本文要点
- 深度学习算法被越来越多地运用到影响生活的决策中,如招聘和解聘员工、刑事司法系统。
- 机器学习实际上会放大偏差。研究人员发现,在人做饭的图片中,67% 是女性,而算法把 84% 的图片标记为女性。
- Pro Publica 发现,黑人被告(错误率 45%)的假阳性率几乎是白人被告(24%)的两倍。
- Buolamwini 和 Gebru 在研究中发现,ML 分类器对男性分类的效果好于对女性分类的效果,对亮肤色人分类的效果好于对暗肤色人分类的效果。
- AI 法规,如 1967 年的年龄歧视和就业法案和平等信用机会法,虽然不完美,但比什么保护都没有强。
本文以 Rachel Thomas 在 QCon.ai 2018 大会上的主题演讲“分析和预防机器学习中的无意识偏差”为基础。Thomas 在 fast.ai 工作,这是一个非营利性的研究实验室,和旧金山大学的数据研究所合作,向开发者社区提供深度学习培训。该实验室提供了一项免费课程,名称“面向编码人员的实用机器学习”。
Thomas 探讨了机器学习偏差的三个案例、偏差来源以及如何避免。
案例 1:用于招聘、解聘和刑事司法系统的软件
深度学习算法在影响生活的决策中运用得越来越多,如招聘、解聘和刑事司法系统。编码偏差会带来决策陷阱和风险。
2016 年,Pro Publica研究了 COMPAS再犯算法。该算法用于预测犯人或被告人被释放之后再次犯罪的可能性。该算法被用于保释、量刑和假释。Pro Publica 发现,黑人被告(错误率 45%)的假阳性率(被标记为“高风险”但没有再犯)是白人被告(24%)的将近两倍。
在这个算法中,种族不是一个显式变量,但种族和性别被潜在编码到许多其他的变量中,如我们在哪里生活,我们的社交网络,我们受到的教育。即使有意识地不看种族或性别,也不能保证没有偏差——装瞎子没用。虽然怀疑 COMPAS 的准确性,但威斯康星州最高法院去年批准了该方法的使用。Thomas 指出,那个算法还在使用真是令人震惊。
重要的是要有一个好的基线,让我们可以知道怎么样才算性能好,并且,有助于说明更简单的模型可能更有效。不能因为某个东西复杂,就认为那有用。人工智能(AI)在预测警务中的使用是一个问题。
去年,Taser 收购了两家 AI 公司,它在向警察部门推销预测软件。该公司占据着美国执法记录仪市场 80% 的份额,因此,他们有大量的视频数据。此外,Verge 在二月份透露,在过去的六年中,新奥尔良警察已经在一个绝密项目中使用来自 Palantir 的预测警务软件,甚至是市政委员都不知道。对于类似这样的应用,需要保持警惕,因为它们的使用不透明。因此有些私人公司,他们不会像警察部门那样遵守国家 / 公共记录法。经常,他们在法庭上受到保护,不需要透露他们在做什么。
此外,在警方现有的数据中存在大量的种族偏见,因此,这些算法用来学习的数据集从一开始就存在偏差。
最后,计算机视觉在运用于有色人种时一再失败。Thomas 表示,这是一个会导致出错的可怕组合。
案例 2:计算机视觉
计算机视觉通常不善于识别有色人种。其中一个最声名狼藉的例子来自 2015 年。可以自动标注照片的谷歌照片在分类毕业照和建筑图片时很有用。但是,它也把黑人标记成了大猩猩。
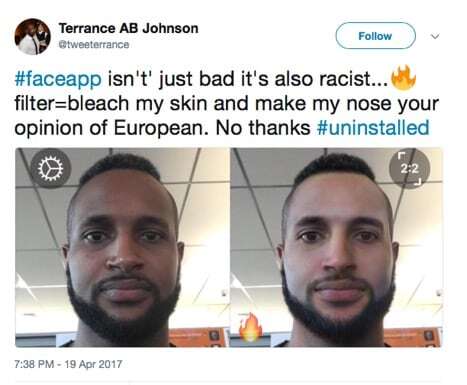
2016 年, Beauty.AI 网站使用 AI 机器人作为选美比赛的裁判。人们发现,与皮肤颜色深的人相比,皮肤颜色浅的人会被判定为更具吸引力。2017 年,使用神经网络创建照片滤镜的 FaceApp 创建了一个火辣滤镜,可以使人的肤色变浅,赋予他们更多欧洲人的特征。Rachel 在 Twitter 上展示了一个用户的真实面貌以及 App 创建的火辣版本。
Thomas 谈到了 Joy Buolamwini 和 Timnit Gebru 发表的一篇学术论文,他们评价了来自微软、IBM 和 Face++(一家中国公司)的几款商用计算机视觉分类器。他们发现,分类器对于男性的效果好于女性,对于肤色浅的人效果好于肤色深的人。差距相当明显,对于浅肤色男性,错误率基本为 0%,而对于深肤色女性,错误率在 20% 到 35% 之间。Buolamwini 和 Gebru 还按照肤色深浅分析了女性错误率。错误率随着肤色加深而增加。肤色最深的类别,错误率在 25% 到 47% 之间。
案例 3:词嵌入
Thomas 研究的第三个案例是类似谷歌翻译这样的产品中的词嵌入。
比如有两个句子“She is a doctor. He is a nurse.”。使用谷歌翻译把他们翻译成土耳其语,然后再译回英语。性别就反转了,那两个句子现在变成了“He is a doctor. She is a nurse.”。土耳其语中的单数代词不分性别,翻译成英语时会按照固定的模式。其他单数代词不分性别的语言也会出现这种情况。按照记录,有许多单词的翻译定式支持女性懒惰、女性忧伤等许多性格特征。
Thomas 解释了为什么会出现这种情况。计算机和机器学习把图片和单词当成数值来看待。同样的方法被用于语音识别和图片标注。这些算法的工作原理是,它们读取提供的图片,输出类似“穿黑衬衫的男性在弹吉他”或者“穿橘色背心的建筑工人正在路上施工”这样的东西。在类似谷歌智能回复这样的产品中,同样的机制可以自动提供邮件回复建议——如果有人询问你的假期计划,那么智能回复会建议,你可能想说“还没有计划”或者“我正准备要发给你”。
Thomas 举了 fast.ai 课程“面向程序员的实用深度学习”中的一个例子。在这个例子中,我们提供单词,获得一副图片。提供单词“tench(丁鲷)”(一种鱼)和“net(网)”,它就会返回一张丁鲷在网中的图片。该方法会仔细搜索一串单词,但对于相似的单词,它不会告诉我们那意味着什么。因此,虽然“cat”和“catastrophe(灾难)”可能是有顺序的,但是它们之间没有任何语义关联。
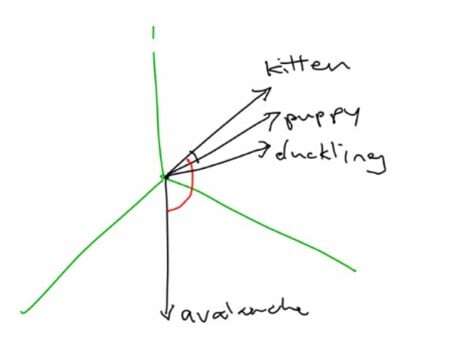
一个更好的方法是把词表示成向量。词嵌入高维向量。她举了“kitten(小猫)”、“puppy(小狗)”和“duckling(小鸭子)”的例子,这几个词可能彼次之间都很接近,因为它们都是动物宝宝。但是,“avalanche(雪崩)”可能就远,因为其因为它与其他词之间没有真正的联系。
关于词向量的更多信息,请查阅 Adrian Colyer 的文章“词向量的神奇力量”。
Word2Vec
Word2Vec 是谷歌发布的一个词嵌入库。还有其他类似的库,如 Facebook 的 fastText,斯坦福大学自然语言处理团队的 GloVe。训练这些库需要大量的数据、时间和计算能力,不过,这些团队已经完成了这项工作,并且发布了自己的库供公众使用,因此还是很方便的。由于是已经训练过的版本,所以用起来就容易多了。GitHub 上提供了所有这三个项目的代码,Thomas 自己的词嵌入工作坊也是如此。你可以使用 Jupyter Notebook 运行她的程序,并尝试不同的词。
相似的词,“puppy(小狗)”和“dog(狗)”或“queen(王后)”和“princess(王妃)”,在距离上非常接近。当然,不相关的词,如“celebrity(名人)”和“dusty(满是灰尘的)”或“kitten(小猫)”和“airplane(飞机)”的距离就比较远。该程序使用了余弦相似度,而不是欧氏距离,因为你不会希望在高维空间中使用欧式距离。
你可以使用这种方法获取语言的某些信息。你还可以找到距离特定目标单词最近的 10 个单词。例如,如果你查找距离“swimming(正在游泳)”最近的单词,那么你会获得类似“swim(游泳)”、“rowing(划船)”、“diving(潜水)”、“volleyball(排球)”和“pool(池塘)”这样的单词。单词类比也有用。它们捕获类似“西班牙之于马德里正如意大利之于罗马”这样的东西。不过,这里有许多地方会产生偏差。例如,“man(男性)”和“genius(天赋)”之间的距离比“woman(女性)”和“genius(天赋)”之间的距离小得多。
研究人员更系统地研究了词篮。比如,他们有一篮或一组花:“clover(三叶草)”、“poppy(罂粟花)”、“marigold(万寿菊)”、“iris(鸢尾花)”等,他们还有一篮昆虫:“locust(蝗虫)”、“spider(蜘蛛)”、“bedbug(臭虫)”、“maggot(蛆)”等。他们有一篮令人愉快的词(health、love、peace、 cheer 等)和一篮令人不愉快的词(abuse、filth、murder、death 等)。研究人员会查看不同词篮之间的距离,他们发现,花和令人愉快的词距离比较近,而昆虫和令人不愉快的词距离比较近。
到目前为止,所有这些似乎都是合理的,但是,研究人员查看了典型的白人名字和典型的黑人名字。他们发现,黑人名字和令人不愉快的单词距离更近,而白人名字和令人愉快的单词距离更近,这是偏差。在所有的单词组中,他们发现了许多种族和性别偏差,比如,“父亲之于医生正如母亲之于护士”,“男性之于计算机程序员正如女性之于操持家务者”。这些类比是在 Word2Vec 和 GloVe 中发现的。
Thomas 探讨了另一个偏差的例子。在一个酒店评价系统中,墨西哥的酒店排名较低,因为“Mexican(墨西哥)”的词嵌入有负面属性。这些词嵌入是用一个很大的文本语料库训练的。这些文本包含许多种族和性别偏差,在我们希望词嵌入可以学习语义时,它们同时学习了这种联系。
机器学习会放大偏差
实际上,机器学习会放大偏差。其中一个例子在文章“男性也喜欢购物:使用语料库层约束减少性别偏差放大”中进行了讨论,该文考查了一个数据集中图片的可视化语义角色标签。研究人员发现,在人做饭的图片中,67% 的是女性,但是该算法把 84% 的图片标注为女性。机器学习算法有放大我们在真实世界看到的东西的风险。
Thomas 提到了 Zeynep Tufekci 的研究,他提供了有关技术与社会的交集的见解。Tufekci 在推特中写道,“许多人告诉我,不管起始点在哪,YouTube 自动播放结束时都是白人至上主义者视频,这真是令人吃惊。”下面是一些例子:
- “我在观看一个叶风机视频,三个视频之后是白人至上论。”
- “我在观看一个关于种植园奴隶制起源的学术讨论,下一个视频来自大屠杀否认者。”
- “我和女儿在看一个关于南非前总统曼德拉的视频,下一个视频是说一些类似‘南非黑人是真正的种族主义者和罪犯’这样的内容。”
非常可怕。
Renée DiResta 是一名虚假信息及宣传传播专家,她几年前注意到,如果你在 Facebook 上加入了一个反接种疫苗小组,那么该网站还会向你推荐有关自然癌症疗法、化学制剂、Flat Earth 和各种各样的反科学团体。这些网络做了许多促进此类宣传的工作。
Thomas 提到了一篇学术论文,关于失控反馈循环如何用于预测执法。如果软件或分析预测一个地区将会有更多的犯罪活动,警察局可能向那里派出更多警官——但是,由于那里有了更多警官,所以他们可能会逮捕更多人,这可能会让我们认为那里有更多犯罪,这又会让我们向那里派出更多警官。我们很容易陷入这种失控反馈循环。
Thomas 建议,我们把某些变量包含在模型中时要进行道德方面的思考。虽然我们可以访问数据,即使那些数据可以提高我们模型的性能,但使用它合乎道德吗?符合我们社会的价值观吗?甚至是工程师都需要就他们从事的工作提出道德问题,并且应该能够回答与之有关的道德问题。我们将会看到,社会对此的容忍度会越来越低。
iRobot 数据科学负责人 Angela Bassa 说,“不是数据可能会有偏差。数据就是有偏差。如果你想使用数据,那么你就需要了解它是如何产生的。”
解决词嵌入中的偏差
即使我们在模型开发早期就消除偏差,但是,可以渗入偏差的地方如此之多,我们需要一直对偏差保持警惕。
使用更具代表性的数据集是一个解决方案。Buolamwini 和 Gebru 发现了上述计算机视觉产品中的偏差缺陷,拼合出一个能更好的表示不同肤色男性和女性的数据集。 Gender Shades 提供了这份数据集。该网站还提供了他们的学术论文以及一段有关他们工作的短视频。
Gebru 和其他人最近还发表了一篇论文“数据集的数据表”。该论文提供了原型数据表,用于记录数据集特征和元数据,可以反映出数据集如何创建、如何构成、做过什么处理、数据集维护需要做哪些工作以及任何法律或道德考虑。了解用于构建模型的数据集很重要。
Thomas 强调,提前考虑意外的结果是我们的工作。考虑下流氓、骚扰者或者威权主义政府如何使用我们构建的平台。我们的平台如何用于宣传或虚假信息?当 Facebook 宣布他们将开始威胁建模时,许多人问他们,为什么在过去的 14 年不那样做。
还有一种观点,就是不要存储我们不需要的数据,那样就没人可以拿走那些数据。
我们的工作是,在这样的情况出现之前,考虑我们的软件可能如何被滥用。信息安全领域的文化就是以此为基础的。从现在开始,我们需要更多地考虑事情会怎样变坏。
有关 AI 的问题
Thomas 列出了一些有关 AI 的问题。
- 数据有什么偏差?所有数据都有某种偏差,我们需要知道那是什么以及数据是如何创建的。
- 代码和数据可以审核吗?是开源的吗?使用闭源的专有算法来做有关医疗保健、刑事司法及招聘谁或解聘谁的决定是有风险的。
- 不同子组的错误率是什么?如果我们没有一个有代表性的数据集,那么我们可能注意不到我们的算法在某个子组上性能糟糕。对于数据集中的所有子组,我们的抽样规模是否足够大?对这一点进行检查很重要,就像 Pro Publica 对于考虑种族的再犯算法所做的那样。
- 一个简单的、基于规则的可选方案的准确率是多少?有一个好的基准真得很重要,不管我们研究的是什么问题,这都应该是第一步,因为如果有人问,95% 的准确率是否够好,我们需要能够回答。答案是否正确取决于语境。我想到了再犯算法,他不比一个双变量的线性分类器更高效。知道简单的可选方案是什么是有好处的。准备采用什么程序来处理申诉或错误?对于影响人们生活的东西,我们需要一个人性化申诉程序。在公司内,作为工程师,我们相对而言有更大的能力提出这些问题。
- 构建它的团队多元化情况如何?构建我们的技术的团队应该能够代表将会受到它影响的人,逐渐地会变成我们所有人。
研究表明,多元化团队表现更好,相信我们是精英的确会增加偏差。不断地面谈会花费许多时间和精力。Julia Evans 的博文“进行小规模的文化变革”就有很好的借鉴意义。
先进技术代替不了好政策。Thomas 谈到,fast.ai 世界各地的学生都在把深度学习运用到解决社会问题,如拯救热带雨林或改善对帕金森病患者的护理。
有一些相关的法规,如 1967 年颁布的年龄歧视与就业法案和平等信用机会法案。这还不完善,但总比没有任何保护好,因为我们真得需要考虑,作为一个社会,我们希望保护什么权力。
Thomas 在演讲总结中表示,检查偏差是一项永远也做不完的工作。我们可以按照一些步骤得出解决方案,但是偏差会从许多地方渗入进来。没有一个检查清单可以保证偏差已经消失,我们无须再担心。对于那个东西,我们要一直保持警惕。
关于作者
 Srini Penchikala 目前是德克萨斯奥斯汀的一名高级软件架构师。Penchikala 在软件架构、设计和开发方面有超过 22 年的经验。他还是 InfoQ 人工智能、机器学习 & 数据工程社区的责任编辑,最近他发布了自己的迷你书《使用 Apache Spark 进行大数据处理》。他已经在 InfoQ、TheServerSide、O’Reilly Network(OnJava)、DevX 的 Java Zone、Java.net 和 JavaWorld 等网站上发表了许多有关软件架构、安全、风险管理、NoSQL 和大数据的文章。
Srini Penchikala 目前是德克萨斯奥斯汀的一名高级软件架构师。Penchikala 在软件架构、设计和开发方面有超过 22 年的经验。他还是 InfoQ 人工智能、机器学习 & 数据工程社区的责任编辑,最近他发布了自己的迷你书《使用 Apache Spark 进行大数据处理》。他已经在 InfoQ、TheServerSide、O’Reilly Network(OnJava)、DevX 的 Java Zone、Java.net 和 JavaWorld 等网站上发表了许多有关软件架构、安全、风险管理、NoSQL 和大数据的文章。
查看英文原文: Analyzing and Preventing Unconscious Bias in Machine Learning




