
编者按:“范式大学”由第四范式发起,致力于成为培养工程师转型为数据科学家的“黄埔军校”。专栏专注于以人工智能解决具体商业问题。在这里你将会看到,企业如何通过可实施的方法完成 AI 转型;个人如何通过最新的科技工具,快速成为能解决问题的机器学习工程师。
本文是大数据杂谈 7 月 27 日社群公开课分享整理,也是第四范式主题月的第四堂公开课内容。
大家好,我是第四范式的罗远飞。前不久,我参加了国内首个迁移学习算法比赛,非常幸运地获得了比赛的冠军。今天,我将以本次比赛为例,介绍我们基于大规模分布式机器学习框架 GDBT,在迁移学习上进行的一些尝试。我会首先介绍迁移学习的背景和 GDBT;然后结合比赛,阐述迁移学习的一些经典算法在实际应用中,可能需要注意的地方;最后,总结本次分享,并简要介绍比赛中一些未来得及尝试,却比较有趣的迁移学习工作。
第一部分:背景介绍
本部分首先介绍迁移学习的背景,其次介绍为何要开发大规模分布式的迁移学习算法,最后简要介绍第四范式大规模分布式机器学习框架 GDBT 的特性。
1.1 迁移学习要解决的问题和难点
简单来说,迁移学习是把一个领域(即源领域)的知识,迁移到另外一个领域(即目标领域),使得目标领域能够取得更好的学习效果。通常,源领域数据量充足,而目标领域数据量较小,迁移学习需要将在数据量充足的情况下学习到的知识,迁移到数据量小的新环境中。但是,如何形式化的描述所要迁移的知识,使用何种方法迁移知识,以及何时迁移是有效的、何时是有副作用的,是使用者所要关注的重点和难点,本次分享主要集中在前两个方面。至于如何保证迁移的有效性,目前并没有很好的理论来支持。
1.2 大规模分布式迁移学习算法的必要性
我们知道,近年来数据量的迅猛增长和计算能力的提升是推动这一波人工智能热潮的主要原因之一。但在实际业务中,我们会发现在很多情况下,数据量较小,不足以支撑 AI 去解决实际问题。而迁移学习能够通过发现大数据和小数据问题之间的关联,把知识从大数据中迁移到小数据问题中,从而打破人工智能对大数据的依赖。那么我们是否还需要大规模分布式机器学习平台呢?答案是肯定的。
因为即使目标领域数据量较小,我们也不能简单的将迁移学习视为小数据学习问题。一方面,源领域的数据量可能是巨大的,为了更好的学习到数据内在的结构等信息,需充分利用所有的数据;另一方面,迁移学习所涉及的领域可能有多个,当领域较多,即使每个领域的数据比较少,所有领域数据累计起来,数据量也可能是巨大的;再者,目标领域本身可能也需要较大的计算量,如一些基于深度学习的迁移学习场景。因此,我们在验证不同的迁移学习算法效果时,是基于第四范式的大规模分布式机器学习框架 GDBT,实现的多机分布式并行计算版本,而非单机。
1.3 GDBT 简介
GDBT(General Distributed Brilliant Technology)是一个为分布式大规模机器学习设计的计算框架,兼顾开发效率和运行效率,使算法工程师可以基于 GDBT 开发各种传统或者创新算法的分布式版本,而不用过多地关心分布式底层细节。它针对机器学习任务在计算、通讯、存储、灾备等方面做了深入的优化,定制了通信框架、算法框架以及参数服务器,为进行大规模机器学习训练提供了基石。GDBT 还有一个很大的特性是对算法开发者友好。它提供的是工业级的开发者易用性,从语言级别上,GDBT 整体基于 C++14 标准,为算法的开发提供了更大的自由;从功能抽象上,GDBT 提供了对参数服务器和算子的良好包装。在 GDBT 上,只需要数百行代码就可以实现像对数几率回归(LR)、矩阵分解(MF)等算法的分布式版本。
接下来,我们将结合赛题,重点介绍基于 GDBT,对一些经典的迁移学习算法进行的尝试与心得。需要说明的是,以下所提及的算法,均是我们基于 GDBT,自主研发,暂未使用开源工具。
第二部分:基于 GDBT 的迁移学习实战
2.1 赛题介绍
比赛主办方为平安旗下前海征信,是国内首个迁移学习赛题:给定 4 万条业务 A 数据及 4 千条业务 B 数据,建立业务 B 的信用评分模型。其中业务 A 为信用贷款, 其特征是债务人无需提供抵押品,仅凭自己的信誉就能取得贷款,并以借款人信用程度作为还款保证;贷款期限为 1-3 年,平均贷款金额为几千至几万的中等额度信用贷款业务。业务 B 为现金贷,即发薪日贷款,贷款期限为 7-30 天,平均贷款金额为一千的小额短期贷款业务。业务 A、B 对应的数据特征完全一致。由于业务 A、B 存在关联性,如何将业务 A 的知识迁移到业务 B,以此增强业务 B 的信用评分模型,是比赛的重点。比赛评测指标是模型在 B 的测试集合上的 AUC。(注:AUC 是业界较为常用的一个模型评测指标,AUC 越高表示模型预测性能越好。)
2.2 问题的限定与形式化
为和比赛保持一致,本次分享在描述相关算法时,仅考虑两个领域间的迁移学习,即将一个源领域(记为 Ds)中的知识,迁移到一个目标领域(记为 Dt)中。源领域和目标领域分别对应的学习任务记为 Ts 和 Tt。以比赛为例,业务 A 对应源领域 Ds 和学习任务 Ts,业务 B 对应目标领域 Dt 和学习任务 Tt。
2.3 解题思路
本次比赛的解题流程如下图所示:首先,我们对原始数据预处理并提取特征,然后运用迁移学习模型对问题建模,最后将不同的模型结果融合,得到最终的预测结果。因特征工程和业务强相关,不同的问题对应的特征提取方法可能相差很大,为了最大化本次解决方案的可扩展性,在参赛过程中,我们并未在特征工程上花费较多精力,仅是简单的将所有特征作为连续值特征处理和缺失值填充。
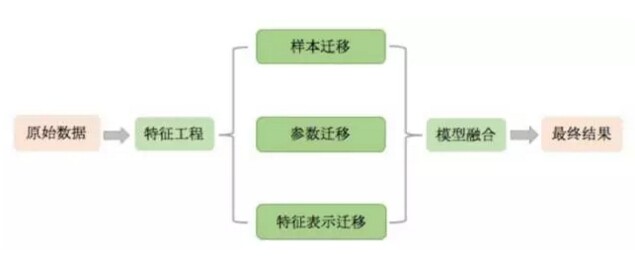
图 1 解题流程
根据 Sinno Jialin Pan 和 Qiang Yang 在 TKDE 2010 上的文章,可将迁移学习算法,根据所要迁移的知识表示形式(即 “what to transfer”),分为四大类:
1)基于样本的迁移学习(instance-transfer);
2)基于参数的迁移学习(parameter-transfer);
3)基于特征表示的迁移学习(feature-representation-transfer);
4)基于关系知识的迁移(relational-knowledge-transfer)。
其中,基于关系知识的迁移认为样本之间具有相关性,而非独立同分布,如知识图谱,主要应用统计关系学习的方法如马尔科夫逻辑网(markov logic network),不在我们本次分享的范围内。我们将结合比赛,重点阐述前三类方法。
2.3.1 基于样本的迁移学习
基于样本的迁移学习是通过从源领域中,选取对目标领域建模有用的样本,和目标领域的样本一起使用,来实现迁移学习的效果。在此我们分享两种方法:
1)通过提升(boosting)算法,对样本设置不同权重;
2)通过一定的过滤规则,只选取和目标领域相近的样本。
第一种方法的代表性工作为 TrAdaBoost,第二种方法是我们从 PU-Learning 中借鉴而来,记为 SPY。
“挑肥拣瘦”的 TrAdaBoost
TrAdaBoost 是戴文渊等人基于 AdaBoost 算法,在 ICML 2007 上提出的一种针对迁移学习的提升算法。它适用于源领域 Ds 和目标领域 Dt 均有标签信息,且特征空间和目标空间均一致,但 Ds 和 Dt 中样本分布不一致的情况。与 AdaBoost 相似,它需要首先选择一种基学习器(base learner),然后根据之前一些基学习器的表现,来训练当前的基学习器,并迭代的调整样本权重。和 AdaBoost 主要区别在于:
- TrAdaBoost 的输入是 Ds 和 Dt 对应的两个数据集,并从 Ds 中只选取对学习任务 Tt 最有用的知识;
- TrAdaBoost 在计算模型误差时,仅考虑在 Dt 上的误差;
- TrAdaBoost 在 Ds 和 Dt 中使用不同的样本调权方式;
- TrAdaBoost 仅使用学习到的所有基学习器中,后训练的半数基学习器来预测模型效果。
关于该算法的更多细节和理论可参阅对应论文。
在应用 TrAdaBoost 解决赛题时,我们发现:样本的初始权重设置和基分类器选取比较关键。初始权重设置是较强的先验信息,而且,如果初始权重设置不当,也会影响计算稳定性。我们可以通过不同领域的样本比例,或根据不同类别样本对应的比例,或综合考虑前二者来设置初始权重。另外,基分类器的选取也会影响迭代轮数、计算稳定性和模型最终效果。在本次比赛时,我们最后选取了梯度提升机(GBM)作为基学习器。和其他选手交流后,发现最优初始权重设置为:Ds 中初始权重均设为 1;Dt 中正样本权重设为 6,负样本权重设为 3。
“里应外合”的 SPY
SPY 是刘冰等人为解决 PU-learning 中只有正样本和无标签样本,而没有负样本问题,在 ICML 2002 上提出的一种从无标签样本中寻找最可能的负例,以便有监督学习的技术。在比赛过程中,我们借鉴其方法,用来从源领域 Ds 中筛选和目标领域 Dt 最相似的样本,然后将选出的样本和 Dt 中的样本放在一起训练模型。SPY 的算法流程为:
- 样本重标记:将 Ds 和 Dt 对应的数据重新标记,即 Ds 中的样本标记为负样本,Dt 中的样本标记为正样本;
- 数据集切分:将重新标记后的 Ds 和 Dt 放在一起,并随机切分为训练集、测试集;
- 分类器训练:选择一个可以输出概率预测结果的基分类器,并在训练集上训练该分类器;
- 概率预测:将训练好的模型在测试集上预测,输出测试集中每条样本属于正样本的概率;
- 样本筛选:将测试集中样本按概率降序排序,设置阈值 k,记不小于第 k 个正样本对应的概率为 p,选择 Ds 中概率不小于 p 的样本,放入 Dt 中。
从上述流程中可以看到,我们首先利用 Dt 和 Ds 中的样本训练一个“裁判”,对测试集中样本打分。然后,利用测试集合中属于 Dt 的样本作为“内应”,根据“裁判”的评判结果,选取出 Ds 中,比 Dt 的部分样本,更“像”Dt 的样本。
在应用 SPY 方法时,可能有两点需要注意:基分类器的选择和筛选阈值的设置。若基分类器太强,SPY 第一步训练出的分类模型效果很好,将不能从 Ds 中选择出足够数量的样本,因此我们选择了 LR 和 NB(朴素贝叶斯)作为基分类器,而非 GBM。另外,筛选阈值的设置需要根据实验结果调整,尽可能既不错杀,也不误放。若设置的过高,会使得和 Dt 差别较大的样本被选中,反之则会遗漏和 Dt 较相似的样本。另外,SPY 可以和交叉验证、集成学习相结合,提高选择出的样本置信度,或增加样本的选择数量。
TrAdaBoost 和 SPY 的结合可能也值得尝试。比如,用 TrAdaBoost 中源领域样本的权重作为 SPY 方法中基分类器的预测结果,然后直接选取权重较高的样本,和目标领域样本一起建模。
2.3.2 基于参数的迁移学习
基于参数的迁移学习是通过在不同领域间共享参数,来实现迁移学习的效果,代表性方法为多任务学习(multi-task learning)。
“一心二用”的多任务学习
多任务学习,即同时学习多个任务,使得不同的学习任务能相互促进。因多任务学习一般是通过共享特征来实现共享参数的功能,所以在实际应用中,需着重考虑两点:1)共享哪些特征,以确定共享模型对应的哪些参数;2)如何共享参数,即选用何种模型共享参数。
对于第一点,需要具体业务具体分析。在确定共同特征后,使用多任务学习相关算法前,需要先将不同领域样本对应的特征空间,重新编码,以便将所有问题映射到同一特征空间中。具体来说,可将源领域 Ds 和目标领域 Dt 对应的特征分为三部分:Fc、Fs 和 Ft,其中 Fc 表示 Ds 和 Dt 对应的共同特征集,Fs 和 Ft 分别表示仅在 Ds 和 Dt 中出现的特征。然后将 Ds 和 Dt 对应的样本,统一编码到 Fc、Fs 和 Ft 三者并集对应的特征空间中去。
对于第二点,我们实现了三种不同的模型,分别是神经网络(NN)、线性分形分类器(LFC)和梯度提升机(GBM)。下面以 NN 和 LFC 为例来说明多任务学习是如何“一心二用”的。
通过 NN 实现多任务学习的思路比较直观,如下图所示。图片上方是使用 NN,做单任务学习的示意图,不同任务间并无任何关联,即“一心一意”。图片下方是使用 NN,进行多任务学习的模型示意图,可以看到两个任务共享一些神经网络层及其相关联的模型参数,但输出层对应两个不同的任务,以此来实现多任务学习。
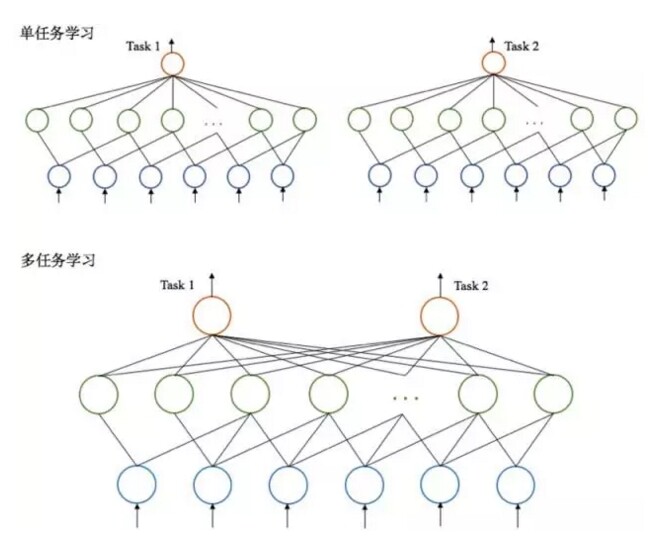
图 2 单任务学习 vs. 多任务学习
LFC 是我们基于 GDBT 开发的增强版 LR 算法,它能根据数据自动生成不同层次的特征,保证在细粒度特征无法命中的时候,层次化的上位更粗粒度特征可以生效。在多个实际业务中应用结果表明,LFC 的预测效果和计算稳定性上均显著优于 LR。LFC 在进行多任务学习时可看作是将模型参数 w 根据特征拆成三部分,即(wc,ws,wt),其中,wc、ws 和 wt 分别对应特征 Fc、Fs 和 Ft 对应的权重。模型训练阶段,在 Ds 对应的样本中,wt 对应的特征取值均为 0;在 Dt 对应的样本中,ws 对应的特征取值均为 0。两个领域通过共享 wc 来实现相互学习。
在实际应用多任务学习实现迁移学习效果时,Ds 和 Dt 对应的数据量可能差别很大,在模型迭代训练时,可以调整不同领域对应的迭代轮数,或对数据进行采样,或通过定义代价敏感的损失函数(cost-sensitive loss function)来调节。另外,多任务学习的目的是提升各个学习任务的效果,但迁移学习仅关注目标领域 Dt 的学习效果,我们可通过修改多任务学习的损失函数,如给予 Dt 更高的权重,来重点学习 Dt 对应的学习任务 Tt。
除了上述 LFC 和 NN 外,也可考虑使用 AdaBoost/GBM 等作为多任务学习的基分类器,具体可查阅相关文献。
2.3.3 基于特征表示的迁移学习
基于特征表示的迁移学习是利用源领域 Ds(和目标领域 Dt)的信息,寻找合适的特征表示空间,作为所要迁移知识的载体,来增强目标领域的学习效果。因此,该类方法的关键在于如何找到合适的特征表示空间。
“筑巢引凤”的特征表示学习
“筑巢”的方法可大致分为无监督和有监督两类。其中,无监督是指只利用数据中的属性信息,而不使用标签信息。它一般是通过最小化重构误差来学习特征的表示空间,如下图所示的自编码器(autoencoder)所示,通过最小化输入和输出之间的误差,来训练该神经网络,最后使用隐藏层及其相关联的参数来代表所要学习的特征表示。除自编码器外,还有流形学习(manifold learning)、稀疏编码(sparse coding)等方法。
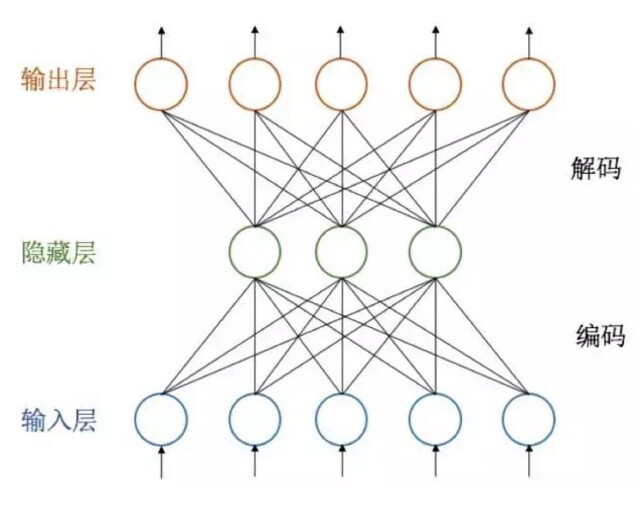
图 3 自编码器示意图
和无监督不同的是,有监督的方法同时利用数据中的属性信息和标签信息。一个最直观的方法是借鉴深度学习中的微调(fine-tuning)方法,即先用 Ds 中的样本训练一个基础模型,然后利用 Dt 中的样本,微调此基础模型。当基础模型是 GBM 时,该方法是先在 Ds 中训练一定数量的树模型,在此基础上,利用 Dt 的样本训练更多树模型。当基础模型是 NN 时,做法比较灵活,可以只使用基础神经网络模型的部分模型参数和结构,余下部分根据 Dt 的特点设计网络结构并随机初始化;也可以不做任何改变,直接微调 NN 的权重。
在实际应用过程中,可以从算法角度,融合各类算法,以取得更好的效果。比如,结合基于样本的迁移学习和基于参数的迁移学习,我们可以利用基于样本的迁移学习算法对源领域数据进行下采样,然后再利用基于参数的迁移学习。
第三部分:总结与展望
今天和大家分享的是我们基于大规模分布式机器学习平台 GDBT,在迁移学习算法上做的一些尝试,包括算法原理和实践时的一些技巧。至于如何度量可迁移性是迁移学习的基本问题之一,目前尚无定论,研究进展也较为缓慢,加之本人才疏学浅,这次分享并未涉及该点。另外,迁移学习能够打破数据孤岛,利用多个企业和用户的数据共同建立更好的模型,但在此过程中如何确保数据的隐私尚无完善的解决方案。最后,深度迁移学习目前研究活跃,我们公司首席科学家杨强老师在 CCAI 2017 大会上有相关的主题报告,感兴趣的可以去学习。
很荣幸能有机会和大家分享,我们在迁移学习实践上做的若干初步的尝试,谢谢大家。以上只是我个人关于迁移学习应用时的一些浅见,错谬之处在所难免,望不吝指点。
答疑环节
Q1:LFC 是怎么根据数据自动生成不同层次的特征呢?怎么判断生成的特征的有效性的?
罗远飞:LFC 是借鉴了多分辨率分析(multiresolution analysis)的思想,通过对输入的连续值特征进行多尺度的变换,生成不同层次的特征。在得到不同层次的特征后,我们让模型自适应的选择出泛化性能好的特征,而非手工筛选。
Q2:分布式计算框架 GDBT 和 Spark 有什么区别,或者有什么优势?
罗远飞:目前比较流行的计算框架比如 Hadoop、Spark 其重点任务大多是 ETL 类的任务。机器学习计算任务相比于传统的 ETL 计算任务有很多自身的特点,比如在计算方面,ETL 会做的一些相对“简单”的运算,机器学习算法会对数据做相对复杂的运算,在存储方面,ETL 需要处理来源不同的各种数据,比较少的反复迭代运算,很多机器学习算法会对数据做反复的迭代运算,可能会有大量的不断擦写的中间数据产生。GDBT 是一个专门为分布式大规模机器学习设计的计算框架,针对机器学习任务在计算、通讯、存储、灾备等方面做了深入的优化,使算法工程师可以基于 GDBT 开发各种传统或者创新算法的分布式版本,而不用过多地关心分布式底层细节。
Q3:GDBT 上实验迁移学习算法,和单机的区别?
罗远飞:由于 GDBT 良好的设计和抽象,算法工程师在实现分布式机器学习算法时,重点关注数据的核心变换和计算逻辑即可,而不用过多地关心分布式底层细节。比如,在需要进程间通信或与参数服务器交互时,直接调用相应接口就可以想要的功能。
Q4:为什么将基于特征表示的迁移学习称为“筑巢引凤”?
罗远飞:在此我们将所要学习的特征表示空间形容为“凤巢”,在目标领域更好的模型效果比喻为“凤凰”。该类方法一般是在源领域学习到一个特征表示空间,即“筑巢”;然后将目标领域的数据放入该空间中,建模得到较好的模型效果,即“引凤”。
Q5:多源迁移学习如何找使得多个源域分布一致的多个域之间的共同特征空间呢?
罗远飞:有两种直观的方法,一种是直接根据业务含义,确定哪些特征是可以在不同域之间共享的;另一种方法是直接通过上面分享的基于特征表示的迁移学习,找到一个或多个空间,使得不同域在所学习到的空间上的“差异”尽可能小。
Q6:比赛时,是如何做模型融合的?
罗远飞:我们比赛时仅使用了两种简单加权平均的方法,一种是预测结果直接加权平均,一种是按秩加权平均。预测结果直接加权平均时,需要注意的是如果不同模型预测的结果分布不太一致,如 A 模型预测结果区间一般是 [0, 0.4],而 B 模型的大多在 [0.6, 1],则需要先对 A、B 的预测结果做概率较正(probability calibration)。按秩加权是指将预测结果在预测样本集合中的序,加权平均。它的好处是不需要概率较正,但不能直接应用于线上实时预估场景中。当然,模型融合(Stacking/Ensembling)有更 fancy 的用法,比如和交叉验证结合,训练多层的融合模型。
Q7:多任务学习时,是如何对样本重新编码到一个新的共同空间中去的?
罗远飞:假设我们有两个业务 A 和 B 的数据,特征均为 100 维。在多任务学习时,如果我们认为 A 和 B 有 50 维共同特征,则重新编码后,空间大小为 100+100-50=150 维,其中,第 1-50 维对应共同特征,第 51-100 维对应只在 A 中的特征,第 101-150 维对应只在 B 中的特征。
Q8:如果找到了不同域共享的特征,但是因为是不同域数据分布还是不一致,这能一起合并做分类吗?第二个上面说的只是针对两个域的找空间,如果是多个领域的空间,怎么找,或者有没有相关文献啊?
罗远飞:对于第一点,将不同域的样本重新编码到同一个空间中后,是可以合并在一起训练模型的,有兴趣请参考论文《Regularized Multi–Task Learning》,论文中有理论上的证明。对于第二点多个领域的迁移学习,可以参考我们公司首席科学家杨强老师的一些工作,如《Transitive Transfer Learning》。
作者介绍
罗远飞,第四范式机器学习工程师,从事算法调研与开发工作,已申请多项机器学习相关专利。硕士毕业于中国科学院信息工程研究所,研究方向为知识图谱、自然语言处理与机器学习,曾在自然语言处理国际顶级会议 ACL、EMNLP 上发表论文。
公众号推荐:
AGI 概念引发热议。那么 AGI 究竟是什么?技术架构来看又包括哪些?AI Agent 如何助力人工智能走向 AGI 时代?现阶段营销、金融、教育、零售、企服等行业场景下,AGI应用程度如何?有哪些典型应用案例了吗?以上问题的回答尽在《中国AGI市场发展研究报告 2024》,欢迎大家扫码关注「AI前线」公众号,回复「AGI」领取。


分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论