Apache Samza 是 LinkedIn 最近开源的一款流处理器。在题为《 Samza:LinkedIn 的实时流处理》的演讲中,Chris Riccomini 探讨了 Samza 的功能集,它如何与 YARN 和 Kafka 集成,LinkedIn 如何用它,以及其未来路线图是什么。
发生在 LinkedIn 的大部分处理是 RPC 样式的数据处理,这种情况需要非常快速的响应。在响应延迟谱的另一端是批处理,此处,他们大量使用了 Hadoop。Hadoop 处理和批处理通常发生在事后,经常晚几个小时。
这样,在异步 RPC 处理和 Hadoop 样式的处理之间就出现了空白。对于前者,用户正积极等待响应;而对于后者,尽管已经努压缩,但仍然需要很长的时间才能运行完。
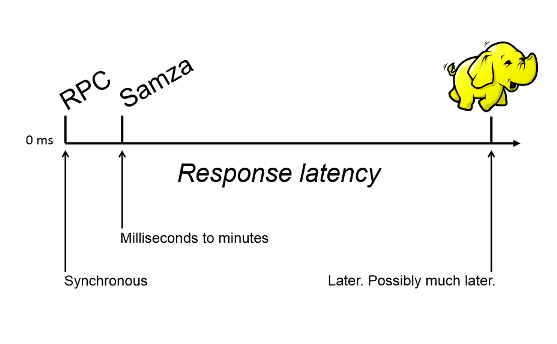
这个空白就是 Samza 适用的地方。我们可以在此处对数据进行异步处理,但也不能等待几个小时。操作时间通常以毫秒到分钟为单位。我们的想法是相对快速地对数据进行处理,并将其返回到需要它的地方,不管是下游系统,还是某个实时服务。
Chris 谈到,目前,在工具和环境方面,对流处理的支持最差。
对于这种类型的处理,LinkedIn 看到了许多应用场景——
- 当人们进入另一家公司、当他们喜欢一篇文章、当他们加入一个团体等等情况下进行新闻推送显示。
新闻无法接受延时传播,如果使用 Hadoop 进行批量计算,那么响应时间可能是几个小时,甚至是一天之后。从新闻中非常快速地获取趋势分析文章很重要。
- 广告——获取相关广告,以及跟踪和监控广告显示、点击次数和其它指标
- 复杂监控——允许执行像“过去一分钟里最慢的五个页面”这样的复杂查询。
LinkedIn**** 的现有生态系统
Samza 背后的动机及其架构都受到 LinkedIn 现有生态系统的巨大影响。因此,在深入研究 Samza 之前,对现有生态系统有个大概的了解很重要。
Kafka 是 LinkedIn 几年前发布的一个开源项目。它是一个满足消息队列和日志聚合两个需求的消息系统。LinkedIn 的所有用户活动,所有的指标和监控数据,甚至是数据库变更都会进到这个系统。
LinkedIn 还有一个名为 Databus 的专用系统,该系统将他们所有的数据库做成了一个流模型。它像一个包含了每个键值对最新数据的数据库。但当该数据库变化时,他们实际上可以将变化集做成一个流。每个单独的变化是那个流中的一条消息。
因为 LinkedIn 有 Kafka,而且已经集成了好几年,所以 LinkedIn 的许多数据,几乎全部,都是流格式,而不是数据格式或者存储在 Hadoop 上。
创建 Samza 的动机
Chris 谈到,当开始用 Kafka 和他们系统中的所有数据做流处理的时候,他们是从一个类似 Web 服务的东西开始的,它会启动,从 Kafka 读取消息并做一些处理,然后将消息写回。
在做这件事的时候,他们意识到,要使它真正有用并具备可扩展性,有许多问题需要解决。比如分区:如何划分流?如何划分处理器?如何管理状态,其中状态本质上是指在处理器中维护的介于消息之间的东西,或者如果每次有消息到达的时候,计数器就会加 1,那么它也可以是像总数这样的东西。如何重新处理?
至于失败语义,我们会得到至少一次,或者至多一次,或者恰好一次消息,也有不确定性。如果流处理器与另一个系统交互,无论它是个数据库,还是依赖于时间或者消息的顺序,如何处理那些真正决定最终输出结果的数据?
Samza 试图解决其中的部分问题。
Samza**** 架构
流是 Samza 最基本的元素。较之对其它流处理系统的预期,Samza 的流定义更严格而且堪称重量级。为了减少延时,其它处理系统,如 Strom,往往有非常轻量化的流定义,比如说,从 UDP 到直接 TCP 连接的一切。
Samza 采用了不同的做法。首先,它希望流能够分区。它希望这些流是有顺序的。如果先读了消息 3,又读了消息 4,那么就无法在一个单独的分区里颠倒它们的顺序。它还希望流能够回放,就是说以后可以回头重读一条消息。它希望流具备容错能力。如果分区 1 里面的一台主机不复存在,那么流在其它主机上应该仍然可读。另外,流通常是无限的。一旦到达了流的末尾——比如说,分区 0 的消息 6——只需要在有消息时设法重新读取下一条。那种情况并不是结束。
这个定义可以很好地映射到 Kafka,于是,LinkedIn 用它做了 Samza 的流基础设施。
在 Samza 中,有许多概念需要理解。要点是——
- 流——Samza 处理流。流是由一定数量的类型或类别相似的不可变消息组成。可以通过像 Kafka 这样的消息系统(其中每个主题是一个 Samza 流)或者数据库(表)或者甚至是 Hadoop(HDFS 中的一个文件目录)提供实际的实现。
诸如消息排序、批处理之类的事情是由流来处理的。
- “作业(Jobs)”——Samza 作业是在一组输入流上执行逻辑转换从而将消息附加到一组输出流的代码。
- 分区——为了可扩展性,每个流都被划分成一个或多个分区。每个分区都是一个完全有序的消息序列。
- “任务(Tasks)”——也是为了可扩展性,每个作业被分解成多个任务后进行分配。任务使用作业输入流相应分区中的数据。
- 容器——分区和任务是逻辑并行单元,而容器是物理并行单元。每个容器是一个运行一个或多个任务的 Unix 进程(或者 Linux cgroup)。
- TaskRunner ——TaskRunner 是 Samza 的流处理容器。它负责启动、执行以及关闭一个或多个 StreamTask 实例。
- “检查点(Checkpointing)”——检查点通常用于故障恢复。如果一个 taskrunner 由于某种原因宕掉了(比如,硬件故障),当重新启动时,它应该使用最后离开时的消息——这是通过检查点实现的。
- 状态管理——需要在不同的消息处理之间传递的数据称之为状态——它可以是保存一个总数那样简单的东西,也可以是复杂得多的东西。Samza 允许任务维持一种持久可变且可查询的状态,而且,它与每个任务在物理上处于同一位置。状态需要具备高可用性:如果出现任务失败的情况,它可以在任务故障转移到另一台机器时还原。
数据存储是可插拔的,但 Samza 带有一个开箱即用的键 - 值存储。
- YARN(Yet Another Resource Manager)是 Hadoop v2 在 v1 基础上做的最大改进——它将 Map-Reduce 作业追踪器从资源管理中剥离出来,并允许 Map-reduce 替代方案使用相同的资源管理器。Samza 使用 YARN 进行集群管理、故障跟踪等。
Samza 提供了一个 YARN ApplicationMaster 和一个开箱即用的 YARN 作业运行程序。
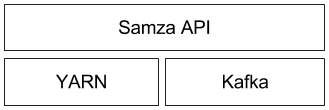
读者可以通过查看详细架构来了解各种组件之间如何交互,也可以通过阅读整个文档来了解每个组件的细节。
可能的改进
在Samza 中使用诸如YARN 这样的组件有一个好处,就是允许在已经运行了草案任务、测试任务和MapReduce 任务的同一个网格上运行Samza。对于上述所有的任务,都可以使用相同的基础设施。不过,由于现有的设置完全是试验性的,LinkedIn 目前还没有在一个“多框架(multi-framework)”环境下运行Samza。
Chris 说,为了进入一个更大的多框架环境,进程隔离还需要做得更好一些。
结论
Samza 是 Apache 的一个正在孵化中项目,相对还不成熟,因此还有很大的改进空间。使用 hello-samza 工程是一个不错的入门方式,那是个很小的东西,在大约 5 分钟之内就可以配置好并运行。通过它,可以使用来自维基百科服务器的实时更改日志来弄清楚发生了什么,而且它还提供了一连串可供使用的东西。
建立在 Hadoop 之上的 STORM 是另一个流处理器项目。读者可以查看 Samza 和 STORM 比较。
关于作者
 Chris Riccomini是 LinkedIn 的一名资深软件工程师,他目前是 Apache Samza 项目的提交者和 PMC 成员。在 LinkedIn,他参与了众多项目,包括:“你可能认识的人(People You May Know)”、REST.li、Hadoop、工程工具和 OLAP 系统。在加入 LinkedIn 之前,它在 PayPal 从事数据可视化和欺诈行为建模工作。
Chris Riccomini是 LinkedIn 的一名资深软件工程师,他目前是 Apache Samza 项目的提交者和 PMC 成员。在 LinkedIn,他参与了众多项目,包括:“你可能认识的人(People You May Know)”、REST.li、Hadoop、工程工具和 OLAP 系统。在加入 LinkedIn 之前,它在 PayPal 从事数据可视化和欺诈行为建模工作。
查看英文原文:**** How LinkedIn Uses Apache Samza




