
物流的战火,从来都是“非传统”的竞争者从“非传统”的角度切入的。
1956 年,马尔科姆·麦克莱发明了集装箱。世界上第一支集装箱船队从美国扬帆起航,将当时的货运成本从 5.83 美元 / 吨降低到 0.158 美元 / 吨。保守的运输公司、火车运输公司以及装卸工人等各派实力极力反对。但是市场的手,无情地摧毁了所有的试图抵抗时代潮流的巨头。
1997 年,罗宾逊把在海运服务领域的“无船承运人”思想,移植到公路货运服务领域,向“无车承运人”转型。这一次大胆转型,罗宾逊抛弃了自有运输车辆,建立了整合社会运输商的信息系统。三年内跃居美国第一公路运输企业。
明天的这把火,很可能烧在人工智能。烧掉传统物流同行的武器仍然不变:成本。我们的战场就是中国的公路干线物流。
中国物流的特点是大而复杂。2016 年运输费用 6.0 万亿(绝大部分是公路),物流总成费用 11 万亿,占 GDP 15.3%。平均运输距离 429 公里,累计运输量 336 亿吨。在这个大市场中,存在地区性差异和季节性差异,参与其中的玩家众多:个体司机,车队老板,物流公司,黄牛,3PL,工厂,连锁集团等等。而且,中国是个全工业链国家,运输品类最为齐全。运输附加值从最高的半导体、精密机械到最大宗的煤炭、矿石、农产品,呈现强烈的地域性差异。(本文图中的数据均来自满帮)
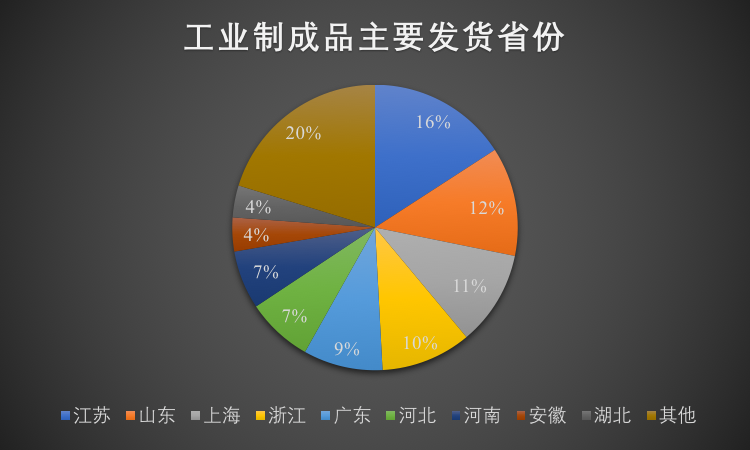
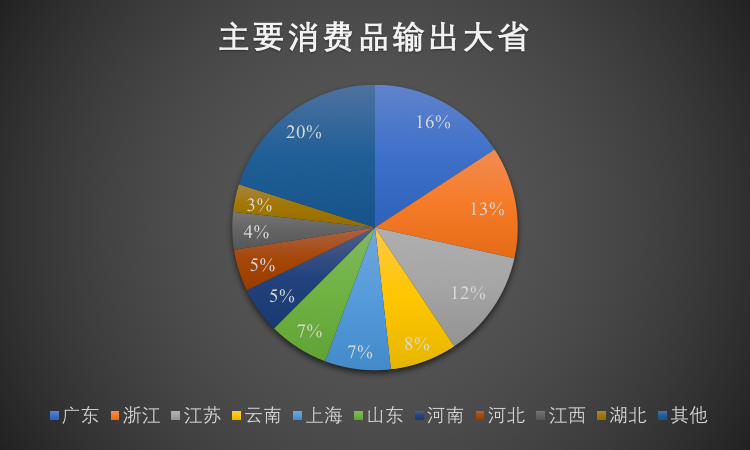
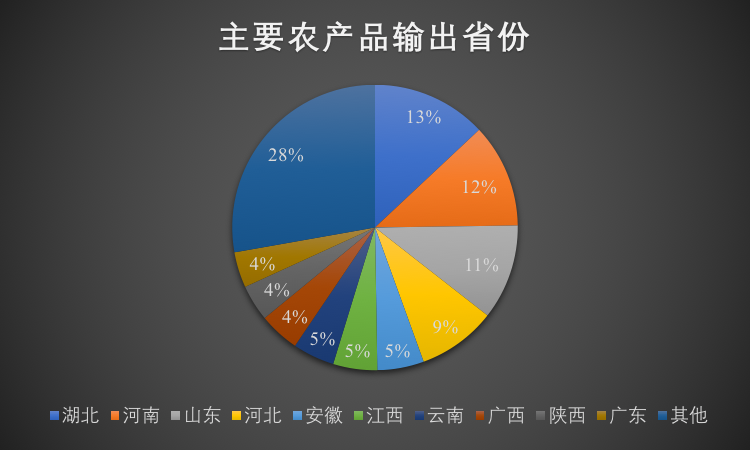
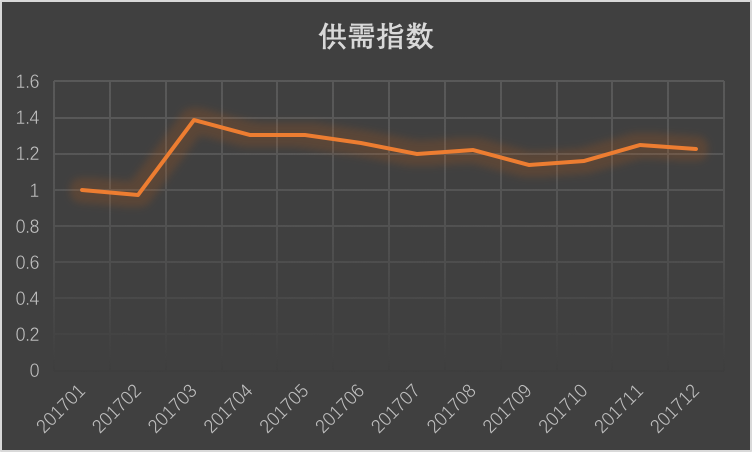
除了存在地区性差异,还存在巨大的季节性差异,比如煤炭、蔬菜天然就存在季节性差异,而节日,南北气候差异更是直接影响了大宗运输。比如9 月开始突增的西安到西藏地区的煤炭运输。即便从全国看来,不同季节的供需关系也是动态的。
那么作为全国最大的公路物流平台,如何在国内庞大的物流市场,应对不同空间和时间的需求呢?我们的中心抓手就是:市场供需。方向有两个:车货匹配,智能调度。
公路车货匹配的场景和特色
车货匹配在广义上,也是撮合交易的一种,如同电商、打车。在平台产品上的展现形态,也以推荐、排序、订单匹配为主。但车货匹配有极其独特的特点,比如货源是无库存的唯一品和非标准品。唯一指的是每宗货源几乎各不相同,运输方案、时间各有变化,而且一次性成交就立刻下线,完全不同于商城的热点商品推荐原则。非标是指,货源对车辆是有要求的,而且在不同时间、线路、种类上计价方式也不同,是非标准品。这一点也和打车出行场景的车人匹配产生重大差异。还有一点和打车场景不同的是,车人匹配的场景是局部区域在较短时间窗口内满足供需,车货匹配则是长时间大区域内的匹配——毕竟货运计划可以长达一个月,车辆的行驶里程远大于打车场景。
完成匹配,先要解决大数据的采集和计算框架问题
车货匹配平台有很多数据进入的通道,比如天气、GPS/ 北斗位置信息、用户app 行为日志、交易和支付、车辆行驶数据等等。这些数据要经过一个略显传统的大数据框架来处理。为了满足实时性,还需要流式计算是Spark streaming 组件和相关的t+0 服务。由于满帮的融合,整套数据方案还要同时解决开放性问题,能够在数仓和实时策略做到互相授权、互相调用。因此,我们还要建设一个强大的中台数据服务端。
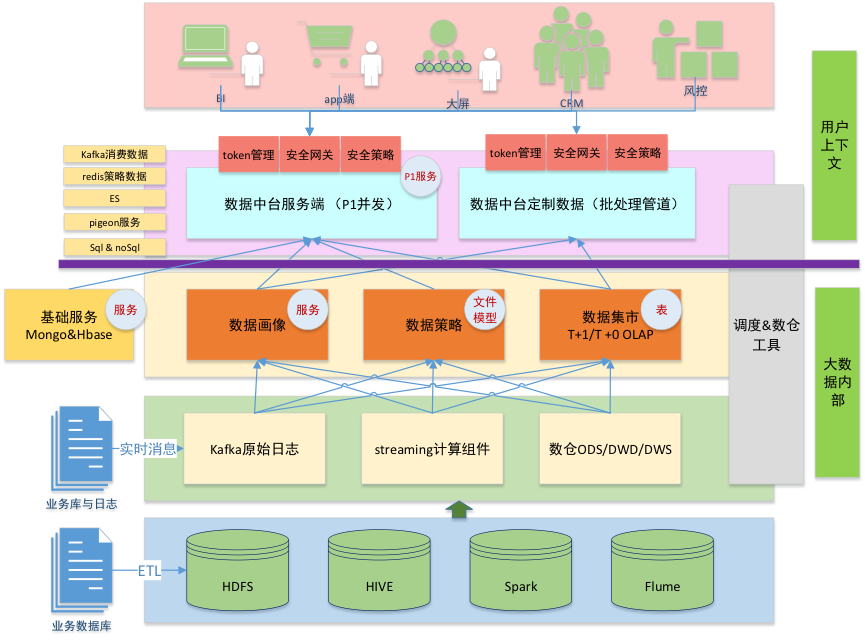
业内有个著名的共识,按重要性排序,场景> 数据> 算法。在满帮集团的公路干线匹配平台上,我们建设了自己的数据架构,解决了离线和在线的数据计算和存储问题,并且用灵活的机制保证策略的“热插拔”——能够随时将测试完成的策略快速配置在生产线上,并安排适合的灰度、AB 和评估工具。
车货匹配和智能调度实现方法详解
具体到车货匹配,这个算法场景本质是一个推荐场景,也依然可以套在CTR、CVR 的模型上,所不同的是,我们推荐的商品是“唯一”属性的,还要兼顾地区差异和“公平性”。公平性是这样一种指征:在一个时间窗口内,被拨打电话或IM 进行联系的货源,除以总货源。叫做反馈率。这是个重要指征,因为这个值和地区(区县一级)的供需关系(拨打电话司机,发货货主)呈现强烈正相关。反馈率一旦达到一个阈值,就会在这个地区形成一种新的平衡:用户自然流失等于或小于平台自然流入,地面团队可以把更多精力放在服务用户身上,而非拉新促活。那么对于业务指标来说,完成反馈率提升甚至比提供更有效的用户匹配更重要——所以公平性原则的权重很大。
重点是实时部分的接入机制。传统的小黑板方式成交,基本需要半天甚至一天的时间来实现供需双方的撮合。大规模使用线上平台,2016 年24 小时反馈则达到了60%。到了2017 年,58% 的货源基本在1 小时内完成线上撮合,2018 年,20 分钟内撮合行为发生率40%,人货匹配策略彻底成了一个线上实时策略。
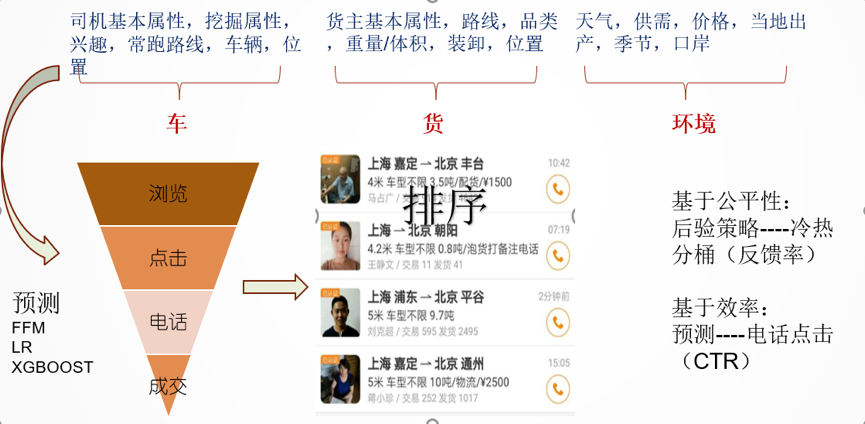
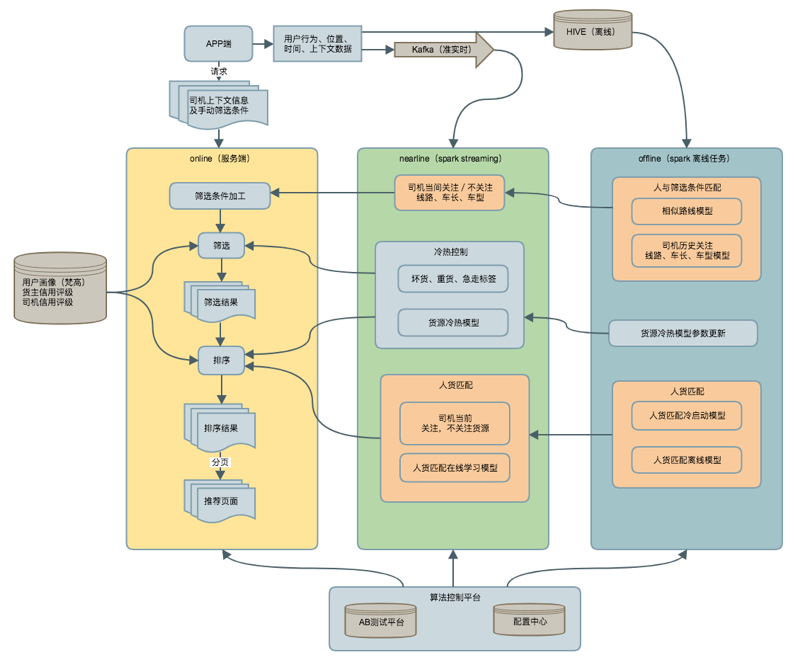
在这个体系内,基本上货源在上架瞬间,我们能准确找到它的潜在承运方,预测出会有多受欢迎(在不同的冷热分桶里会有多少个电话),策略是让车- 货匹配,和让过于受欢迎、有竞争力的货源能够牺牲部分曝光,分配给冷门的货源,以实现公平性,达到反馈提升的效果。
具体到技术细节来说,我们使用Xgboost 来预测车- 货的基础相关性,实际是一个CTR 和CVR 混布模型,我们在其中部署了在线实时系统,自研了一套基于FTRL 算法的在线学习算法,将用户实时的行为数据结果和Xgboost 的离线结果共同训练而得,点击预测的准确率达到90%+。首页推荐CTR 提升了5 倍。货源订单转化率从11% 提升到16%。全国24 小时反馈率则从60% 提升到了64%-68%。特别在低反馈地区50 城实验,很多地区获得的提升更高达15%,30 分钟内反馈率提升15%,12000 条路线上的司机空驶率降低30%
第二个场景是智能调度。这里面有区域供需预测、价格、以及ETA 等场景。其中最重要的是价格预测。事实上供需预测也是价格的前置条件,而价格也是引导司机进行市场化调度的重要手段。不同于滴滴和uber 的将区域分割成六边形,货运领域的区域,无论时间还是空间,都更加宽阔,事实上我们在操作时是以区县、小时来作为单位的。特别是,货物都是非标品!这对价格的预测提出了更加困难的考验。
原则上我们更倾向于使用一些可解释模型,结合深度学习来进行应用。单纯的RNN 或者LSTM 模型在处理数据时,常常无法面对突发条件,比如个别地区道路封闭、雨雪天气等,往往会出现无法快速调整的情况。而人工干预和深度神经网络模型的结合,也常常造成模型退化。所以我们采用了一个较复杂的特征工程模型,同时极可能分离模型与规则部分。
我们的价格预测做法如下:
将价格因素分为两类:可变价格和不可变成本。将过路费和汽柴油费用和以车辆平均寿命的计提折旧作为线性成本。如果把线性成本认为是独立可叠加的,再配合上后面将要介绍的非线性成本,则价格公式有:
(1)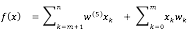
因为线性成本的独立可叠加性,可通过线性回归进行价格预测。鉴于我们掌握有充分的多年的全国公路干线运输信息,因此可以轻易调查到过路费、汽柴油费用和车辆平均寿命。
- 过路费 = (出发地 - 目的地高速公路里程 * 车型) * fix
- 如果是库内没有的出发地和目的地,则按照附近核心节点城市的里程 + 出发地到节点城市的里程计算。
- 汽柴油价格与之类似,但是要考虑到货物重量和车况。
- 非线性成本有:供需关系,天气,节假日,里程,系统热噪音等,经过离散化和归一化处理。
供需关系指的是运价与成交率的关系。根据不同地区和时间,会有多个局部波峰。为了达成最高的成交率,根据供需环境调整价格预测范围,我们采用了 Walras-Samuelson 过程为假设,来预测平衡价格。记做:
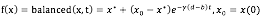
因此,加入供需关系后有:
(2)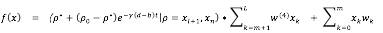
剩下的四个因素是:周期因素(每周,节假日,季节),系统热噪音,装卸费用,司机劳务费用。
各自的解决方法是:
- 周期因素分离:主成分分析 + 傅里叶变换
- 系统噪音:小波分析
- 装卸费用 / 司机劳务费用:基于时间序列的循环神经网络回归。
则有基于干线物流大数据的运价计算公式:
(3)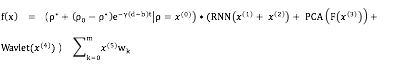
X(1)代表装卸费用的几个特征:装卸重量,当地的人均收入,当地出发地司机的平均运营里程,当地发货量,发货地址坐标等。
X(2)代表司机劳务费用的几个特征:地区在时间窗口的采用平均劳务费,当地出发、进入的车货供需量,货主信用等级,货主发货量等。
X(3)代表呈现周期性的特征:比如周二,周三,月初,月末,节日等,拆分成 1/0 的二值特征,以及价格相关的特征向量。
X(4)代表噪音较大的向量特征:地区发货量,司机历史成单,货主发货经纬度等。
X(5)代表距离,油价等线性特征。
该方法的特征抽取和计算方法架构为:
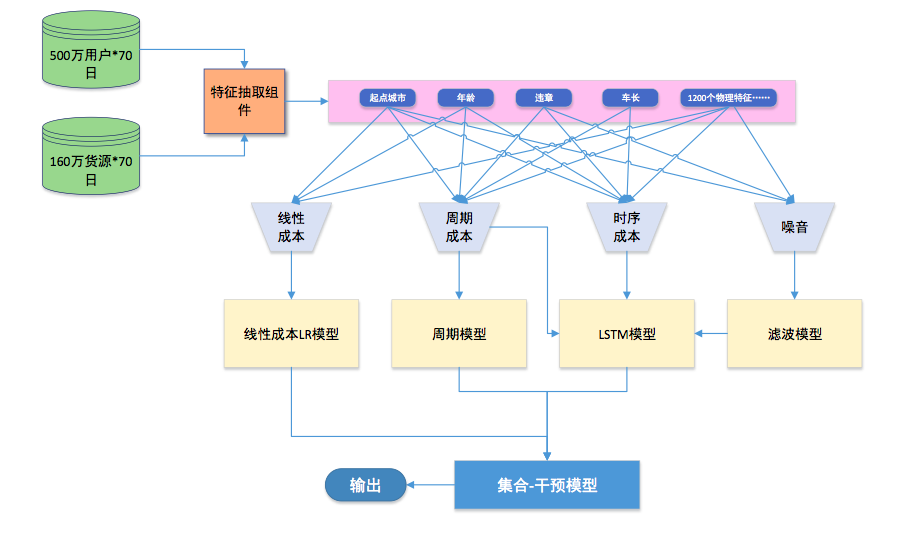
这个模型的坏处非常明显:需要做大量人工特征工程,而且很多数据流未经过主算法模型。对调整模型有较大的困难。
但是多方妥协的好处在于,可以直接干预模型中的线性成本和周期模型。由于价格是个混沌模型,我们实际预测出来的只是价值,需要通过 t+0 的前线数据采集和地面不断进行纠正和后验调整。而且,平台本身也在市场中不断和传统势力进行博弈,有时候,为了运营活动要进行妥协。这一切都造就了当前的模型形态——一切为了实战。
日前,我们最新的数据预测,在大部分地区,预测价格在经济人报价或见证报价上下的 10% 内算作准确的话,当前的模型,普货准确率 83.30%,重货 86.37%。以此为基础,我们在上海、南京等区域实现了热力供需 / 价格体系,能够直接对货主和司机施加影响,对我们自营车队,加盟商都提供了可以依赖的成本产出指导。至于价格,才能撬动供需关系,才能实现非自营 / 加盟车队的调度。以上海地区为例,我们调整下的市场行为,价格波动更小,而反馈率超过了 85%,高活货主加盟会员率远超其他地区,几乎达到 100%。上海等地区出发的路线成为可盈利的标杆路线。
小结
除了在车货匹配和报价领域,我们在风控、人脸识别、调度等各种场景下都做了许多大胆尝试。未来随着满帮平台在物流领域的不断深入,通过机器学习和深度神经网络技术来提升效率,降低成本,是非常有前景的话题。特别是自动驾驶技术的进场,我们希望能通过更有力的调度手段,来实现更美好的行业前景。
作者介绍
罗竞佳,满帮集团运满满公司大数据部负责人。算法和数据专家,自然语言和机器学习专家。先后在中科院计算所网络存储实验室、百度无线搜索等供职。在算法和推荐上参与及拥有“与查询序列相对应的搜索建议”,“搜索候选词的推荐方法”等多项专利。2013、2014 的百度世界大会上的“轻应用”、“直达号”等项目的检索策略架构师。16 年领导百度糯米 POI 策略组,在反作弊项目中侦测数千万异常流水,挽回巨大损失;17 年领导开发门店 POI 素材写作工具,实现基于 fasttext 和 LSTM 的门店机器写作,月均产出 5 万 + 图文内容和门店介绍文章,完成了内容闭环。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论