在 3 月 26 号由百度开发者中心、百度地图开放平台和百度车联网联合举办的第 62 期《基于地图开放技术的车联网实践》百度沙龙上,来自百度开放平台 LBS 云方向的技术负责人张鑫,分享了题为《基于 LBS 云的海量位置数据存储和检索实现》的演讲,介绍了 LBS 云平台的整体架构,以及在整个发展过程中的优化历程。
演讲者简介:
张鑫是百度高级研发工程师,目前是百度开放平台 LBS 云方向的技术负责人,主要负责 LBS 云存储和云检索的架构优化和 RGC(逆地理编码)的系统架构优化产品布局,主导了百度 RGC 效果性能优化项目,项目获得百度创新奖。重新设计优化了云存储基础检索集,摘要检索的架构。
主要分享内容为七部分:
- 目前 LBS 云系统所支撑的业务场景
- LBS 云架构的优化演进
- LBS 云系统的特点
- LBS 云系统架构
- LBS 云索引结构演进
- 存储演进
- 存储控制优化
LBS 云所支撑的业务场景
百度地图开放平台主要是为地图开发者提供一系列的系统解决方案。目前这些解决方案主要是涵盖六个方面:定位、地图、数据、出行、轨迹和分析。每一个解决方案都有一系列的服务 SDK 和 API,并打包成一个完整的产品来对外提供。开发者也可以根据自己的需求使用集中的服务或者 SDK 进行开发。在数据处理方面的服务主要还是 POI 检索,Place 检索是对百度地图使用的 POI 检索服务做了一层封装。
LBS 云主要是让开发者上传个性化数据,并支持对这些数据的存储及检索。GC 是地理编码引擎,接收一个文本的地址串后解析成百度地址库中对应的地址。还有经纬度信息,RGC 和 GC 恰恰相反,当 RGC 接收到一个 XYZ 经纬度坐标之后就会把这个经纬度坐标转换成一个语义上可以解读地址,也就是一个文本串,或者是一个结构化的地址。
目前 LBS 云所支撑的业务场景可以通过三个相对典型的案例来详述:
- 首先是物流行业。包裹分发到一个网点,不再需要相应的作业人员看包裹上的地址来进行分发,而是把业务员负责的片区数据存储到云平台上,这个包裹的地址用 LBS 云的 GC 转换到一个 XY 坐标,通过检索系统确定这个坐标所对应的服务片区。
- 其次是酒店。通过百度地图酒店数据来定位选择合适的酒店,这些数据目前就存储在 LBS 云平台上,对酒店周边服务进行检索都是通过 LBS 云平台实现的。
- 最后是交友。找附近的人估计是很多社交类开发者比较共性的诉求,LBS 云平台系统支撑开发者把这样的数据信息上传到云存储,实现查找附近人的功能。
LBS 云系统的特点
这里可以介绍一下百度 LBS 云系统比较突出的 6 个特点:
- 高可用性- LBS 云系统存储的可用性可以达到 4 个 9,检索可用性在 5 个 9 以下,可用性的标准是根据系统从收到一个请求到给出应答这一过程的耗时不超过两秒,这是可用性的保准。
- 容量大- LBS 云系统存储现在为每个开发者都提供了大概是千万级别的存储,空间可以达到数百 G,而且容量还可以根据需求来申请扩大。
- 灵活性强-系统可以存储各种各样的 POI 数据,可以根据用户想要上传的字段来灵活安排,这些字段是否参与检索、是否参与排序都可以自定义的。关键是这些字段的属性也是可以修改的,所以灵活性非常强。
- 实时-开发者将数据上传到 LBS 云平台,其存储发布到检索是在秒级之间,能够达到及时更新。
- 高效的空间索引-从前面分享的场景里可以看出,LBS 云系统所支撑的开发者大部分在做周边检索,空间索引算法采取的是 GeoHash 算法,耗时不到 7 个毫秒,非常高效。
- 数据安全-最后一点大家都比较关注,放到 LBS 云平台上的数据安全吗?从两个纬度来讲:第一,用户之间的数据是互相隔离的,每个用户都有自己的 AK,你在注册成为我们开发者的时候有自己的 AK,一个用户的数据只能被该用户使用。第二:开发者上传的数据有多个副本存储在平台上,不会出现数据丢失的问题。
LBS 云系统架构
既然这个系统有如此多的特点,那么它的架构又是怎么样的,如何支撑这些特点?
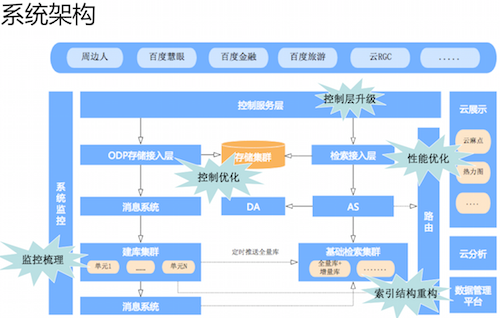
(上图)左边部分是系统监控,LBS 云系统里的每一个子模块、子服务都有精密严格的系统监控,这个监控包含了对机器资源本身的监控,CPU、磁盘都有监控。另外对 QPS、耗时、SLA 的监控都是非常完备的,一旦出现任何问题,系统都会灵敏及时的报警。(上图)右边主要包含三部分,一个是针对检索结果和云分析结果的云展示,做数据可视化的展示。另一个是数据管理平台,用户可以通过这个平台对上传的数据进行便捷的编辑、修改。(上图)中间区域是整个架构的核心——控制服务层,主要功能是负责并发控制、配额控制以及集群。通过对服务请求的控制,将存储请求分发到检索层,存储请求会通过存储检索层更新到存储集群当中。如果将这些数据发布到检索,是可以通过系统推送到检索端。而如果是从检索端进来的请求,首先会进行索引查询,查询完之后再去存储集群中查摘要,把索引跟摘要的信息做一个整合反馈给用户,这就是检索接入层。
AS 是高级检索单元,主要负责把查询传给 DA,做一些语义理解,把理解的结果发到基础的检索集群当中。基础检索集群主要负责真正的倒排检索,基础检索集群里的库分为两部分,一是全量库,全量库静态不可修改。另一个是增量库,实时发布的内容会更新到增量库。通过实时查检索全量库和增量库,并将结果反馈给 AS。最后介绍的建库集群有两个功能:一是把增量信息推送到基础检索集群,其次是及时构建全量库,替换基础检索集群库。
LBS 云系统架构在经过全面而细致的调研之后,对各个风险点进行了分析,随后做了如下的一些改进:
- 对基础检索索引进行了一个重构。
- 对检索性能做了全面的优化。
- 对 ODP 存储接入层做了控制优化。
- 全面升级控制服务层。
- 对监控的梳理。
LBS 云索引结构演进
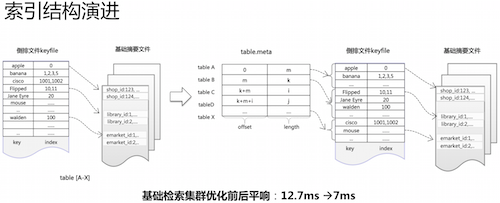
通过上图可以看出来,云存储系统可以保证用户数据互相隔离,A 用户不能访问 B 用户的数据,云检索系统中基础检索单元原先的全量库设计是:将所有用户数据的索引混建在一起,取得倒排拉链后,再根据用户的唯一标识 user_id 做过滤,这种设计会使得某些用户的检索会被其他用户的数据增长影响而导致性能变差,最严重的是会导致很多用户数据会由于拉链过长截断的问题而一直没有机会返回,当用户量小数据量少的时候问题并不明显,而随着接入 LBS 云的用户越来越多,原先这种索引之间没有彻底隔离的设计对用户体验造成了极大的伤害。
针对这个问题重新设计了 LBS 全量库的倒排结构,设计目标:
- 全面隔离用户,用户之间互不干扰,有各自独立的索引区间。
- 重构后性能至少要比现状好,解决随着用户增长,系统性能不合理地变差。
具体方案:
- 重新设计了全量库索引结构,提供了支持区间有序,允许全局有重复 key 的基础索引文件结构,提供了区间二分检索的查询。
- 采用新的索引结构的同时,设计了 Table.meta 二级索引结构,用于维护每个用户对应的索引区间,通过记录 (起始位置,长度) 信息来界定用户自己的索引区间,打破了原来用户索引杂糅无法分离的设计。
- 上图中 table ABC…的索引内容完全分离,互不影响。基础检索集群的平响从 12.7 毫秒降到了 7 毫秒,两类 PV 量最大的空间检索平响超过 100ms 的长尾比例从原来的 2.82%,12% 减少到 1.58%,5.89%,也彻底解决了用户检索效果上的问题。
存储演进
对存储以及监护层性能优化主要分为三点,第一点是把检索监护层从 PHP 改成了 C++,因为存储集群搭配的 PHPdriver 本身性能是非常差的。第二点是对 driver 进行升级。经过测试验证,连接池比短连接性能稳定非常多。第三点改进比较重要,引入 cache 集群来提升 table 层的性能。
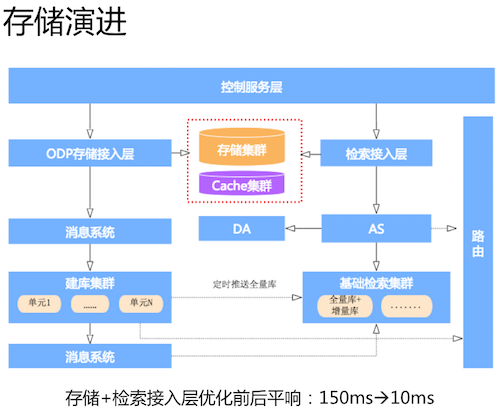
关于提升 table 层的性能有两点需要说明,第一点性能方面我们如何保障的?
- 首先 Cache 集群采用了 Redis 做了存储接入层。其次就是将 Cache 存储结构里的用户信息缩减。还有就是把存储集群当中的数据加载到 Cache 集群中,而加载操作不是由检索监护层完成的,检索监护层发一条消息给消息系统,由另外一个模块完成这种存储集群到 Cache 集群的更新。
- 第二点是如何有序的更新,以及保证最终一致性。假设现在在更新数据,同一时刻不同的 POI 数据也在更新,要解决有序性这个问题。方法就是去掉并发,不同的数据可以并发,相同的数据有序更新。
存储控制优化
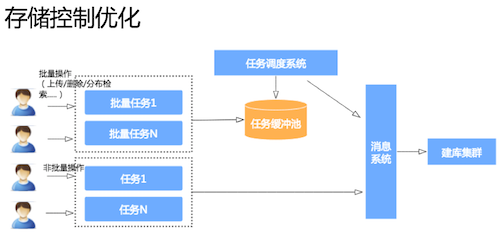
在存储控制优化方面也做了很多改善,V1.0 版本只支持非批量操作,单套 POI 数据实时增删改。V2.0 版本引入批量操作,支持用户对自己的表进行批量上传、删除,以及发布检索等批量任务。引入批量操作对系统造成了很大压力,因为部分用户会上传超过严格配额的数据。优化方法就是增加配额管理,减少数据过载现象。
任务调度系统也是优化的重点,此前,只要用户池里有任务就会被提取出来发到后端消息系统,更新到建户集群当中,这样的做法对后端建户集群造成很大压力,消息系统有很多消息堆积。解决方法就是根据后端建库系统性能对任务做一些调整,使得不会有过量任务冲击到后端建库集群,保证一些实时单条数据更新不受太大干扰。
控制服务层升级是非常有意义的事情,将之前控制的服务层内部 RPC 组建升级到最新最好用的组建,组建升级之后就使得检索的可用性提升了近一个 9。




