
在之前的对话中,百度基础体系首席架构师林仕鼎先生提到要将数据中心当做逻辑上的一台机器来设计架构。但是从物理的层面上,一台机器内部的几个 CPU、几个硬盘,跟一个数据中心里面上万个 CPU、上万块硬盘相比,完全是不一样的概念。因此,在为数据中心这台“机器”设计软件——比如存储系统时,对这种差异性的处理至关重要。
之所以会从存储系统先开始,是因为数据存储是最根本的需求。不管你做什么,你都需要存储。所以,通常都是先做存储系统,然后才是其他系统。我们做一个大规模存储系统,它就已经在推动整个系统的架构发生了变化。
对于系统架构的变化,前一篇文章中提到最根本的原因就是使用场景的变化:
从单用户多任务到多用户单任务,带来了系统架构的变化,然后带来了软件设计理念的变化。那么,数据中心里面使用的这些系统,无论是分布式的文件系统也好,数据库也好——实际上我们也不需要区分它是文件系统还是数据库,它们都是分布式的存储系统——它们整体设计理念是发生了变化的。
在林仕鼎看来,这种软件设计理念的变化包含很多方面,但最基本的一点就是:分层。
这个“机器”里面是一个有层次的架构。有些东西是比较紧密的,比如说我这些机器正好在同一个盒子,即同一台物理机器里面,这时候我们的交换是通过内存,而不是通过网络,我们就可以做共享内存,而不是消息。也可能我们在同一个机架里面,那么我们的交换基本可以做到 1:1。也有可能我们分散在不同的机架上,这时候我就不能毫无限制的把信息扔给另一台机器了,因为这时候会有个收敛比。综合考虑这些信息,我就可以根据整个物理的情况来选择一个平衡:成本和软件复杂度的平衡。
“所以,”林仕鼎补充到,“因为不同层下的限制不同,你的软件本身必须要能够去适应。”
CCDB 是林仕鼎为百度设计的第二套存储系统。当前在生产环境下使用的 BDDB 是 2008 年的设计,从 2009 年开始用于百度网页的存储。BDDB 实际上已经是按照分布式的思想去设计的,但它还是把一台机器当做一台机器来看。
一个存储系统有三个层:block 层,stream 层,以及 table 层。CCDB 的设计是,我把这三个层放在一块儿,放在一台机器上面去。然后,机器和机器之间连起来,就把每个层直接扩展到多机了。这样,你由软件上的层次,映射到物理机器的架构上的时候,就可以尝试多种不同的设计方案出来。就像我刚才说的,我们有同一台机器里面通过内存交换的架构,有同一个交换机下 1:1 交换的架构,有跨交换机的、有一定收敛比的架构。我们需要选择合适的单元映射到合适的硬件上。不同的映射方式会带来很多种不同的变化。
除了物理结构上的层次和存储软件本身的层次之外,这个分层在单机的存储设备上也有所体现:
我们看到存储,有硬盘,有 SSD,有内存。所以还有一个需要考虑的因素就是,我们需要把什么东西分别放在这不同的介质上面?
林仕鼎介绍了现在希捷的一个做法:把 SSD 和机械硬盘打包,做成混合硬盘:
它在一个盘里同时有内存这样的 cache,有 SSD 的 cache,而它把这些内存、SSD、硬盘都给隐藏了起来,做成一个设备。
对百度的应用场景而言,这肯定又是不可取的,因为单机做了多余的事情:
数据中心里面,我们本身就把这两个分开来考虑。你把它并到一块,反而会限制它的范围,导致你这边数据的 cache 只能放到这块盘里面。而如果我把它分来的话,我就可以跨多机建一个逻辑上的 SSD 层。在物理上,我在这块盘的 SSD 上 cache 的东西,可以弄到另一块盘上去。
所以,CCDB 的做法是这样的:把 block 层存在硬盘上,把 stream 层放在 SSD 上(这层是可选的),而内存则用于做写缓冲。
于是,就变成这样:
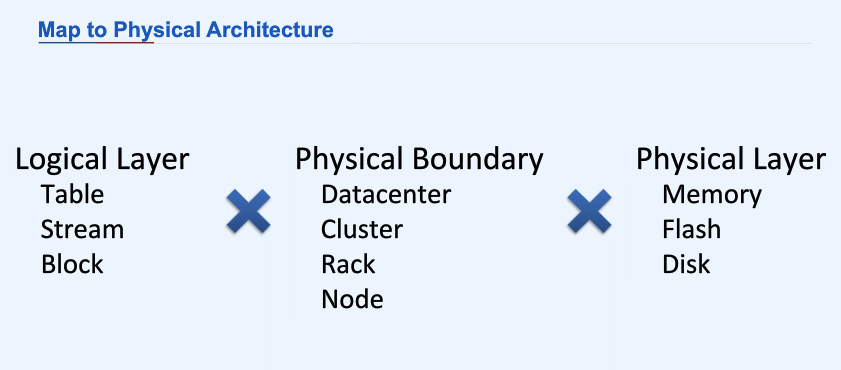
(来自林仕鼎在深圳的分享资料)
将多机资源合并成逻辑上的一个层,一个最直接的好处就是可以实现另一种意义上的高可靠性:
因为我们把多机的内存放在一块儿,这就意味着同一份数据我可以写到不同的内存上面去。这种实现的可靠性级别和我从内存写入硬盘的可靠性级别是不同的,但很多情况下,我有这种多机内存级的可靠性级别就够了,不一定要到硬盘上去,那样性能成本太高了。
我们一旦把整个设计的理念从软件这个层面来考虑的话,那么在设计上存在的可能性,以及架构层面的考虑,是完全不一样的,因为你什么都可以去做,而且可以很灵活的去调整。
在 4 月 25 日 QCon 北京的主题演讲上,林仕鼎将会带来主题为《架构设计与架构师》的分享,就系统领域中基本的存储、计算、分布式技术以及服务模型进行分析,从另一种视角看待这些领域问题。敬请期待!
感谢马国耀对本文的审校。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论