《Kubernetes 与云原生应用》专栏是 InfoQ 向轻元科技首席架构师王昕约稿的系列文章。本专栏包含 8 篇内容,将会从介绍和分析 Kubernetes 系统以及云原生应用入手,逐步推出基于 Kubernetes 的容器设计模式实践案例,希望对计划应用 Kubernetes 的朋友有所帮助。本文是该专栏的第 7 篇。
-
Kubernetes 系统架构与设计理念
-
云原生应用的设计理念与挑战
-
Kubernetes 与云原生应用的容器设计模式
-
Kubernetes 容器设计模式实践案例 - 单节点多容器模式
-
Kubernetes 容器设计模式实践案例 - 多节点选举模式
-
Kubernetes 容器设计模式实践案例 - 工作队列模式
-
Kubernetes 容器设计模式实践案例 - 分散收集模式
-
云原生应用的容器设计模式综述与展望
K8s 与容器设计模式
目前 K8s 社区推出的容器设计模式主要分为三大类:第一类,单容器管理模式;第二类,单节点多容器模式;第三类,多节点多容器模式;一类比一类更复杂。根据复杂性的不同,本系列文章给出不同篇幅的实践案例介绍。
云计算跟分布式系统是一个事物的两种解读:云计算是面子,分布式系统是里子。云计算给用户刻画出的是方便的、弹性的、自动化的随时随地可以得到的信息处理服务;而后台,需要云平台背后的研发和运维工程师创建维护好一个复杂的分布式系统。本系列文章所推出的容器设计模式,旨在将分布式系统,特别是将分布式应用模式化,简化分布式系统的创建和维护。
本文将介绍容器设计模式的最后一种,分散收集模式。这是最复杂的一种,但也是最具通用意义的一种模式。分散收集模式先将服务扇出到多个微服务实例上做独立处理,再将所有处理结果扇入到一个逻辑根微服实例上作合并,以此来完成对一个复杂问题的处理;这和数学和计算机算法中的分治法非常相似。这一模式对利用 k8s 平台运行分布式系统有普遍应用价值。
分散收集模式
分散收集模式利用分布式系统弹性计算能力的容器设计模式。在这一模式中,计算服务的使用者,即服务的客户端,将初始计算请求发送给一个“根计算节点”。根计算节点对计算任务做出分割,将任务分割成大量的小计算任务,然后将小计算任务分配给大量计算服务器进行分布式平行计算 。每个计算服务器都计算初始计算任务的一小块,将计算结果返回给根计算节点。根计算节点将所有计算结果合并起来,组成一个针对初始计算任务的一个统一的结果,返回给申请计算任务的客户端。
这一系统中的分布式服务器非常适合用容器技术来实现,具体到 K8s 系统中,就是一个 K8s 的 Pod;具体到 Docker 系统中,就是一个 Docker 容器。利用容器快速部署启动和运行时开销特别小的特点,任务可以被分到很多小服务器上并行处理,这些容器形成的小服务器跟其他任务共同使用基础设施计算节点的能力。
一个典型的分散收集模式的分布式系统如图 Fig01 所示。根节点接受到来自客户端的服务请求,将服务请求分配给不同的业务模块分散处理,处理结果收集到根节点,经过一定的汇聚合并运算,产生一个合并的结果交付给客户端。
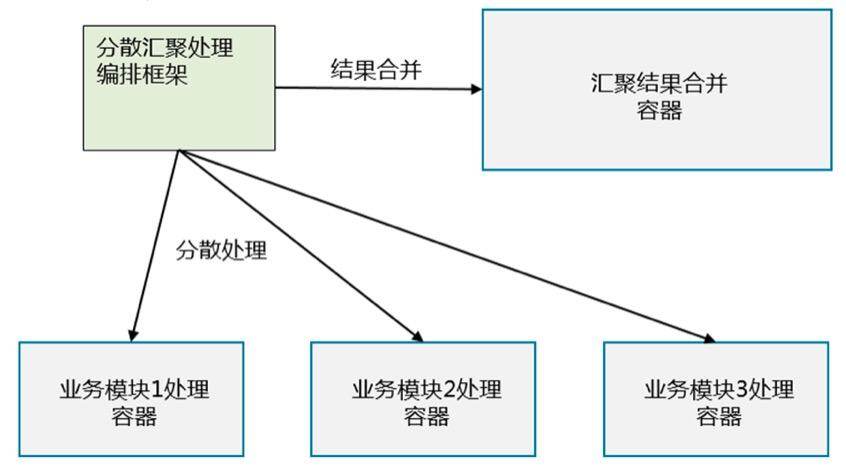
Fig01 分散收集模式示意图
本文中案例的代码
本文中使用的代码在 Github 仓库: https://github.com/xwangqingyuan/metaparticle
本文中使用的代码主要以 metapaticle 项目为基础: https://github.com/brendandburns/metaparticle
本文作者在此基础上增加了用于演示 scatter gather 容器模式的案例,在 https://github.com/xwangqingyuan/metaparticle/tree/master/examples 目录下。
分布式计算模式项目 Metapaticle
Metapaticle 项目的目的在开发并展示一种基础设施即代码的编程模式,力图将基础设施管理逻辑和功能运算逻辑以同一种语言实现在同一短小精干的程序中。
在分布式计算系统中,不仅功能性计算的逻辑是重要的,对计算系统的逻辑拓扑结构的控制也是重要的。大家可以想象,依靠流行大数据分析框架 Hadoop MapReduce,Spark,Storm 和 Flink 等进行分布式大数据运算,代码中往往包含逻辑拓扑结构的逻辑。
在以往的分布式计算特别是云计算体系中,大多将基础设施管理的逻辑由配置文件和自动化运维工具来配置,而功能运算逻辑由通用的编程语言来控制。这一模式也比较符合过去基础设施管理逻辑和功能运算逻辑的特点。
在过去,基础设施相对固定,变化较小,因此用来管理它的配置文件和自动化运维工具不需要支持太强大的动态逻辑功能;另一方面,过去大多数编程语言的抽象度和表达能力较底层,以命令式的编程范式为主;因此,功能运算逻辑和基础设施管理逻辑相距较远。即便如此,当开发人员开始运维自己的软件系统时,不可避免地将同时用两种语言分别管理基础设施和功能运算逻辑,往往给开发人员带来不舒服的感觉。
随着云计算特别是容器技术的流行,计算机系统的基础设施越来越动态,人们对基础设施管理控制的逻辑控能力要求越来越大。同时,随着计算机语言的发展,函数式编程,声明式语言越来越收到开发人员的熟悉;人们越来越倾向于使用高抽象度的、高表达力的函数式编程模式甚至声明式语言来快速地实现功能逻辑,使得很多应用功能逻辑的代码看上去越来越简单得像“配置文件”。这样,对基础设施管理逻辑控制能力的需求和对功能运算逻辑控制能力的需求似乎越来越接近了。
在这种背景下,metaparticle 项目被设计用来探索将基础设施管理逻辑和功能运算逻辑以同一种编程语言来实现的模式。正像我们提到的,随着云计算和容器的发展,基础设施管理逻辑和功能运算逻辑越来越融合成一个整体的分布式计算任务。Metaparticle 谋求的正是用同一种语言搞定一个整体的计算任务。
目前 metaparticle 主要支持 javascript 语言,主要是利用它的简单性和它对函数式编程的支持。当然,按照 metaparticle 的设计思想,未来 Python,Scala,Swift 这些较高级的语言都可是用来实现 metaparticle 的模式。Metaparticle 的设计思想在于用同一种语言完成同一个分布式计算任务,但是并不会谋求限制到某一种特定语言。Metaparticle 项目还很初级,主要对我们的帮助还是试验和启发作用。
Metaparticle 支持 3 种分布式系统的服务模式:分散收集模式(Scatter/Gather)、分片模式(Shard)和水平扩展模式(Spread)。其中分散收集模式是更具通用性的一种模式,正好也是本系列文章中准备介绍的最后一种容器设计模式,也是最复杂的一种设计模式。本文中针对分散收集模式的演示案例,以 metaparticle 为基础,先要通过 nodejs 的包管理工具安装 metaparticle 模块,然后通过 node 来试验本文中的案例。
安装 Metaparticle
本文中的演示案例以 Metaparticle 的 Scatter/Gather 模式为基础,要安装可参照文件 https://github.com/xwangqingyuan/metaparticle/blob/master/README.md 和 https://github.com/xwangqingyuan/metaparticle/blob/master/examples/server1.md
要通过 NPM 安装 Metaparticle,可以直接运行:
$ npm install metaparticle
也可以下载代码后,通过本地代码安装:
$ git clone <a href="https://github.com/xwangqingyuan/metaparticle.git"><u>https://github.com/xwangqingyuan/metaparticle.git</u></a>
$ npm install ./metaparticle/
在安装过程中如果碰到缺少的nodejs module,直接用npm install即可。
通过分散收集计算正态分布(高斯分布)的统计特性
在本演示案例中,利用分散收集模式模拟展示一个正态分布的统计直方图。
计算高斯分布的示例代码文件 scatter-gather-gaussian.js 清单。
// Import the main library
var mp = require('metaparticle');
// A simple function for calculating a Gaussian distributed value
// from a uniform random value
var gaussian = function (sigma, mean) {
var u1 = 2 * Math.PI * Math.random();
var u2 = -2 * Math.log(Math.random());
var n = Math.sqrt(u2) * Math.cos(u1);
return n * sigma + mean;
};
// This function is executed on each leaf
var leafFunction = function (data) {
var result = { 'n': [] };
for (var i = 0; i < 100; i++) {
result.n.push(gaussian(25, 100));
}
return result;
};
// This function is executed on each root
var mergeFunction = function (responses) {
var histogram = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0];
for (var i = 0; i < responses.length; i++) {
for (var j = 0; j < responses[i].n.length; j++) {
if (responses[i].n < 0 || responses[i].n > 200) {
continue
}
var ix = Math.floor(responses[i].n[j] / 20);
histogram[ix]++;
}
}
return histogram;
};
var svc = mp.service(
// name of the service
"histogram-service",
// library function that creates a scatter/gather service
mp.scatter(10, leafFunction, mergeFunction));
// Expose the root service to the world
svc.subservices.gather.expose = true;
// And serve
mp.serve();
在本例中,根服务器将计算任务分配给 10 个叶子服务器计算。方法mp.scatter用来调度整体的分布式计算。方法mp.scatter的第一个参数是分片的个数,第 2 个参数是叶子服务器的计算函数leafFunction,第 3 个参数是根服务器合并的计算函数mergeFunction。
在本例中,每个叶子节点都模拟一个方差为 25,均值为 100 的正态分布随机变量。计算函数leafFunction用来产生 100 个随机变量,计算函数mergeFunction用来合并所有子节点的随机变量,统计这些随机变量的样本值处在不同区间的个数。
启动分散收集模式计算高斯分布的服务器端容器服务。
xwang@dev-xwang:/gitws/github.com/xwangqingyuan/metaparticle/examples$
node scatter-gather-gaussian.js
building image (this may take a bit)
building image done.
deploying
运行客户端程序发送请求计算统计结果。
xwang@dev-xwang:/gitws/github.com/xwangqingyuan/metaparticle/examples$
node client.js histogram-service
[0,4,55,139,296,284,160,53,9,0]
通过计算结果可以看到,正如一般正态分布所预期的一样,正态分布的主要样本个数集中在直方图中间的部分296 和 284,越向两边样本个数越少。
停止并删除分散收集模式的服务器端容器服务。
xwang@dev-xwang:/gitws/github.com/xwangqingyuan/metaparticle/examples$
node scatter-gather-gaussian.js delete
通过分散收集计算均匀分布的统计特性
在本例中,每个叶子节点都模拟一个处于 0 到 200 之间的均匀分布的随机变量。计算函数leafFunction用来产生 100 个随机变量,计算函数mergeFunction用来合并所有子节点的随机变量,统计这些随机变量的样本值处在不同区间的个数。
计算均匀分布的示例代码文件 scatter-gather-uniform.js 清单。
// Import the main library
var mp = require('metaparticle');
// A simple function to caculate a uniform integer
var uniform = function (lower, upper) {
return Math.round(lower + (upper-lower)*Math.random());
};
// This function is executed on each leaf
var leafFunction = function (data) {
var result = { 'n': [] };
for (var i = 0; i < 100; i++) {
result.n.push(uniform(0, 200));
}
return result;
};
// This function is executed on each root
var mergeFunction = function (responses) {
var histogram = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0];
for (var i = 0; i < responses.length; i++) {
for (var j = 0; j < 10; j++) {
histogram[j] += responses[i].n[j];
}
}
return histogram;
};
var svc = mp.service(
// name of the service
"histogram-service",
// library function that creates a scatter/gather service
mp.scatter(10, leafFunction, mergeFunction));
// Expose the root service to the world
svc.subservices.gather.expose = true;
// And serve
mp.serve();
启动分散收集模式计算均匀分布的服务器端容器服务。
xwang@dev-xwang:/gitws/github.com/xwangqingyuan/metaparticle/examples$
node scatter-gather-uniform.js.js
building image (this may take a bit)
building image done.
deploying
运行客户端程序发送请求计算统计结果。
xwang@dev-xwang:/gitws/github.com/xwangqingyuan/metaparticle/examples$
node client.js histogram-service
[1244,980,1066,961,679,1097,825,1021,719,911]
通过计算结果可以看到,正如一般均匀分布所预期的一样,均匀分布的主要样本个数在 10 个收集得到的样本区间分布比较均匀,围绕平均数 1000 上下波动。
停止并删除分散收集模式的服务器端容器服务。
xwang@dev-xwang:/gitws/github.com/xwangqingyuan/metaparticle/examples$
node scatter-gather-uniform.js delete
通过分散收集计算整数中的数字出现频率
在本例中,利用分散收集模式,模拟统计一系列整数的 10 进制占位数字的统计特性。
在本例中,每个叶子节点都计算 100 个处于 0 到 100 之间的均匀分布的整数的所有占位数字的出现次数,例如 56 这个整数,有 5 和 6 两个数字,会给 5 和 6 这两个数字的次数分别增加 1。计算函数leafFunction用来产生 100 个随机变量,并统计这 100 个随机变量的数字(0-9)出现次数,计算函数mergeFunction用来合并所有子节点的计算的出现次数,计算出总的出现次数。
计算整数中的数字出现频率的示例代码文件 scatter-gather-count-digit.js 清单。
// Import the main library
var mp = require('metaparticle');
// A simple function to caculate a uniform integer
var uniform = function (lower, upper) {
return Math.round(lower + (upper-lower)*Math.random());
};
// This function is executed on each leaf
var leafFunction = function (data) {
var result = {'n': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]};
for (var i = 0; i < 100; i++) {
var num = uniform(0, 100);
var str = "" + num;
for (var j = 0; j < str.length; j++) {
var digit = parseInt(str.charAt(j));
result.n[digit]++;
}
}
return result;
};
// This function is executed on each root
var mergeFunction = function (responses) {
var histogram = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0];
for (var i = 0; i < responses.length; i++) {
for (var j = 0; j < 10; j++) {
histogram[j] += responses[i].n[j];
}
}
return histogram;
};
var svc = mp.service(
// name of the service
"histogram-service",
// library function that creates a scatter/gather service
mp.scatter(10, leafFunction, mergeFunction));
// Expose the root service to the world
svc.subservices.gather.expose = true;
// And serve
mp.serve();
启动分散收集模式计算高斯分布的服务器端容器服务。
xwang@dev-xwang:/gitws/github.com/xwangqingyuan/metaparticle/examples$
node scatter-gather-count-digit.js
building image (this may take a bit)
building image done.
deploying
运行客户端程序发送请求计算统计结果。
xwang@dev-xwang:/gitws/github.com/xwangqingyuan/metaparticle/examples$
node client.js histogram-service
[83,184,178,196,207,202,204,231,205,196]
通过计算结果可以看到,在所有数字中,1-9 的数字出现频率是比较接近的,大概在 200 左右,而 0 作为数字出现频率是较低的,大概少 100 个左右,这是因为 0 不会作为首位数字出现。
停止并删除分散收集模式的服务器端容器服务。
xwang@dev-xwang:/gitws/github.com/xwangqingyuan/metaparticle/examples$
node scatter-gather-count-digit.js delete
通过分散收集计算整数末尾数字的出现频率
在本例中,利用分散收集模式,模拟统计一系列整数的 10 进制末尾数字的出现。
在本例中,每个叶子节点都计算 100 个处于 0 到 100 之间的 5 的倍数的末尾数字的出现频率。计算函数leafFunction用来产生 100 个随机变量,并统计这 100 个随机变量的数字(0-9)出现次数,计算函数mergeFunction用来合并所有子节点的计算的出现次数,计算出总的出现次数。
计算高斯分布的示例代码文件 scatter-gather-count-last-digit.js 清单。
// Import the main library
var mp = require('metaparticle');
// A simple function to caculate a uniform integer
var uniform = function (lower, upper) {
return Math.round(lower + (upper-lower)*Math.random());
};
// This function is executed on each leaf
var leafFunction = function (data) {
var result = {'n': [0, 0, 0, 0, 0, 0, 0, 0, 0, 0]};
for (var i = 0; i < 100; i++) {
var num = uniform(0, 20)*5;
var str = "" + num;
var digit = parseInt(str.charAt(str.length-1));
result.n[digit]++;
}
return result;
};
// This function is executed on each root
var mergeFunction = function (responses) {
var histogram = [0, 0, 0, 0, 0, 0, 0, 0, 0, 0];
for (var i = 0; i < responses.length; i++) {
for (var j = 0; j < 10; j++) {
histogram[j] += responses[i].n[j];
}
}
return histogram;
};
var svc = mp.service(
// name of the service
"histogram-service",
// library function that creates a scatter/gather service
mp.scatter(10, leafFunction, mergeFunction));
// Expose the root service to the world
svc.subservices.gather.expose = true;
// And serve
mp.serve();
启动分散收集模式计算高斯分布的服务器端容器服务。
xwang@dev-xwang:/gitws/github.com/xwangqingyuan/metaparticle/examples$
node scatter-gather-count-last-digit.js
building image (this may take a bit)
building image done.
Deploying
运行客户端程序发送请求计算统计结果。
xwang@dev-xwang:/gitws/github.com/xwangqingyuan/metaparticle/examples$
node client.js histogram-service [495,0,0,0,0,505,0,0,0,0]
通过计算结果可以看到,在所有数字中,0 和 5 的作为末尾数字占据了所有出现次数,各占出现频率的一半,而其他数字不会作为末尾数字出现;这很显然,因为这里统计的所有整数都是 5 的倍数。
停止并删除分散收集模式的服务器端容器服务。
xwang@dev-xwang:/gitws/github.com/xwangqingyuan/metaparticle/examples$
node scatter-gather-count-last-digit.js delete
总结
本文主要介绍了 K8s 集群中,多节点容器模式中的分散收集模式。分散收集模式利用分布式系统弹性计算能力的容器设计模式。在这一模式中,计算服务的使用者,即服务的客户端,将初始计算请求发送给一个“根计算节点”。根计算节点对计算任务做出分割,将任务分割成大量的小计算任务,然后将小计算任务分配给大量计算服务器进行分布式平行计算 。每个计算服务器都计算初始计算任务的一小块,将计算结果返回给根计算节点。根计算节点将所有计算结果合并起来,组成一个针对初始计算任务的一个统一的结果,返回给申请计算任务的客户端。
分散收集模式是本系列容器设计模式的最后一种,也是最复杂的和最有普遍应用价值的一种模式。本文同时介绍了分布式计算模式项目 Metapaticle,该项目的目的在开发并展示一种基础设施即代码的编程模式,力图将基础设施管理逻辑和功能运算逻辑以同一种语言实现在同一短小精干的程序中。
依靠 K8s 集群强大的基础设施编排引擎和控制工具,以容器为基础实施的分布式应用可以获得强大的动态管理基础设施的能力,DevOps 理念从流程管理上连通开发和运维,而 Metapaticle 则考虑从编程范式和编程语言上打通开发和运维,成为一种新的 DevOps 自动化工具。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




