本文整理自刘超在 ArchSummit2016 全球架构师峰会(北京站)的演讲。
网易蜂巢是做容器 Docker 的,用 Kubernetes 来管理容器。现在蜂巢已经支撑了内部、外部很大规模的云计算应用,所以我们这个题目有两个关键,一个是 Kubernetes 和容器,另外一个是大规模云应用。
网易蜂巢的大规模容器平台
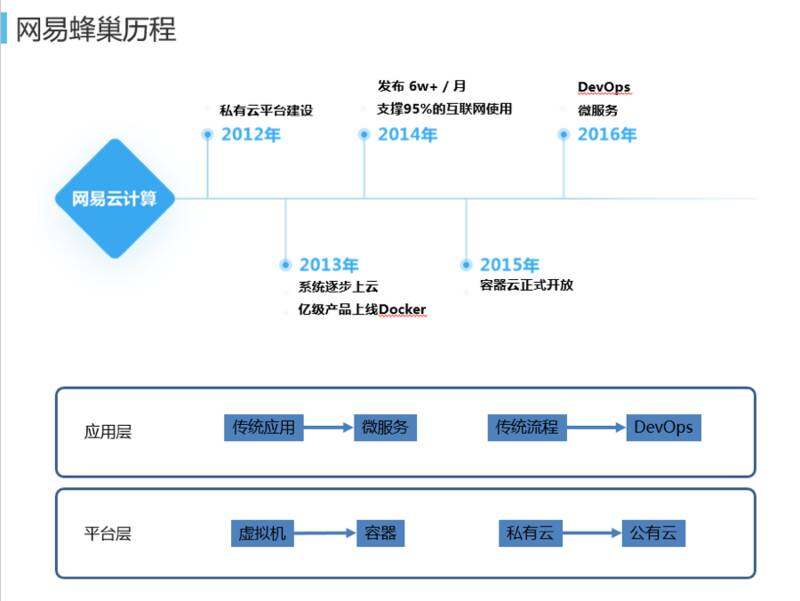
上图展示了蜂巢发展历程。其实很早就开始做蜂巢了,一开始从私有云开始建设。发展分成两层:应用层、平台层。进行了四个方面的转变,一是从虚拟机进展到容器。因为虚拟机仅仅是资源平台的弹性,并没有实现到应用级别的弹性,实现容器后对应用层要有一定的关心、改造、架构梳理。在应用层我们要做微服务化的改造以及开发流程 DevOps 的改造,我们还经历了从私有云到公有云的转化。2014 年 95% 的应用移到平台上来,2015 年容器云平台才正式对外开放。很多应用都是我们自己支撑地比较好以后才作为容器云平台开放,对外进行服务。2016 年主要是 DevOps 微服务帮助用户真正改变流程,改进架构。
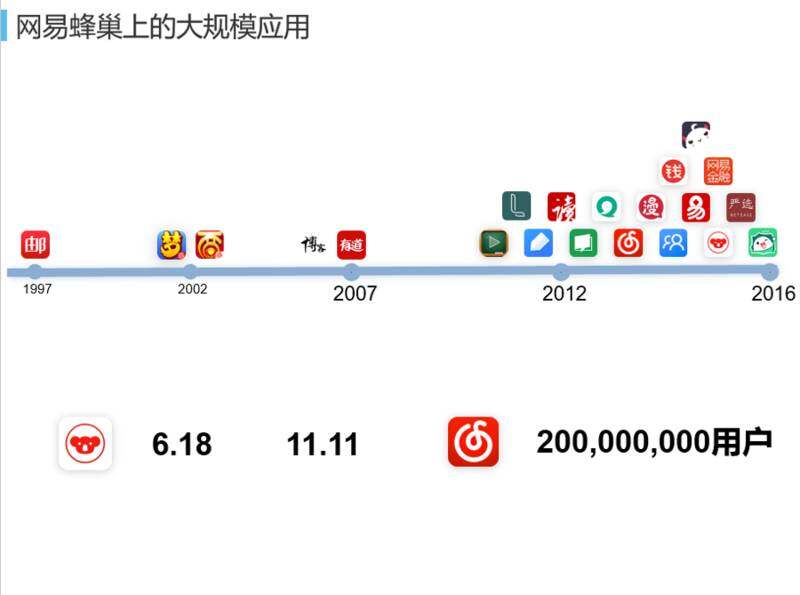
上图是蜂巢上大规模的云应用,从最早的邮箱,到后来互联网应用产生了一个爆发的阶段,很多 logo 大家都认识,比如说笔记、云音乐、考拉海购等等。我们很骄傲的是,其中考拉海购和网易云音乐都部署在蜂巢平台上面,它们扛过了“双十一”。虽然我们的音乐产品推出时间比较晚,但是用户量很快激增,对整个架构也是一个很大的挑战。
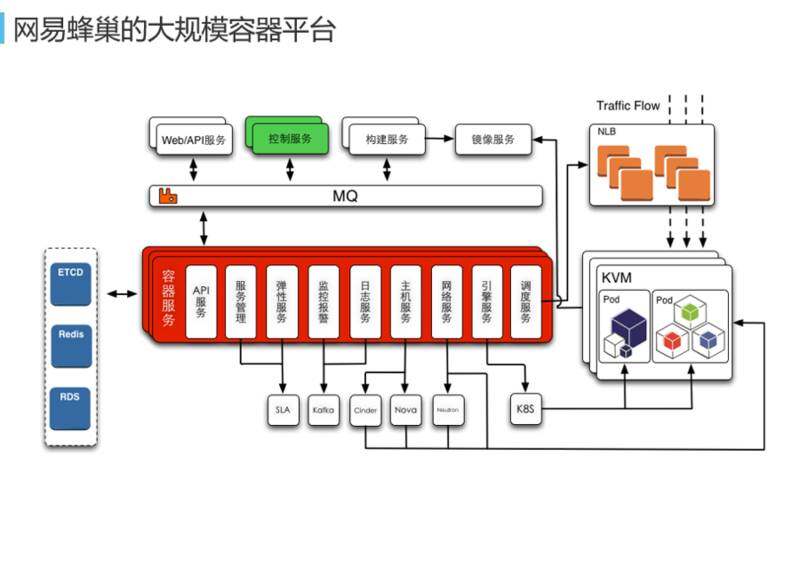
蜂巢大规模容器平台整个架构如图所示。我们原来做过私有云、IaaS 平台,IaaS 平台其实是比较费力的,尤其是对网络方面的优化和存储方面的优化。到了容器平台以后,容器本身对 CPU 隔离、内存隔离、应用隔离做得不错,但是对跨主机网络隔离、统一存储支持做得不够,尽管有一些开源解决方案可以做这个事情,但我觉得对 IaaS 平台做的一些优化是能够帮助容器层来提供高性能的网络和存储服务,所以我们的容器平台和 IaaS 平台有深度结合。在右图的 KVM,因为我们做的是公有云,最关注的就是安全问题。容器隔离性其实本身做得没有那么好,容器的权限不知道开的高还是低,如果开的低用起来很别扭,因为很多权限没有给它,但是开的高的话就可能在同一个主机上还有其他人的应用。 在公有云平台上,采取的策略是不同的租户不共享主机、不共享虚拟机,这样就能实现比较好的隔离性。
私有云平台建设
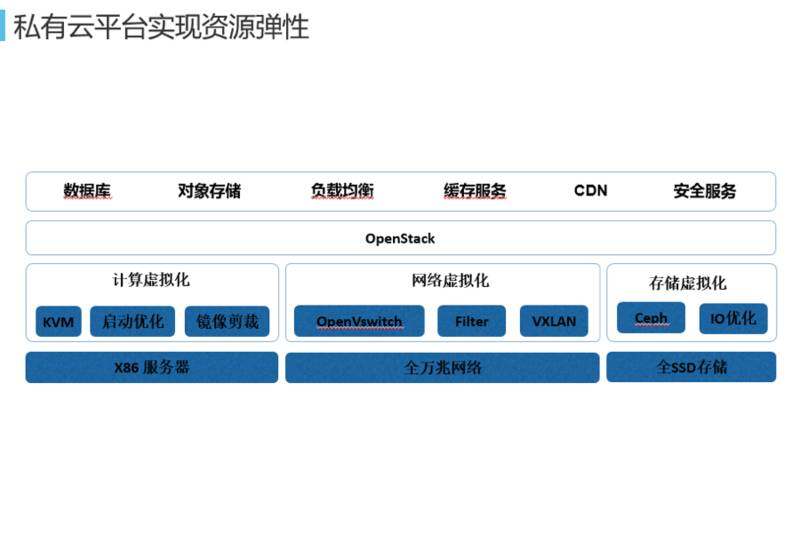 这是私有云平台资源弹性架构图。网易数据中心开始建立起来时就是朝着五星级数据中心建立的,所以硬件层非常好,实现了全万兆互联、全 SSD 存储。如果在蜂巢平台上订购一个容器,存储都是 SSD 的,性能非常棒。计算虚拟化、网络虚拟化、存储虚拟化,基本的 OpenStack 都会做这三层。把 KVM 作为计算存储化、OpenVswitch 作为网络存储化、存储虚拟化方面做了很多改进。基于 OpenStack 之上是 PaaS 平台,PaaS 平台有数据库、对象存储、负载均衡、缓存服务、CDN、安全服务。这些服务发展的整个历程比云平台还要早,因为像数据库、对象存储、缓存服务是在网易研究院一开始成立时,这方面的技术就已经开始积累了。
这是私有云平台资源弹性架构图。网易数据中心开始建立起来时就是朝着五星级数据中心建立的,所以硬件层非常好,实现了全万兆互联、全 SSD 存储。如果在蜂巢平台上订购一个容器,存储都是 SSD 的,性能非常棒。计算虚拟化、网络虚拟化、存储虚拟化,基本的 OpenStack 都会做这三层。把 KVM 作为计算存储化、OpenVswitch 作为网络存储化、存储虚拟化方面做了很多改进。基于 OpenStack 之上是 PaaS 平台,PaaS 平台有数据库、对象存储、负载均衡、缓存服务、CDN、安全服务。这些服务发展的整个历程比云平台还要早,因为像数据库、对象存储、缓存服务是在网易研究院一开始成立时,这方面的技术就已经开始积累了。
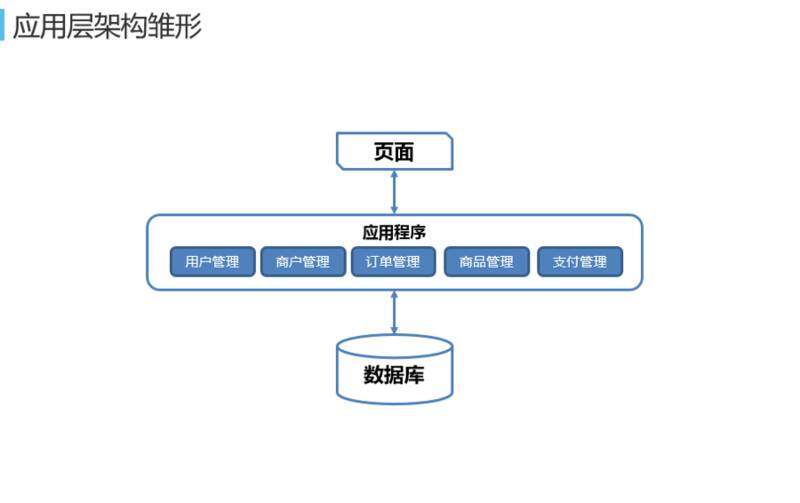
再往上是应用层。这是应用层的架构雏形,是一个电商网站。一般一开始应用层构建时都是单机模式的,这不能说架构师一开始设计时没有设计好。其实现在互联网的应用,我们遇到好多的客户最想要的点就是上线速度快。现在有很多应用就是半年过一茬,如果赶不上这个风口,可能就飞不起来,就会被竞争对手落下,这样架构再好也没有用,所以一般不会一开始就把应用层拆得七零八落的。
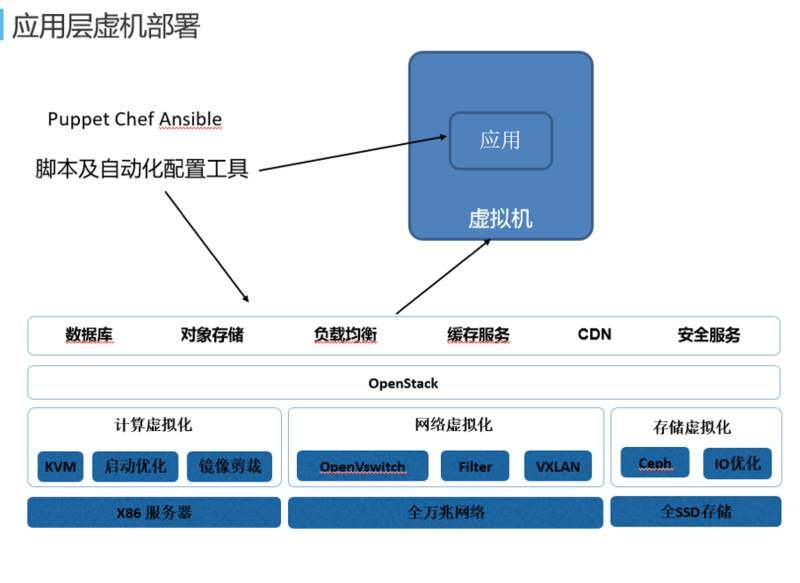
虚拟机层面部署方式一般会采取通过脚本或者自动化配置的工具来进行应用的部署,这里经常用的是 Puppet Chef Ansible。虚拟机能实现的资源层面比较弹性,比如说“双十一”原来有 5 个节点,卡一下变成 10 个节点,很快可以部署出来,但是另外 5 个节点里面是空的,怎么办呢?并不能很好实现应用弹性,所以就需要自动化的工具,除了调 IaaS 平台把虚拟机创建出来以外,还要进行部署。应用部署上去之后,如果变化比较慢是没有任何问题的,脚本是固定的只需要写一次就可以了,但是现在应用变化非常快,需要不断调整脚本,运维成本还是相对比较大的。
随着业务发展,应用层的架构就会越来越复杂。比如说用户的管理,要不要给用户做一些活动,用户浏览时要不要提供搜索推荐,要不要做积分,商户要不要管理自己的供应商,和客户有矛盾的话要不要有仲裁,支付需不需要对账,商品配送要不要物流管理,包括对接银联、支付宝支付等等,所有的功能都加进来了。如果还是加到同样一个应用里的话,整个架构就太复杂了。这个时候架构就会面临着三个方面的问题:
- 时间的灵活性。一个新的活动要上线的时候,能否尽快实现它的快速迭代。
- 空间的灵活性。能否实现非常快的弹性伸缩。
- 管理的灵活性。比如说有一个服务挂了,怎么样把它尽快接起来,和原来应用进行一定程度的关联。
从虚拟机到容器
接下来是一个从虚拟机过渡到容器的时代。这个时代主要有以下几个方面的不同:
- 原来以资源为核心,现在以应用为核心。运维人员不能再认为不关心应用,只要虚拟机不挂就没有问题。这个时候开发人员和运维人员已经不再是两个独立的实体,现在流行的概念就是 DevOps。
- 有状态容器。为什么要支持有状态容器?从虚拟机到容器的演化过程,容器其实比较适用于部署一些无状态的东西,最好是挂了以后再起,只有商务逻辑并没有数据。虽然在哪个机器上重启都是可以的,但是我们发现中间还是有很大沟壑的,用习惯虚拟机的用户不适应一旦切换到容器,应用就马上进行无状态,所以我们采取了一定的技术,下面也会分享如何实现有状态的容器。
- 容器跨主机互联和容器使用云盘存储。它对于计算的隔离比较好,但是对于网络互联、共享云盘,虽然业界有开源的方案,但是这种方案还是有问题的,一个是性能问题,一个是二次虚拟化的问题,一般采取公有云创建虚拟机的时候,虚拟机之间的互联已经有了一个层次的虚拟化,这个时候容器之间的跨主机互联还要再做一次虚拟化,这样一层一层套性能就大幅度降低。云盘存储也是,如果要在 IaaS 层之外再做一层集群,还是会有二次虚拟化,本来下面就是一个虚拟的存储,创建出云盘,云盘再打出集群,这种二次虚拟化存储基本不可以使用了。
去状态化
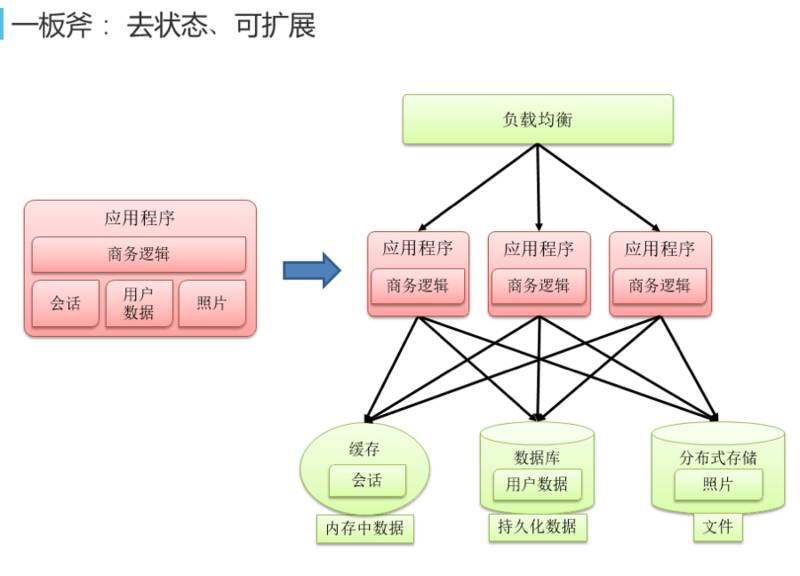
所谓的去状态化,就是应用程序一开始会有很多的数据,比如有些数据是保存在内存里,像会话的数据,有的是保存在本地文件系统、本地库里,像照片。去状态化做的事情没有那么难,把这些数据外置化就可以了, 可以把会话放在缓存里,可以把用户数据放在数据库里,可以把照片保存在远程的分布式存储里面。仅仅包括商务逻辑、算法的应用扩展起来就非常方便,一变三、三变五,可以比较好地分担整个应用。其他有状态的事情就交给外面的缓存、数据库和分布式存储来做。开源软件和互联网软件发展到今天,外部的缓存、数据库和分布式存储都已经有了自己的集群模式,所以把它外置出来并不担心丢失。
容器化
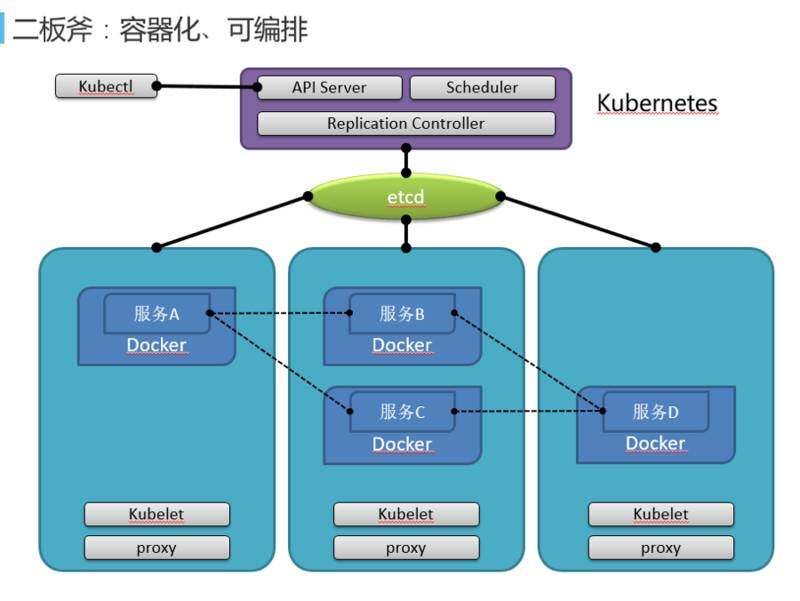
无状态化以后,就可以进行容器化。有人说容器化就是微服务,微服务就是容器化,其实不完全。这里我们用 Kubernetes 进行管理,把一个服务拆成了四个服务,服务 A、B、C、D,它们之间互相关联、互相调动。容器化并用 Kubernetes 管理以后,它的服务可以自发现、自修复。如果这时候中间的机器挂了,中间的 B、C 服务会自动迁移到另外两台机器上,重启以后 IP 地址可能会是改变的,那么服务 A、D 怎么找到服务 B、C 呢?Kubernetes 会自动管理,Kubernetes 中每个服务都有一个服务名,A 调用 B,B 就是一个服务名。A 不用关心 B 的 IP 是什么,也不用把 IP 配在配置文件里面,只需要把服务名配在配置文件。无论 B 迁移到哪个机器,A 要访问 B,Kubernetes 会自动把服务名映射为 B 的 IP 地址访问过去。这样就会优雅地实现自修复以及负载均衡。如果发现 B 是瓶颈,原来 B 只有一个实体,现在 B 有三个实体,这三个实体还叫 B,那么 A 访问时还是访问 B,但是 A 访问时不用关心访问的是这三个 B 里面的哪一个,Kubernetes 会帮我们选一个进行访问,这样就实现了负载均衡。
DevOps、可迭代
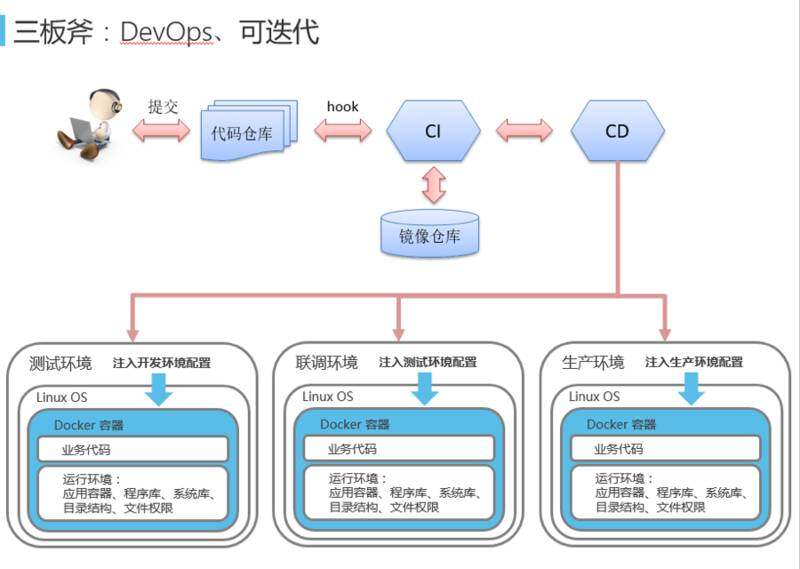
用这种方式,开发的整个流程会非常的顺畅。因为容器的镜像是不可变的,所以镜像把 OS、业务代码、运行环境、程序库、目录结构都包含在内,好处是镜像无论放在测试、联调、生产环境里面,都能保证环境的一致性。其次,比如从 1.0 版本升级到 1.1 版本,发现 1.1 版本有点不对,要回滚到 1.0 版本时,也可以确认它就是当时的 1.0 版本。如果是自己手工调整的话,需要特别小心,过了一段时间可能会忘了自己做了哪些微调整从 1.0 版本升级到 1.1 版本。当然其中会有不一样的地方,比如说环境的配置可能需要通过环境变量或者更稳健的方式来注入测试环境、联调环境、生产环境。中间一个优雅的事情是,比如原来做一个程序往往会有三份配置文件,打包时也会把不同的配置文件放进去。如果以 Kubernetes 自发现的方式,把 B 的名字放到配置文件里就可以了。本地起一个开发环境,只要把 B 的名字设为 127.0.0.1,在本地就可以相互访问。到测试环境,A 访问 B,配置文件是不用变的,访问的 B 就是测试环境里面的 B。到生产环境里面一样,配置文件也不用变更,不用每次保存多份配置文件,开发流程也会非常顺畅。
微服务架构
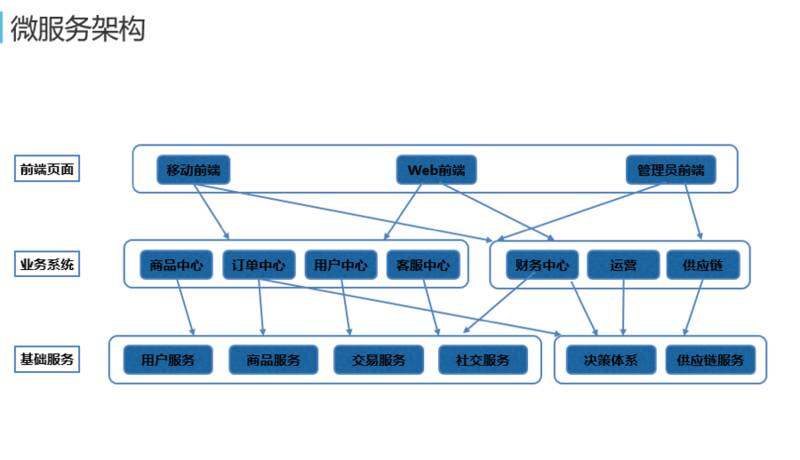
这是最初电商的架构,本来是单体的架构,后来拆分成很多很多的子服务,包括前端的、业务系统、基础服务系统的,它们之间相互引用,利用 Kubernetes 相互发现。如果没有自发现的系统,维护起来还是比较麻烦的。这其实是考拉海购抽象化的模型,整个架构比这个要复杂。巨大的优点是,比如“双十一”来了,进行压测可以发现里面的瓶颈点,对瓶颈点可以进行弹性伸缩,对于非瓶颈点伸缩就相对小一点。大家不会在“双十一”那天疯狂的进行用户注册,但是下订单压力就比较大了。
从私有云到公有云
接下来,我们从私有云开始迈向公有云,开始对外进行服务。这还是有一些挑战的:
第一,容器的安全问题。如果我们允许用户共享主机,大家进容器是能看到这个机器上所有的 CPU 和 MEMORY 的,而不是仅仅只能看到两盒。如果是一个黑客,完全可以把旁边的容器黑掉,所以安全问题是一个非常关键的问题,安全问题一个解决思路就是 KVM。
第二,容器启动速度问题。申请容器时可以开一个相对比较大的 KVM,第一个容器启动会有 KVM 启动时间,第二个容器启动就没有 KVM 启动时间,你就会立刻体会到容器的好处。
第三,容器的规模问题。大家都开始使用公有云之后,容器规模会迅速扩大,也会导致整个 Kubernetes 集群迅速扩大,从千节点现在已经到了 15000 节点。
第四,容器的租户隔离问题。除了 CPU、MEMORY 的隔离,网络隔离、存储隔离也是一个问题。
网易蜂巢平台及优化
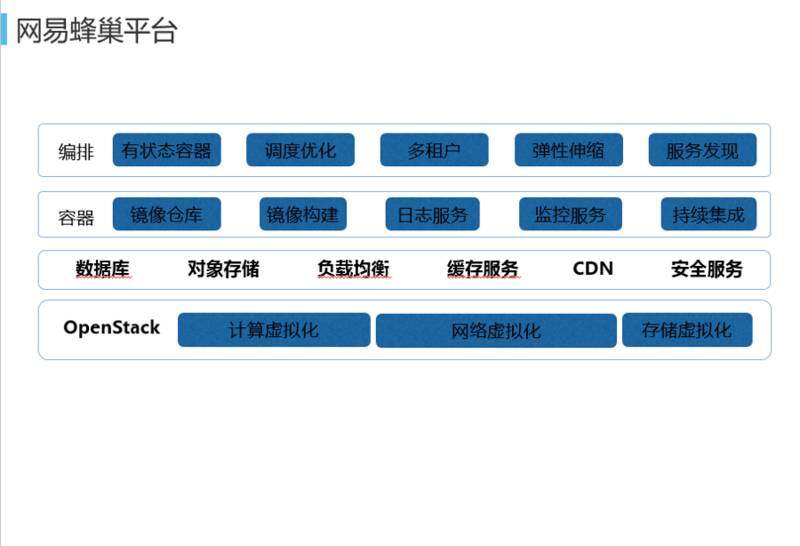
这是基于 OpenStack 上 PaaS 平台再往上的容器和编排的平台。在容器这一层我们提供了自己的镜像仓库,因为在国外访问,由于防火墙的问题实在是太慢了,当然本地需要做一个 cache,镜像取下来的时间几乎可以忽略不计。微服务场景下,必须要有日志服务,把一个东西拆成了很多个东西以后如果出现了问题,日志挨个看太多,所以日志服务采取类似 ELK 的方式,把日志收集起来,提供统一的搜索引擎,这样做之后交易的整个过程,哪个环节出了问题都一目了然。再往上就是编排,除了 Kubernetes 本身带的弹性伸缩和服务发现能力之外,我们做了有状态容器,弥补了从传统的虚拟机到最现代化的容器中间的过渡阶段。还有调度优化,为什么要做调度优化?当集群规模特别大的时候,原来 Kubernetes 自己的调度机制已经不能满足这么多节点的调度性能。作为一个分布式系统最核心的就是调度系统,这就是为什么很多大型的分布式系统最后都是在修改调度系统,比如 OpenStack 会把原来的调度系统分成很多的子服务,也是在做调度方面的优化。我们的多租户是全方位的多租户,不光是普通的隔离。

Kubernetes 是有多租户的想法和机制的,比如有 Namespace,但没有办法隔离节点、网络,网络和存储其实还是需要我们通过自己的机制来进行隔离的。节点的隔离是不同租户是不会共享节点的,这时候需要有一个 LABEL 做控制。网络隔离是利用 IaaS 层的能力进行网络间的隔离,不同租户会有自己的 VXLAN ID。调度性能优化,Kubernetes 本身是串型队列优化,如果都是这个方式,当集群大的时候任务队列会特别多,会有很多人上来提交任务,这个时候一个队列并不能解决问题,我们就改为了多个优先级队列解决问题,这样就可以多线程的处理。集群扩展性,Kubernetes 会把数据放到 ETCD 里,Agent 节点会到里面发现自己需要做哪些事情。我们后来发现集群规模大了以后,单独的一个 ETCD 集群不能放下这么多数据量,根据 Pod、Node 等资源,当一个用户有一个操作时,我们知道这是属于哪个用户,进行负载量均衡的拆分。
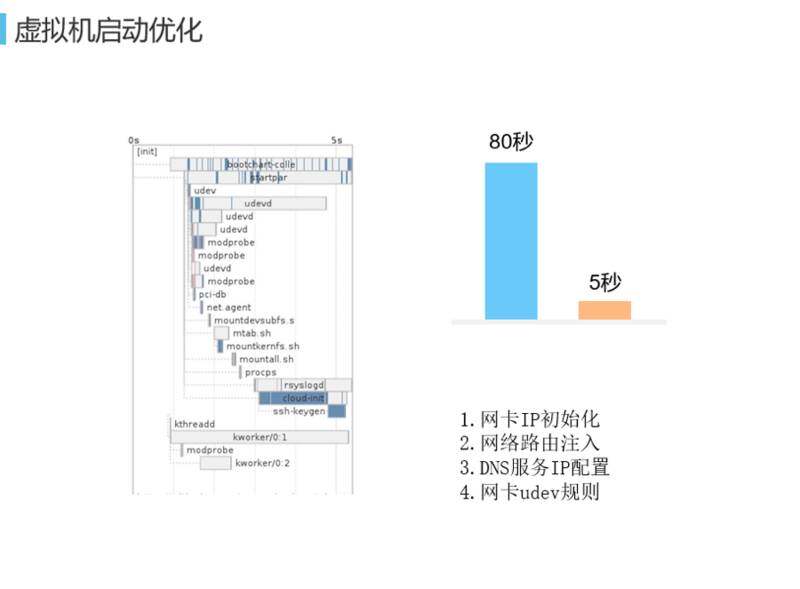
这是虚拟机启动优化做的事情。我们发现虚拟机启动之所以在分钟级就要分析一下,虚拟机启动用了多长时间,并不完全每一次都是一分钟,有时候长有时候短。OpenStack 会调用 DHCPServer,根据上面拉下来的东西进行本地的初始化,初始化由于各种问题会导致时间非常不可控。其实 IP 是可以静态化的,比如虚拟机的启动、容器的启动,刚启动的时候数据库就可以给它分配一个 IP,Agent 就知道将要用哪个 IP,就不需要再通过 DHCP 的方式再分配 IP。网卡打到虚拟机,虚拟机里的网卡会再放到 Docker 的 Namespace 里面,这样 Docker 访问网卡就只有一层的虚拟化。有一些传统应用,有些东西是放在虚拟机里的,新的应用是放在容器里面的,它们之间的相互调用不希望用外部 NAT 方式,因为性能会下降。如果可以统一管理,就可以做到只有一层虚拟化,如果虚拟机、容器里面的应用属于同一个租户的话就可以相互互联了。
蜂巢特色
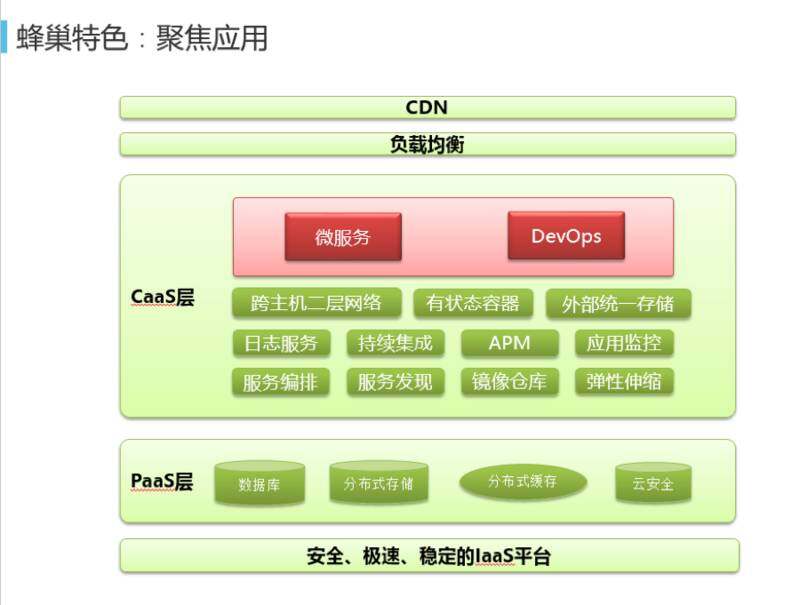
蜂巢的特色首先就是聚焦应用,客户只需要做好自己的微服务和 DevOps 就可以了。哪怕不能完全做好,下面有跨主机的二层网络、有状态容器、外部统一存储这三个,并没有意识到用容器的方式和虚拟机有太大差别。公用的监控、镜像、弹性伸缩、持续集成的服务。下面有我们的 PaaS 层数据库、分布式存储,如果用蜂巢,不需要关心数据库的数据会不会丢失,自己要不要起个数据库,要不要起个 DBA,这样就避免了麻烦。你只需要关心微服务化和 DevOps,尽快把自己的服务上线,站在风口上就可以了。
第二个特色,我们是全开源平台。无论 IaaS 层用 OpenStack,容器层用 Kubernetes,数据库用 MySQL,缓存使用 Redis。虽然经过后台一定优化,但是它们的接口是完全标准的,无论你用了 MySQL 任何私有的特性,迁上来都不会有不适应的地方。这样一个全开源平台对用户嵌入是非常友好的。
点击“阅读原文”查看演讲完整 ppt。
作者介绍
刘超,爱代码,爱开源。网易云解决方案总架构师,主要责任是把内部和外部很多云应用搬到容器的蜂巢上来,目标是做到写代码中最懂解决方案的,懂解决方案中的最会写代码的。10 年云计算领域研发及架构经验,Open DC/OS 贡献者。长期专注于 kubernetes、 OpenStack、Hadoop、Docker、Lucene、Mesos 等开源软件的企业级应用及产品化。曾出版《Lucene 应用开发揭秘》。




