1 研发背景
互联网时代也是信息爆炸的时代,内容太多,而用户的时间太少,如何选择成了难题。电商平台里的商品、媒体网站里的新闻、小说网站里的作品、招聘网站里的职位……当数量超过用户可以遍历的上限时,用户就无所适从了。
对海量信息进行筛选、过滤,将用户最关注最感兴趣的信息展现在用户面前,能大大增加这些内容的转化率,对各类应用系统都有非常巨大的价值。
搜索引擎的出现在一定程度上解决了信息筛选问题,但还远远不够,其存在的两个主要弊端是:第一搜索引擎需要用户主动提供关键词来对海量信息进行筛选。当用户无法准确描述自己的需求时,搜索引擎的筛选效果将大打折扣,而用户将自己的需求和意图转化成关键词的过程有时非常困难(例如“找家附近步行不太远就可以到的餐厅,别太辣的”)。更何况用户是懒惰的,很多时候都不愿意打字。第二是搜索结果往往会照顾大多数用户的点击习惯,以热门结果为主,很难充分体现出个性化需求。
解决这个问题的最好工具就是——推荐系统(Recommendation System)。
推荐系统的效果好坏,体现在推荐结果的用户满意度上,按不同的应用场景,其量化的评价指标包括点击率、成交转化率、停留时间增幅等。为了实现优秀的推荐效果,众多的推荐算法被提出,并在业界使用。但是其中一类方法非常特殊,我们称为多模型融合算法。融合算法的意思是,将多个推荐算法通过特定的方式组合的方法。融合在推荐系统中扮演着极为重要的作用,本文结合达观数据的实践经验为大家进行系统性的介绍。
为什么需要融合推荐算法
推荐系统需要面对的应用场景往往存在非常大的差异,例如热门 / 冷门的内容、新 / 老用户,时效性强 / 弱的结果等,这些不同的上下文环境中,不同推荐算法往往都存在不同的适用场景。不存在一个推荐算法,在所有情况下都胜过其他的算法。而融合方法的思想就自然而然出现了,就是充分运用不同分类算法各种的优势,取长补短,组合形成一个强大的推荐框架。俗话说就叫“三个臭皮匠顶个诸葛亮”。
在介绍融合方法前,先简单介绍几类常见推荐算法的优缺点
基于物品的协同过滤(Item-based Collaborative Filtering)是推荐系统中知名度最高的方法,由亚马逊(Amazon)公司最早提出并在电商行业内被广泛使用。
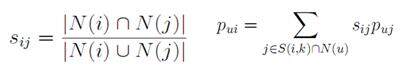
基于物品的协同过滤在面对物品冷启动(例如新上架物品),或行为数据稀疏的情况下效果急剧下降。另外,基于物品的协同过滤倾向于为用户推荐曾购买过的类似商品,通常会出现多样性不足、推荐惊喜度低的问题。
而另一类协同过滤方法,基于用户的协同过滤(User-based Collaborative Filtering)方法,其公式略有不同:
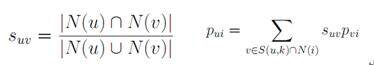
基于用户的协同过滤在推荐结果的新颖性方面有一定的优势,但是推荐结果的相关性较弱,而且容易受潮流影响,推荐大众热门物品。同时新用户或低活跃用户也会遇到用户冷启动的棘手问题。
还有一类方法称为基于模型的方法。常见的有隐语义与矩阵分解模型(Latent Factor Model),LFM 对评分矩阵通过迭代的方法进行矩阵分解,原来评分矩阵中的 missing value 可以通过分解后的矩阵求得。
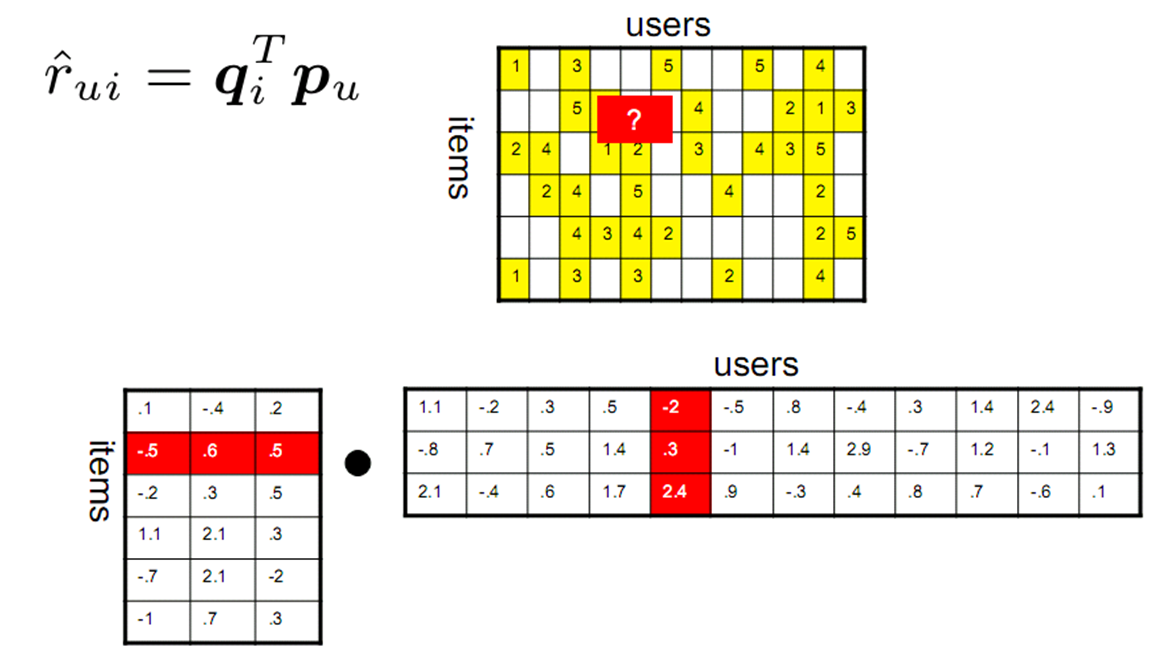
在达观数据的实践经验里,LFM 通常是推荐精度较好的一类计算模型。但当数据规模大时其运算性能会明显降低,同时计算依赖全局信息,因而很难作增量更新,导致实际工程中会遇到不少困难。而且隐语义模型还存在调整困难、可解释性差等问题。
基于内容的推荐算法(Content-based Recommendation)是最直观的推荐算法,这个方法实现简单方便,不存在冷启动问题,应对的场景丰富,属于“万金油”型打法。例如按同类别、同标签等进行推荐。但在一些算法公开评测中,基于内容的方法效果都是效果较差的。原因时基于内容的方法缺少用户行为的分析,存在“结果相关但是不是用户想要的”这样难以克服的问题。同时该算法往往受限于对文本、图像或音视频内容分析的技术深度,很难准确把握住用户真正关注的“内容点”。
基于统计思想的一些方法,例如 Slope One,关联规则 (Association Rules),或者分类热门推荐等,计算速度快,但是对用户个性化偏好的描述能力弱,实际应用时也存在各种各样的问题,在此不多赘述。
即使相同的算法,当使用不同数据源时也会产生不同的推荐结果。比如协同过滤,使用浏览数据和使用交易数据得到的结果就不一样。使用浏览数据的覆盖面比较广,而使用交易数据的偏好精度比较高。
常见的多模型融合算法
达观数据的众多实践发现,多模型融合算法可以比单一模型算法有极为明显的效果提升。但是怎样进行有效的融合,充分发挥各个算法的长处?这里总结一些常见的融合方法:
1)线性加权融合法
线性加权是最简单易用的融合算法,工程实现非常方便,只需要汇总单一模型的结果,然后按不同算法赋予不同的权重,将多个推荐算法的结果进行加权,即可得到结果:
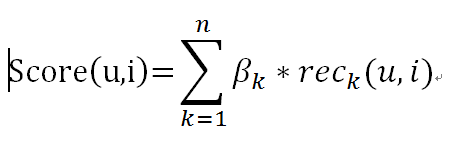
是给用户(user)推荐商品(item)的得分, 是算法 K 的权重,是算法 k 得到的用户(user)对商品 item 的推荐得分。这种融合方式实现简单,但效果较差。因为线性加权的参数是固定的,实践中参数的选取通常依赖对全局结果升降的总结,一旦设定后,无法灵活的按照不同的推荐场景来自动变换。比如如果某个场景用算法 A 效果较好,另外一种场景用算法 B 效果较好,线性融合的方式在这种情况下不能取得好的效果。为了解决这个问题,达观数据进行了改进,通过引入动态参数的机制,通过训练用户对推荐结果的评价、与系统的预测是否相符生成加权模型,动态的调整权重使得效果大幅提升。
2) 交叉融合法
交叉融合常被称为 Blending 方法,其思路是在推荐结果中,穿插不同推荐模型的结果,以确保结果的多样性。
这种方式将不同算法的结果组合在一起推荐给用户
交叉融合法的思路是“各花入各眼”,不同算法的结果着眼点不同,能满足不同用户的需求,直接穿插在一起进行展示。这种融合方式适用于同时能够展示较多条结果的推荐场景,并且往往用于算法间区别较大,如分别基于用户长期兴趣和短期兴趣计算获得的结果。
3)瀑布融合法
瀑布型(Waterfall Model)融合方法采用了将多个模型串联的方法。每个推荐算法被视为一个过滤器,通过将不同粒度的过滤器前后衔接的方法来进行:
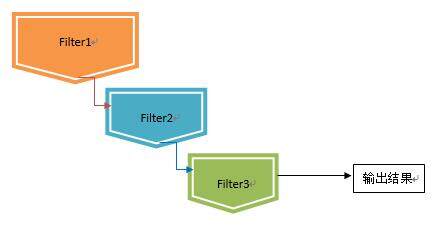
在瀑布型混合技术中,前一个推荐方法过滤的结果,将作为后一个推荐方法的候选集合输入,层层递进,候选结果在此过程中会被逐步遴选,最终得到一个量少质高的结果集合。这样设计通常用于存在大量候选集合的推荐场景上。
设计瀑布型混合系统中,通常会将运算速度快、区分度低的算法排在前列,逐步过渡为重量级的算法,让宝贵的运算资源集中在少量较高候选结果的运算上。在面对候选推荐对象(Item)数量庞大,而可曝光的推荐结果较少,要求精度较高、且运算时间有限的场景下,往往非常适用。
4)特征融合法
不同的原始数据质量,对推荐计算的结果有很大的影响。以用户兴趣模型为例,我们既可以从用户的实际购买行为中,挖掘出用户的“显式”兴趣,又可以用用户的点击行为中,挖掘用户“隐式”兴趣;另外从用户分类、人口统计学分析中,也可以推测用户偏好;如果有用户的社交网络,那么也可以了解周围用户对该用户兴趣的影响。
所以通过使用不同的数据来源,抽取不同的特征,输入到推荐模型中进行训练,然后将结果合并。这种思路能解决现实中经常遇到的数据缺失的问题,因为并非所有用户都有齐全的各类数据,例如有些用户就缺少交易信息,有些则没有社交关系数据等。通过特征融合的方法能确保模型不挑食,扩大适用面。
5)预测融合法
推荐算法也可以被视为一种“预测算法”,即我们为每个用户来预测他接下来最有可能喜欢的商品。而预测融合法的思想是,我们可以对每个预测算法再进行一次预测,即不同的算法的预测结果,我们可以训练第二层的预测算法去再次进行预测,并生成最终的预测结果。
如下图所示,我们把各个推荐算法的预测结果作为特征,将用户对商品的反馈数据作为训练样本,形成了第二层预测模型的训练集合,具体流程如下
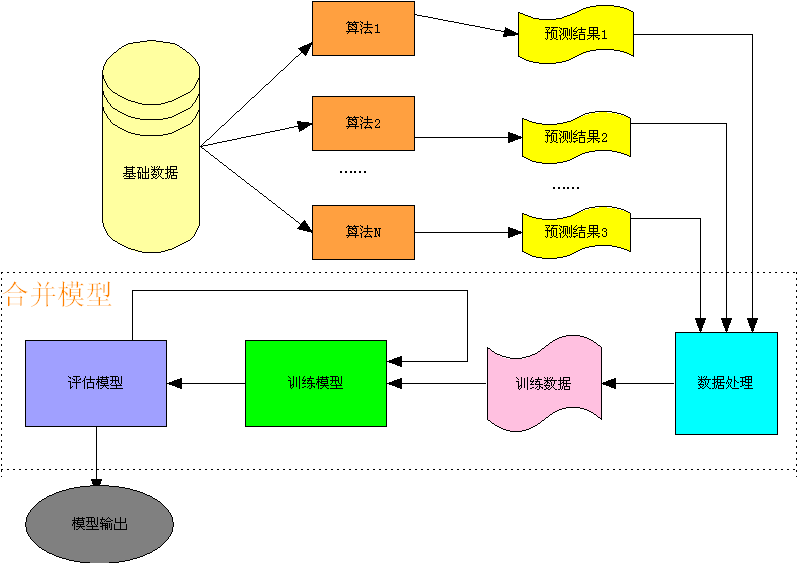
图中的二层预测模型可以使用常用的分类算法,如 SVM、随机森林、最大熵等,但达观实践中,融合效果较好的是 GBDT(Gradient Boosting Decision Tree) 方法。
6)分类器 Boosting 思想
推荐问题有时也可以转化为模式分类(Pattern Classification)问题去看待,我们将候选集合是否值得推荐划分为几个不同的集合,然后通过设计分类器的方法去解决。这样一来我们就可以用到分类算法中的 Boosting 思想,即将若干个弱分类器,组合成一个强分类器的方法。Boosting 的核心思想是每轮训练后对预测错误的样本赋以较大的权重,加入后续训练集合,也就是让学习算法在后续的训练集中对较难的判例进行强化学习,从而得到一个带权重的预测函数序列 h,预测效果好的预测函数权重较大,反之较小。最终的预测函数 H 对分类问题采用有权重的投票方式,对回归问题采用加权平均的方法对新示例进行判别。算法的流程如下:(参考自 treeBoost 论文)

通过模型进行融合往往效果最好,但实现代价和计算开销也比较大。
达观的多级融合技术
在达观数据( http://datagrand.com )的实践中,采用的多级融合架构如下:
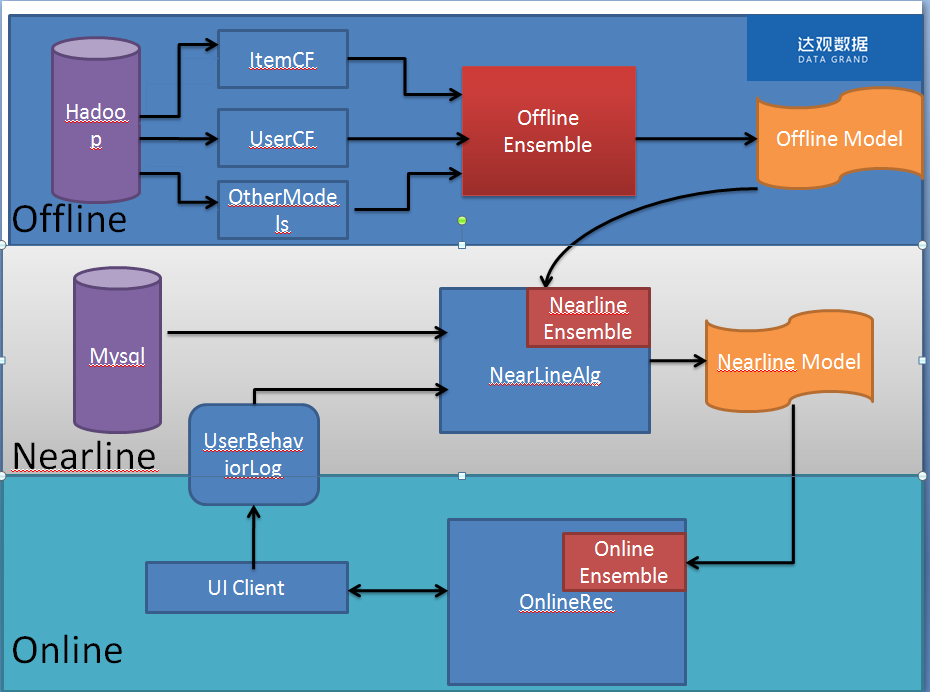
Online 系统
直接面向用户,是一个高性能和高可用性的推荐服务,其中的 Online Ensemble 模块会融合 Nearline 计算的推荐结果以及基于 content Base 的推荐结果。Online 系统往往请求压力比较大,需要在较短的时间内返回结果,所以这里往往使用最简单的优先级融合算法。
Nearline 系统
这个系统部署在服务端,一方面会接收 User Behavior Log,根据用户最新的动作行为,生成推荐结果,并且和 Offline Model 进行融合,达观这边使用通过点击反馈进行调整的线性融合方法,具体方法如下,
-
Nearline 获取用户的展现日志和点击日志。展现日志包括了用户展现的哪些 item,以及这些 item 是通过什么算法推荐出来,推荐的位置,以及对应的权重
-
如果是展现日志,则减小推荐出 item 对应策略的权重,更新方式如下
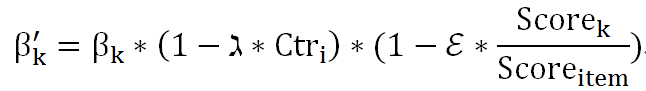
是更新后的权重,是展现位置 i 的平均点击率,是算法 K 对该 item 的得分。是该 item 的总得分。是位置点击率的衰减常数、是算法点击率的衰减常数,可以根据具体的业务场景设置不同的值。
-
如果是点击日志,则增加推荐出 item 的对应策略的权重,更新方式如下
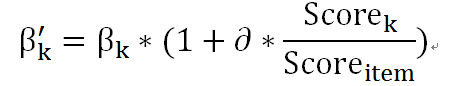
是更新后的权重,是算法 K 对该 item 的得分,是该 item 的总得分, 是点击衰减常数
-
根据更新后的权重,重新计算该用户的推荐结果。
通过这种融合方式,会为每个用户生成一个加权线性融合算法的 Model,根据这个 Model 计算出对应的推荐结果。
Offline__系统
挖掘长期的、海量的用户行为日志。以优化点击率为例,我们可以把用户的展现过的 item,以及是否点击形成训练数据,我们就需要生成一个是否点击的分类模型。我们的分类器分为两个 Level: L1 层和 L2 层。L1 层是基础分类器,可以使用协同过滤、矩阵分解、contentbase 等基础算法;L2 层基于 L1 层,将 L1 层的分类结果形成特征向量,再组合一些其他的特征后,形成 L2 层分类器(如 GBDT)的输入。
Ensemble 的训练过程稍微复杂,因为 L1 层模型和 L2 层模型要分别进行训练后再组合。实践中我们将训练样本按照特定比例切分开,分别简称为 Train pig 和 Test Pig。基于划分后的样本,整个训练过程步骤如下:
- 使用 Train pig 抽取特征,形成特征向量后训练 L1 层模型
- 使用训练好的 L1 层模型,预测 Test pig,将预测结果形成 L2 层的输入特征向量
- 结合其他特征后,形成 L2 层的特征向量,并使用 Test pig 训练 L2 层模型
- 使用全部训练样本(Tain pig + Test pig)重新训练 L1 层模型
- 将待测样本 Test 抽取特征后先后使用上述训练好的 L1 层模型生成预测结果,再把这些结果通过 L2 层 Ensemble 模型来生成最终的预测结果
达观在使用过程中的一些心得如下
1)算法融合的特征除了算法预测值之外,也可以加入场景特征。比如在场景 1 算法 A 效果较好,场景 2 中算法 B 效果较好,当我们把场景也作为特征进行融合,就可以学习出这种特征
2)数据切分一定要干净。往往容易犯的错误是基础算法用的一些词典使用了全部的数据,这会使得融合算法效果大打折扣,因为相当于基础算法已经提前获知了融合算法的测试数据
3)基础算法的区分度越好,融合算法的效果越好,比较不容易出现过拟合
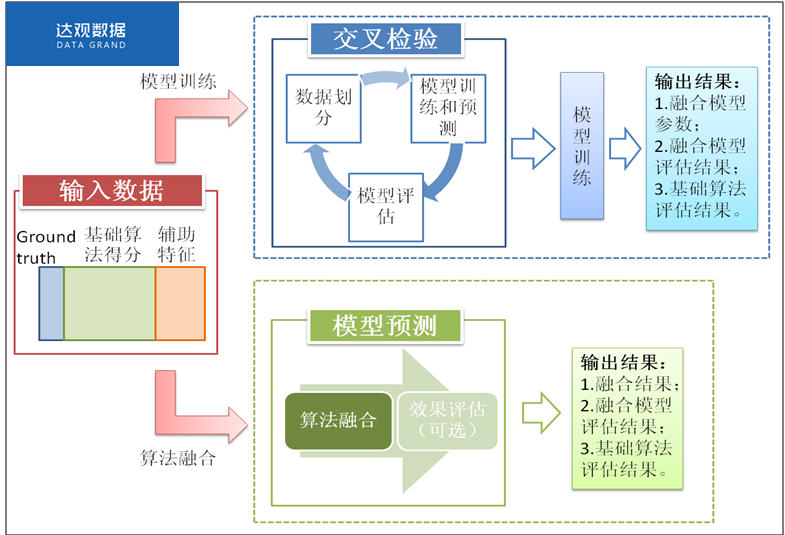
4)L2 层也一样可能出现过拟合(Overfitting),所以也可以加交叉验证,L2 层示意图如下图所示
总结和展望
推荐系统中的融合技术是非常重要的一个环节,在实战中,灵活运用融合技术可以发挥各个算法的长处,满足多样的用户需求,大大提升推荐结果的质量,达观数据在此方面将不懈努力,探索出更多更好的应用。
作者简介
纪达麒,达观数据联合创始人 &CTO, 国际计算机学会(ACM)会员。曾服务于搜狗、盛大、腾讯几家公司,任腾讯文学数据中心高级研究员、盛大文学技术总监等职务,主要负责数据挖掘与分析团队。在推荐系统、用户建模、计算广告等领域有较深入的理解和多年的实战经验,有 6 项推荐系统、数据挖掘相关的国家发明专利,多次圆满完成公司重大紧急项目的开发工作,所开发的智能推荐系统曾创造了上线后点击率提升 300% 的记录。曾带领团队多次获得国际数据挖掘竞赛的大奖。如 2012 年 ACM KDD-Cup 国际大数据竞赛亚军、2014 年 ACM CIKM-Competition 世界冠军、EMI Hackathon 音乐推荐算法竞赛世界冠军等。拥有北京邮电大学计算机硕士学位。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




