
《Kubernetes 与云原生应用》专栏是 InfoQ 向轻元科技首席架构师王昕约稿的系列文章。本专栏包含 8 篇内容,从介绍和分析 Kubernetes 系统以及云原生应用入手,逐步推出基于 Kubernetes 的容器设计模式实践案例,希望对计划应用 Kubernetes 的朋友和对分布式系统技术有兴趣的朋友有所帮助。
本文是该专栏的最后一篇,作者试图从宏观角度对云计算系统、云原生应用和容器设计模式等相关理念作综述和展望。
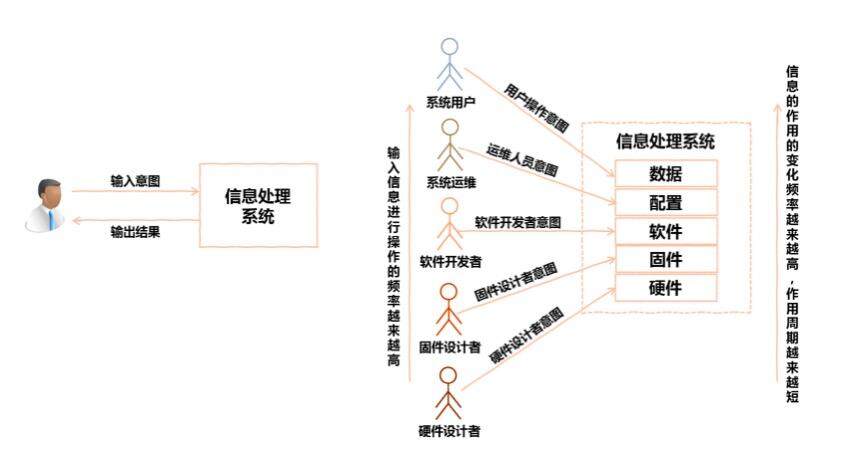
信息系统的分层
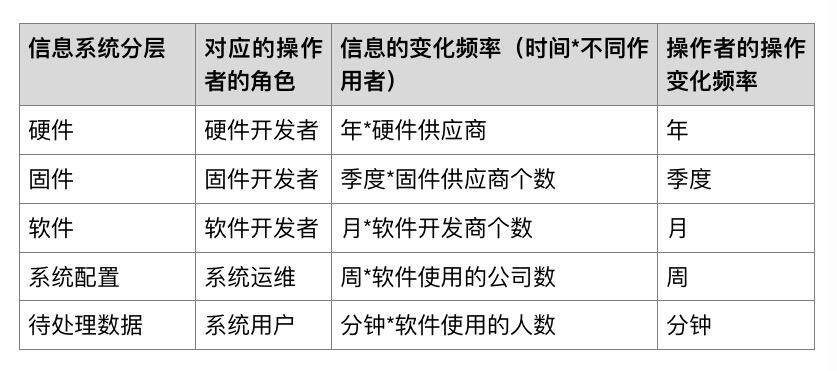
我们平常所使用的所有应用软件,如果从根本上看,都可以看作一种信息处理系统。人们跟这些系统的关系,无非是人输入信息处理的请求意图,经过信息处理系统的处理,系统返回一个输出结果给人。如果只考虑一个系统的使用者,似乎对系统的输入者只有系统用户和系统运维,运维人员负责配置信息系统,用户负责使用信息系统。然而考虑一个信息系统的整个生命周期,其实一个信息系统的构建者也对这个系统不断有输入。经过了多年的工业化、信息化的过程,一个信息系统的构建划分成了很多的阶段,同时一整个系统也可以划分成多个层次,从最低层到最上层,可以分为硬件、固件、软件、配置和数据几层信息。
在设计开发硬件的过程中,硬件设计者的意图固化在硬件中,在开发固件的过程中,固件设计者的意图固化在固件中,软件开发过程中软件开发者的意图固化在软件中,配置系统过程中系统运维人员的意图加载到系统中,用户输入数据进行处理时,用户的意图输入到系统中。自底向上,从硬件到数据,对应角色对信息系统发生作用的频率越来越高,信息有效作用的周期越来越短。越靠低层,信息固化得越稳定;越靠上层,信息的变化越灵活。
随着信息技术的不断发展,各个层次的界限越来越模糊,或者说,各个层次之间的关系越来越具有相对性。如果我们把系统下层叫做“平台”,系统上层叫做“应用”,这样说来,固件是跑在硬件上的“应用”,软件是跑在固件上的“应用”,配置是跑在软件上的“应用”,数据是跑在配置上的“应用”。如果我们把系统下层叫做“硬件”,系统上层叫做“软件”,这样说来,固件是跑在硬件上的“软件”,软件是跑在固件上的“软件”,配置是跑在软件上的“软件”,数据是跑在配置上的“软件”。这样,“平台”与“应用”的区别,或者说“硬件”与“软件”的区别,本质并不是用什么方式实现;而是相对来说,谁更稳定,谁更灵活,要想在上层灵活地做东西,必须要下层的稳定。
虚拟机、容器、基础设施即服务,和平台即服务
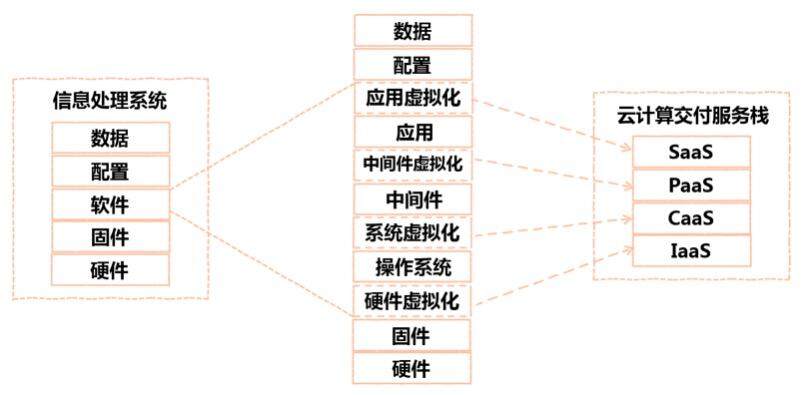
在信息系统的各个层次中,最起决定作用也是最智能的部分,是软件这个层次。传统的企业软件,主要有操作系统、中间件和应用 3 个层次。随着虚拟化和云计算技术的发展,各个层次都产生了虚拟化技术,或者说将其服务化的技术。在硬件和固件之上,产生了硬件虚拟化的技术,以下面的硬件资源为基础,虚拟化出虚拟计算机,对于上层,下层就像真实的很多个独立的物理机器一样。在操作系统上面,产生了系统虚拟化技术,对于上层,下层就像真实的很多个独立的操作系统一样。在中间件(例如 Web 应用中间件 Tomcat,数据库中间件 MySQL)上面,产生了中间件虚拟化技术,对于上层,下层就像真实的很多个独立的中间件服务一样。在应用上面,产生了应用虚拟化技术,对于上层,下层就像真实的很多个独立的应用软件一样。
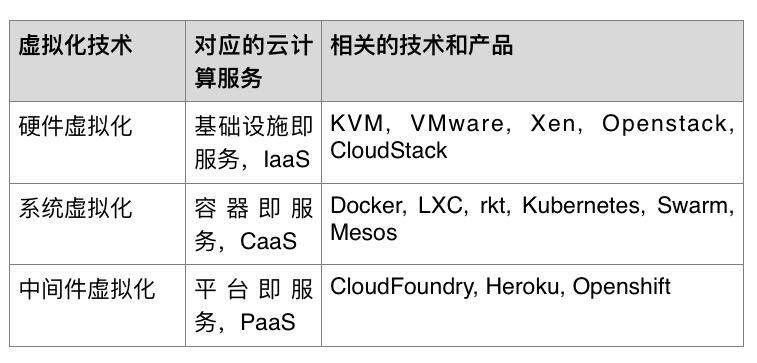
不同层次的虚拟化技术,正好对应不同层次的云计算服务交付方式。管理硬件虚拟化的云计算服务称为基础设施即服务 IaaS,管理系统虚拟化的云计算服务称为容器即服务 CaaS,管理中间件虚拟化的云计算服务称为平台即服务 PaaS,管理应用软件虚拟化的云计算服务称为软件即服务 SaaS。
请技术专家们原谅此处硬件虚拟化、系统虚拟化、中间件虚拟化和应用虚拟化这几个词汇的不严谨性。针对一些概念只可意会、不可言传的本质,作者这里主要是以类比的方式说明一些理念,没能追求概念的准确性。
(另一方面,作者是个唯名论者,而不是一个本体论者,即认为一个概念的名称的主要作用是为了好记,而且概念的名称一定跟上下文相关。应该尽量避免为了一个概念的本质涵义是什么而争论,特别是没有定义清楚上下文的情况下。而定义清楚上下文是一项十分繁芜而且无趣的工作,这也解释了,为什么当代的学术论文如此令常人敬而远之,为什么一些最聪明的人没有追求博士学位,以及一些最厉害的数学家和计算机科学家无法给同行解释清楚自己的证明。作者声明本文所有概念只在本文上下文范围内有效,希望即便如此,本文也能对一些人有所帮助。)
容器技术和容器即服务近两年因为 Docker 的崛起而在云计算领域独领风骚,有些人把基于容器的云计算服务归为 PaaS,有些人把它归为 IaaS;基本上来说,这就是介于 PaaS 和 IaaS 之间的服务,而且事实上证明,这一层服务有必要而且非常受欢迎,也就没有必要再纠结名字了。不同层次的云计算服务所相关的技术和产品见下表。
另一方面,就像前面提到的,“平台”和“应用”的概念可以是相对的,而 PaaS 和 SaaS 的概念,在实际中也可能是相对的。例如,一个建筑信息云平台系统,相对于通用的 PaaS 如 CloudFoundry 和 Openshift,它就是 SaaS;而它相对于建筑公司自己在上面运行的应用就是 PaaS。
云计算系统的弹性与伸缩性
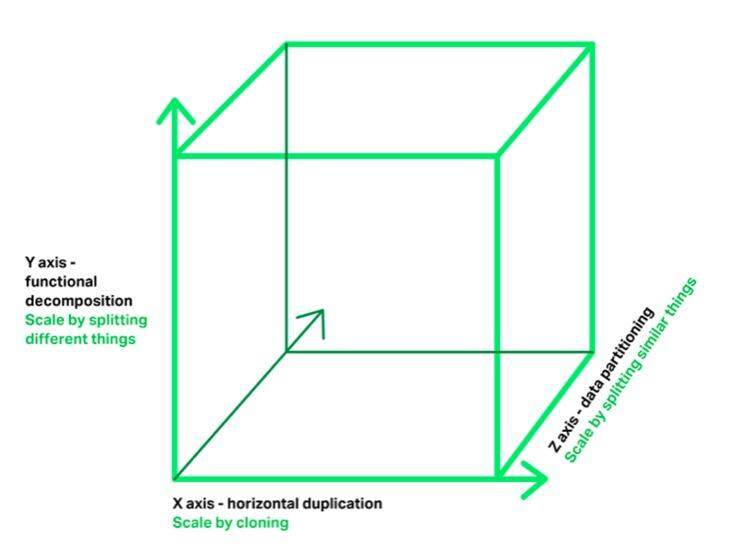
从云计算的定义出发,云计算系统一个基本特性就是计算能力的弹性和伸缩性。弹性和伸缩性的意思是能够根据实际的需要,随时增多或减少计算能力。弹性伸缩针对不同的处理对象,有不同的伸缩模式,如下图,分别处于 X、Y、Z 轴 3 个不同维度。
第一,对于同一类事物的无状态服务,数据不需要持久化,处理结果不需要保存在信息系统中,可以通过 X 轴计算实例的水平复制进行伸缩,这就是 Kubernetes 系统中 Replication Controller 和 ReplicaSet 所完成的功能;举例说明,一个电子商务系统的下订单服务,本身只是做订单处理但不存储数据的无状态服务,这个微服务就可以用水平复制的模式来伸缩。
第二,对于同一类事物的有状态服务,数据存储的内容各不相同,身份也各不相同,可以通过 Z 轴存储实例的数据分片进行伸缩,这就是 Kuberenetes 的 PetSet 或者 StatefulSet 所完成的功能;举例说明,下订单服务的订单数据存储在 MySQL 数据库中,要想增加订单数据存储的能力,就需要对针对订单数据库表进行数据分片。
第三,对于不同类别事物的处理,则需要通过 Y 轴的功能分割来进行伸缩,Y 轴的分割也称为垂直分割;举例说明,一个完整的电子商务系统,可以根据业务功能分割成用户管理、购物车管理、订单管理、产品目录管理、库存管理、支付管理、配送管理等多个独立的微服务。需要说明的是,功能分割(Y 轴)是水平复制(X 轴)和数据分片(Z 轴)的前提,只有通过功能分割解耦将不同的事物分割出来,才能针对同一事物进行水平复制或数据分片。
容器与微服务架构
功能分割的主要过程也就是微服务分割的过程。随着容器技术的风靡,微服务架构也成为软件技术领域的热门词汇。微服务架构的理念,是将一个完整的应用,按照业务拆分成彼此独立的模块以支撑服务的独立开发、部署和伸缩。微服务分割也就是业务功能分割。微服务分割和传统软件模块分割的一大区别是,微服务分割强调领域数据模型的分割,也就是数据存储服务的分割,以保证不同微服务之间没有持久化数据方面的依赖性,从而使得不同的微服务真正可以在运行时独立进行部署和伸缩。传统的软件模块分割,比较多的是考虑代码的重用性和各模块开发的独立性,但因为并没有为超高用户压力的弹性要求做准备,比较少考虑数据持久化层面的伸缩性。而如前所述,Y 轴业务功能分割是 Z 轴数据分片的前提,因此要想真正应对超高用户压力的弹性计算要求,进行业务功能分割是第一步。
微服务架构的理念,在以 Docker 为代表的容器技术风靡之前就已经存在,像亚马逊、Netflix 这些需要应对超高用户压力公司,早早就以微服务架构分割自己的应用,利用虚拟机技术部署自己的微服务。不过要利用微服务架构在系统弹性伸缩方面的好处,一个前提是每个服务实例仅部署一个微服务,避免不同微服务之间互相影响,而这在虚拟机时代,带来的开销是比较大的,特别是对于那些没有应对高用户压力需求的企业。一个传统的电商应用,按照微服务架构尽量拆分,可能拆分为 6 到 7 个服务;如果利用虚拟机部署,这 6 到 7 个服务运行都会附带虚拟机操作系统的开销,这对一个没有很大压力的应用来说,未免得不偿失。而容器技术,刚好解决了应用轻负载情况下的额外开销问题,使得分割后独立部署的微服务,与应用无关的额外资源开销很小,这就使得微服务架构有了如鱼得水的感觉。
云原生应用与 12 要素应用
一提到云原生应用,大家就一定会提到 12 要素应用包括本系列文章的第二篇,也详细解读了 12 要素。作为本系列文章的最后一篇,本文想对于概念采取灵活宽容的态度,正如前文所述,“应用”和“平台”可以理解为相对的概念。12 要素应用是 PaaS 平台 Heroku 提出的理念,其中很重要的一个理念,就是无状态化 Stateless。在 Heroku 团队的语境下,所有有状态服务都是其 Heroku“平台”提供的,而所有其客户的“应用”当然都应该是无状态的。另一方面,对于以私有云为基础的企业应用,或者是对某些有状态服务有特殊需求的应用,除了无状态服务,可能也需要自己构建特别的有状态服务,将这些有状态服务作为自己无状态服务的后台支撑服务(Backing Service)。
以 Kubernetes 容器平台为例,在其上可以构建高可用高可伸缩的有状态服务,例如 Redis、MySQL、MongoDB、Cassandra 等。如果在这种语境下,将 Kubernetes 作为“平台”,Redis、MySQL、MongoDB、Cassandra 这些作为应用,那这些应用则是有状态的。对于有状态服务(应用),如何实现云原生应用理念,还没有像 12 要素那样的公认标准,但可以确认的是 Kubernetes 平台已经开始在探索,特别是它的 StatefulSet(以前的 PetSet)对象就是专门为有状态服务而设计的。如果从“云原生”的基本定义出发,云原生应用是专门为部署在云平台而设计的,自带集群扩展伸缩能力,能够利用云平台的资源调度能力进行应用层集群扩展伸缩的应用,只要具备了这种动态伸缩能力,就可以称为云原生应用,随着 k8s 平台上 Redis、 MySQL、MongoDB 和 Cassandra 等有状态服务跟 StatefulSet 的深入集成,我们将可以更清晰地看出有状态的云原生应用的模式。
宠物、牲畜与机器人
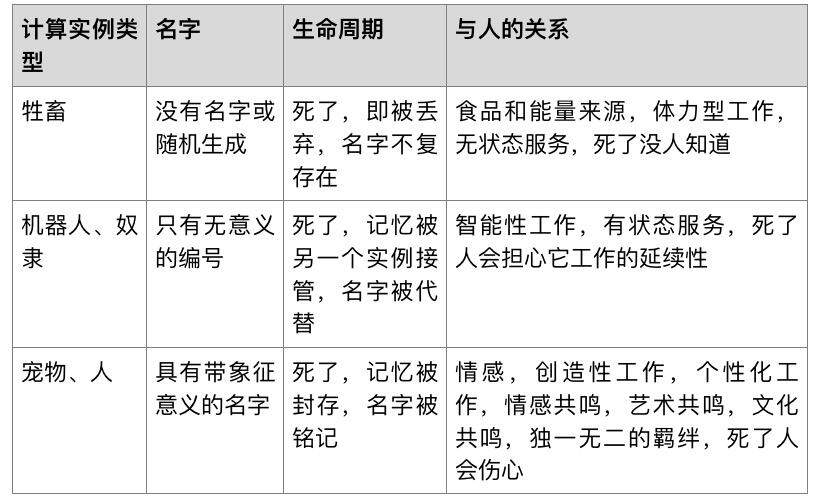
Kubernetes 是原生为生产环境而设计的平台,其一个原生的设计目标,就是让基于容器的为服务实例 Pod,全面取代虚拟机。虚拟机既可以提供无状态服务,也可以提供有状态服务,这也是 k8s 在有了 Replication Controller 和 ReplicaSet 之后,又持续推出 PetSet(或 StatefulSet)的原因。在云计算领域,一直有宠物和牲畜的比喻。那些有上万台物理服务器的云计算领军公司,比如谷歌和亚马逊,将自己的服务器比作牲畜,将一般企业悉心维护的计算机比作宠物。
宠物是有名字的,有记忆的,需要主人悉心照顾的;宠物死了,主人是要伤心流泪的。这就好像大多非云计算公司的计算机系统或虚拟机系统,运维人员要悉心维护,经常更新操作系统和用户密码,开放端口要申请审批,万一以外宕机了,运维人员要心疼的。牲畜则不一样,牲畜存在的唯一意义是提供肉制品和奶制品,牲畜不需要有名字,牲畜也没有记忆(至少主人不关心它有没有记忆),主人对牲畜是大规模集约化养殖,牲畜死了,只要不是传染病大规模死亡,主人是不会为它伤心的。这和谷歌亚马逊这些公司的情况类似,单独一台计算机出现故障的概率很低,但是在上万台计算机里出现一台故障的概率就很高。这些公司可不想因为一台计算机出现的故障而影响业务,所以一定要使系统能够自动化维护,对出现故障的计算机像处理牲畜尸体一样处理掉就算了。
在本系列文章主题介绍的 Kubernetes 系统,正是为自动化运维而设计的系统,因此其 Pod 从一开始就被设计成牲畜的角色;依靠 Replication Controller 和 Deployment 控制创建的 Pod,其名字是个随机 ID,没有人会记得这种名字,也可以说没有名字。这种 Pod 也是符合 12 要素应用模型的无状态服务实例,是没有记忆的。
不过 Kubernetes 系统的设计目标远不止无状态容器,还要支持有状态服务实例。因此,Kubernetes 引入了新的资源类型 PetSet,用来提供有状态服务。如本系列文章前文所述,PetSet 里的 Pod 有一个固定的编号和身份,对应固定的存储,一旦某个编号的 Pod 宕机,同样编号的 Pod 要被启动起来并挂在到同样的存储设备上,接替以前编号的 Pod 工作。以较真的角度说,“PetSet”这个名字是不贴切的,因为虽然 PetSet 是有状态的,但工程师设计这个资源,肯定不是为了要当宠物来照顾的。设计 PetSet 的唯一目的是要它能够持续干活,它所具备的名字,也不是一个真正有意义的名字,而仅仅是一个为了识别身份的编号而已。事实上,PetSet 里 Pod 不像一个宠物,而更像一个智能组织里的机器人或是奴隶。机器人死了,主人不会伤心,只会要一个同样的机器人来继承它的记忆,继续做同样的工作。因此说,PetSet 确实不是个贴切的名字,事实上,在最新的 Kubernetes 版本中,工程师们也确实认识到这点,正打算把它的名字改成 StatefulSet。
有关宠物与牲畜、机器人与人的概念,似乎从技术到哲学再到文艺都有相似比喻。宠物与人,是有灵魂的、有名字的,而牲畜与机器人是没有灵魂没有名字的,顶多有个编号。如果看过日本导演宫崎骏电影《千与千寻》,可能也记得里面的人物如果失去了名字,也就变成了牲畜或者只能给别人埋头工作的奴隶了。不同计算实例类型对应的特点比较见下表。
分布式状态管理系统的设计模式
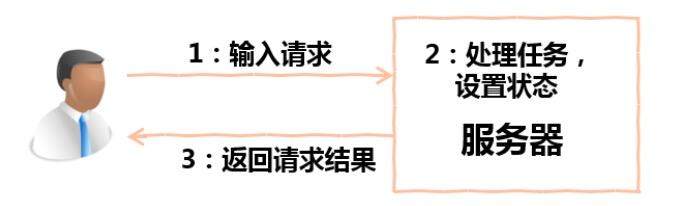
分布式系统的状态管理一直是个云计算领域的难题。在传统的服务器系统中,软件开发人员一直以同步操作的方式保证系统状态的一致性。对于只有单个计算机节点的系统,这样的方式是自然而然的。像下图这样的系统,用户输入配置,服务器处理请求,设置状态,等待状态设置完成返回配置结果,对于单个计算机节点的系统是合情合理的。
对于管理多个子系统的情况,加入仍然采取同步操作并返回状态的方式,如下图所示,有两种情况可能造成问题。第一,如果需要收集的字系统个数特别多,则非常有可能出现某一个或几个字系统联系不上或反映很慢的问题,这将造成管理服务器的返回很慢;第二,某些情况,子系统本身的状态转变就是很慢的,这将给管理服务器同步返回结果造成原生困难。事实上,在像 OpenStack 和 Kubernetes 这样的云平台管理系统中,需要处理很长时间的任务是大量存在的,比如 OpenStack 中启动虚拟机的任务和 Kubernetes 中调度大量 Pod 的任务。
(点击放大图像)

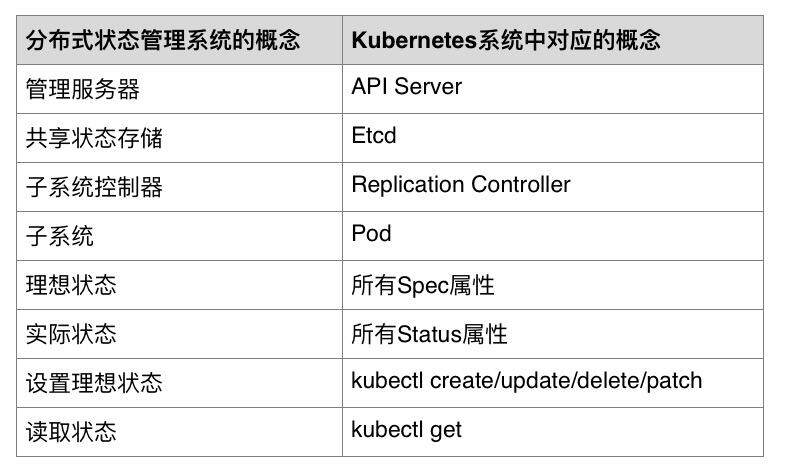
针对分布式系统的状态管理的这一问题,k8s 系统的设计中原生融入了谷歌多年来运维管理大型分布式系统的经验。对于每个管理的分布式对象,并不是仅仅有一个状态,而是有理想状态(例如k8s 中API 对象的Spec)和实际状态(例如k8s 中API 对象的Status)两种状态。如下图,用户输入设置理想状态后,管理服务器(例如k8s API Server)将理想状态存入到共享状态存储(例如Etcd)并通知子系统控制器(例如Replication Controller),然后马上将理想状态返回,而并不会等待实际状态的处理结果。系统中的子系统控制器,会不断从共享状态存储读取理想状态和实际状态,然后相应地控制对应集群中的子系统(例如Pod)。子系统再完成自己的处理任务后,会将自己的实际状态设置到共享状态存储。对于运维管理k8s 系统的用户,如果他想查看任何一个系统的实际状态,需要单独向管理服务发送读取状态的请求,管理服务器会将所请求对象的理想状态和实际状态一起返回给客户。
(点击放大图像)

在k8s 系统中,所有包含分布式状态的API 对象都以同样的模式设计,这使得在现有功能基础上不断创新增加新功能和新API 对象的方法变得非常直观,也使得k8s 的开发者和使用者理解系统的机制变得非常容易。能把这么复杂的分布式状态管理的问题总结出这么清晰直观的设计模式,在k8s 系统之前我几乎没有见到过。
容器设计模式和云原生应用架构的发展展望
前面介绍的是k8s 系统本身所应用的设计模式,此外,在本系列文章的前面几篇中,结合一些简单案例介绍了k8s 社区推出的针对应用的容器设计模式。云原生应用运行的环境都是复杂的分布式环境,在这种情况下,一些有用的设计模式可以起到四两拨千斤的作用。这些设计模式主要用来解决在分布环境中的一些通用问题,比如模块解耦的问题,主控节点选举的问题,并行处理任务调度的问题和在分布式系统中应用分治法的问题。与传统的面向对象设计模式的最明显地区别在于,容器设计模式是跨编程语言的,这个当然也来自于容器本身的编程语言无关性。
(点击放大图像)

在介绍这些容器设计模式的过程中,我们也对Metaparticle 项目窥豹一斑。Metapaticle 项目的目的在开发并展示一种基础设施即代码的编程模式,力图将基础设施管理逻辑和功能运算逻辑以同一种语言实现在同一短小精干的程序中。在分布式计算系统中,不仅功能性计算的逻辑是重要的,对计算系统的逻辑拓扑结构的控制也是重要的。大家可以想象,依靠流行大数据分析框架Hadoop MapReduce、Spark、Storm 和Flink 等进行分布式大数据运算,代码中往往包含逻辑拓扑结构的逻辑。
当然这些基础设施管理的逻辑能够交给应用开发者用代码管理的一个前提是,因为像Docker 和Kubernetes 这样的技术将部署和应用自动化运维管理的接口封装得如此得体而简单,使得应用开发者只需要编写一种声明式的编排文件,就可以得到自己想要的信息系统,或者说,应用开发者可以非常简单地向系统表达自己关于应用组合编排和基础设施管理的意图,并让系统按照自己的意图工作。
目前,基于Docker、Kubernetes、Ansible、Puppet、Chef、Jenkins 等一系列自动化工具系统,已经使得软件系统运维和开发过程变得异常地自动化和智能化,形成了将软件开发和运维一体化整合的DevOps 系统。DevOps 带来的自动化和智能化意味着减少人力成本和系统稳定,同时,也意味着向信息系统输入意图的开发人员减少。毕竟,信息系统是给用户使用的,是要满足用户的需求,体现用户的意图,因此,在整个系统的生命周期中,掺杂与用户无关的人的意图越少越好。
(点击放大图像)

如果我们回顾DevOps 得以实现的过程,其原因在于类似Docker、Kubernetes、Ansible、Python、Go、Jave、Scala、Groovy、Nodejs、Swift 等等这些软件工具和程序开发语言表达能力越来越强,同时也越来越简单易学易用,使得开发和运维两部分工作可以合二为一。假如我们将这样的智能工具向信息系统的下层和上层继续扩展;向下,使得硬件和固件也可以用相对高级简易的语言进行编程;向上,进一步让工具语言智能化和简单化,甚至发展到从用户自然语言实现自动编程,这样,普通用户对于系统来说也就和开发人员一样,而系统可以从用户处获取完整的用户意图,完全遵循最终用户的意图处理信息。我们可以称这样的系统为意图即代码系统,或者干脆称为人工智能系统,只不过这一系统不具有独立意识,完全按照用户的意图工作。
这里所说的完整的意图即代码系统固然还是畅想,但其实目前还是可以在某些领域看到一些技术对这一远景的靠近。例如向上,利用数据可视化的技术D3(Data Driven Document),用户只需要输入人人一看就懂的数据列表,就可以产生表意丰富而且支持互动的动态图表;再比如向下,已经有固件FPGA 系统支持用C 语言编程,相信在未来FPGA 技术像容器一样在云计算领域爆发流行的节点,很快会出现对更高级的编程语言的支持。总之,作为云计算系统的设计开发者,希望能开发出一站式解决用户需求的系统,给用户最大的灵活度同时让用户能以最简单的方式实现自己的意图。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。
活动推荐:
2023年9月3-5日,「QCon全球软件开发大会·北京站」 将在北京•富力万丽酒店举办。此次大会以「启航·AIGC软件工程变革」为主题,策划了大前端融合提效、大模型应用落地、面向 AI 的存储、AIGC 浪潮下的研发效能提升、LLMOps、异构算力、微服务架构治理、业务安全技术、构建未来软件的编程语言、FinOps 等近30个精彩专题。咨询购票可联系票务经理 18514549229(微信同手机号)。

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论