
HBase 是一个分布式的、非关系型开源数据库。HBase 有如下几个特点:首先 HBase 是 No-SQL 的一个典型实现,提升了系统的可扩展性;其次 HBase 支持线性水平扩展,极大提升了系统的可伸缩性和运算能力;最后 HBase 和 Google 的 BigTable 有异曲同工之妙,底层也是建立在 HDFS(Hadoop 分布式文件系统) 之上,可以搭建在廉价的 PC 机集群上。No-SQL、云计算、海量数据分析的普及,使我们越来越关注系统的可靠性(High Availability),数据容灾 / 数据恢复是高可用系统的一个很重要的技术组成,本文由简入深,一步步搭建一个 HBase 数据集群,并详细说明生产环境如何使用 HBase 数据容灾方案。
HBase 架构简介
HBase 在完全分布式环境下,由 Master 进程负责管理 RegionServers 集群的负载均衡以及资源分配,ZooKeeper 负责集群元数据的维护并且监控集群的状态以防止单点故障,每个 RegionServer 会负责具体数据块的读写,HBase 所有的数据存储在 HDSF 系统上。
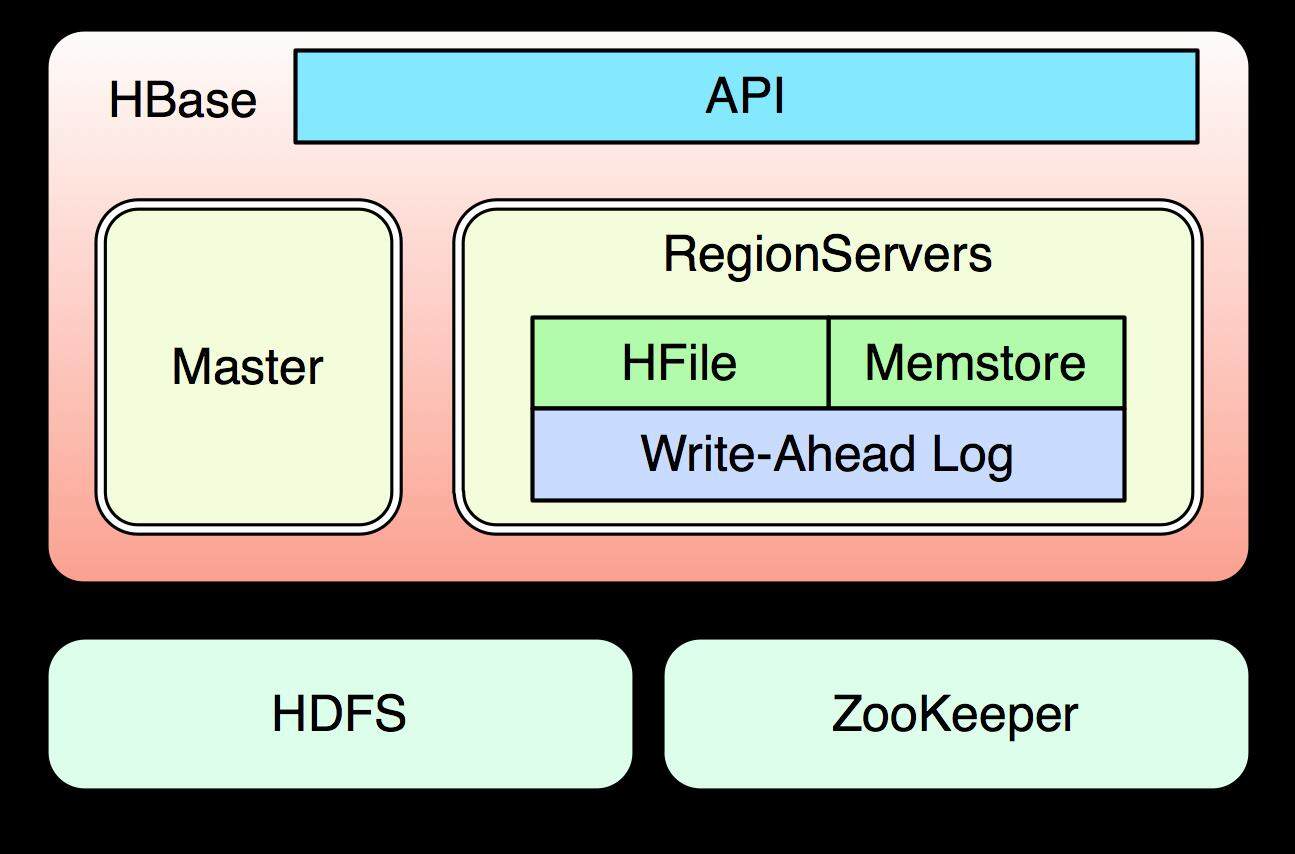
图一 HBase 逻辑架构 [1]
HBase 集群部署
HBase 集群物理架构
物理机
192.168.0.105 Master Ubuntu Desktop 11.10 Desktop 192.168.0.102 Slave1 Ubuntu Desktop 11.10 Desktop 192.168.0.103 Slave2 Ubuntu Desktop 11.10 Desktop 192.168.0.104 Slave3 Ubuntu Desktop 11.10 Desktop 192.168.0.101 Recover Ubuntu Desktop 11.10 Desktop
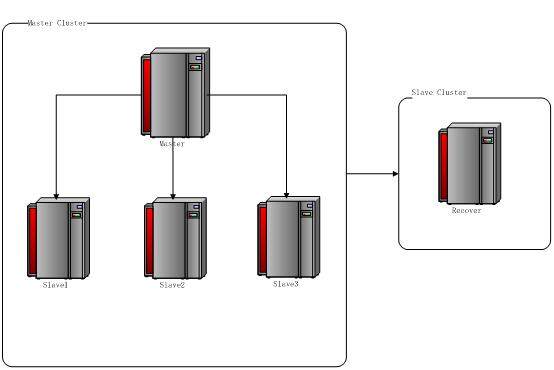
图二 集群物理架构
先决条件
- SSH 协议 [2] Hadoop 集群之间的通讯采用的是 SSH 协议,所以要保证 Master、Slave 之间可以自由的通讯,一般推荐使用无验证通讯
-
安装 SSH ```
apt-get install openssh-server
apt-get install openssh-client
- 创建相同用户名的 SSH 公钥 在 master 主机和 slave 机上创建相同的用户 hadoop
sudo adduser hadoop
- 在主机上生成公私钥 key pair ``` ssh-keygen -t rsa -P "" cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
-
将 key 值复制到 slave1 和 slave2 上 ```
scp $HOME/.ssh/id_rsa.pub hadoop@slave1:/home/hadoop/.ssh/authorized_keys
scp $HOME/.ssh/id_rsa.pub hadoop@slave2:/home/hadoop/.ssh/authorized_keys
scp $HOME/.ssh/id_rsa.pub hadoop@slave3:/home/hadoop/.ssh/authorized_keys
这样 master 就可以自由的访问 slave 节点了 2. Java 安装 ``` sudo apt-get install sun-java6-jdk
Hadoop 部署
-
hadoop-env.sh ```
export JAVA_HOME=/usr/lib/jvm/java-6-sun
export HADOOP_HOME=/home/hadoop/hadoop-0.20.2
- master,slaves ``` Master, Slave1, Slave2, Slave3
-
core-site.xml ```
fs.default.name hdfs://master:9000 hadoop.tmp.dir // 临时文件目录/data/tmp/hadoop // 注意不要放到 /tmp 目录下
- hdfs-site.xml ``` <property> <name>dfs.replication</name> // 备份文件 <value>1</value> </property>
-
mapred.xml ```
mapred.job.tracker master:9001
2. 启动 Hadoop hadoop namenode format // 首先需要格式化 namenode
bin/start-all.sh
验证服务:MapReduce 管理界面 http://master:50030/jobtracker.jsp ### **HBase 部署 ** 1. HBase 配置 下载 HBase 0.90.50 版本 [\[5\]](#_Ref5) - HBase-env.sh ``` export JAVA_HOME=/usr/lib/jvm/java-6-sun export HBase_MANAGES_ZK=true //zookeeper 随 HBase 启动
-
HBase-site.xml ```
HBase.rootdir hdfs://master:9000/HBase // 端口号和名称和 Hadoop 配置一致HBase.cluster.distributed true dfs.replication 1 HBase.master master HBase.zookeeper.quorum slave1,slave2,slave3
2. 启动 HBase 集群 Master 主机上执行 $HBase\_HOEM/bin/start-HBase.sh {1} 验证:使用 jps 命令查看 HBase 的集群进程 {1}  {1} ## HBase 数据容灾 {1} 前面我们已经介绍过,如果 HBase 单个节点出现故障,Zookeeper 会通知 master 主进程,master 会将 HLog 日志进行拆分,分发到其他 RegionServer 上进行数据恢复。HBase 对于单点故障的容错能力还是不错的,但是如果发生多点故障,现有的基本容错功能是远远不够的 (会造成数据丢失)。 {1} ### **HBase Replication 机制 [\[6\]](#_Ref6)** {1} HBase 0.90 以后开始支持 Replication 机制,该机制设计的主导思想是基于操作日志 (put/get/delete) 做数据同步,这点很像 MySQL 基于 Binary Log 做 statement-based replication[\[7\]](#_Ref7)。 {1} 如下图所示,客户端的 put/delete 操作会被 RegionServer 写入本地的 HLog 中去,与此同时每个 RegionServer 会将 Hlog 放入对应 znode 上的 Replication 队列,HBase 集群会有一个独立的线程,根据固定大小的 buffer 值,将 HLog 内容推送到 Slave Cluster 集群中的某个 RegionServer 上 (当前版本只支持单个 Slave Cluster 复制),并在将当前复制的偏移量保存在 ZooKeeper 上,整个过程是异步完成的。 {1} 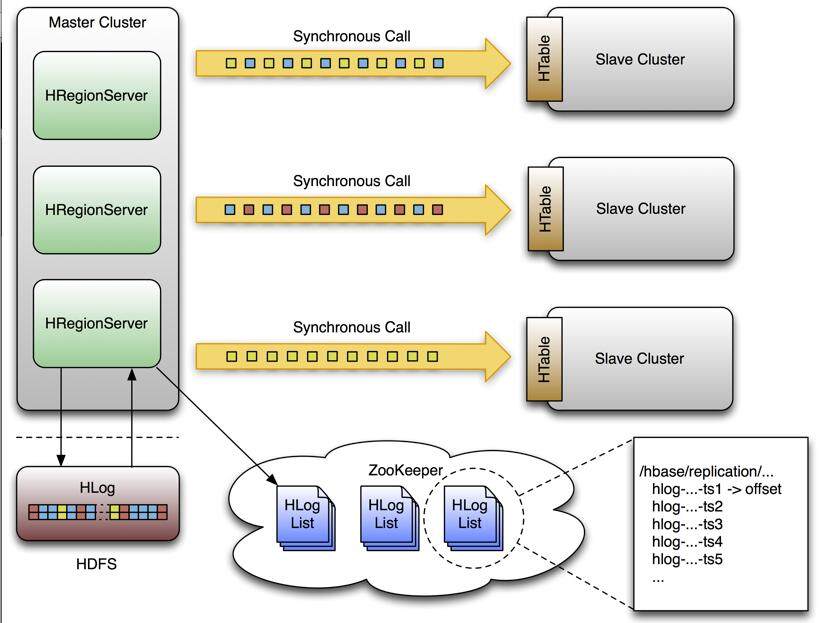 {1} ** 图三 HBase 数据同步 **[**\[8\]**](#_Ref8) {1} ### **HBase Replication 启动 ** {1} 1. HBase-env.sh ``` export JAVA_HOME=/usr/lib/jvm/java-6-sun export HBase_MANAGES_ZK=<strong>false</strong> //ZooKeeper 独立启动
- HBase-site.xml master 集群和 slave 集群的配置需要同时修改
<property> <name>HBase.replication</name> <value>true</value> </property>
- Shell 启动复制功能
add_peer disable 'my_table_name' // 表名字 alter ' my_table_name ', {NAME => 'family_name', <strong>REPLICATION_SCOPE => '1'</strong>} // 修改表 schema enable ' my_table_name'
验证:查看 RegionServer 的日志
Considering 1 rs, with ratio 0.1 Getting 1 rs from peer cluster # 1 Choosing peer 192.168.0.101:62020
数据校验
为了保证数据一致性,生产环境上做异地容灾需要增加数据校验 / 数据监控。HBase 的 Replication 机制,根据官方的文档提供了数据比对的工具类 VerifyReplication [9] 。我们可以将其功能包装起来,做自动化校验。下面是代码片段:
final String[] argumentsArray = new String[] { "--starttime=xxxxxxxxxxx", // 开始时间戳根据具体的业务需要 "--stoptime=" + new Date().getTime(), // 选取当前时间戳作为结束的时间戳 "1", //peer node id "my_table_name" // 表名 }; final Timer timer = new Timer(); timer.schedule(new TimerTask() {@Override public void run() { try { Configuration conf = HBaseConfiguration.create(); Job job = VerifyReplication.createSubmittableJob(conf, argumentsArray); job.waitForCompletion(true); long value = job.getCounters().findCounter(VerifyReplication.Verifier.Counters.BADROWS).getValue(); if (value > 0) { Logger.getLogger("Finding Unmatched Rows! " + value); } } catch (Exception e) { // 异常处理策略 final String msg = "Comparing Job Error!"; Logger.getLogger(this.getClass()).error(msg, e); try { SMTPClientWrapper.send("xxx@xxx.com", "HBase replication error!", msg); } catch (Exception e1) { // 考虑邮件服务器 down 机, failover Logger.getLogger(this.getClass()).error("send alarm email error!", e); } } } }, 0, 600000); // 十分钟校验一次
小结与展望
HBase 的 Replication 机制,为增强系统可靠性提供了有力支持,但目前单节点 Slave Cluster 复制会增加系统的负荷并间接形成 Slave Cluster 的数据热点,期待 HBase 后续的版本支持多节点 Slave Clusters 复制。
引用
[1] http://ofps.oreilly.com/titles/9781449396107/intro.html
[2] http://en.wikipedia.org/wiki/Secure_Shell
[3] http://hadoop.apache.org/common/docs/current/cluster_setup.html
[4] http://hadoop.apache.org/common/releases.html#Download
[5] http://www.apache.org/dyn/closer.cgi/HBase/
[6] http://HBase.apache.org/replication.html
[7] http://dev.mysql.com/doc/refman/5.1/en/replication-formats.html
[8] http://HBase.apache.org/replication.html
[9] http://HBase.apache.org/xref/org/apache/hadoop/HBase/mapreduce/replication/VerifyReplication.html
感谢崔康对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。

腾讯云云原生提质增效实践精选集 2024
《2024腾讯云云原生提质增效实践精选集》出炉,5大热门技术领域,13个行业精选标杆案例,痛点到解决方案全...













评论