
这是一篇由纳斯达克首席架构师 Nate Sammons 撰写的文章。
纳斯达克集团公司在全球范围内负责金融交易运营工作,且每天处理的数量总量极为庞大。我们运行着种类繁多且数量可观的分析及监控系统,而且这些系统全部需要访问同样的整体数据集。
纳斯达克集团自 Amazon Redshift 发布之日起就开始将其引入自身业务体系,我们也对这一决定感到由衷赞赏。我们此前已经在 re:Invent 大会上多次探讨过该系统的客户使用情况,最近的一次来自《FIN401 地震式转变:纳斯达克向 Amazon Redshift 迁移》一文。目前,我们的系统每天将平均 55 亿行数据移动至 Amazon Redshift 当中(2014 年 10 月的单日峰值移动量为 140 亿行)。
除了我们的 Amazon Redshift 数据仓库之外,我们还拥有一套庞大的历史数据设施体系,旨在将其作为单一、巨型数据集加以访问。目前,这套历史数据归依体系分布在大量不同系统当中,这使相关内容变得难于使用。我们的目标是建立起一套新的双重统一化数据仓库平台,其一方面需要为纳斯达克各内部部门带来更为理想的历史数据集访问能力,另一方面则希望在流程当中实现更突出的成本效益。对于这套平台,Hadoop 是一项明确的选项:它支持多种不同类型的 SQL 及其它用于数据访问的接口,同时拥有一整套活跃且持续发展的工具及项目生态系统。
为什么选择 Amazon S3 与 Amazon EMR?
我们新型数据仓库平台的主要构建宗旨是为了将存储与计算资源加以分离。在传统 Hadoop 部署机制当中,存储容量的伸缩通常也要求我们对计算容量进行伸缩,而且计算与存储资源二者之间的任何比例变更都要求使用者对硬件进行修改。在我们的长期历史归档用例当中,HDFS 当中访问频率较低的数据仍然需要保持始终可用,并一直占用集群当中每个节点的计算资源。
除此之外,HDFS 的默认复制因子为 3,这意味着每个数据块需要占用集群中的三个节点。这虽然能够在一定程度上保障耐久性水平,但也同时代表着大家必须购买必要的存储容量、从而在对集群进行容量扩展时将磁盘数量增加至预期原始容量的三倍。除此之外焦点问题也需要得到关注:如果某个给定数据块在集群中只存在于三个节点当中,但却需要经受频率极高的访问操作,那么大家必须对其进行复制或者将特定计算节点设置为访问焦点。
不过在 Amazon S3 与 Amazon EMR 的帮助下,我们能够顺利摆脱上述难题。二者允许大家将用于数据仓库的计算与存储资源进行分离,并根据需要单独对其进行规模伸缩。其中不再存在焦点,因为 S3 中的每个对象都能够以无需焦点机制的支持下与任意其它对象一下接受访问。Amazon S3 还拥有几乎无限的可扩展能力、11 个 9 的卓越耐久性(即 99.999999999%)、自动跨数据中心复制、简洁直观的跨区域复制以及令人心动的低廉成本。随着与 IAM 政策的进一步集成,S3 还带来一套拥有经过深入细化调整且涵盖多个 AWS 账户访问控制机制的存储解决方案。考虑到上述理由,Netflix 公司以及其它众多企业已经证明了 Amazon S3 是一套极具可行性的数据仓库平台。此外,AWS Lambda 等新型服务的出现能够针对 S3 事件执行任意代码作为响应,而这将进一步拓展用户可资挖掘的使用潜力。
利用 EMR 启用集群
EMR 的出现令使用者能够更轻松地部署并管理 Hadoop 集群。我们能够根据实际需要对集群规模与提升与削减,并在周末或者节假日期间将其关闭。一切元素都运行在虚拟私有云(简称 VPC)环境之下,因此我们能够对网络访问进行严格控制。IAM 角色集成则让使用者能够轻松实现泛用性访问控制机制。最重要的是,EMRFS——这是一套 HDFS 兼容性文件系统,能够访问 S3 当中的存储对象——允许大家利用访问控制挼顺 S3 当中的数据存储层。
我们能够利用多套 EMR 集群在同样的存储系统基础之上运行多个数据访问层,而且这些访问层能够实现彼此隔离且不需要占用计算资源。如果某项特定任务需要在少数情况下使用每个节点中的大量内存资源,我们可以直接为其运行一套专用的内存优化型节点集群,而不必再像过去那样纠结于集群内 CPU 与内存的具体搭配比例。我们能够在无需针对特定内部客户修改“主”生产集群的前提下运行实验性集群。成本分配同时易于实现,因为我们能够为 EMR 集群添加标签、从而进行成本追踪或者根据需要将其运行在各个独立 AWS 账户当中。
由于它能够极大降低集群体系的管理难度,现在我们得以建立新的实验性数据访问层并运行大规模 POC,同时无需为了运行相关 Hadoop 集群所带来的新硬件采购支出或者将大量时间用于摆弄各种类型的移动部件。这与我们当初启用 Amazon Redshift 时的状况非常相似:在 Amazon Redshift 出现之前,我们甚至根本无法想象自己能够对容量超过 100TB 的生产数据库进行复制以完成实验性目标。如果使用传统处理方式,整个过程可能需要耗时数个月,其中包括订购硬件、设置以及进行数据迁移等等——现在,我们只需要一个周末就能搞定全部工作,并在实验完成后直接将其“回炉再造”。总而言之,Amazon Redshift 为我们开启了一扇新的可能性大门,而在此前这一切完全不可能实现。
随着我们全新数据仓库的推出,我们的目标旨在建立起一套极具实用性且能够为一系列类型广泛、技能储备有异的用户提供访问能力的平台方案。其主要接口通过 SQL 实现 ; 我们曾经对 Spark SQL、Presto 以及 Drill 等进行过评估,但我们同时也认真考量过其它候选方案以及非 SQL 机制。Hadoop 社区的发展速度极快,因此根本不存在一款能够通吃一切的万试万灵型查询工具。我们的目标是为客户希望使用的一切 Hadoop 生态系统分析及数据访问应用程序提供必要支持。EMR 与 EMRFS 与 S3 相对接让上述目标成为了可能。
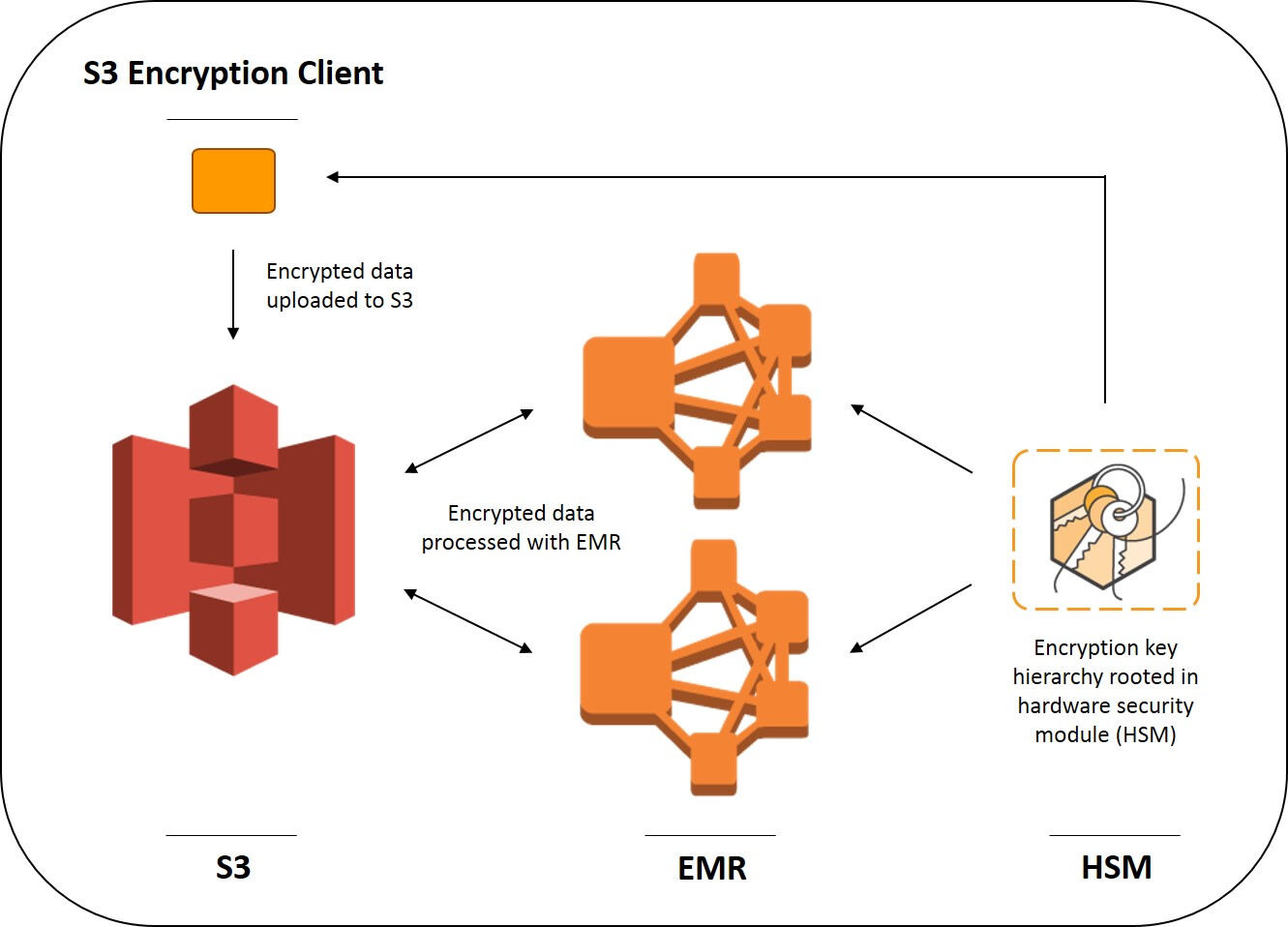
安全要求与 Amazon S3 客户端加密机制
纳斯达克集团拥有一套业务涵盖范围广且士气高昂的内部信息安全团队,其在数据及应用程序保护方面遵循着严格的管理政策及标准。考虑到数据的敏感性水平,这部分内容必须在存储及传输过程中得到确切加密。除此之外,加密密钥必须被保存在位于纳斯达克基础设施内部的 HSM(即硬件安全模块)集群当中。我们为 HSM 选择了与 AWS CloudHSM 服务相同的设备品牌与机型(即 SafeNet Luna SA),这也使得我们能够将 Amazon Redshift 集群主密钥保存在自己的 HSM 当中。为了简单起见,我们将其称为纳斯达克 KMS,其功能类似于原有 AWS 密钥管理服务(简称 AWS KMS)。
最近,EMR 在 EMRFS 中推出了一项新功能,允许客户利用自有密钥实现 S3 客户端加密,其利用 S3 加密客户端的封闭加密机制。EMRFS 允许大家通过实现由 AWS SDK 提供的 EncryptionMaterialsProvider 接口编写自己的瘦适配机制,这样当 EMRFS 在 S3 内读取或者写入某个对象时,我们就将获得一项回调以为其提供加密密钥。这是一种简洁的低级钩子,允许大家在无需添加任何加密逻辑的前提下运行大多数应用程序。
由于 EMRFS 是一种 HDFS 接口实现机制(当大家在 EMR 当中使用‘s3://’时即可进行调用),因此前面提到的各层无需在加密过程中进行识别。EMRFS 在堆栈中还属于低级机制,因此其运作方式可谓包罗万象。换言之,它几乎能够应对一切集成加密任务。需要强调的是,seek() 函数同样适用于保存在 S3 当中的加密文件,因此其对于多数 Hadoop 生态系统内的文件格式而言都是一种极为重要的性能保障功能。
使用定制化加密素材提供程序
在素材提供程序方面,我们的实现方案能够与纳斯达克 KMS 进行通信(具体情况请参阅下文中的‘代码示例’章节)。EMR 能够从 S3 当中提取出自己的.jar 实现文件,将其放置在集群中的每个节点当中,并通过 EMRFS 配置在集群上的 emrfs-site.xml 配置文件当中使用我们的素材提供程序。我们能够在创建新集群时指定下列参数,从而轻松通过 AWS 命令行实现上述目标:
--emrfs Encryption=ClientSide,ProviderType=Custom,CustomProviderLocation= s3://mybucket/myfolder/myprovider.jar,CustomProviderClass=providerclassname
利用上述代码,一个 s3get 与 configure-hadoop 引导操作将以自动化方式实现添加并分别被配置为复制提供程序 jar 文件及配置 emrfs-site.sml。其中 s3get 引导操作在获取到来自 S3 的请求后将使用被分配至该集群的 Instance Profile,这样一来大家就能够对自己的提供程序 jar 文件进行访问限制。另外,如果大家的提供程序类通过来自 Hadoop API 的 Configurable 实现,那么也能够从运行时中的 Hadoop 配置 XML 文件处获取配置数值。
S3 对象上的“x-amz.matdesc”用户元数据字段被用于存储“素材描述”,这样我们的提供程序就能了解到需要接收哪些密钥。该字段中包含一套 JSON 版本的 Map<String.String>,其会在针对现有目标进行密钥请求时被交付至提供程序实现处。当某密钥被请求编写一个新的对象时,同样的映射将被交付至 EncryptionMaterials 对象,后者当中也拥有一条 Map<String.String> 作为描述。我们会经常对加密密钥进行轮换,所以我们会利用该映射为 S3 对象所使用的加密密钥保存惟一一条标识符。密钥标识符本身不会被作为敏感信息处理,因此我们可以将其存储在 S3 当中的对象元数据之内。
数据输入任务流
纳斯达克已经拥有一套成熟的数据采集系统,其开发目标在于支持我们对 Amazon Redshift 的采用与推广。这套系统建立在一套任务流引擎之上,该引擎每天能够执行约 30000 次编排操作,同时使用 MySQL 作为状态信息的持久性存储机制。
大部分此类操作需要执行多个步骤,且遵循以下几种常见模式:
- 通过 JDBC、SMB、FTP 以及 SFTP 等对其它系统进行数据检索。
- 验证数据语法及正确性,以确保既定模式未出现变更或者数据未出现丢失等等。
- 将数据转化为 Parquet 或者 ORC 文件。
- 利用 S3 客户端加密机制将文件上传至 S3 当中。
我们的数据采集系统本身并不具备直接针对 HDFS 的能力。我们利用类似的 EncryptionMaterialsProvider 实现机制将数据直接写入至 S3 当中,而无需借助 Hadoop Configuration 接口钩子。这一点非常重要,即避免在对 EMRFS 进行数据读取或者写入时采用任何特殊方式。而且只要大家的素材提供程序能够检测到需要使用的正确加密密钥,EMR 就能以无缝化方式在 S3 当中操作加密对象。
代码示例
我们的加密素材提供程序可参照以下代码示例:
import java.util.Map; import javax.crypto.spec.SecretKeySpec; import com.amazonaws.services.s3.model.EncryptionMaterials; import com.amazonaws.services.s3.model.EncryptionMaterialsProvider; import org.apache.hadoop.conf.Configurable; import org.apache.hadoop.conf.Configuration; public class NasdaqKMSEncryptionMaterialsProvider implements EncryptionMaterialsProvider, Configurable { private static final String TOKEN_PROPERTY = “token”; private Configuration config = null; // Hadoop 配置 private NasdaqKMSClient kms = null; // 面向 KMS 的客户端 @Override public void setConf(Configuration config) { this.config = config; // 读取任意需要初始化的配置值 this.kms = new NasdaqKMSClient(config); } @Override public Configuration getConf() { return this.config; } @Override public void refresh() { /* nothing to do here */ } @Override public EncryptionMaterials getEncryptionMaterials(Map desc) { // 从素材描述中获取密钥标识 String token = desc.get(TOKEN_PROPERTY); // 从 KMS 中检索加密密钥 byte[] key = kms.retrieveKey(token); // 利用该密钥创建一个新的加密素材对象 SecretKeySpec secretKey = new SecretKeySpec(key, “AES”); EncryptionMaterials materials = new EncryptionMaterials(secretKey); // 利用密钥标识(identifier)对相关素材进行标记 materials.addDescription(TOKEN_PROPERTY, token); return materials; } @Override public EncryptionMaterials getEncryptionMaterials() { // 生成一个新的密钥,利用其进行密钥分配, // 同时利用该标识返回新的加密素材 // 并将其存储在素材描述当中。 return kms.generateNewEncryptionMaterials(); } }
总结
在本篇文章中,我们对新的数据仓库项目进行了宏观概述。由于我们现在能够将 Amazon S3 客户端加密机制与 EMRFS 加以配合,因此我们得以在 Amazon S3 当中针对闲置数据实现安全保护要求,并充分享受由 Amazon EMR 所带来的可扩展能力以及应用程序生态系统。
如果大家对此有任何疑问或者建议,请在评论栏中与我们分享。
查看原文链接: Nasdaq s Architecture using Amazon EMR and Amazon S3 for Ad Hoc Access to a Mass

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论