
在几周前发布的计费系统迁移博文中,我们概括介绍了将计费系统迁移至云中所采用的方法。本文将深入介绍数据库的迁移过程。希望我们的经验能帮你顺利完成自己的迁移任务。
你是否考虑过为了顺利完成复杂的数据库迁移任务,都需要考虑并解决哪些问题?但你可能也会问,“这有什么复杂的?”
想想数据库迁移过程中遇到的下列挑战吧,我们本次迁移几乎遇到了所有这些问题:
- 源和目标硬件存在差异
- 使用了不同的操作系统
- 需要跨域异构数据库进行迁移
- 涉及多个数据中心 – Netflix 数据中心(DC)和 AWS 云
- 要迁移的是非常关键的交易计费数据
- 有选择地迁移数据集
- 需要在最小停机时间的前提下迁移持续变化的数据
对任何公司来说账务都是一种关键服务,这一点大部分人都不会否认。在任何迁移项目中,数据库的迁移都是最基本要素,数据库能否成功迁移直接决定了整个项目能否成功。Netflix CDE(云数据库工程)团队最近对这一最重要的数据库子系统进行了迁移。下文将介绍为确保迁移项目成功完成我们所采取的一些关键措施。
数据库的选择
为顺利处理付款过程中产生的事务,计费应用程序的事务须符合 ACID (原子性、一致性、隔离性、持久性)要求。RDBMS 似乎是此类数据存储的最佳选择。
(点击放大图像)

Oracle:由于源数据库使用了 Oracle 产品,直接迁移至云中运行的 Oracle 数据库可避免进行跨数据库迁移,降低代码开发和配置工作量。我们过去在生产环境中使用 Oracle 产品的体验也让自己对该产品的性能和伸缩性更有信心。然而考虑到许可成本以及“依原样”迁移遗留数据所要产生的技术债,最终只能寻求其他解决方案。
AWS RDS MySQL:理想情况下我们会选择 MySQL RDS 作为后端,毕竟亚马逊在关系型数据库即服务产品的管理和升级方面做的挺好,为了实现高可用还提供了多可用区(AZ)支持。然而 RDS 的主要不足之处在于存储容量有着 6TB 上限。我们迁移时的容量已接近 10TB。
AWS Aurora:AWS Aurora 可以满足我们对存储容量的需求,但目前还是 Beta 测试版。
PostgreSQL:PostgreSQL 是一种强大的对象 - 关系开源数据库系统,但我们团队内部缺乏足够的 PostgreSQL 使用经验。在自己的数据中心内我们主要使用 Oracle 和 MySQL 作为后端数据库,更重要的是选择 PostgreSQL 会导致未来无法无缝迁移至 Aurora,因为 Aurora 使用了基于 MySQL 的引擎。
EC2 MySQL:最终我们的计费系统选择使用 EC2 MySQL,这种技术无须许可成本,同时未来可以直接迁移至 Aurora。该方式需要在 i2.8xlarge 实例上使用 InnoDB 引擎配置 MySQL。
生产数据库体系结构
为确保计费应用程序可以承受基础结构、区域和地域故障,并将可能的停机时间降至最低,高可用性和伸缩性是我们设计整个体系结构时最主要的考虑因素。
通过在另一个区域内为数据库主副本创建 DRBD 副本,即可承受区域故障,节点出错等基础结构故障,以及 EBS 卷故障。当本地和远程写操作均完成后,会使用“同步复制协议”将主要节点上的写操作标记为已完成。借此可确保一个节点的故障绝对不会导致数据丢失。虽然这样的设计会影响写操作的延迟,但延迟依然在 SLA 可接受的范围内。
读取副本可设置为本地或跨区域配置,这样不仅可以满足对高可用的需求,而且有助于增强伸缩性。来自 ETL 作业的读取流量会分流至读取副本,借此降低主要数据库执行繁重 ETL 批处理的负担。
一旦主要 MySQL 数据库故障,工作负载将被故障转移至使用同步模式进行复制的 DRBD 辅助节点。辅助节点开始承担主节点的角色后,会更改数据库主机的 route53 DNS 记录将其指向新的主节点。按照设计,计费应用程序与生俱来的“批处理”特性可顺利应对此类停机事件。CNAME 记录传播工作完成后,客户端连接不会回退(Fallback),而是会建立指向新主节点的连接。
(点击放大图像)

迁移工具的选择
我们在迁移工具的选择方面花费了大量时间和精力。概念验证工作成功与否的最主要条件在于能否重启动批载荷(Bulk load)、双向复制,以及数据完整性。在评估迁移工具时我们主要侧重于下列几个条件。
- 批 / 增量载荷的重启动
- 双向复制
- 每个表并行性(Parallelism per table)
- 数据完整性
- 传输过程中错误报告
- 上线后回滚的能力
- 性能
- 易用性
GoldenGate 以丰富的功能脱颖而出,该产品很好地满足了我们的需求。GoldenGate 可以在遇到故障后重启动批载荷(很少的几张表就达到数百 GB 容量),该产品的双向复制功能可以让我们从 MySQL 轻松回滚到 Oracle。
GoldenGate 的主要不足在于了解该工具工作原理所面临的学习曲线。此外该产品使用了易于出错的手工配置过程,这也增大了项目难度。如果源表没有主键或唯一键,GoldenGate 会使用所有列作为提取和复制操作的增补日志键对。但我们发现了一些问题,例如复制到目标的数据仅仅是相关表的增量载荷,因此决定在切换这些表的过程中执行不预定义主键或唯一键的完整加载。GoldenGate 的优势和包含的功能远远超过了所造成的困难,我们最终选择使用该工具。
架构转换和验证
由于源和目标数据库存在差异,数据类型和长度也有所不同,为了在迁移数据的同时确保数据完整性,验证工作变得必不可少。
数据类型误配造成的问题需要花些时间来修复。例如因为一些历史遗留原因,Oracle 中的很多数值已定义为 Number 数据类型,MySQL 缺少类似的类型。Oracle 中的 Number 数据类型会存储定数和浮点数,这一点比较难以处理。一些源表中的列使用 Number 代表整数,另一些情况则会代表十进制数值,其中一些值的长度甚至达到 38 位。作为对比,MySQL 使用了明确的数据类型,例如 Int、bigInt、decimal、double 等,而 bigInt 不能超过 18 位。因此必须确保通过恰当的映射以便在 MySQL 中反应精确的值。
分区表(Partitioned table)需要特殊处理,与 Oracle 的做法不同,MySQL 会将分区键视作主键和唯一键的一部分。为确保不对应用逻辑和查询产生影响,必须用恰当的分区键重新定义目标架构。
默认值的处理在 MySQL 和 Oracle 之间也有不同。对于包含 NOT NULL 值的列,MySQL 会确定该列暗含的默认值,在 MySQL 中启用 Strict 模式即可看到此类数据转换问题,这样的事务会执行失败并显示在 GoldenGate 的错误日志中。
架构转换工具:为了实现架构转换并进行验证,我们评估了多种工具,但由于原有架构设计中所存在的问题,这些工具默认提供的架构转换功能无法使用。即使 GoldenGate 也无法将 Oracle 架构转换为相应的 MySQL 版本,因此只能首先由应用程序的所有者重新定义架构。优化架构也是我们此次迁移的目标之一,数据库和应用程序团队合作审阅了数据类型,并通过多次迭代找出了所有误配的内容。在存在误配的情况下,GoldenGate 会对这些值进行截断以符合 MySQL 数据类型的要求。为了缓解这一问题,我们主要借助数据对比工具和 GoldenGate 错误日志找出源和目标之间数据类型的误配。
数据完整性
完整加载和增量加载执行完毕后,又遇到另一个让人气馁的问题:必须核实目标副本的数据完整性。由于 Oracle 和 MySQL 使用了不同数据类型,无法通过用普通封装脚本对比行键(Rowkey)哈希值的方式保证数据的精确性。虽然有几个第三方工具能跨越不同数据库对实际值进行数据对比,但总量 10TB 的数据集比较起来也不容易。最终我们使用这些工具对比了样本数据集,借此找出了少数由于架构映射错误导致的不一致问题。
测试刷新:确保数据完整性的方法之一是使用应用程序对生产数据库的副本进行测试。为此可安排从 MySQL 生产数据库进行刷新并用于测试。考虑到生产环境使用 EBS 作为存储,只要创建 EBS 快照即可轻松创建测试环境,同时可在测试中执行时间点恢复。为确保足够高的数据质量,这一过程重复了多次。
Sqoop 作业:我们在数据校正过程中使用了 ETL 作业和报表,并使用 Sqoop 作业从 Oracle 中拉取创建报表所需的数据。此外还针对 MySQL 配置了这些作业。在源和目标之间进行持续复制的过程中,会在 ETL 的特定时间窗口内运行报表,这样即可找出增量加载过程中产生的变化。
行计数(Row count):是用于对源 / 目标进行比较和匹配的另一种方法。为此需要首先暂停目标的增量加载,并对 Oracle 和 MySQL 的行数进行匹配。在使用 GoldenGate 完整加载表之后也会对行计数的结果进行比较。
性能调优
基础结构:计费应用程序将数据持久保存在数据中心内两个 Oracle 数据库中,运行数据库的计算机性能极为强大,使用了 IBM Power 7,32 颗双核心 64 位处理器,750GB 内存,通过 SVC MCS 集群分配 TB 级别的存储,集群使用了 4GB/s 接口,运行 RAID10 配置的 8G4 集群。
迁移过程中最大的顾虑是性能,目标数据库将整合到一个装备有 32 颗 vCPU 和 244GB 内存的 i2.8xlarge 服务器上。为了优化查询性能,应用程序团队在应用层进行了大量调优。在 Vector 的帮助下,性能团队可以方便地发现性能瓶颈,通过调整特定的系统和内核参数解决这些问题。详细信息请参阅附件。
我们用 EBS 供应的 IOPS 卷组建 RAID0 实现了极高的读写性能。为了通过每个卷获得更高吞吐率,共使用 5 个容量各 4TB 的卷,而没有使用更大容量的单个卷。这样做也可以加快创建快照和还原的速度。
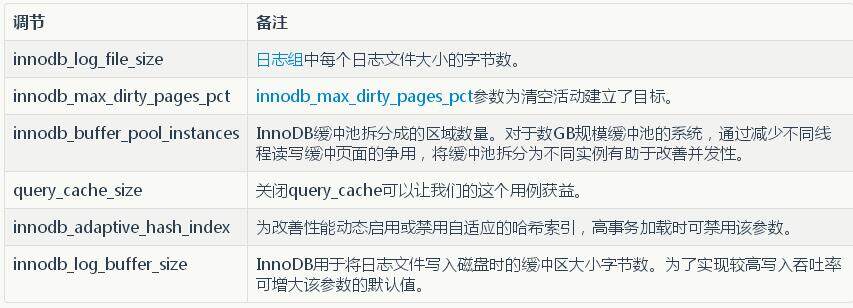
数据库:对于 MySQL 的使用我们还有一个比较大的顾虑,担心计费应用程序在对数据执行批处理过程中 MySQL 的吞吐率无法满足数据规模的需求。 Percona 为此提供了顾问支持,在迁移过程中以及迁移之后,MySQL 数据库的性能表现都让我们感到满意。这里的诀窍在于使用两个 cnf 文件,一个用于迁移数据的过程中对 innodb_log_file_size 之类的参数进行优化,以便执行批量插入;第二个 cnf 文件用于在实时生产应用程序工作负载中对 innodb_buffer_pool_instances 之类的参数进行调整,借此促进事务的实时加载。详情请参阅附件。
数据加载:在概念验证过程中,我们针对开启和关闭索引两种情况测试了表的初始加载,并决定在加载前启用所有索引。这样做的原因在于 MySQL 中索引是通过单线程方式创建的(大部分表有多个索引),因此我们改为使用 GoldenGate 的并行加载功能在合理的时间内为表中填入索引。最后一次割接过程中还启用了外键约束。
我们学到的另一个窍门是按照实例的内核数量执行相同遍数的完整和增量加载过程。如果这些过程的执行遍数超过内核数量,数据加载性能将大幅降低,因为实例需要花费更多时间进行上下文切换。通过完整加载和增量加载将 10TB 数据装入目标 MySQL 数据库,这一过程用了大约两周时间。
结论
虽然对任何迁移项目来说,数据库的迁移都是最大挑战,但真正决定项目成功与否的关键在于要确保一开始就选择了正确的方法,并且在整个执行过程中与应用程序团队密切合作。回顾整个迁移过程,这个项目的成功完全是组织内部不同团队通力合作的成果,大家一起制定的整个迁移计划是促成这一切的关键!为了在不影响业务的前提下顺利完成整个充满挑战的迁移项目,除了人员和团队之间的相互协调,自由的文化和责任感也是促成这一切必不可少的要素。
附件
批量插入时对数据库的调节

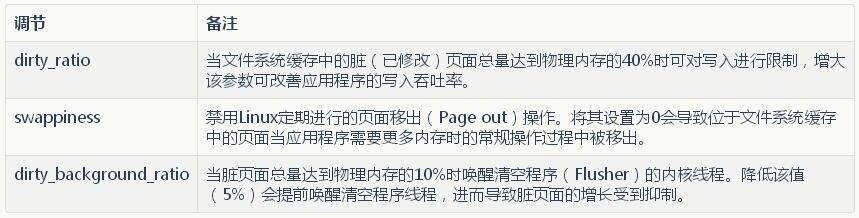
高事务吞吐率的数据库调节
存储
- 使用 5 个 4TB EBS PIOPS 卷组建 RAID0
- 使用 LVM 管理同一卷组中的两个逻辑卷(DB 和 DRBD 元数据)
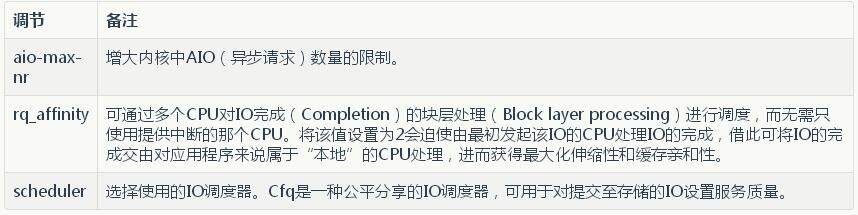
CPU 调度器方面的调节

虚拟机的调节
文件系统和 IO 存储指标
作者:Jyoti Shandil, Ravi Nyalakonda, Rajesh Matkar, Roopa Tangirala,阅读英文原文: Netflix Billing Migration to AWS - Part III
感谢木环对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

暂无签名

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论