能利用 GPU 的纹理单元加载用于通用计算的数据,该纹理单元是在图形渲染过程中为像素加载色彩数据的内存单元。该方法可以降低与非对称内存执行相关的损失。但是,由于其图形原型,纹理内存主要在数据有良好的空间局部性和应用程序能较好地利用连接纹理缓存时有效。
GPU 也拥有快速片上暂存存储器,它可以减少访问小块高本地化数据所带来的访问延迟。不规则应用的开发人员有时可以利用暂存对聚集数据使用一些编程技巧,使得片上内存访问更规则。尽管该方法可行,但却要消耗大量的人力。
最新一代 GPU 也含有数据缓存,但如果应用程序有非常不规则的访问模式,那么它们很可能就会因为大量的失误而失效。当应用程序的不规则存在于控制流程,或线程执行于 GPU 分支中同一个 SIMD 单元的时候,就会有性能问题。
对于有着大数据集的不规则应用,在多 GPU 上其可扩展性依然是个挑战。目前为止,一个 GPU 板最大的内存空间是 6GB。由于不同 GPU 间没有共享内存抽象,应用开发者必须手动对数据分区,同时 PCI Express 总线间的沟通可能会造成维护共享状态的算法超负荷。
就算最新 GPU 有着对等和直接访问,GPU 间的数据分区还是必需的。在集群级别上,当需要跨网络时,分区变得更加复杂,通信开销也随之增加。
UltraSPARC 处理器在节点可拓展性上表现出了同样的困难。在一个节点上,它们显示出一个抽象的共享内存。尽管如此,在节点间,它们还是表现出一贯的分布式内存设置,并要求分布式内存编程方法。Ultra-SPARC 处理器的设计仅仅隐藏了节点等级的延迟,并没有在集群级别的网络延迟上下任何功夫。
XMT 的优势
XMT 为了节点间的拓展做了专门设计。它的抽象共享内存,水平内存层次结构和细粒度同步提供了一个简单的全机编程模式。需要大容量内存的程序可以使用 XMT 所有可用内存,而不需要开发人员重组其代码。
ThreadStorm 处理器可以在单字粒度上处理本地或远程(对其它节点)内存操作。内存加扰的目的在于分配内存和网络访问模式,减少热点。相对于有限资源,ThreadStorm 的大量线程允许它容忍互连网络的延迟。这些特性减少了可用数据带宽的同时,也消除了性能上的损失,以及在高度不规则模式下内存访问上所花费的编程精力。
一般情况下,除了更简单的机器范围编程模型,当在单节点内存容不下数据时,XMT 比其它架构更有效;或数据在单一模板内存容不下时,XMT 也比 GPUs 更有效;同时当高度不规则模式产生缓存或者在协调内存不力的时候,XMT 也更有效。比如,一个开发人员可以执行一个简单的广度查询算法时,不用考虑数据移动或内存模式优化,就能获得良好的性能和拓展性。
另外一个例子是,与大量字典匹配的 Aho-Corasick 字符 6。基于缓存的处理器,如果模式存在于缓存中,那么其匹配流程就会很快。如果不是,流程速度就会有所下降,因为处理器需要从内存中获取模式。对模式结构的访问是不可预测的,难以凝聚。
当算法本身与字典匹配时(最差情况),它会彻底地探索模式数据和架构,而该架构是针对定期访问体验的性能下降而优化的。另一方面,当算法仅与一小部分模式匹配,并可探索缓存时(最优情况),XMT 不需要达到同样的性能峰值。系统的平板存储器层次结构保证了性能的稳定性:最好情况下的性能与最坏的时候没有大的区别。
模拟 XMT
为了支持我们在大型多线程系统上的研究,我们开发了一个新型并联式全系统模拟器,它可以在 48 核主机(四路酷龙 6176SE)上以每秒高达 250 千转的速度重现具有 128 个处理器的 XMT、一个大型经典不规则应用集合,以及低于 10% 精度的错误频率 7。该模拟器可执行不可修改的 XMT 应用,支持所有的系统架构特性,并集成了一个可以快速而且准确描述网络和内存通信事件的参数化模型,同时也考虑了争夺所带来的影响 8。我们使用该模拟器来定位当前 XMT 架构中的瓶颈,并提出一个基于多核的可能演变来克服这些限制。
我们通过检测模拟器计数器中由于挂起内存请求而导致的更新管道拖延,来初步估计一个具有 128 个处理器的 XMT 在总体执行时间上由内存操作所带来的影响。图 1a 展示了一个字典与 20000 个最常见英语单词相比较的 Aho-Corasick 字符匹配算法 6 的模拟执行时间,以及从 ASCII 字母表获得的统一分布的随机符号,和平均长度为 8.5B 的输入集。
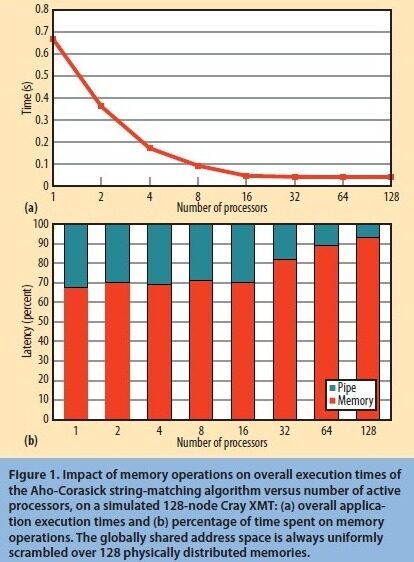
图 1 在模拟的 128 节点 CrayXMT,内存操作对 Aho-Corasick 字符匹配算法的总体执行时间的影响相对于活跃着的处理器数量:(a)总体应用程序执行时间,(b)在内存操作上所消耗的时间比。全局共享地址空间总是统一分配在 128 个物理内存上。
就算系统没有将所有处理器用于内存操作,它依然将地址空间分配在所有节点上。如图 1b 所展示的,一直到 16 个处理器都变活跃,系统在等待内存访问上所花的时间都保持在 70% 左右。当多于 16 个处理器变活跃时,总体执行时间却不再下降,系统等待内存访问时间反而增加。当达到 128 个活跃处理器时,系统等待时间则超过了 90%。
为了找出造成该行为的原因,我们使用模拟器监控 NIC 和 MC 上内存引用流量。图 2 展示了当 128 个处理器都活跃时,网络 NIC 的传入流量。实线表示请求访问 NIC 的输入应用数量,虚线则表示 NIC 每秒可接收引用的最大速率(140Mref/s 双向)。该图表显示了很多应用程序中,其请求输入频率远远大于可用 NIC 带宽,从而拖延了远程内存引用,造成了总体执行的延迟。
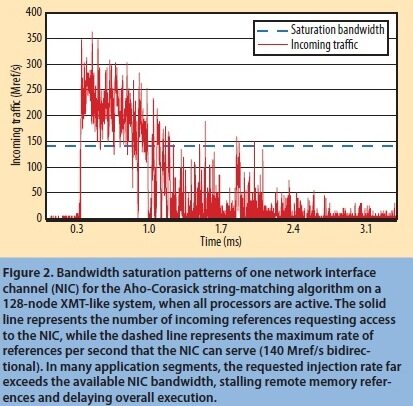
图 2 当所有处理器都处于活跃状态时,在 128 个节点 XMT 类似系统上,通过 Aho-Corasick 字符匹配算法所得的单一网络接口通道的带宽饱和模式。实线表示请求 NIC 访问的输入引用数量,而虚线则表示 NIC 每秒能服务的最大引用数(140Mref/s 双向)。在很多应用程序中,请求输入数往往远远大于可用的 NIC 带宽,从而拖延了远程内存引用,造成了总体执行的延迟。
关于 MC 接口,我们发现其带宽饱和影响要比 NIC 小很多。尽管这可能看起来与持续引用数相矛盾,但是它是由同一地址分配来决定的。举个例子,在 128 个节点配置中,由于分配,处理器一般从 128 个可能的目的节点中产生一个本地引用和 127 个远程应用。只有本地引用才会使用 MC 频道,而远程的则使用 NIC 频道。但是从其它节点来的输入引用会流入 NIC 和 MC 频道。结合输入和输出引用,NIC 频道比 MC 频道能容忍更高的流量.
多核设计的发展
基于这些结果,我们设计了一种基于 XMT 的多核系统架构。我们使用模拟器来决定内核和 MC 数量的最佳组合来提高总体系统性能。
系统设计
如图 3 所示,该设计包括多个类似 ThreadStorm 的内核,其中每个硬件线程包含一个专用的注册文件和一个加载 / 存储队列(Load/Store Queue,LSQ)。所有队列链接到一个分配模型,该模型在系统所有内存模块中统一分配内存操作。每个处理器包括多个独立的 MC,其中每个 MC 连接到不同的片外内存模块。所有部件都通过片上分组交换网络(Network on Chip,NoC)连接,配置为二维的网格连接,并且每个都有自己独立的路由器。一个集成的 NIC 将处理器连接到系统中的其它节点上。NoC 的延迟仅占系统平均内存引用延迟的 2% 还少。
(Click on the image to enlarge it)(点击图片扩大)

图3 基于XMT 的多核处理器架构。
性能发展
我们使用模拟器来评估该设计在32 个节点的类XMT 系统中,每个处理器内核数目从1 增加到16,以及每个处理器中独立MC 数目从1 增加到8 时的情况。我们将NIC 带宽设置为670Mref/s(目前XMTSeaStar2 网络5 的5 倍,并类似于Cray Gemini 内部连接)及每个MC 带宽为200Mref/s(目前XMT DDR 内存频道的两倍)。同时利用延迟和带宽参数来模拟与网络线路图1 和DDR3 内存需求相关的模拟。
图4 展示了使用三个基准评价出的结果:我们用于之前实验的Aho-Corasick 字符匹配应用程序;BFS,一个常见内核,用于基于图形数据结构的应用程序中;还有矩阵乘法,一个典型的常规内核,我们常用于评估我们的设计决策在更常见及有更少限制的应用上所带来的影响。图中实心“理想”线表示当网络和内存引用没有任何争夺,以及饱和从未发生时所获取的性能。这些线说明随着每个处理器的内核数量增加,这些基准评估有足够的并行去拓展。
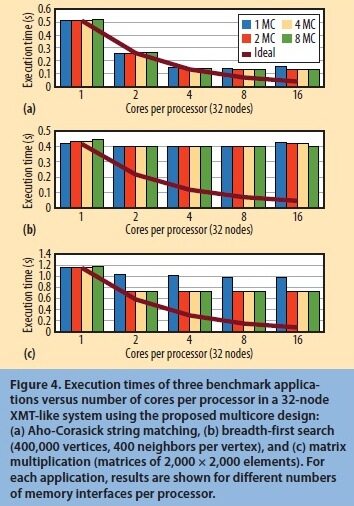
图4 在32 节点类XMT、使用推荐的多核设计系统中每个处理器的内核数量,相对于三个基准评价下应用程序的执行时间:(a)Aho-Corasick 字符匹配,(b)广度优先查询(每点有400000 个顶点,400 个邻点),以及(c)矩阵乘法(2000x2000 因子矩阵)。每个应用程序中,针对每个处理器在不同内存接口数量的结果。
如图4a 所示,在字符匹配时,每个处理器中的MC 数量并不会显著地影响总体性能。这是内存管理以及优化应用来减少热点所带来的一个结果。对于最高四个内核的处理器, 该提速几乎是线性,进入停滞期是由于NIC 达到饱和所至。
如图4b 所示,对于BFS,结果则有很大的不同。BFS 是个同步密集型基准(它对每个访问过的顶点都用了一个锁),而NIC 早已因为基础配置中的重试操作达到饱和。因此,应用程序不能拓展。
在矩阵乘法中,如图4c 所示,使用更多的MC(达到两个)能提高性能,因为它能在某些内存接口减少热点。如果每个处理器有多于两个的内核和MC,瓶颈又变成了NIC,应用程序性能的稳定性则与内核或MC 的数量无关。
这些实验证明多核方法能激发不规则应用下一代互连的开发。事实上,如果有一个能容忍比现有SeaStar2 几乎大五倍带宽的网络,该系统则会由于更高的输入速率提高性能到每个节点4 核。规则应用也会受益于由每个处理器多个MC 提供的更高的本地内存带宽。
内存引用汇总
在XMT 以及我们的多核设计中,一个小的网络数据包会封装所有远程内存操作,产生细粒度流量。但这种小消息通常会产生高费用,因为所有网络中减少了的头/ 负荷比并不对这种流量进行优化。
为了减轻这个影响,一些互连系统会将小数据包聚合起来。通常它们要么在自定义的路由器硬件上执行,比如在IBM Power7 集线器模块9,要么在软件中通过特定驱动程序和API 实现。尽管如此,类似XMT 的机器,它的每个内存加载/ 存储都是直接映射到一个网络引用的,不包含任何中间软件层,而且后一种方法很难实现。
为了不通过设计一个昂贵的定制网络来减小由于小信息所带来的网络消耗,我们在我们的多核设计中集成了一个修改,它在处理器层执行网络引用集合。
硬件的实现
聚集机制通过缓冲到D 内存引用来运作,其中D 内存引用用于一个W 周期的时间窗口的同一目的节点(DST)。当到达D 内存引用或时间窗口已经消逝时,该机制会使用一个有着共享头的单一网络包往DST 发送所有在缓存器中的内存引用。
图5 展示了正在执行拟定机制的硬件设计。多核接口的LSQ 带有一个选择逻辑来决定分配给每个内存引用的DST。该选择逻辑使用DST 来放置FIFO(先入先出)缓存器,该缓存器保存了用于聚集的内存引用的数据—地址,值,内存操作码和控制位。
(Click on the image to enlarge it)(点击图片扩大)

图 5 用于聚集逻辑的硬件实现
系统中针对每个 DST 都有一个 FIFO 缓存器,所有的缓存器里又都有一些 D 引用。当 D 引用在缓存器中时,数据包创建逻辑使用缓存器里的所有内容和一个单一的头来创建一个网络数据包。每个 FIFO 缓冲器也都与一个从 W 周期开始的递减计数器相关联。当计数器到 0 时,就算缓存器是空的,数据包创建逻辑也会被激活。如果缓存器在计数器到达 0 前就已经变满时,该模块会马上将该数据包发送出去,并将计数器重置到 W。一个选择性搁置逻辑模块会防止处理器在缓存器已满而网络数据包无法再生成时,生成相同 DST 的进一步引用,比如:当聚集逻辑正在创建另外一个数据包。
在一个支持高数量节点的系统里,为每个 DST 执行一个 FIFO 缓存器需要大量的片上存储器。为了降低这个要求,很可能要利用到多级分层聚合方案,它可以让每个缓存器收集指向节点组的内存引用。然后节点组中的一个节点会将引用分配到它们特定的目的地。该方法的代价就是稍微高的聚合逻辑复杂度和延迟。但是,进一步对每个处理器增加一些线程可以减轻增加的延迟。
可扩展性分析
我们把我们的聚集机制聚集在一个具有 32 个节点 XMT 仿真模块,并初步评估缓冲区大小 D 和时间窗口长度 W 间的权衡。我们发现最佳参数是 D=16 和 W=32。随着节点数的增多,填充缓存所需时间以及平均网路延迟也越来越多,这个结果显然取决于机器上节点数量。
我们重新执行前面图 4 所展示使用相同三个基准的多核配置拓展分析。图 6 将结果与带和不带聚合逻辑进行了比较;这种情况下,每个处理器有两个 MC,而我们发现这是前面图标中最好的权衡。性能的改进在所有基准下都是显著的,越来越接近理想拓展。
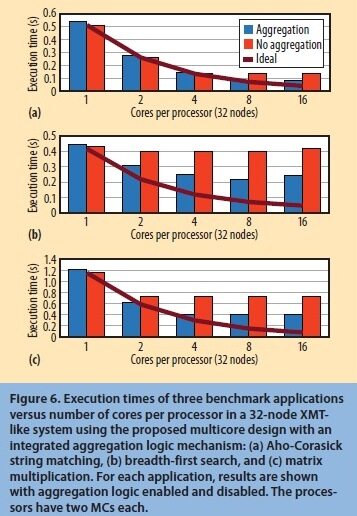
图 6 在使用结合了集成的聚集逻辑机制而提议的多核设计,具有 32 个节点类似 XMT 的系统里,三个基准下应用程序执行时间相对于每个处理器中的内核数量:(a)Aho-Corasick 字符匹配,(b)广度优先查询,和(c)矩阵乘法。对于每个应用,其结果在聚合逻辑启用和禁用时都表示出来了。每个处理器都带有两个 MC。
高性能计算系统的当前趋势是往采用先进缓存架构的处理器方向发展,它的目标是浮点密集型运算。尽管这些方案适合那些具有高计算密度、高本地化和常规数据结构等特性的应用。但是它们却不适合用于处理那些不断涌现的数据密集型的不规则应用,这些应用呈现出大型非结构数据集,而这些数据集则具有差本地化、高同步强度,以及内存占用远远超出通用计算节点可用范围等特性。这些应用提出了对新型架构的需求,该新架构需能通过大规模多线程容忍而非降低延迟,并有着更简单的全机编程模式。类似数据汇总和压缩的新方案需能更好地使用未来互连基础设施,以及在性能上的显著提高。验证这些方案同时也需要新的工具,如优化了的可拓展模拟器和原型平台。
参考文献
- P. Kogge et al., “ ExaScale Computing Study: Technology Challenges in Achieving Exascale Systems ,” DARPA Information Processing Techniques Office, 2008;
- J. Feo et al., “ELDORADO,” Proc. 2nd ACM Int’l Conf. Computing Frontiers (CF 05), ACM, 2005, pp. 28-34.
- J.L. Shin et al., “A 40 nm 16-core 128-Thread CMT SPARC SoC Processor,” Proc. 2010 IEEE Int’l Solid-State Circuits Conf. (ISSCC 10), IEEE, 2010, pp. 98-99.
- “NVIDIA’s Next Generation CUDA Compute Architecture: Fermi,” white paper, Nvidia, 2009;
- R. Brightwell et al., “SeaStar Interconnect: Balanced Bandwidth for Scalable Performance,” IEEE Micro, May 2006, pp. 41-57.
- A. Tumeo, O. Villa, and D.G. Chavarría-Miranda, “Aho- Corasick String Matching on Shared and Distributed- Memory Parallel Architectures,” IEEE Trans. Parallel and Distributed Systems, Mar. 2012, pp. 436-443.
- O. Villa et al., “ Fast and Accurate Simulation of the Cray XMT Multithreaded Supercomputer ,” preprint, IEEE Trans. Parallel and Distributed Systems, 2012;
- S. Secchi, A. Tumeo, and O. Villa, “Contention Modeling for Multithreaded Distributed Shared Memory Machines: The Cray XMT,” Proc. 11th IEEE/ACM Int’l Symp. Cluster, Cloud and Grid Computing (CCGRID 11), ACM, 2011, pp. 275-284.
- B. Arimilli et al., “The PERCS High-Performance Interconnect,” Proc. 18th IEEE Symp. High-Performance Interconnects (HOTI 10), IEEE, 2010, pp. 75-82.
关于作者
AntoninoTumeo是西北太平洋国家实验室(Pacific Northwest National Laboratory)的一名科研专家。他的研究范围包括高性能体系结构的建模和仿真,硬件 - 软件协同设计,FPGA 原型设计和 GPGPU 计算。Tumeo 从意大利米兰理工大学(Politecnico di Milano, Italy)获得了计算机工程的博士学位。其联系方式为: antonino.tumeo@pnnl.gov 。
Simone Secchi是西北太平洋国家研究室的一名博士后研究助理。他的研究范围包括高性能计算架构的建模和并行软件仿真,基于 FPGA 的多处理器系统的能量感知仿真,以及高等芯片网络架构。Secchi 从意大利卡利亚里大学(University of Cagliari, Italy)获得电子和计算机工程博士学位。其联系方式为: simone.secchi@ pnnl.gov 。
Oreste Villa是西北太平洋国家研究室的一名科研专家。它的研究范围包括计算机体系架构和仿真,科学计算加速器,GPGPU 和不规则应用程序。Villa 从意大利米兰理工大学获得计算机工程博士学位。其联系方式为: oreste.villa@pnnl.gov 。
Computer 是 IEEE 计算机协会的旗舰出版物,出版了很多为同行热议且广受赞誉的文章。这些文章大都由专家执笔撰写,代表了计算机技术软硬件及最新应用的领先研究。它提供较商业杂志更多的技术内容,而较研究学术期刊具有更多的实践性思想。 Computer 传递着可适用于日常工作环境的有用信息。
参考英文原文: Designing Next-Generation Massively Multithreaded Architectures for Irregular Applications
感谢陈菲对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论