理想情况下,服务调用总能成功完成并返回需要的结果。不幸的是,在现实中,服务可能而且也会失败。这种失败可以有一大堆的问题引起。它可以是由服务本身引起,如入参验证失败,或只是服务实现的一个 bug,或通信问题 (如服务不可达或实现不可访问底层的数据库)。最后,失败可以由部署问题引起,如软件升级之后,必需的一个库没有被正确地部署。
一种被广泛采用的失败处理机制是异常处理,包括捕获并记录错误,以及在失败发生时选择一个备选执行路径。在应用程序和组件实现中,它已经成为一种标准机制。问题在于,它特别依赖于应用程序设计者和开发者对可能异常情况的预见能力,以及在运行时正确的利用代码 1 处理它们的能力。这种方法基于以下假设:
- 应用程序作为一个整体完全地被设计,包括所有可能的异常状况。这意味着应用程序所有的执行路径被全部定义,结果是,它可以被应用程序团队完全地测试。
- 应用程序在单台机器(或有限数量的机器)上运行,使用标准化的异常报告模式,在本地文件日志文件中报告所有的异常。
- 应用组件中发生的变更被集中管理,这意味着应用程序开发团队可以对变更进行完整的控制。
在分布式系统的情况下,试图实现这种异常处理方法明显变得复杂,因为在这种情况下,异常不仅可以由应用程序代码本身,也可以由基础设施(如网络)故障引起,这使得分析所有可能的异常场景变得更加困难。此外,在此情形下,异常日志在多台物理机间传播,也使得协调它们明显更复杂。在面向服务架构(SOA)上下文中的特性,如松耦合(组织性和技术性),自治以及依赖已有实现业务功能的应用使得异常处理变得更加复杂。
由于每个服务是自行设计、实现和维护,并可用到多个企业解决方案(在服务设计时,它们可能是未知的)中,特定服务的异常处理实现围绕 3 点进行:处理异常;向本地服务实现记录异常;在它们不能被本地解决时,将它们向服务消费者报告为。如果没有采取特殊的度量,这将导致“异常处理孤岛”(见图 1) 2 。
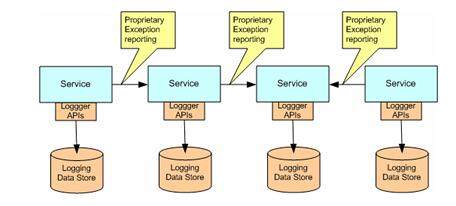 图 1 异常处理孤岛
图 1 异常处理孤岛
以下的复杂问题在单片应用程序中并不是什么大问题,为了支持 SOA 下的异常处理,必须被处理 [2]。
- SOA 的分布式和异构的天性使得它特别容易失败,在多个层次上引起异常 [3]。系统级的异常,由消息传递、通信和其他基础设施失败引起。应用级异常,由于错误的消息语义或应用中的逻辑错误导致。业务级异常,由于违反最佳实践、合规法律、规章制度,或业务经理要求的业务政策引起。后者甚至可能对服务执行本身不可见,可能需要服务管理解决方案适当的检测它们。
- 有一种异常情况是任何参与者中的异常处理无法检测的,即与横跨不同业务过程的一个或多个服务(有时横跨多个公司)的特定业务事务相关的异常情况。在此情形下,异常处理可能需要聚合业务事务级别的异常信息。这意味着特定服务的异常信息必须被使用该服务的业务事务割断。此外,这种隔断的需要还因为隐私、健康保险携带和责任法案(Health Insurance Portability and Accountability Act,HIPAA) 和其它的合规要求而加强。
- 单个服务缺少整个解决方案(业务过程)的视角。缺少过程范围的视角,将使得错误修正变得困难。因此,服务实现一旦检测到异常,并不总能选择一条可选执行路径,同时还不得不通知消费者,因为它可能有修正这种情形所需要的上下文。然而,SOA 递归组合的特性使得情况进一步的复杂化:消费者常常是另一个服务,因此也不是解决该问题的合适位置 [4]。不是所有的异常都能被自动处理,有时唯一处理失败的办法就是通过人工干预。要做到这些,就需要决定谁是合适的人,并通知他们关于异常的事情。
- 松耦合、异构的服务对于异常的发现和处理常常各不相同。有些可能会使用一些特殊的组件,如 log4j、log4ne、.NET 企业库等等,其它则使用专有解决方案。此外,正如 [1] 中所定义的,包装现有应用程序的功能是当前服务实现普遍的做法。这些传统应用可以以不同的方式检测、记录和通知异常。
对异常处理实现应用 SOA 原则,是 SOA 中一种优雅的异常处理解决方案。这将导致所有主要的异常管理元素“服务化”[4],(即,日志,异常解决和通知)。图 2 显示了异常日志、解决和通知的总体架构。
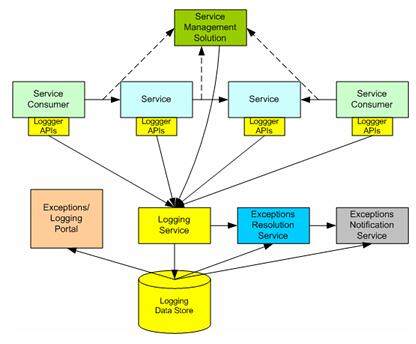 图 2 异常日志、解决和通知的统一架构
图 2 异常日志、解决和通知的统一架构
服务实现中的工具代码用于检测和记录系统级和应用级异常。日志使用标准日志组件(如 Log4J、Log4NET、.NET 企业库等)暴露的通用 API。日志实现将调用请求翻译成对异常记录服务的服务调用。在这种情形下,为了降低异常记录的效率影响,服务调用常常使用异步调用。尽管这个实现是以日志服务为中心,但是异常处理还依赖其它几个元素:
- 日志服务接收所有的日志请求,将它们保存在日志数据库中,并将它们转发给异常解解决服务。
- 异常解决服务使用异常解析规则处理每个日志消息,这些规则指明消息是否应该被忽略(如信息消息)、自动解决或是否需要人工干预。
- 通知服务接收通知请求,并使用一组规则分发通知(如,电子邮件网关、分页网关、企业管理解决方案)。
- 异常 / 日志门户可以让人们查阅和浏览异常日志信息。
- 服务管理监视服务通信量决定业务级别异常,并将它们报告给日志服务,它将它们和其它任何系统中的异常等同对待。
以上的功能划分确保了异常记录和解决风格一致。这允许公式化企业最佳实践(“公共知识”),并改善异常的审计、监视和控制。这代表了合规制定取得了重大进展。
异常解决服务集中化允许更快地实现特定异常类型处理的变更。最常用的异常解决方法是:
- 自动解决,解决那些不需要人工干预的问题。
- 半自动解决,评估规则集并建议可能的解决方案。
- 依靠人来进行人工解决。
附注:服务异常定义
SOA 中的异常处理非常依赖服务异常定义语义。服务异常可以属于 3 组(即系统、应用或业务)之一,因此它在服务有效负荷(回复)中可能有不同的表示。服务有效负荷可以被编码进 SOAP 消息;即使在消息使用其它编码时,这些想法也是可应用的。SOAP 报文提供了特殊化的元素(SOAP Fault)用于异常的传播。使用 SOAP Fault 的最佳实践在别处描述 [6]。
SOAP Fault 最适合报告系统级别的异常,而且应该总被用于报告这类异常。(通过给 SOAP Fault 元素补充执行堆栈的内容,J2EE 实现通常提供了与问题有关的额外信息。)系统级别的异常通常与系统的软硬件错误相关。这意味着服务调用可以在问题解决之后重试,这种重试可以自动地(如,通过故障转移)也可以是手动地(如,在物理替换了错误元件之后)。
应用和业务级别异常需要更多数据来正确定义错误起因。这些情况下,往往需要为每个具体错误使用特定模式来定义信息,这样可以有效地扩展领域语义模型以描述失败场景。另一个复杂情形是,基于一次服务调用可能返回多个错误。这种情形的典型例子就是验证错误。为了降低通信开支,通常返回所有的验证错误(即将它们一批打包),这样可以同时解决他们。
这些异常类型可以被作为包含扩展细节信息的 SOAP Fault,或作为包含指示错误的有效负荷的普通服务响应被传递回来。两种方法各有优缺点,总结如下:
SOAP Fault 特殊化的有效负荷 优点 - 直接被 Web 服务规范和工具支持。
为所有类型异常提供统一的传递方式。
直接映射到诸如 Java、C#编程语言的异常。
明确隔离系统级别和应用级别异常。
允许引入同时支持成功和失败场景的语义模型。
无需使用 SOAP。
缺点 - 需要区分语义模型为成功和失败场景
- 要求服务消费者检查回复有效负载,并显式区分应用级别的成功和失败场景。
不考虑在以上总结表中的这些缺点,使用特殊化的有效负荷汇报应用程序和业务级别异常是更好的方法,因为它增加了灵活性和扩展性。
图 2 给出解决方案需要以下前提:
- 所有日志、消息、包含信息、警告、异常等必须遵守标准格式,如公共基础事件(Common Base Events,CBE)[5]。
- 所有参与者(即服务消费者和提供者、日志、异常解决和通知服务)应该能解释异常 / 日志信息,这要求遵循企业语义模型(参见服务异常定义附注)。
- 分析和理解失败需要跨越服务边界链接日志消息。这要求横跨业务事务范围的唯一相关 ID。
本文所描述的异常管理方法,应用面向服务架构的原则为有效管理 SOA 实现中的异常提供了基础。它介绍了使用特殊化的基础设施来构建灵活、可扩展的异常处理解决方案。它通过提供整个企业统一的异常处理方法改善实现的一致性。通过提供横跨多个服务消费者和提供者之间的单一、统一的日志,它同样也简化了维护并改善了可测试性。
关于作者
Boris Lublinsky 在软件工程和技术架构方面拥有超过 25 年的经验。最近几年,他关注企业架构,SOA 和过程管理。在他的整个职业生涯中,Lublinsky 博士是一个活跃的技术演讲者和作者。他已在不同杂志超过 40 份的技术出版物上发表文章,包括:Avtomatika i telemechanica,IEEE Transactions on Automatic Control,Distributed Computing,Nuclear Instruments and Methods,Java Developer’s Journal,XML Journal,Web Services Journal,JavaPro Journal,Enterprise Architect Journal 和 EAI Journal。目前 Lublinsky 博士为大型保险公司工作,他的职责包括开发和维护 SOA 策略和框架。通过 blublinsky@hotmail.com 可以联系他。
参考文献
1.B. Lublinsky,将SOA 定义为一种体系结构风格(原文: Defining SOA as an architectural style )。IBM Developworks,2007 年 1 月
2.Ramesh Ranganathan,管理 SOA 中的异常。 IT 工具箱:工程技术,2005 年 9 月。
3.Sean Fitts,当异常是规则时:完成可靠和可跟踪的面向服务架构。SOA/WebServices 期刊,2005 年 9 月。
4.Peter Abrahams,解决加速器 - SOA 的异常处理。It-director,2005 年 9 月。
5.Andy Brodie,Amanda Watkinson,公共事件基础架构:从技术预览到产品发布(原文: The common event infrastructure: From technical preview to production )。DevelopWorks,2005 年 4 月。
6.Russell Butek Ping Wang, Web 服务编程技巧与窍门:在 JAX-RPC 应用程序中构建有状态会话(原文: Web services programming tips and tricks: Exception handling with jax-rpc )。DeveloperWorks,2004 年 2 月。
1 这种手段一般基于 try/catch 块(当今的大多数编程语言都支持,如 Java 或 C#),允许决定异常并为随后的分析记录信息。
2 相比于“数据孤岛”和“自动化孤岛”。 查看英文原文: Implementing Exceptions in SOA
译者简介:胡键,自 2000 年西安交通大学硕士毕业后一直从事软件开发。2002 年开始使用 Java,在项目开发中经常采用 OpenSource 工具,如 Ant、Maven、Hibernate、Struts 等,目前正在研究信息集成方面的规范和技术。可以通过 jianhgreat@hotmail.com 与他联系,或访问博客: http://foxgem.javaeye.com/ 。参与 InfoQ 中文站内容建设,请邮件至 china-editorial@infoq.com 。

暂无签名

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...







评论