机器学习会议于四月十一日(星期五)在纽约盛大召开。这是首次在纽约召开机器学习会议,这次会议取得了空前巨大的成功,以至于会议入场券很快就宣告售罄。会议一整天都围绕机器学习的话题展开,其中有相当一部分话题还涉及到了大数据以及如何大规模应用机器智能的问题。
所有迹象都表明,数据科学领域变得比以往任何时候都更加强大,如今的数据科学家至少得具备两项技能:具有数学和统计背景的传统研究技能和能够使用当下最流行的大数据框架从事工作的工程技能。
机器学习和大数据
来自于 Google 公司的 Corinna Cortes 首先登台,由此拉开了大会的序幕。他介绍了 Google 公司的服务是如何构建的,尤其是如何将服务扩展到数以百万用户。以图像浏览问题为例,Google 在一款命名为 Google Image Swirl 的产品中应用了他们在图像处理方面的研究成果,该产品能够把相似的图片聚集在一起。据 Corinna 介绍,可以通过计算图片和已形成聚类中的所有图片之间的两两距离把相似的图片聚集到一起,但是按照 Google 的数据规模这种方式很快就被否定了。为了解决这个问题,Google 一开始即使用了 Kernel-PCA 算法的短矢量描述图像,并采用随机预测自上而下地增长结果树。在查询时,只需要查找结果树并返回相关的图像即可。
Corinna 讲述的另一个例子是 Google Flu Trends (Google 流感趋势),它的本质是发现查询搜索之间的相关性。这类似于 Google 另一个称为 Google Correlate 的产品,它允许用户上传自己的数据到服务器并由此整理出各种类型的图表,再配合互联网搜索结果整合出该词汇的搜索趋势。Corinna 介绍了该产品的原理:通过把时间序列拆分成较小的块,把每个块看作是一个聚类中心,然后使用 K-means 算法对这些小块进行聚类从而发现其趋势。
来自于 Intel 公司的 Ted Willke 登场后强调了一个重要的范式转换:我们的生活周围充满了语境和语义问题,这些语境和语义正在被越来越多的系统所分析使用,比如 RDF (资源描述框架,即使用 XML 语法将元数据描述成数据模型)。网络规模的扩展也为RDF 数据的存储和处理带来了挑战。Ted 介绍了使用 Titan 分布式数据库存储 RDF 数据,并应用 LDA 算法使用 Gremlin 简化数据表示的做法。
在另一个非同寻常的演讲中,来自 Tapad 公司的 Yael Elmatad 讲述了 Tapad 公司的设备图构造算法,这个设备图是由连接到一起的消费者的设备组成,它包含了由超过 100 万个家庭和 250 万个人组成的近 20 亿个节点。设备之间边的加权算法经过了多次尝试之后才得以修正。最初,Yael 专注于数据分段(根据不同设备各自的特征来分段),但是很快 Yael 就发现这种方法表现不佳,仅比随机猜测好 10%,因为分段数据本身充满了随机性和噪音,而且较长寿命的设备往往会积累很多段。Yael 并没有设法去纠正这个数据上的偏差,而是考虑到这是一个比较独特的领域,因此采用了一种不同的方法。这个方法就是使用 Tapad 公司的内部浏览数据,虽然这些数据很难获取并且很稀疏。但是结果却令人鼓舞,比随机猜测好了 40%,这已经非常接近于 Tapad 公司认定的比随机好 50% 的理想结果了。关于构建模型时应该考虑什么样的数据 Yael 总结了一个有趣的论述:
稀有的和原始的数据往往是最好的数据,因为这些数据没有包含隐藏的偏见,也没有经过不必要的处理。
来自 Yahoo 公司的 Edo Liberty 登台介绍了一种流计算模型,该模型常被用于在内存有限的情况下进行大规模数据处理。Edo 的任务是发明一种算法,在 Yahoo 邮箱电子邮件资源有限的情况下处理数以百万计的用户请求。这就是 Edo 在其讲义中描述的 Misra-Gries 算法,该算法对所有有效的邮件进行聚类,计算它们的条件概率从而确定两封电子邮件之间可能的前后关联。这种方法可以追溯到一个共同的理论,即空间交易的准确性。
在可扩展性方面市面上有许多数据库,例如 Amazon Redshift ,它为了性能而构建并试图成为一个通用的平台以适用于所有用例。正如 LogicBlox 公司的 Shan Shan Huang 所说,有时一个因为非常具体的目标而构建的数据库也可以扩展成一个通用的数据库,就像 Amazon Redshift 。LogicBlox 公司已经以 Leapfrog Triejoin 的形式实现了他们自己的连接算法,这是一种最坏情况下的最优连接,并且可以在他们自己的平台上使用。
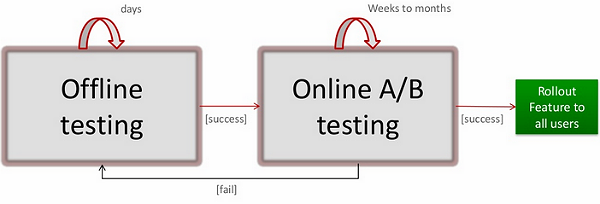
在这一天的讨论中,最令人印象深刻的话题是由 Netflix 公司的 Justin Basilico 发起的,这家公司拥有 30% 以上的美国交通信息。 Justin Basilico 介绍了他们是如何构建推荐系统并基于用户的口味在首页显示用户喜欢的影片的。在Netflix 公司看来,所有的行为数据皆可用于推荐,包括游戏数据,评级信息,电影数据,印象,交互,甚至是社交数据。之后这些事件会被送到多个模型进行处理,而这些模型在推给所有用户之前会经过严格的测试评估,整个流程如下:
很多用户都想在其现有的Hadoop 架构上应用机器学习算法,不只是Mahout(开源项目,提供一些可扩展的机器学习领域的经典算法的实现),还包括H2O。来自Oxdata 的Irene Lang 和AnqiFu 详细介绍了如何使用H2O 在Hadoop 之上增加一个内存层和R 算法接口以保持其在数据科学界的认识度。
崛起的Spark
Apache Spark 是一个开源项目,它最初是由加州大学伯克利分校开发的,到现在为止也不过才仅仅开发了两年之久。现在,它已经成为最流行的大数据架构之一,它具有最活跃的社区贡献者,甚至超越了 Apache Hadoop 。在机器学习大会上,Spark 成为很多话题中的一个共同的主题,这强化了 Spark 作为一个处理大规模数据领域的领先架构的地位。
不必对来自于 Databricks 的演讲感到惊讶,因为这家公司在 Spark 幕后做了很多无私的工作。 Xiangrui Meng 对 Spark 框架作了一个精辟的阐述,并强调了 Spark 的一个关键点:Spark 将成为数据科学领域最为强大的平台,因为它把所有与数据科学有关的组件整合成了一个单一的平台。MLlib 就是在 Spark 之上构建的一个项目,它提供了一个可靠的、大规模的机器学习平台,这个平台可以被集成到其它由 UC Berkeley 提供的软件项目中。比如,可以把 MLlib 集成到 Spark SQL 中,Xiangrui 给出了下面的例子:
// 数据能从已有的数据源中轻松抽取出来
// 比如 Apache Hive(集市数据批量加工和处理技术)
val trainingTable = sql("""
SELECT e.action,
u.age,
u.latitude,
u.longitude,
FROM Users u
JOIN Events e
ON u.userId = e.userId""")
// 因为‘SQL’返回的是一个 RDD,所以上述查询结果可以轻松地适用于 MLlib
val training = trainingTable.map { row =>
val features = Vectors.dense(row(1), row(2), row(3))
LabeledPoint(row(0), features)
}
val model = SVMWithSGD.train(training)
并且为了整合 Spark Streaming,下面的例子展示了如何实时收集和处理微博:
// 装配连接图
val graph = Graph(pages, links)
val pageRank: RDD[(Long, Double)] = graph.staticPageRank(10).vertices
// 加载页标签(垃圾邮件或其它)和内容特征
val labelAndFeatures: RDD[(Long, (Double, Seq((Int, Double))))] = ...
val training: RDD[LabeledPoint] =
labelAndFeatures.join(pageRank).map {
case (id, ((label, features), pageRank)) =>
LabeledPoint(label, Vectors.sparse(features ++ (1000, pageRank))
}
// 利用逻辑回归检测垃圾邮件
val model = LogisticRegressionWithSGD.train(training)
根据 Cloudera 公司的 Josh Wills 所讲,Spark 真正强大的一个地方在于:它同时擅长数据清理和数据建模。因为所有的事情都能在同一环境下完成,所以开发者不必在上下文之间不断地切换。但是 Josh 觉得这依然很原始,因为开发者需要手工把原始数据导入模型,Josh 喜欢利用 Spark 想要为 Spark 实现一个特征提取 DSL(领域特定语言),类似于 R 公式规范。然而,真正的挑战是它需要在分布式环境中运行,并且需要大量的开发。
Spark 还是一个不够成熟的技术,但是依然有一些发言者提到他们正在等待机会把 Spark 带入到他们的基础设施中,包括 Spotify 和 Netfix。
用机器学习分析人类行为
人类的行为非常丰富,同时也成为很多公司的驱动力,比如社交网络。来自 HireIQ 公司的 Todd Merrill 讲述了如何利用行为分析帮助呼叫中心做出聘用决策。通过对面试过程中记录的语音信号进行音频分析,HireIQ 能抽取出类似于音调这样的有意义的特征,并利用这些特征构建模型从而最小化一个潜在员工可能在短期内退出的概率。尽管在开始的时候因为过度拟合存在一些缺陷,但现在这个工具大部分情况下能得出和人类专家一样的结果,并且能够有效降低呼叫中心的招聘成本。
人类行为分析应用最广泛的领域是在线网络广告的投放。来自于 Dstillery 的 Claudia Perlich 详细地讲述了在展示广告的高维数据上应用模型时所面对的挑战。这个演讲中的一个有趣的亮点是:你必须在乖离率和方差之间作出一个权衡,有时优化不同的变量可以产生更好的结果。比如,在构建一个模型从而决定谁会购买给定网站上的物品的时候,试图分析优化点击可能会产生几乎随机的结果,因为你可能在为那些视力不好的人优化,而针对网站访问这种简单的指标优化产生的结果反而可能会更好。Claudia 还给出了另一个经验:准备样本的时候,要保持正面样本和反面样本的比例大致相当,否则会影响模型的准确性。
Spotify 带来了另一个完全不同的案例,也是与人类行为分析相关的。 Erik Bernhardsson 解释了企业如何从使用的数据中发现模式,并将其应用于协同过滤结构音乐,即找到和你喜好类似的音乐。关键因素之一是要计算出两个音轨或专辑的相似度。Erik 引用了 George Box 的话:
基本上,所有的模型都是错误的,但有些是有用的。
这正是 Spotify 所采用的方法,通过在播放次数上使用潜在因素法把问题转变成矩阵分解问题。其思想就是把所有的用户和轨迹置入一个大的稀疏矩阵,然后运行 PLSA 算法。其结果就是一组非常小且紧凑的用户音乐品味指纹图的向量。除了具有一个固定的基础模型之外,这个方法还非常快,也非常容易扩展,而且其相似性计算犹如计算余弦相似度一样容易。虽然最初的时候PLSA 并不适合内存,同时团队也必须采用Hadoop,但是大部分新的模型并不需要很多潜变量,并且适合于RAM,因而也避免了Hadoop 的开销。
机器学习的广泛应用
机器学习也能帮助科学家把他们的算法应用于更多方面,正如来自于 Ayasdi 的 Pek Lum 所介绍的案例。Pek 应用 Topological Data Analysis (TDA) 技术解决当今大多数基于查询的系统的局限性。例如,当需要从癌症患者样本中发现相似的人类基因组时,Ayasdi 利用 TDA 建立图形网络并发现这些数据中的模式。这种特定类型的分析还能应用于其他高维复杂数据集。依据 Pek 所说,对于任何类型的 TDA 系统而言,主要有三个基本的属性:
- 坐标不变性:即使形状得到旋转、翻转,或者更一般地改变坐标系,形状的拓扑度量属性都不会被改变。
- 形变不变性:即使形状被拉长或压扁,其尺寸也不会被改变。
- 压缩表示:在处理图形的时候能够将其还原到原来的基本元素,能够剥离出噪音仅保留与信号相关的部分是非常重要的。
IBM Watson(沃森)团队还把机器学习应用到了医疗保健领域,在电脑 Watson 击败人类之后人们就开始使用 Watson 之后的系统处理现实世界中的问题,尤其是医疗保健。Watson 构建在语义关系抽取之上, Chang Wang 介绍了如何将其应用于医学领域。其主要思想就是,首先通过检测问题之间的关系产生候选答案,然后从 DBpedia 或者 FreeBase 这样的知识库中查找。在产生了候选答案之后,第二步就是分析语句以决定它们的意思是否一样。最后,Watson 会构建并更新知识库,这对像医疗知识这种假设变化得非常快的领域是至关重要的。
医疗保健数据具有不确定性的特点,来自于斯蒂文斯理工学院( Stevens Institute of Technology )的 Samantha Kleinberg 讲述了它是如何影响模型的。他所面临的一个具体问题就是基于血液中葡萄糖的水平决定胰岛素的摄入量,通过体内的传感器进行自动调节。传感器本身可能会给出错误的结果,比如当它们被校准,或者当它们被关闭而缺失值的时候。这将导致高噪音数据,必须被离散化。
关于作者
 Charles Menguy是一个内心对数据科学存在强烈偏见的软件工程师。他已经成功把 Hadoop 大数据技术应用于网络广告业,目前供职于 Adobe 公司,从事的工作是帮助公司扩展其基础设施以应对现代网络应用中产生的大规模的数据。
Charles Menguy是一个内心对数据科学存在强烈偏见的软件工程师。他已经成功把 Hadoop 大数据技术应用于网络广告业,目前供职于 Adobe 公司,从事的工作是帮助公司扩展其基础设施以应对现代网络应用中产生的大规模的数据。
Charles 热衷于数据分析和机器学习,也是 StackOverflow 的积极贡献者,最近开始在这里写博客。
参考英文原文: MLConf NYC 2014 Highlights
感谢孙镜涛对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。




