
虽然已经红了很久,但是“微服务架构”正变得越来越重要,也将继续火下去。各个公司与技术人员都在分享微服务架构的相关知识与实践经验,但我们发现,目前网上的这些相关文章中,要么上来就是很有借鉴意义的干货,要么就是以高端的专业术语来讲述何为微服务架构。就是没有一个做到成熟地将技术传播出来,同时完美地照顾“初入微服务领域人员”,从 0 开始,采用通俗易懂的语言去讲解微服务架构的系列。所以,我们邀请青柳云的苏槐与 InfoQ 一起共建微服务架构专题“Re:从 0 开始的微服务架构”,为还没有入门该领域的技术人员开路,也帮助微服务架构老手温故知新。
这是专题的第五篇文章,看如何用 Docker 支撑微服务。
专题文章传送
非常巧合,2013 年 3 月 Docker 发布 0.1 版本,时隔一年(2014 年 3 月)Martin Fowler 给出了微服务架构的定义。经过几年的发展,两个毫不相干的技术最终走到了一起:使用 Docker 来支撑微服务架构的开发和运维。
我们甚至可以说,没有 Docker 的蓬勃发展,就没有微服务架构的落地与开花。SoundCloud 的 Phil Calcado 最近却在 Twitter 上说了这样的话:
“Microservices came to be because of containers” is a myth. We were already doing microservices on fvcking Weblogic。
起初,我也很好奇他为什么这么说,后来才发现他说的是”fvcking Weblogic”,并且早在 15 年接受 InfoQ 采访的时候,他已坦诚有更好的方法来实现微服务架构的构建流水线:“那是我第一次意识到我们搞砸了,原来有简单渐进的方式能够解决研发环境快速构建、基本的监控以及应用快速部署的问题,而且完全没必要构建自己的系统”。详情见:
http://www.infoq.com/cn/news/2015/03/soundcloud-microservices
各位怎么看?
不谈这个。在前几篇文章中,我们已经聊到微服务架构的优势、劣势,什么时候该选择微服务架构,使用哪些技术和组件来开发微服务,微服务 API 如何治理等等。
同时,前面也提到使用基于 Docker 的微服务平台来支撑微服务的自动化开发和运维,但是并没有深入。那么,这篇文章就来详细聊聊怎么使用 Docker 来提高微服务的开发效率和运维效率。
这篇文章的阅读对象是希望借助 Docker 实施轻量级微服务架构却不知道如何下手的朋友,所以,我还是延续前文的风格,尽量以浅显的语言来从以下几个方面进行介绍。
- Docker 核心概念
介绍 Docker 的镜像、容器以及镜像仓库概念。
- 为什么使用 Docker 实施微服务架构
介绍使用 Docker 实施微服务架构的优势。
- 必须了解的 Docker 知识
介绍镜像构建、容器创建、容器编排、集群管理、文件存储、容器网络、容器监控、容器日志。
- 快速运行一个微服务架构 Demo
包含注册中心(Eureka)、调用链(DCTrace)、Service A、Service B、网关(Zuul)和 Demo 门户
Docker 核心概念
镜像(Image)
我们可以认为:镜像 = 操作系统 + 运行环境 + 应用程序。譬如,我们可以将 Centos7 操作系统、JVM 和 Java 应用程序做成一个镜像。我们交付的软件不再是 zip 包或者 war 包,而是镜像。Docker 镜像技术实现了应用程序运行环境与主机环境的无关性。
容器(Container)
容器是镜像的运行态。通过 docker run 命令即可快速的基于镜像创建一个或多个容器。
镜像仓库(Registry)
在项目或者产品的不断迭代过程中,应用的各版本镜像存储在镜像仓库中,类似于代码仓库 for source code 或 Maven 仓库 for Jar file。
为什么使用 docker 实施微服务架构

在前文介绍如何快速搭建一个微服务架构时提到,我们需要使用自动化的构建和监控工具来解决微服务架构运维难的问题。之前由于篇幅问题,并没有把微服务的运维问题展开来谈。所以,这里我们就来详细看看 Docker 为微服务开发和运维带来了什么样的好处。
环境依赖隔离
我们经常会碰到一种现象,“应用在我的机器上跑的好好的,部署到生产环境就有出问题了”。Docker 隔离了应用对环境的要求,它将应用依赖的底层库或者组件制作成镜像,从而保证了开发、测试、生产环境的一致性。
计算资源隔离
Docker 之前,在同一台机器上部署多个同构甚至异构应用是非常困难的,不同的应用依赖的底层库有可能冲突,不同应用之间可能会抢占 CPU 和内存等计算资源。Docker 利用 Linux 的名称空间 (Namesaces)、控制组 (Contorl groups)、Union 文件系统和容器格式 (Container format) 实现了资源(例如 CPU、内存、IO 等)的隔离,保证同一台主机上的多个应用不会互相抢占资源。
更高的计算资源利用率
在微服务架构下,系统从单体程序拆成了多个独立部署的程序,每个程序处于独立的 Web 容器中,必然增加了对计算资源的需求。Docker 可以帮助抵消这个弊端。
基于资源隔离的特性,我们就可以在主机上部署多个应用,把主机的每个角落的计算资源都利用起来。所以,使用 Docker 后,我们可以提高 5~10 倍的计算资源利用率。
例如原来我们将应用部署在一个 4 核 8G 的主机上,而这个应用真实需要的内存只有 1GB,我们就可以在这台主机上部署 7 个类似的应用(还有 1GB 留给操作系统)。对我们公司来说,这种利用率的提高在开发测试环境上尤为明显。
迁移方便
Docker 之前,一个版本发布时,交付物是一个程序包加一份环境配置的文档。现在,交付物是一个 Docker 镜像,这个镜像里,已经包含了最新版本的程序包和修改过的运行环境。真正上线时,一条命令就可以把最新版本的程序发布起来。这对于需要半夜上线的同学是绝对的救星。
版本管理更便捷
之前,对于版本的管理,更多考虑的源代码级的,比如开个 Branch 或打个 Tag。现在,版本是一个包含了运行环境和程序包的镜像。在上线失败的时候,可以很快回滚到之前的版本。
编排的支持
微服务架构下,一个系统包含多个程序包,而多个程序包之间是有依赖关系的。Docker 编排工具可以帮助管理这些依赖关系,从而达到一键创建整个系统的目的。
运维更快速
Docker 除了能够方便地管理应用系统,还能够方便地管理 DB、Redis、MQ 这些中间件。除了能够快速地创建和启停这些中间件,我们可以基于系统的需求把对这些中间件的优化配置一起做到镜像里。中间件研发人员交会的成果不再是一个基础安装文件加一堆配置说明,而是一个标准化的镜像。
环境可重建
以前,运行环境是由基础环境加一堆配置文档组成的,如果管理稍有不慎,文档和真实环境就会不一致。在 Docker 中,使用 Dockerfile 来创建运行环境,每一个对环境的修改都是一条 Dockerfile 命令,所以,运行环境的创建也变得程序化和标准化。从而能够快速地重建所需要的运行环境,进一步保证开发、测试、生产环境的一致性。
就目前来看,Docker 能够支持除.net 以外的几乎所有开发语言。对于.net core,2016 年 6 月发布 1.0 版本,2017 年 8 月发布 2.0 版本,应该说微软还是在这上面花了不少力气。只是,还没有听到身边的朋友有谁把.net 项目迁到.net core 上面去。也许还需时日来观察和沉淀,我们也做了一个基于.net core 的 demo 放到了青柳云镜像里,持续关注。如果哪位朋友有在生产上使用了.net core,请不吝赐教。
必须了解的 Docker 知识
Docker 的理念为“Build, Ship and Run Any App, Anywhere”,通过容器和镜像的特性让 DevOps 变得容易,但 Docker 的前景,更在于支持分布式、服务化设计,实现一系列可独立开发、独立部署和独立扩展的服务组合,以保证业务的灵活性和稳定性。
当前 AWS、微软、阿里云、IBM、Redhat、VMware、华为、Intel 等各大公有云和私有云提供商都不约而同地大力投资 Docker,实际上就是认可了这样的趋势。
利用 Docker 搭建微服务架构,就需要了解一些必需的 Docker 知识,比如镜像构建、容器创建、容器编排、集群管理、文件存储、容器网络、容器监控、容器日志。
拿一个包含 ABC 组件的微服务系统为例,我们会利用持续集成工具(例如 Jenkins)创建镜像,并将镜像推送到镜像仓库中(例如 Docker Registry,Harbor),再利用编排工具(例如 Docker Compose)创建并启动容器。
容器启动后,ABC 组件就会随着容器一起启动,这时就需要考虑 ABC 组件的数据文件如何持久化存储,分布在不同主机上的组件如何网络通信(Docker 容器默认不能跨主机通信),容器资源使用情况如何监控,容器日志如何查看,等等。
下面,就来简要介绍一下这些知识。
镜像构建
最简单的方法,一条命令就可以从镜像仓库(Docker registry,类似于代码仓库或 Maven 仓库)里拉取指定版本的镜像到本地。例如 docker pull mysql:5.6,5.6 就是镜像的版本号。
除了从镜像仓库里拉到现成的镜像,还可以使用 Dockerfile 来创建自定义的镜像。


由于国内访问直接访问 Docker hub 网速比较慢,拉取镜像的时间就会比较长。我们可以从一些国内的镜像仓库上拉取,或者配置阿里的镜像加速来拉取,或者自已搭建一个镜像中心。
- 网易镜像中心: https://c.163.com/hub#/m/home/
- 阿里开发者中心: https://dev.aliyun.com/
- 自建镜像中心: Docker registry 或 Harbor
另外,对于镜像,还有一个需要了解的概念就是层。对于一个镜像来说,是分为很多层的,每一条 Dockerfile 命令都会创建一个新的层,但是如果这条命令产生的结果和之前执行过的 Dockerfile 命令产生的结果相同,Docker 就会复用之前已经创建的层。
例如,Dockerfile 里有三个步骤:拉取 CentOS,安装 Tomcat,上传程序包。那么,在创建新的程序包时,由于 CentOS 和 Tomcat 没有变化,所以本次镜像创建只会为“上传程序包”这一步骤创建新层。
这也就为什么第二次执行 Dockerfile 会比之前的执行快很多的原因。所以,我们就需要尽量把引起镜像层变化的步骤放到 Dockerfile 的后半部分。
容器创建
如果把镜像类比成 Java 的类,容器就是基于类(镜像)创建出来的对象。镜像创建好了,一条命令就可以基于镜像创建多个容器实例:
docker run -d --name=helloworld helloworld:2.0### 容器编排
微服务架构下,一个系统有 N 多的组件,用户中心、配置中心、注册中心、业务组件、数据库、缓存服务等等等。我们如果希望一键创建和启动这些组件,就需要容器编排工具,例如 Google 的 Kubernetes,Docker 原生的 Docker Compose。两者相比,Kubernetes 提供了更多的高级功能,而 Docker Compose 相对来说更易于使用。
下面以代码示例来使用 Docker Compose 创建 Spring Cloud Eureka 和 MySQL。后面的 Demo 中还会再次讲到。

集群管理
多数情况下,出于性能和高可用的考虑,都需要将系统部署于多台主机上(多个 Docker),那么手工地选择主机并在主机上一个个地创建容器是不现实的。
Kubernetes 和 Docker Swarm 都很好地解决了这个问题。Kubernetes 的功能更完善,资源调度、服务发现、运行监控、扩容缩容、负载均衡、灰度升级、失败冗余、容灾恢复、DevOps 等样样精通,可实现大规模、分布式、高可用的 Docker 集群。而 Swarm 的优势则是 Docker 原厂打造,并且暴露的 API 与 Docker API 一致,使用起来更简便、可控。
文件存储
要将应用或数据库放在容器里运行,并且有效利用容器的快速创建、快速销毁、快速扩展运行实例的优势,一个前提条件就是要保证容器的 无状态性,也就意味着要将应用程序或数据库产生的数据文件放到容器外面。Docker 提供了四种方法持久化应用数据。
- 挂载宿主机文件
在创建容器的时候,可以添加“-v” 参数来添加挂载目录。譬如,运行 MySQL 镜像时,我们需要将 MySQL 中的数据目录挂在到物理磁盘上,执行命令
docker run --name=mysql -d -p3306:3306 -v /data/mysql/data:/var/lib/mysql mysql:5.6此命令将容器中 MySQL 数据目录“/var/lib/mysql”挂在到宿主机“/data/mysql/data”目录上。
注意:使用“-v”参数一定要牢记,宿主机挂载目录中的文件会覆盖容器中同名文件。如果不需要分布式存储,建议使用这种简单方式实现数据持久化。
- 添加数据卷
这种数据持久化方式也是通过“-v”参数实现数据挂在到物理机器上。与第一种唯一不同的是,不需要指定宿主机挂载的目录。
譬如,运行 MySQL 镜像,执行命令
docker run --name=mysql -d -p3306:3306 -v /var/lib/data mysql:5.6无需指定宿主机目录。我们可以使用“docker inspect ContainerName" 查看挂载目录在物理机器的实际位置。
注意:卸载容器后,数据卷不会自动删除。这种数据持久化方式,一般不太建议使用。
- 使用数据卷容器
如果多个容器之间需要共享数据,譬如,容器 A 需要使用容器 B 的数据。docker 还提供了容器数据卷方式。首先,我们需要创建数据卷容器 B:
docker run --name=containerB -v /dbstore training/postgres然后,在创建容器 A 时,使用 --volumes-from 参数挂载数据卷容器 B:
docker run --name=containerA --volumes-from containerB training/postgres这样,在容器 A 中就可以访问 /dbstore 数据目录了。这种数据持久化方式,我们一般也很少使用。
- 第三方存储插件
Docker 支持第三方存储方式以插件形式接入 Docker。采用这个方式,存储不依赖宿主机。Docker 支持非常多的存储插件,譬如:Contiv、Convoy、Netshare、Azure 等等。
- Contiv:目前支持分布式存储 Ceph 与 NFS 文件系统。
- Convoy:支持 devicemapper、nfs 文件系统。
- Netshare:支持 NFS 3/4,AWS EFS 和 CIFS 文件系统。
- Azure File Storae plugin:支持微软 Azure 文件系统。
微服务应用中,应用之间需要跨多主机共享文件,建议使用第三方存储插件方式扩展存储。
简而言之,最简单的方法就是将本地目录挂载到容器中,并将本地目录映射到文件存储服务器,从而实现多容器实例共享相同的文件数据。
容器网络
容器网络可以算是 Docker 中最复杂的部分了,Docker 内置了 none、bridge、host 三种方式的网络驱动。
- none:创建容器时,如果指定网络为 none,那么此容器内将没有网络。我们使用第三方网络插件时,创建容器时选择为 none 类型网络驱动。
- bridge:创建容器时,如果不指定网络驱动,Docker 默认采用此方式。
- host:如果容器使用 host 类型网络,容器与宿主机处在同一网络空间(Network Namespace)中,这种方式,数据包无需转换,其网络性能基本等同于物理机网络的性能。
上面介绍的几种网络,只是针对单主机而言。下面介绍两种 跨多主机通讯 的 SDN 网络。
- Calico
Calico 是纯三层实现的网络通讯技术。主要利用 Linux 路由表和 iptables 实现网络转发与隔离。Calico 相比于其他网络技术,其性能更接近物理网络。但是,Calico 对物理网络是有入侵的。
要实现三层网络,首要实现路由发现。Calico 通过 BGP 协议实现路由发现。但是,不是所有的路由设备都支持 BGP 协议。国内,阿里云 ECS 多实例之间也不支持 BGP 路由发现。在云服务环境中,如果不支持 BGP 协议,Calico 提供了隧道模式,但是,其性能远不如前者。
- Overlay
Overlay 容器间跨主机通讯原理:Overlay 是将容器发送数据包封装到三层网络中,通过 UDP 发送到其他宿主上(譬如,M),宿主机 M 收到此数据包后交由 VTMP 拆包并转发到对应的容器中。因为需要做装包与拆包,所以其性能不如 Calico 网络。
Overlay 网络下的容器与外部网络通讯,还是走桥接网络,但是这个网络不是 docker0,而是 docker_gwbridge。相比 Calico 网络,Overlay 性能比较差。
但是,由于 docker1.9 版本已经将 Overlay 网络做了跨主机通讯网络,在后续升级、维护方面比较具有优势(强大与火热的 Docker 社区支持)。
在微服务实施中,如果容器间不需要跨主机通讯的,建议使用 bridge 与 host 网络。如果需要跨主机通讯的,网络性能要求比较高,建议使用 Calico 网络;网络性能无特殊要求,建议使用 Overlay 网络。
容器监控
为容器分配了 CPU、内存等计算资源后,自然需要时刻监控容器的资源使用情况,这当然也可以借助开源工具来完成,例如 Google 的 Cadvisor 和 Prometheus。
我们没有对 Prometheus 做过研究,有兴趣的朋友可以去试试看。对于 Cadvisor,虽然它提供了图形化界面来查看资源使用情况,但没有提供告警功能。
所以,我们使用 Cadvisor + InfluxDB + Grafana 来查看容器使用情况,并将 InfluxDB 数据源接入到自研的监控平台中,实现告警功能。
容器日志
Docker 容器日志来源于容器的标准输出流(stdout)与标准错误流(stderr)。在微服务开发中,使用 log4j、slf4j、logback 等日志组件时,默认都会将日志输出到文件和标准输出流中。
通过 Docker 容器方式部署后,对于重要的日志文件,在创建容器时,通过“-v” 参数将日志文件挂在到宿主机磁盘上永久保存。如果将日志输入到标准输出流,我们可以通过“docker logs”命令查看日志。
注意:如果通过 docker logs 查看的日志量很大时(超过 1GB),将会使 Docker 出现假死现象。所以,在使用 docker log 命令时,我们建议加上 --tail 参数,指定查看最后多少行日志信息。
过多的日志将会占用大量的磁盘空间,在创建容器时,可以通过参数“–log-driver”与“–log-opt”指定容器产生的日志文件数已经文件大小。譬如
docker run --name=mysql -d ---log-drive=json-file --log-opt=max-size=100m;max-file=1 mysql:5.6至此,我们简要介绍了使用 Docker 支撑微服务架构开发需要用到的功能和注意的事项。下面,我们就用一个 Demo 来完成一个实例的演练。
快速运行一个微服务架构 Demo
在开始之前,可以通过地址 http://msa.qingliuyun.com/ 来查看 Demo 的效果。
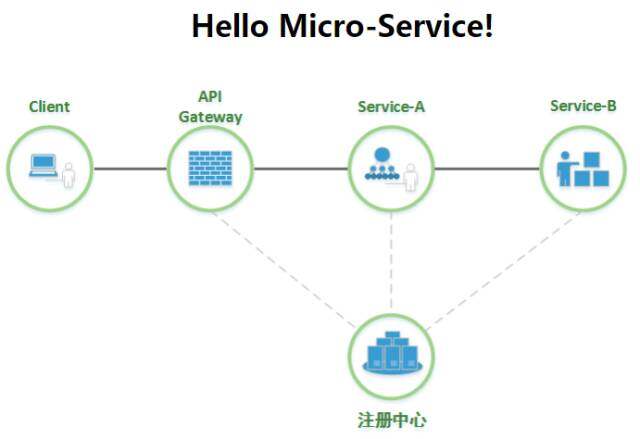
请求处理流程:
1 . 内部服务 A 和 B 启动后,将自身服务地址注册到注册中心(Eureka)。
2 . API 网关从注册中心拉取服务 A 和 B 的服务地址。
3 . 客户端(Client)调用 API 网关(API Gateway)。
4 . API 网关将调用请求转发给内部服务 A(Service A)。
5 . 内部服务 A 接受到请求后,将请求转发给服务 B(Service B)处理。
6 . 内部服务 B 返回处理结果。内部服务 B 将请求结果返回给客户端。
考虑到本篇文章的篇幅问题,我们将 Demo 源代码上传到了
https://github.com/qingliuyun/msa-demo
有兴趣的同学可以去看看,非常简单。
同时,也准备了一篇文档来介绍 Demo 的两种安装方法:
- 基于 Docker + Docker Comopose;
- 基于青柳云微服务平台;
链接地址:
http://docs.qingliuyun.com/pro/images/quick_start/kuai-su-da-jian-wei-fu-wu-jia-gou-zu-jian.html
文档中包含了安装过程中需要的数据库初始化脚本和 Docker Compose 脚本文件。
写在最后
至此,我们就完整地介绍了微服务架构的概念、优势劣势、使用场景、基于 Spring Cloud 的微服务开发和 API 治理,以及如何使用 Docker 来支撑微服务的开发和运维。
虽然不能详细地介绍每个知识点,但还是希望这个系列能帮助大家对微服务架构有一个比较全面的认识。也感谢大家在文章发表过程中提出的各种问题、建议和指正,衷心希望微服务架构能让大家的系统运行得更好。
最后,特别感谢田光同学在文章编写过程中给出的各种建议,祝愿 InfoQ 越办越好。
作者介绍
苏槐,微信号 Sulaohuai,青柳云研发总监,现服务于神州数码青柳云团队,曾就职于 Oracle,新加坡电信等企业。擅长容器技术、微服务架构、敏捷开发及技术管理。
下篇文章
没有下篇文章咯,这个系列到这里就结束了,感谢各位读者的关注,也感谢苏槐老师和中途出场的小羊老师的分享!
感谢雨多田光对本文的策划和审校。
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论