
1. 背景
1.1. 编解码技术
通常我们也习惯将编码(Encode)称为序列化(serialization),它将对象序列化为字节数组,用于网络传输、数据持久化或者其它用途。
反之,解码(Decode)/ 反序列化(deserialization)把从网络、磁盘等读取的字节数组还原成原始对象(通常是原始对象的拷贝),以方便后续的业务逻辑操作。
进行远程跨进程服务调用时(例如 RPC 调用),需要使用特定的编解码技术,对需要进行网络传输的对象做编码或者解码,以便完成远程调用。
1.2. 常用的编解码框架
1.2.1. Java 序列化
相信大多数 Java 程序员接触到的第一种序列化或者编解码技术就是 Java 默认提供的序列化机制,需要序列化的 Java 对象只需要实现 java.io.Serializable 接口并生成序列化 ID,这个类就能够通过 java.io.ObjectInput 和 java.io.ObjectOutput 序列化和反序列化。
由于使用简单,开发门槛低,Java 序列化得到了广泛的应用,但是由于它自身存在很多缺点,因此大多数的 RPC 框架并没有选择它。Java 序列化的主要缺点如下:
1) 无法跨语言:是 Java 序列化最致命的问题。对于跨进程的服务调用,服务提供者可能会使用 C++ 或者其它语言开发,当我们需要和异构语言进程交互时,Java 序列化就难以胜任。由于 Java 序列化技术是 Java 语言内部的私有协议,其它语言并不支持,对于用户来说它完全是黑盒。Java 序列化后的字节数组,别的语言无法进行反序列化,这就严重阻碍了它的应用范围;
2) 序列化后的码流太大: 例如使用二进制编解码技术对同一个复杂的 POJO 对象进行编码,它的码流仅仅为 Java 序列化之后的 20% 左右;目前主流的编解码框架,序列化之后的码流都远远小于原生的 Java 序列化;
3) 序列化效率差:在相同的硬件条件下、对同一个 POJO 对象做 100W 次序列化,二进制编码和 Java 原生序列化的性能对比测试如下图所示:Java 原生序列化的耗时是二进制编码的 16.2 倍,效率非常差。
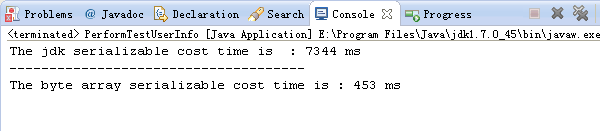
图 1-1 二进制编码和 Java 原生序列化性能对比
1.2.2. Google 的 Protobuf
Protobuf 全称 Google Protocol Buffers,它由谷歌开源而来,在谷歌内部久经考验。它将数据结构以.proto 文件进行描述,通过代码生成工具可以生成对应数据结构的 POJO 对象和 Protobuf 相关的方法和属性。
它的特点如下:
1) 结构化数据存储格式(XML,JSON 等);
2) 高效的编解码性能;
3) 语言无关、平台无关、扩展性好;
4) 官方支持 Java、C++ 和 Python 三种语言。
首先我们来看下为什么不使用 XML,尽管 XML 的可读性和可扩展性非常好,也非常适合描述数据结构,但是 XML 解析的时间开销和 XML 为了可读性而牺牲的空间开销都非常大,因此不适合做高性能的通信协议。Protobuf 使用二进制编码,在空间和性能上具有更大的优势。
Protobuf 另一个比较吸引人的地方就是它的数据描述文件和代码生成机制,利用数据描述文件对数据结构进行说明的优点如下:
1) 文本化的数据结构描述语言,可以实现语言和平台无关,特别适合异构系统间的集成;
2) 通过标识字段的顺序,可以实现协议的前向兼容;
3) 自动代码生成,不需要手工编写同样数据结构的 C++ 和 Java 版本;
4) 方便后续的管理和维护。相比于代码,结构化的文档更容易管理和维护。
1.2.3. Apache 的 Thrift
Thrift 源于 Facebook,在 2007 年 Facebook 将 Thrift 作为一个开源项目提交给 Apache 基金会。对于当时的 Facebook 来说,创造 Thrift 是为了解决 Facebook 各系统间大数据量的传输通信以及系统之间语言环境不同需要跨平台的特性,因此 Thrift 可以支持多种程序语言,如 C++、C#、Cocoa、Erlang、Haskell、Java、Ocami、Perl、PHP、Python、Ruby 和 Smalltalk。
在多种不同的语言之间通信,Thrift 可以作为高性能的通信中间件使用,它支持数据(对象)序列化和多种类型的 RPC 服务。Thrift 适用于静态的数据交换,需要先确定好它的数据结构,当数据结构发生变化时,必须重新编辑 IDL 文件,生成代码和编译,这一点跟其他 IDL 工具相比可以视为是 Thrift 的弱项。Thrift 适用于搭建大型数据交换及存储的通用工具,对于大型系统中的内部数据传输,相对于 JSON 和 XML 在性能和传输大小上都有明显的优势。
Thrift 主要由 5 部分组成:
1) 语言系统以及 IDL 编译器:负责由用户给定的 IDL 文件生成相应语言的接口代码;
2) TProtocol:RPC 的协议层,可以选择多种不同的对象序列化方式,如 JSON 和 Binary;
3) TTransport:RPC 的传输层,同样可以选择不同的传输层实现,如 socket、NIO、MemoryBuffer 等;
4) TProcessor:作为协议层和用户提供的服务实现之间的纽带,负责调用服务实现的接口;
5) TServer:聚合 TProtocol、TTransport 和 TProcessor 等对象。
我们重点关注的是编解码框架,与之对应的就是 TProtocol。由于 Thrift 的 RPC 服务调用和编解码框架绑定在一起,所以,通常我们使用 Thrift 的时候会采取 RPC 框架的方式。但是,它的 TProtocol 编解码框架还是可以以类库的方式独立使用的。
与 Protobuf 比较类似的是,Thrift 通过 IDL 描述接口和数据结构定义,它支持 8 种 Java 基本类型、Map、Set 和 List,支持可选和必选定义,功能非常强大。因为可以定义数据结构中字段的顺序,所以它也可以支持协议的前向兼容。
Thrift 支持三种比较典型的编解码方式:
1) 通用的二进制编解码;
2) 压缩二进制编解码;
3) 优化的可选字段压缩编解码。
由于支持二进制压缩编解码,Thrift 的编解码性能表现也相当优异,远远超过 Java 序列化和 RMI 等。
1.2.4. JBoss Marshalling
JBoss Marshalling 是一个 Java 对象的序列化 API 包,修正了 JDK 自带的序列化包的很多问题,但又保持跟 java.io.Serializable 接口的兼容;同时增加了一些可调的参数和附加的特性,并且这些参数和特性可通过工厂类进行配置。
相比于传统的 Java 序列化机制,它的优点如下:
1) 可插拔的类解析器,提供更加便捷的类加载定制策略,通过一个接口即可实现定制;
2) 可插拔的对象替换技术,不需要通过继承的方式;
3) 可插拔的预定义类缓存表,可以减小序列化的字节数组长度,提升常用类型的对象序列化性能;
4) 无须实现 java.io.Serializable 接口,即可实现 Java 序列化;
5) 通过缓存技术提升对象的序列化性能。
相比于前面介绍的两种编解码框架,JBoss Marshalling 更多是在 JBoss 内部使用,应用范围有限。
1.2.5. 其它编解码框架
除了上述介绍的编解码框架和技术之外,比较常用的还有 MessagePack、kryo、hession 和 Json 等。限于篇幅所限,不再一一枚举,感兴趣的朋友可以自行查阅相关资料学习。
2. Netty 编解码框架
2.1. Netty 为什么要提供编解码框架
作为一个高性能的异步、NIO 通信框架,编解码框架是 Netty 的重要组成部分。尽管站在微内核的角度看,编解码框架并不是 Netty 微内核的组成部分,但是通过 ChannelHandler 定制扩展出的编解码框架却是不可或缺的。
下面我们从几个角度详细谈下这个话题,首先一起看下 Netty 的逻辑架构图:
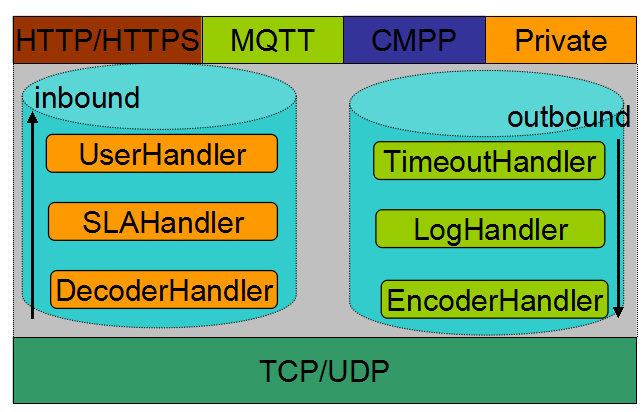
图 2-1 Netty 逻辑架构图
从网络读取的 inbound 消息,需要经过解码,将二进制的数据报转换成应用层协议消息或者业务消息,才能够被上层的应用逻辑识别和处理;同理,用户发送到网络的 outbound 业务消息,需要经过编码转换成二进制字节数组(对于 Netty 就是 ByteBuf)才能够发送到网络对端。编码和解码功能是 NIO 框架的有机组成部分,无论是由业务定制扩展实现,还是 NIO 框架内置编解码能力,该功能是必不可少的。
为了降低用户的开发难度,Netty 对常用的功能和 API 做了装饰,以屏蔽底层的实现细节。编解码功能的定制,对于熟悉 Netty 底层实现的开发者而言,直接基于 ChannelHandler 扩展开发,难度并不是很大。但是对于大多数初学者或者不愿意去了解底层实现细节的用户,需要提供给他们更简单的类库和 API,而不是 ChannelHandler。
Netty 在这方面做得非常出色,针对编解码功能,它既提供了通用的编解码框架供用户扩展,又提供了常用的编解码类库供用户直接使用。在保证定制扩展性的基础之上,尽量降低用户的开发工作量和开发门槛,提升开发效率。
Netty 预置的编解码功能列表如下:base64、Protobuf、JBoss Marshalling、spdy 等。
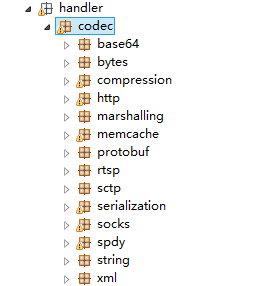
图 2-2 Netty 预置的编解码功能列表
2.2. 常用的解码器
2.2.1. LineBasedFrameDecoder 解码器
LineBasedFrameDecoder 是回车换行解码器,如果用户发送的消息以回车换行符作为消息结束的标识,则可以直接使用 Netty 的 LineBasedFrameDecoder 对消息进行解码,只需要在初始化 Netty 服务端或者客户端时将 LineBasedFrameDecoder 正确的添加到 ChannelPipeline 中即可,不需要自己重新实现一套换行解码器。
LineBasedFrameDecoder 的工作原理是它依次遍历 ByteBuf 中的可读字节,判断看是否有“\n”或者“\r\n”,如果有,就以此位置为结束位置,从可读索引到结束位置区间的字节就组成了一行。它是以换行符为结束标志的解码器,支持携带结束符或者不携带结束符两种解码方式,同时支持配置单行的最大长度。如果连续读取到最大长度后仍然没有发现换行符,就会抛出异常,同时忽略掉之前读到的异常码流。防止由于数据报没有携带换行符导致接收到 ByteBuf 无限制积压,引起系统内存溢出。
它的使用效果如下:
解码之前: +------------------------------------------------------------------+ 接收到的数据报 “This is a netty example for using the nio framework.\r\n When you“ +------------------------------------------------------------------+ 解码之后的 ChannelHandler 接收到的 Object 如下: +------------------------------------------------------------------+ 解码之后的文本消息 “This is a netty example for using the nio framework.“ +------------------------------------------------------------------+
通常情况下,LineBasedFrameDecoder 会和 StringDecoder 配合使用,组合成按行切换的文本解码器,对于文本类协议的解析,文本换行解码器非常实用,例如对 HTTP 消息头的解析、FTP 协议消息的解析等。
下面我们简单给出文本换行解码器的使用示例:
@Override protected void initChannel(SocketChannel arg0) throws Exception { arg0.pipeline().addLast(new LineBasedFrameDecoder(1024)); arg0.pipeline().addLast(new StringDecoder()); arg0.pipeline().addLast(new UserServerHandler()); }
初始化 Channel 的时候,首先将 LineBasedFrameDecoder 添加到 ChannelPipeline 中,然后再依次添加字符串解码器 StringDecoder,业务 Handler。
2.2.2. DelimiterBasedFrameDecoder 解码器
DelimiterBasedFrameDecoder 是分隔符解码器,用户可以指定消息结束的分隔符,它可以自动完成以分隔符作为码流结束标识的消息的解码。回车换行解码器实际上是一种特殊的 DelimiterBasedFrameDecoder 解码器。
分隔符解码器在实际工作中也有很广泛的应用,笔者所从事的电信行业,很多简单的文本私有协议,都是以特殊的分隔符作为消息结束的标识,特别是对于那些使用长连接的基于文本的私有协议。
分隔符的指定:与大家的习惯不同,分隔符并非以 char 或者 string 作为构造参数,而是 ByteBuf,下面我们就结合实际例子给出它的用法。
假如消息以“$_”作为分隔符,服务端或者客户端初始化 ChannelPipeline 的代码实例如下:
@Override public void initChannel(SocketChannel ch) throws Exception { ByteBuf delimiter = Unpooled.copiedBuffer("$_" .getBytes()); ch.pipeline().addLast( new DelimiterBasedFrameDecoder(1024, delimiter)); ch.pipeline().addLast(new StringDecoder()); ch.pipeline().addLast(new UserServerHandler()); }
首先将“$_”转换成 ByteBuf 对象,作为参数构造 DelimiterBasedFrameDecoder,将其添加到 ChannelPipeline 中,然后依次添加字符串解码器(通常用于文本解码)和用户 Handler,请注意解码器和 Handler 的添加顺序,如果顺序颠倒,会导致消息解码失败。
DelimiterBasedFrameDecoder 原理分析:解码时,判断当前已经读取的 ByteBuf 中是否包含分隔符 ByteBuf,如果包含,则截取对应的 ByteBuf 返回,源码如下:
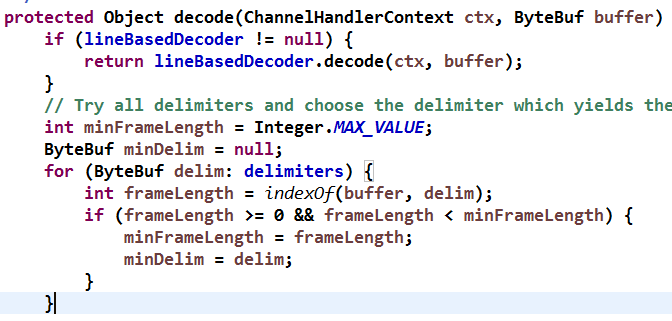
详细分析下 indexOf(buffer, delim) 方法的实现,代码如下:
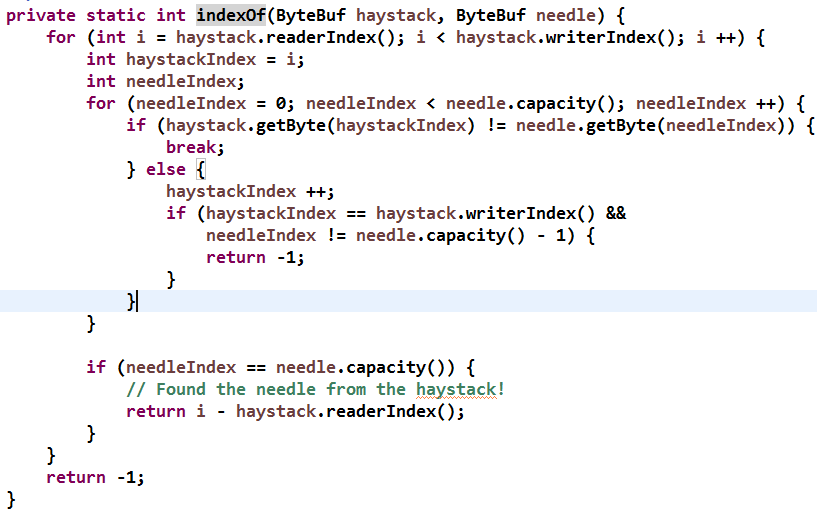
该算法与 Java String 中的搜索算法类似,对于原字符串使用两个指针来进行搜索,如果搜索成功,则返回索引位置,否则返回 -1。
2.2.3. FixedLengthFrameDecoder 解码器
FixedLengthFrameDecoder 是固定长度解码器,它能够按照指定的长度对消息进行自动解码,开发者不需要考虑 TCP 的粘包 / 拆包等问题,非常实用。
对于定长消息,如果消息实际长度小于定长,则往往会进行补位操作,它在一定程度上导致了空间和资源的浪费。但是它的优点也是非常明显的,编解码比较简单,因此在实际项目中仍然有一定的应用场景。
利用 FixedLengthFrameDecoder 解码器,无论一次接收到多少数据报,它都会按照构造函数中设置的固定长度进行解码,如果是半包消息,FixedLengthFrameDecoder 会缓存半包消息并等待下个包到达后进行拼包,直到读取到一个完整的包。
假如单条消息的长度是 20 字节,使用 FixedLengthFrameDecoder 解码器的效果如下:
解码前: +------------------------------------------------------------------+ 接收到的数据报 “HELLO NETTY FOR USER DEVELOPER“ +------------------------------------------------------------------+ 解码后: +------------------------------------------------------------------+ 解码后的数据报 “HELLO NETTY FOR USER“ +------------------------------------------------------------------+
2.2.4. LengthFieldBasedFrameDecoder 解码器
了解 TCP 通信机制的读者应该都知道 TCP 底层的粘包和拆包,当我们在接收消息的时候,显示不能认为读取到的报文就是个整包消息,特别是对于采用非阻塞 I/O 和长连接通信的程序。
如何区分一个整包消息,通常有如下 4 种做法:
1) 固定长度,例如每 120 个字节代表一个整包消息,不足的前面补位。解码器在处理这类定常消息的时候比较简单,每次读到指定长度的字节后再进行解码;
2) 通过回车换行符区分消息,例如 HTTP 协议。这类区分消息的方式多用于文本协议;
3) 通过特定的分隔符区分整包消息;
4) 通过在协议头 / 消息头中设置长度字段来标识整包消息。
前三种解码器之前的章节已经做了详细介绍,下面让我们来一起学习最后一种通用解码器 -LengthFieldBasedFrameDecoder。
大多数的协议(私有或者公有),协议头中会携带长度字段,用于标识消息体或者整包消息的长度,例如 SMPP、HTTP 协议等。由于基于长度解码需求的通用性,以及为了降低用户的协议开发难度,Netty 提供了 LengthFieldBasedFrameDecoder,自动屏蔽 TCP 底层的拆包和粘包问题,只需要传入正确的参数,即可轻松解决“读半包“问题。
下面我们看看如何通过参数组合的不同来实现不同的“半包”读取策略。第一种常用的方式是消息的第一个字段是长度字段,后面是消息体,消息头中只包含一个长度字段。它的消息结构定义如图所示:

图 2-3 解码前的字节缓冲区(14 字节)
使用以下参数组合进行解码:
1) lengthFieldOffset = 0;
2) lengthFieldLength = 2;
3) lengthAdjustment = 0;
4) initialBytesToStrip = 0。
解码后的字节缓冲区内容如图所示:

图 2-4 解码后的字节缓冲区(14 字节)
通过 ByteBuf.readableBytes() 方法我们可以获取当前消息的长度,所以解码后的字节缓冲区可以不携带长度字段,由于长度字段在起始位置并且长度为 2,所以将 initialBytesToStrip 设置为 2,参数组合修改为:
1) lengthFieldOffset = 0;
2) lengthFieldLength = 2;
3) lengthAdjustment = 0;
4) initialBytesToStrip = 2。
解码后的字节缓冲区内容如图所示:

图 2-5 跳过长度字段解码后的字节缓冲区(12 字节)
解码后的字节缓冲区丢弃了长度字段,仅仅包含消息体,对于大多数的协议,解码之后消息长度没有用处,因此可以丢弃。
在大多数的应用场景中,长度字段仅用来标识消息体的长度,这类协议通常由消息长度字段 + 消息体组成,如上图所示的几个例子。但是,对于某些协议,长度字段还包含了消息头的长度。在这种应用场景中,往往需要使用 lengthAdjustment 进行修正。由于整个消息(包含消息头)的长度往往大于消息体的长度,所以,lengthAdjustment 为负数。图 2-6 展示了通过指定 lengthAdjustment 字段来包含消息头的长度:
1) lengthFieldOffset = 0;
2) lengthFieldLength = 2;
3) lengthAdjustment = -2;
4) initialBytesToStrip = 0。
解码之前的码流:

图 2-6 包含长度字段自身的码流
解码之后的码流:

图 2-7 解码后的码流
由于协议种类繁多,并不是所有的协议都将长度字段放在消息头的首位,当标识消息长度的字段位于消息头的中间或者尾部时,需要使用 lengthFieldOffset 字段进行标识,下面的参数组合给出了如何解决消息长度字段不在首位的问题:
1) lengthFieldOffset = 2;
2) lengthFieldLength = 3;
3) lengthAdjustment = 0;
4) initialBytesToStrip = 0。
其中 lengthFieldOffset 表示长度字段在消息头中偏移的字节数,lengthFieldLength 表示长度字段自身的长度,解码效果如下:
解码之前:

图 2-8 长度字段偏移的原始码流
解码之后:

图 2-9 长度字段偏移解码后的码流
由于消息头 1 的长度为 2,所以长度字段的偏移量为 2;消息长度字段 Length 为 3,所以 lengthFieldLength 值为 3。由于长度字段仅仅标识消息体的长度,所以 lengthAdjustment 和 initialBytesToStrip 都为 0。
最后一种场景是长度字段夹在两个消息头之间或者长度字段位于消息头的中间,前后都有其它消息头字段,在这种场景下如果想忽略长度字段以及其前面的其它消息头字段,则可以通过 initialBytesToStrip 参数来跳过要忽略的字节长度,它的组合配置示意如下:
1) lengthFieldOffset = 1;
2) lengthFieldLength = 2;
3) lengthAdjustment = 1;
4) initialBytesToStrip = 3。
解码之前的码流(16 字节):
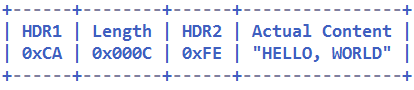
图 2-10 长度字段夹在消息头中间的原始码流(16 字节)
解码之后的码流(13 字节):

图 2-11 长度字段夹在消息头中间解码后的码流(13 字节)
由于 HDR1 的长度为 1,所以长度字段的偏移量 lengthFieldOffset 为 1;长度字段为 2 个字节,所以 lengthFieldLength 为 2。由于长度字段是消息体的长度,解码后如果携带消息头中的字段,则需要使用 lengthAdjustment 进行调整,此处它的值为 1,代表的是 HDR2 的长度,最后由于解码后的缓冲区要忽略长度字段和 HDR1 部分,所以 lengthAdjustment 为 3。解码后的结果为 13 个字节,HDR1 和 Length 字段被忽略。
事实上,通过 4 个参数的不同组合,可以达到不同的解码效果,用户在使用过程中可以根据业务的实际情况进行灵活调整。
由于 TCP 存在粘包和组包问题,所以通常情况下用户需要自己处理半包消息。利用 LengthFieldBasedFrameDecoder 解码器可以自动解决半包问题,它的习惯用法如下:
pipeline.addLast("frameDecoder", new LengthFieldBasedFrameDecoder(65536,0,2)); pipeline.addLast("UserDecoder", new UserDecoder());
在 pipeline 中增加 LengthFieldBasedFrameDecoder 解码器,指定正确的参数组合,它可以将 Netty 的 ByteBuf 解码成整包消息,后面的用户解码器拿到的就是个完整的数据报,按照逻辑正常进行解码即可,不再需要额外考虑“读半包”问题,降低了用户的开发难度。
2.3. 常用的编码器
Netty 并没有提供与 2.2 章节匹配的编码器,原因如下:
1) 2.2 章节介绍的 4 种常用的解码器本质都是解析一个完整的数据报给后端,主要用于解决 TCP 底层粘包和拆包;对于编码,就是将 POJO 对象序列化为 ByteBuf,不需要与 TCP 层面打交道,也就不存在半包编码问题。从应用场景和需要解决的实际问题角度看,双方是非对等的;
2) 很难抽象出合适的编码器,对于不同的用户和应用场景,序列化技术不尽相同,在 Netty 底层统一抽象封装也并不合适。
Netty 默认提供了丰富的编解码框架供用户集成使用,本文对较常用的 Java 序列化编码器进行讲解。其它的编码器,实现方式大同小异。
2.3.1. ObjectEncoder 编码器
ObjectEncoder 是 Java 序列化编码器,它负责将实现 Serializable 接口的对象序列化为 byte [],然后写入到 ByteBuf 中用于消息的跨网络传输。
下面我们一起分析下它的实现:
首先,我们发现它继承自 MessageToByteEncoder,它的作用就是将对象编码成 ByteBuf:

如果要使用 Java 序列化,对象必须实现 Serializable 接口,因此,它的泛型类型为 Serializable。
MessageToByteEncoder 的子类只需要实现 encode(ChannelHandlerContext ctx, I msg, ByteBuf out) 方法即可,下面我们重点关注 encode 方法的实现:
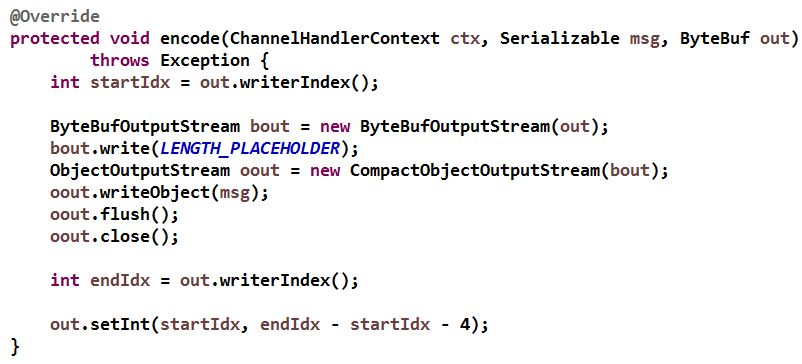
首先创建 ByteBufOutputStream 和 ObjectOutputStream,用于将 Object 对象序列化到 ByteBuf 中,值得注意的是在 writeObject 之前需要先将长度字段(4 个字节)预留,用于后续长度字段的更新。
依次写入长度占位符(4 字节)、序列化之后的 Object 对象,之后根据 ByteBuf 的 writeIndex 计算序列化之后的码流长度,最后调用 ByteBuf 的 setInt(int index, int value) 更新长度占位符为实际的码流长度。
有个细节需要注意,更新码流长度字段使用了 setInt 方法而不是 writeInt,原因就是 setInt 方法只更新内容,并不修改 readerIndex 和 writerIndex。
3. Netty 编解码框架可定制性
尽管 Netty 预置了丰富的编解码类库功能,但是在实际的业务开发过程中,总是需要对编解码功能做一些定制。使用 Netty 的编解码框架,可以非常方便的进行协议定制。本章节将对常用的支持定制的编解码类库进行讲解,以期让读者能够尽快熟悉和掌握编解码框架。
3.1. 解码器
3.1.1. ByteToMessageDecoder 抽象解码器
使用 NIO 进行网络编程时,往往需要将读取到的字节数组或者字节缓冲区解码为业务可以使用的 POJO 对象。为了方便业务将 ByteBuf 解码成业务 POJO 对象,Netty 提供了 ByteToMessageDecoder 抽象工具解码类。
用户自定义解码器继承 ByteToMessageDecoder,只需要实现 void decode(ChannelHandler Context ctx, ByteBuf in, List

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论