
拿 JSON 衬托 Protobuf 的文章真的太多了,经常可以看到文章中写道:“快来用 Protobuf 吧,JSON 太慢啦”。但是 Protobuf 真的有吹的那么牛么?我觉得从 JSON 切换到 Protobuf 怎么也得快一倍吧,要不然对不起付出的切换成本。然而,DSL-JSON 的家伙们居然说在 Java 语言里 JSON 和那些二进制的编解码格式有得一拼( https://blog.dsl-platform.com/improving-java-json-speed/ ),这太让人惊讶了!虽然你可能会说,咱们能不用苹果和梨来做比较了么?两个东西根本用途完全不一样好么。咱们用 Protobuf 是冲着跨语言无歧义的 IDL 的去的,才不仅仅是因为性能呢。好吧,这个我同意。但是仍然有那么多人盲目相信,Protobuf 一定会快很多,我觉得还是有必要彻底终结一下这个关于速度的传说。
DSL-JSON 的博客里只给了他们的测试结论,但是没有给出任何原因,以及优化的细节。这很难让人信服数据是真实的。你要说 JSON 比二进制格式更快,真的是很反直觉的事情。稍微琢磨一下这个问题,就可以列出好几个 Protobuf 应该更快的理由:
-
更容容易绑定值到对象的字段上。JSON 的字段是用字符串指定的,相比之下字符串比对应该比基于数字的字段 tag 更耗时。
-
JSON 是文本的格式,整数和浮点数应该更占空间而且更费时。
-
Protobuf 在正文前有一个大小或者长度的标记,而 JSON 必须全文扫描无法跳过不需要的字段。
但是仅凭这几点是不是就可以盖棺定论了呢?未必,也有相反的观点:
-
如果字段大部分是字符串,占到决定性因素的因素可能是字符串拷贝的速度,而不是解析的速度。在这个评测中( https://github.com/fabienrenaud/java-json-benchmark ),我们看到不少库的性能是非常接近的。这是因为测试数据中大部分是由字符串构成的。
-
影响解析速度的决定性因素是分支的数量。因为分支的存在,解析仍然是一个本质上串行的过程。虽然 Protobuf 里没有 [] 或者 {},但是仍然有类似的分支代码的存在。如果没有这些分支的存在,解析不过就是一个 memcpy 的操作而已。只有 Parabix 这样的技术才有革命性的意义,而 Protobuf 相比 JSON 只是改良而非革命。
-
也许 Protobuf 是一个理论上更快的格式,但是实现它的库并不一定就更快。这取决于优化做得好不好,如果有不必要的内存分配或者重复读取,实际的速度未必就快。
有多个 benchmark 都把 DSL-JSON 列到前三名里,有时甚至比其他的二进制编码更快。经过我仔细分析,原因出在了这些 benchmark 对于测试数据的构成选择上。因为构造测试数据很麻烦,所以一般评测只会对相同的测试数据,去测不同的库的实现。这样就使得结果是严重倾向于某种类型输入的。比如 https://github.com/eishay/jvm-serializers/wiki 选择的测试数据的结构是这样的
message Image { required string uri = 1; //url to the thumbnail optional string title = 2; //used in the html ALT required int32 width = 3; // of the image required int32 height = 4; // of the image enum Size { SMALL = 0; LARGE = 1; } required Size size = 5; // of the image (in relative terms, provided by cnbc for example) } message Media { required string uri = 1; //uri to the video, may not be an actual URL optional string title = 2; //used in the html ALT required int32 width = 3; // of the video required int32 height = 4; // of the video required string format = 5; //avi, jpg, youtube, cnbc, audio/mpeg formats ... required int64 duration = 6; //time in miliseconds required int64 size = 7; //file size optional int32 bitrate = 8; //video repeated string person = 9; //name of a person featured in the video enum Player { JAVA = 0; FLASH = 1; } required Player player = 10; //in case of a player specific media optional string copyright = 11;//media copyright } message MediaContent { repeated Image image = 1; required Media media = 2; }
无论怎么去构造 small/medium/large 的输入,benchmark 仍然是存在特定倾向性的。而且这种倾向性是不明确的。比如 medium 的输入,到底说明了什么?medium 对于不同的人来说,可能意味着完全不同的东西。所以,在这里我想改变一下游戏的规则。不去选择一个所谓的最现实的配比,而是构造一些极端的情况。这样,我们可以一目了然的知道,JSON 的强项和弱点都是什么。通过把这些缺陷放大出来,我们也就可以对最坏的情况有一个清晰的预期。具体在你的场景下性能差距是怎样的一个区间内,也可以大概预估出来。
好了,废话不多说了。JMH 撸起来。benchmark 的对象有以下几个:
-
Jackson: https://github.com/FasterXML/jackson-databind Java 程序里用的最多的 JSON 解析器。benchmark 中开启了 AfterBurner 的加速特性。
-
DSL-JSON: https://github.com/ngs-doo/dsl-json 世界上最快的 Java JSON 实现
-
Jsoniter: http://jsoniter.com/index.cn.html 我抄袭 DSL-JSON 写的实现。特别申明:我是 Jsoniter 的作者。这里提到的所有关于 Jsoniter 的评测数据都不应该被盲目相信。大部分的性能优化技巧是从 DSL-JSON 中直接抄来的。
-
Fastjson: https://github.com/alibaba/fastjson 在中国很流行的 JSON 解析器
-
Protobuf: https://github.com/google/protobuf 在 RPC (远程方法调用)里非常流行的二进制编解码格式
-
Thrift: https://thrift.apache.org 另外一个很流行的 RPC 编解码格式。这里 benchmark 的是 TCompactProtocol
Decode Integer
先从一个简单的场景入手。毫无疑问,Protobuf 非常擅长于处理整数
message PbTestObject { int32 field1 = 1; }
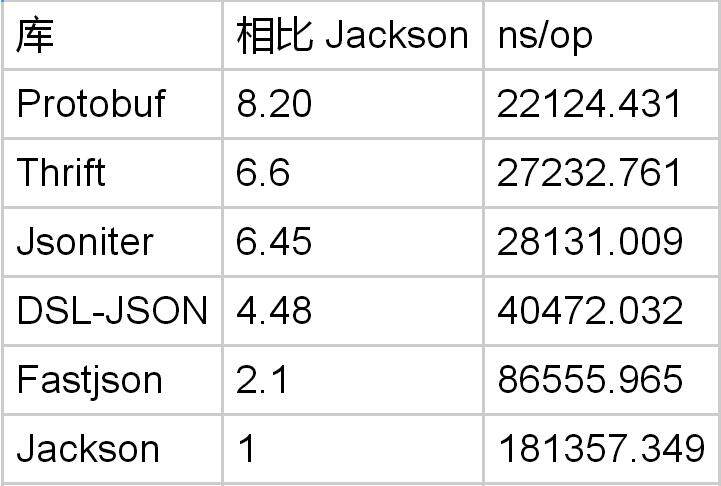
从结果上看,似乎优势非常明显。但是因为只有 1 个整数字段,所以可能整数解析的成本没有占到大头。所以,我们把测试调整对象调整为 10 个整数字段。再比比看
syntax = "proto3"; option optimize_for = SPEED; message PbTestObject { int32 field1 = 1; int32 field2 = 2; int32 field3 = 3; int32 field4 = 4; int32 field5 = 5; int32 field6 = 6; int32 field7 = 7; int32 field8 = 8; int32 field9 = 9; int32 field10 = 10; }
这下优势就非常明显了。毫无疑问,Protobuf 解析整数的速度是非常快的,能够达到 Jackson 的 8 倍。
DSL-JSON 比 Jackson 快很多,它的优化代码在这里 https://github.com/ngs-doo/dsl-json/blob/master/library/src/main/java/com/dslplatform/json/NumberConverter.java
private static int parsePositiveInt(final byte[] buf, final JsonReader reader, final int start, final int end, int i) throws IOException { int value = 0; for (; i < end; i++) { final int ind = buf[i] - 48; if (ind < 0 || ind > 9) { ... // abbreviated } value = (value << 3) + (value << 1) + ind; if (value < 0) { throw new IOException("Integer overflow detected at position: " + reader.positionInStream(end - start)); } } return value; }
整数是直接从输入的字节里计算出来的,公式是 value = (value << 3) + (value << 1) + ind; 相比读出字符串,然后调用 Integer.valueOf ,这个实现只遍历了一遍输入,同时也避免了内存分配。
Jsoniter 在这个基础上做了循环展开
... // abbreviated int i = iter.head; int ind2 = intDigits[iter.buf[i]]; if (ind2 == INVALID_CHAR_FOR_NUMBER) { iter.head = i; return ind; } int ind3 = intDigits[iter.buf[++i]]; if (ind3 == INVALID_CHAR_FOR_NUMBER) { iter.head = i; return ind * 10 + ind2; } int ind4 = intDigits[iter.buf[++i]]; if (ind4 == INVALID_CHAR_FOR_NUMBER) { iter.head = i; return ind * 100 + ind2 * 10 + ind3; } ... // abbreviated
Encode Integer
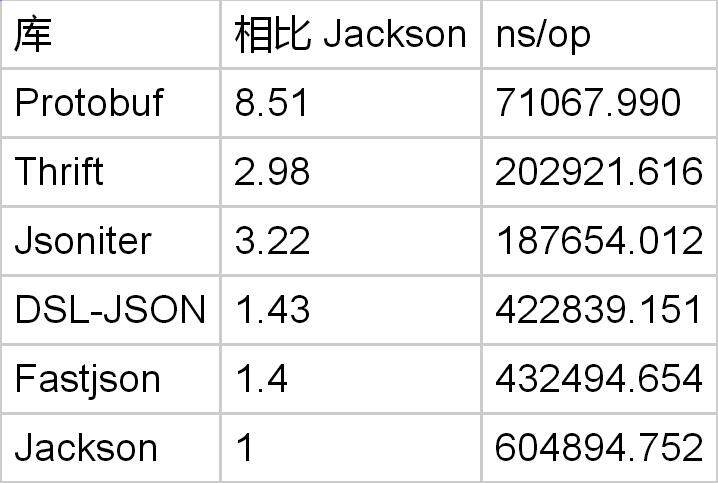
编码方面情况如何呢?和编码一样的测试数据,测试结果如下:
不知道为啥,Thrift 的序列化特别慢。而且别的 benchmark 里 Thrift 的序列化都是算慢的。我猜测应该是实现里有不够优化的地方吧,格式应该没问题。整数编码方面,Protobuf 是 Jackson 的 3 倍。但是和 DSL-JSON 比起来,好像没有快很多。
这是因为 DSL-JSON 使用了自己的优化方式,和 JDK 的官方实现不一样 https://github.com/ngs-doo/dsl-json/blob/master/library/src/main/java/com/dslplatform/json/NumberConverter.java
private static int serialize(final byte[] buf, int pos, final int value) { int i; if (value < 0) { if (value == Integer.MIN_VALUE) { for (int x = 0; x < MIN_INT.length; x++) { buf[pos + x] = MIN_INT[x]; } return pos + MIN_INT.length; } i = -value; buf[pos++] = MINUS; } else { i = value; } final int q1 = i / 1000; if (q1 == 0) { pos += writeFirstBuf(buf, DIGITS[i], pos); return pos; } final int r1 = i - q1 * 1000; final int q2 = q1 / 1000; if (q2 == 0) { final int v1 = DIGITS[r1]; final int v2 = DIGITS[q1]; int off = writeFirstBuf(buf, v2, pos); writeBuf(buf, v1, pos + off); return pos + 3 + off; } final int r2 = q1 - q2 * 1000; final long q3 = q2 / 1000; final int v1 = DIGITS[r1]; final int v2 = DIGITS[r2]; if (q3 == 0) { pos += writeFirstBuf(buf, DIGITS[q2], pos); } else { final int r3 = (int) (q2 - q3 * 1000); buf[pos++] = (byte) (q3 + '0'); writeBuf(buf, DIGITS[r3], pos); pos += 3; } writeBuf(buf, v2, pos); writeBuf(buf, v1, pos + 3); return pos + 6; }
这段代码的意思是比较令人费解的。不知道哪里就做了数字到字符串的转换了。过程是这样的,假设输入了 19823,会被分解为 19 和 823 两部分。然后有一个 DIGITS 的查找表,根据这个表把 19 翻译为 “19”,把 823 翻译为 “823”。其中 “823” 并不是三个 byte 分开来存的,而是把 bit 放到了一个 integer 里,然后在 writeBuf 的时候通过位移把对应的三个 byte 解开的
private static void writeBuf(final byte[] buf, final int v, int pos) { buf[pos] = (byte) (v >> 16); buf[pos + 1] = (byte) (v >> 8); buf[pos + 2] = (byte) v; }
这个实现比 JDK 自带的 Integer.toString 更快。因为查找表预先计算好了,节省了运行时的计算成本。
Decode Double
解析 JSON 的 Double 就更慢了。
message PbTestObject { double field1 = 1; double field2 = 2; double field3 = 3; double field4 = 4; double field5 = 5; double field6 = 6; double field7 = 7; double field8 = 8; double field9 = 9; double field10 = 10; }
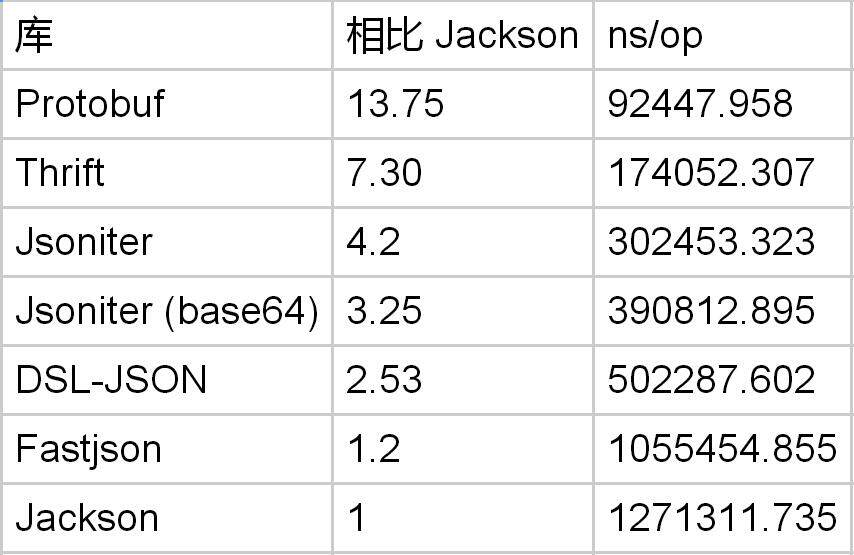
Protobuf 解析 double 是 Jackson 的 13 倍。毫无疑问,JSON 真的不适合存浮点数。
DSL-Json 中对 Double 也是做了特别优化的 https://github.com/ngs-doo/dsl-json/blob/master/library/src/main/java/com/dslplatform/json/NumberConverter.java
private static double parsePositiveDouble(final byte[] buf, final JsonReader reader, final int start, final int end, int i) throws IOException { long value = 0; byte ch = ' '; for (; i < end; i++) { ch = buf[i]; if (ch == '.') break; final int ind = buf[i] - 48; value = (value << 3) + (value << 1) + ind; if (ind < 0 || ind > 9) { return parseDoubleGeneric(reader.prepareBuffer(start), end - start, reader); } } if (i == end) return value; else if (ch == '.') { i++; long div = 1; for (; i < end; i++) { final int ind = buf[i] - 48; div = (div << 3) + (div << 1); value = (value << 3) + (value << 1) + ind; if (ind < 0 || ind > 9) { return parseDoubleGeneric(reader.prepareBuffer(start), end - start, reader); } } return value / (double) div; } return value; }
浮点数被去掉了点,存成了 long 类型,然后再除以对应的 10 的倍数。如果输入是 3.1415,则会变成 31415/10000。
Encode Double
把 double 编码为文本格式就更困难了。
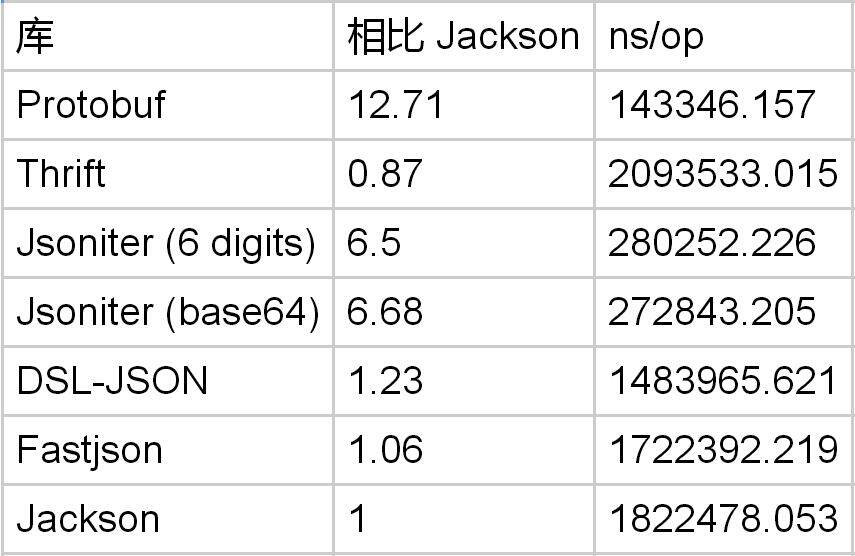
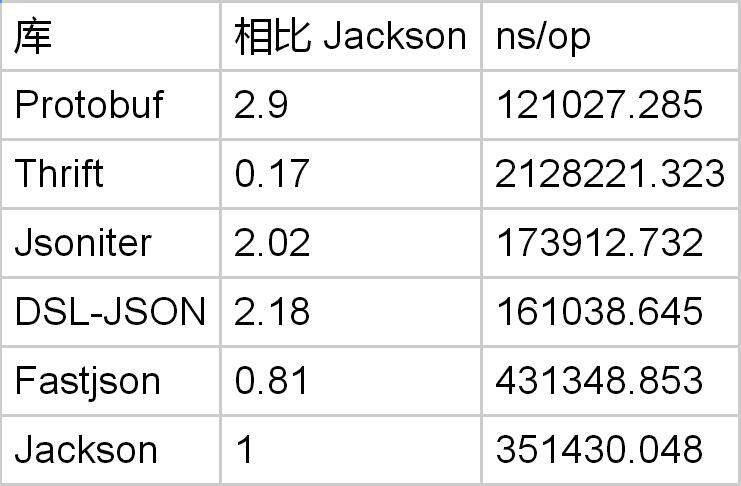
解码 double 的时候,Protobuf 是 Jackson 的 13 倍。如果你愿意牺牲精度的话, Jsoniter 可以选择只保留 6 位小数。在这个取舍下,可以好一些,但是 Protobuf 仍然是 Jsoniter 的两倍。
保留 6 位小数的代码是这样写的。把 double 的处理变成了长整数的处理。
if (val < 0) { val = -val; stream.write('-'); } if (val > 0x4ffffff) { stream.writeRaw(Double.toString(val)); return; } int precision = 6; int exp = 1000000; // 6 long lval = (long)(val * exp + 0.5); stream.writeVal(lval / exp); long fval = lval % exp; if (fval == 0) { return; } stream.write('.'); if (stream.buf.length - stream.count < 10) { stream.flushBuffer(); } for (int p = precision - 1; p > 0 && fval < POW10[p]; p--) { stream.buf[stream.count++] = '0'; } stream.writeVal(fval); while(stream.buf[stream.count-1] == '0') { stream.count--; }
到目前来看,我们可以说 JSON 不是为数字设计的。如果你使用的是 Jackson,切换到 Protobuf 的话可以把数字的处理速度提高 10 倍。然而 DSL-Json 做的优化可以把这个性能差距大幅缩小,解码在 3x ~ 4x 之间,编码在 1.3x ~ 2x 之间(前提是牺牲 double 的编码精度)。
因为 JSON 处理 double 非常慢。所以 Jsoniter 提供了一种把 double 的 IEEE 754 的二进制表示(64 个 bit)用 base64 编码之后保存的方案。如果希望提高速度,但是又要保持精度,可以使用 Base64FloatSupport.enableEncodersAndDecoders();
long bits = Double.doubleToRawLongBits(number.doubleValue()); Base64.encodeLongBits(bits, stream); static void encodeLongBits(long bits, JsonStream stream) throws IOException { int i = (int) bits; byte b1 = BA[(i >>> 18) & 0x3f]; byte b2 = BA[(i >>> 12) & 0x3f]; byte b3 = BA[(i >>> 6) & 0x3f]; byte b4 = BA[i & 0x3f]; stream.write((byte)'"', b1, b2, b3, b4); bits = bits >>> 24; i = (int) bits; b1 = BA[(i >>> 18) & 0x3f]; b2 = BA[(i >>> 12) & 0x3f]; b3 = BA[(i >>> 6) & 0x3f]; b4 = BA[i & 0x3f]; stream.write(b1, b2, b3, b4); bits = (bits >>> 24) << 2; i = (int) bits; b1 = BA[i >> 12]; b2 = BA[(i >>> 6) & 0x3f]; b3 = BA[i & 0x3f]; stream.write(b1, b2, b3, (byte)'"'); }
对于 0.123456789 就变成了 “OWNfmt03P78”
Decode Object
我们已经看到了 JSON 在处理数字方面的笨拙丑态了。在处理对象绑定方面,是不是也一样不堪?前面的 benchmark 结果那么差和按字段做绑定是不是有关系?毕竟我们有 10 个字段要处理那。这就来看看在处理字段方面的效率问题。
为了让比较起来公平一些,我们使用很短的 ascii 编码的字符串作为字段的值。这样字符串拷贝的成本大家都差不到哪里去。所以性能上要有差距,必然是和按字段绑定值有关系。
message PbTestObject { string field1 = 1; }
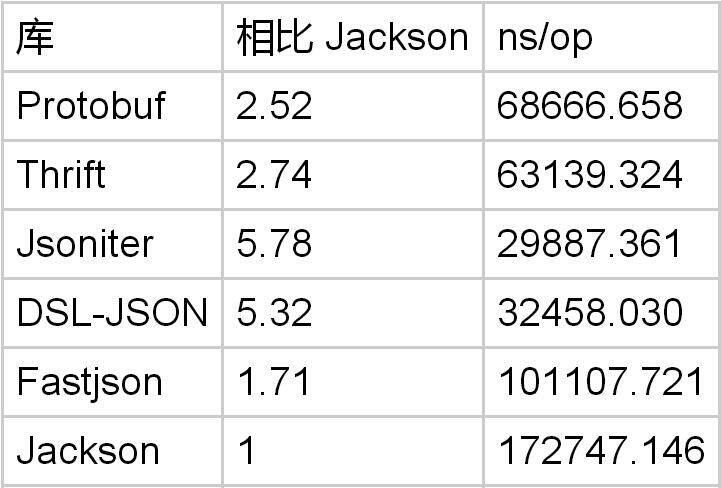
如果只有一个字段,Protobuf 是 Jackson 的 2.5 倍。但是比 DSL-JSON 要慢。
我们再把同样的实验重复几次,分别对应 5 个字段,10 个字段的情况。
message PbTestObject { string field1 = 1; string field2 = 2; string field3 = 3; string field4 = 4; string field5 = 5; }
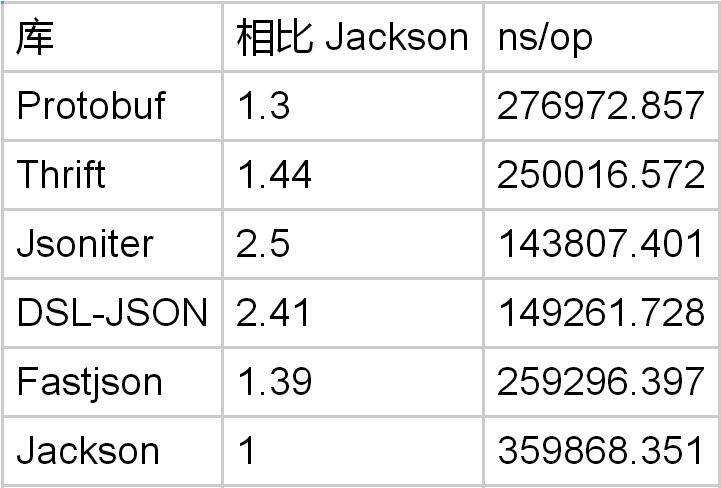
在有 5 个字段的情况下,Protobuf 仅仅是 Jackson 的 1.3x 倍。如果你认为 JSON 对象绑定很慢,而且会决定 JSON 解析的整体性能。对不起,你错了。
message PbTestObject { string field1 = 1; string field2 = 2; string field3 = 3; string field4 = 4; string field5 = 5; string field6 = 6; string field7 = 7; string field8 = 8; string field9 = 9; string field10 = 10; }
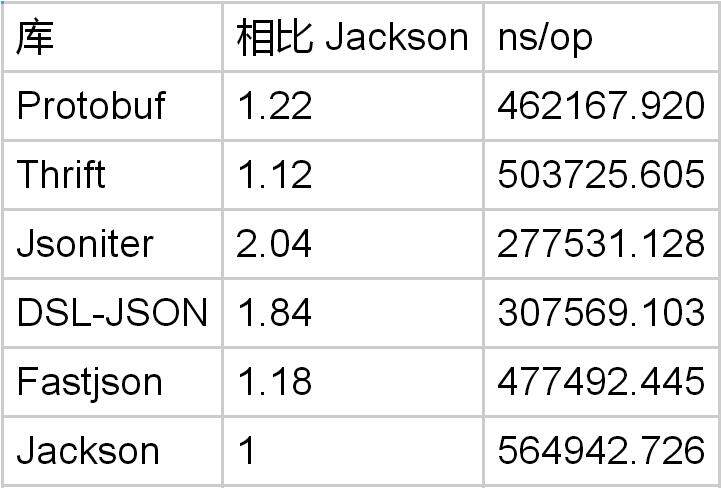
把字段数量加到了 10 个之后,Protobuf 仅仅是 Jackson 的 1.22 倍了。看到这里,你应该懂了吧。
Protobuf 在处理字段绑定的时候,用的是 switch case:
boolean done = false; while (!done) { int tag = input.readTag(); switch (tag) { case 0: done = true; break; default: { if (!input.skipField(tag)) { done = true; } break; } case 10: { java.lang.String s = input.readStringRequireUtf8(); field1_ = s; break; } case 18: { java.lang.String s = input.readStringRequireUtf8(); field2_ = s; break; } case 26: { java.lang.String s = input.readStringRequireUtf8(); field3_ = s; break; } case 34: { java.lang.String s = input.readStringRequireUtf8(); field4_ = s; break; } case 42: { java.lang.String s = input.readStringRequireUtf8(); field5_ = s; break; } } }
这个实现比 Hashmap 来说,仅仅是稍微略快而已。DSL-JSON 的实现是先 hash,然后也是类似的分发的方式:
switch(nameHash) { case 1212206434: _field1_ = com.dslplatform.json.StringConverter.deserialize(reader); nextToken = reader.getNextToken(); break; case 1178651196: _field3_ = com.dslplatform.json.StringConverter.deserialize(reader); nextToken = reader.getNextToken(); break; case 1195428815: _field2_ = com.dslplatform.json.StringConverter.deserialize(reader); nextToken = reader.getNextToken(); break; case 1145095958: _field5_ = com.dslplatform.json.StringConverter.deserialize(reader); nextToken = reader.getNextToken(); break; case 1161873577: _field4_ = com.dslplatform.json.StringConverter.deserialize(reader); nextToken = reader.getNextToken(); break; default: nextToken = reader.skip(); break; } {1}
使用的 hash 算法是 FNV-1a。
long hash = 0x811c9dc5; while (ci < buffer.length) { final byte b = buffer[ci++]; if (b == '"') break; hash ^= b; hash *= 0x1000193; }
是 hash 就会碰撞,所以用起来需要小心。如果输入很有可能包含未知的字段,则需要放弃速度选择匹配之后再查一下字段是不是严格相等的。 Jsoniter 有一个解码模式 DYNAMIC_MODE_AND_MATCH_FIELD_STRICTLY,它可以产生下面这样的严格匹配的代码:
switch (field.len()) { case 6: if (field.at(0) == 102 && field.at(1) == 105 && field.at(2) == 101 && field.at(3) == 108 && field.at(4) == 100) { if (field.at(5) == 49) { obj.field1 = (java.lang.String) iter.readString(); continue; } if (field.at(5) == 50) { obj.field2 = (java.lang.String) iter.readString(); continue; } if (field.at(5) == 51) { obj.field3 = (java.lang.String) iter.readString(); continue; } if (field.at(5) == 52) { obj.field4 = (java.lang.String) iter.readString(); continue; } if (field.at(5) == 53) { obj.field5 = (java.lang.String) iter.readString(); continue; } } break; } iter.skip();
即便是严格匹配,速度上也是有保证的。DSL-JSON 也有选项,可以在 hash 匹配之后额外加一次字符串 equals 检查。
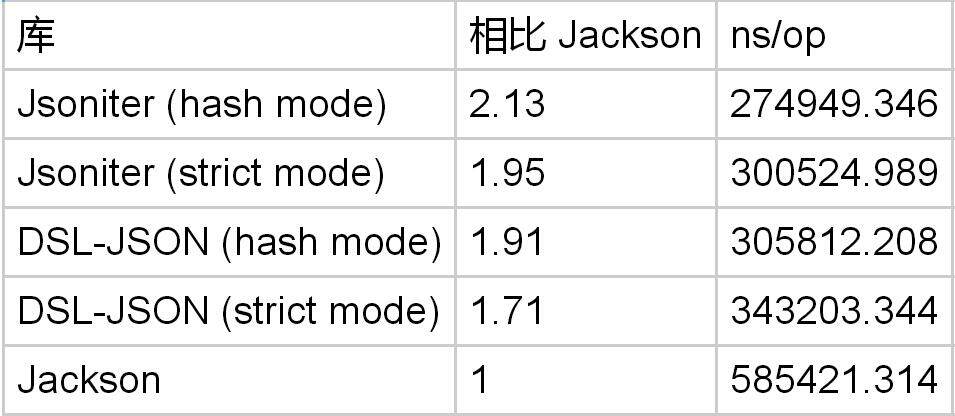
关于对象绑定来说,只要字段名不长,基于数字的 tag 分发并不会比 JSON 具有明显优势,即便是相比最慢的 Jackson 来说也是如此。
Encode Object
废话不多说了,直接比较一下三种字段数量情况下,编码的速度
只有 1 个字段
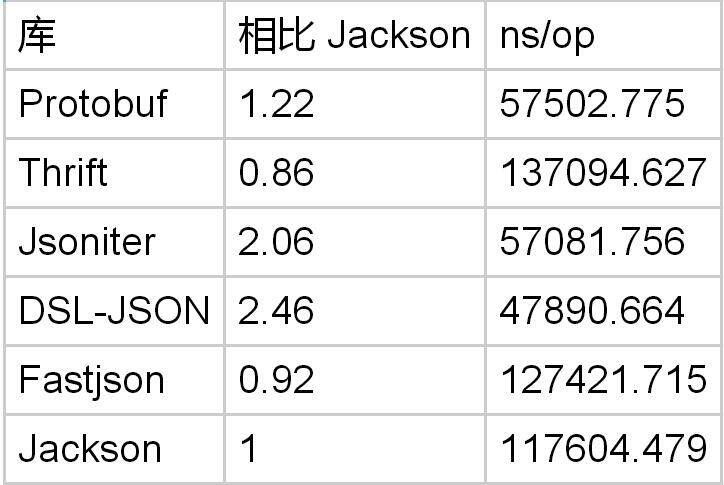
有 5 个字段
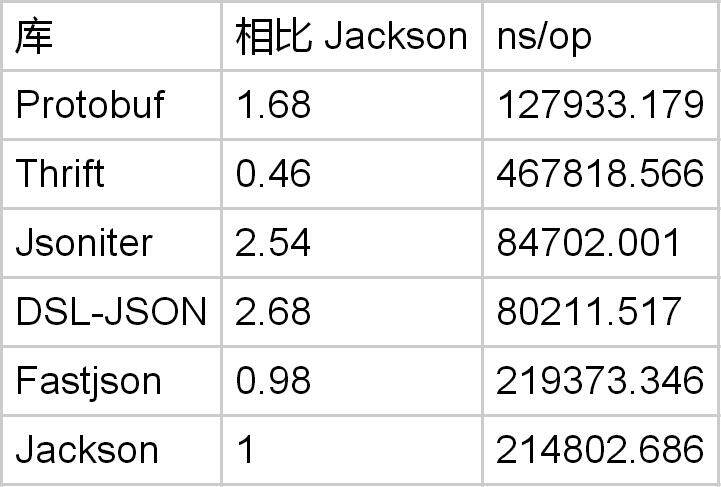
有 10 个字段
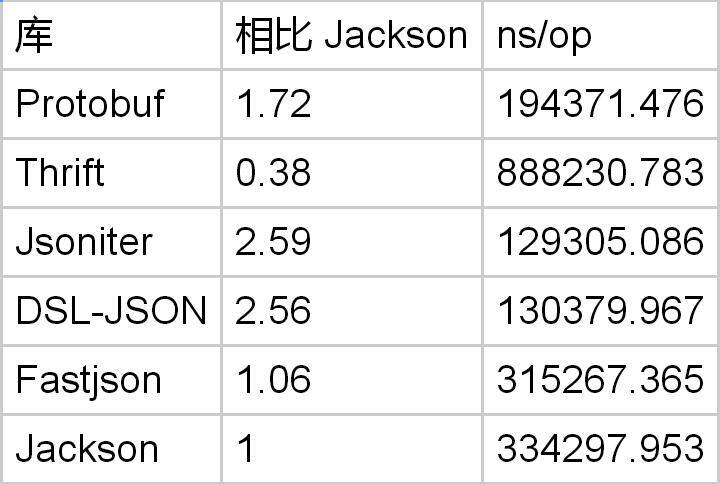
对象编码方面,Protobuf 是 Jackson 的 1.7 倍。但是速度其实比 DSL-Json 还要慢。
优化对象编码的方式是,一次性尽可能多的把控制类的字节写出去。
public void encode(Object obj, com.jsoniter.output.JsonStream stream) throws java.io.IOException { if (obj == null) { stream.writeNull(); return; } stream.write((byte)'{'); encode_((com.jsoniter.benchmark.with_1_string_field.TestObject)obj, stream); stream.write((byte)'}'); } public static void encode_(com.jsoniter.benchmark.with_1_string_field.TestObject obj, com.jsoniter.output.JsonStream stream) throws java.io.IOException { boolean notFirst = false; if (obj.field1 != null) { if (notFirst) { stream.write(','); } else { notFirst = true; } stream.writeRaw("\"field1\":", 9); stream.writeVal((java.lang.String)obj.field1); } }
可以看到我们把 “field1”: 作为一个整体写出去了。如果我们知道字段是非空的,则可以进一步的把字符串的双引号也一起合并写出去。
public void encode(Object obj, com.jsoniter.output.JsonStream stream) throws java.io.IOException { if (obj == null) { stream.writeNull(); return; } stream.writeRaw("{\"field1\":\"", 11); encode_((com.jsoniter.benchmark.with_1_string_field.TestObject)obj, stream); stream.write((byte)'\"', (byte)'}'); } public static void encode_(com.jsoniter.benchmark.with_1_string_field.TestObject obj, com.jsoniter.output.JsonStream stream) throws java.io.IOException { com.jsoniter.output.CodegenAccess.writeStringWithoutQuote((java.lang.String)obj.field1, stream); }
从对象的编解码的 benchmark 结果可以看出,Protobuf 在这个方面仅仅比 Jackson 略微强一些,而比 DSL-Json 要慢。
Decode Integer List
Protobuf 对于整数列表有特别的支持,可以打包存储
22 // tag (field number 4, wire type 2) 06 // payload size (6 bytes) 03 // first element (varint 3) 8E 02 // second element (varint 270) 9E A7 05 // third element (varint 86942) 设置 [packed=true] message PbTestObject { repeated int32 field1 = 1 [packed=true]; }
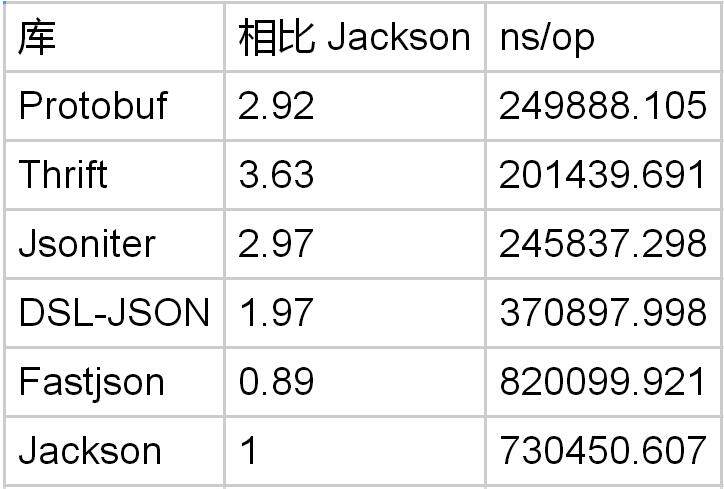
对于整数列表的解码,Protobuf 是 Jackson 的 3 倍。然而比 DSL-Json 的优势并不明显。
在 Jsoniter 里,解码的循环被展开了:
public static java.lang.Object decode_(com.jsoniter.JsonIterator iter) throws java.io.IOException { java.util.ArrayList col = (java.util.ArrayList)com.jsoniter.CodegenAccess.resetExistingObject(iter); if (iter.readNull()) { com.jsoniter.CodegenAccess.resetExistingObject(iter); return null; } if (!com.jsoniter.CodegenAccess.readArrayStart(iter)) { return col == null ? new java.util.ArrayList(0): (java.util.ArrayList)com.jsoniter.CodegenAccess.reuseCollection(col); } Object a1 = java.lang.Integer.valueOf(iter.readInt()); if (com.jsoniter.CodegenAccess.nextToken(iter) != ',') { java.util.ArrayList obj = col == null ? new java.util.ArrayList(1): (java.util.ArrayList)com.jsoniter.CodegenAccess.reuseCollection(col); obj.add(a1); return obj; } Object a2 = java.lang.Integer.valueOf(iter.readInt()); if (com.jsoniter.CodegenAccess.nextToken(iter) != ',') { java.util.ArrayList obj = col == null ? new java.util.ArrayList(2): (java.util.ArrayList)com.jsoniter.CodegenAccess.reuseCollection(col); obj.add(a1); obj.add(a2); return obj; } Object a3 = java.lang.Integer.valueOf(iter.readInt()); if (com.jsoniter.CodegenAccess.nextToken(iter) != ',') { java.util.ArrayList obj = col == null ? new java.util.ArrayList(3): (java.util.ArrayList)com.jsoniter.CodegenAccess.reuseCollection(col); obj.add(a1); obj.add(a2); obj.add(a3); return obj; } Object a4 = java.lang.Integer.valueOf(iter.readInt()); java.util.ArrayList obj = col == null ? new java.util.ArrayList(8): (java.util.ArrayList)com.jsoniter.CodegenAccess.reuseCollection(col); obj.add(a1); obj.add(a2); obj.add(a3); obj.add(a4); while (com.jsoniter.CodegenAccess.nextToken(iter) == ',') { obj.add(java.lang.Integer.valueOf(iter.readInt())); } return obj; }
对于成员比较少的情况,这样搞可以避免数组的扩容带来的内存拷贝。
Encode Integer List
Protobuf 在编码数组的时候应该有优势,不用写那么多逗号出来嘛。
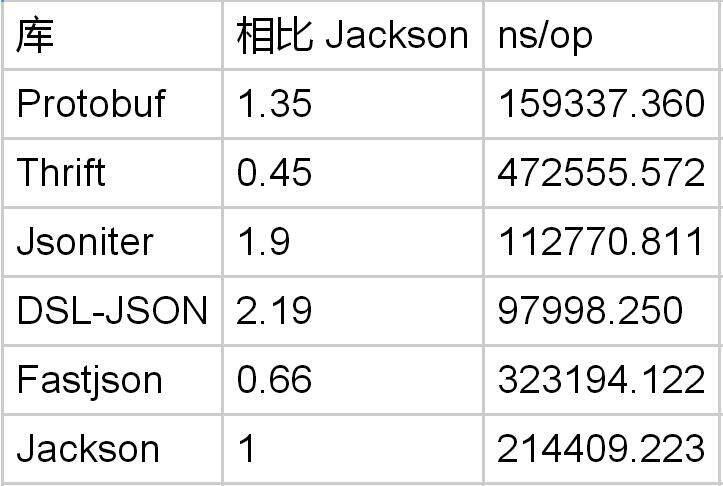
Protobuf 在编码整数列表的时候,仅仅是 Jackson 的 1.35 倍。虽然 Protobuf 在处理对象的整数字段的时候优势明显,但是在处理整数的列表时却不是如此。在这个方面,DSL-Json 没有特殊的优化,性能的提高纯粹只是因为单个数字的编码速度提高了。
Decode Object List
列表经常用做对象的容器。测试这种两种容器组合嵌套的场景,也很有代表意义。
message PbTestObject { message ElementObject { string field1 = 1; } repeated ElementObject field1 = 1; }
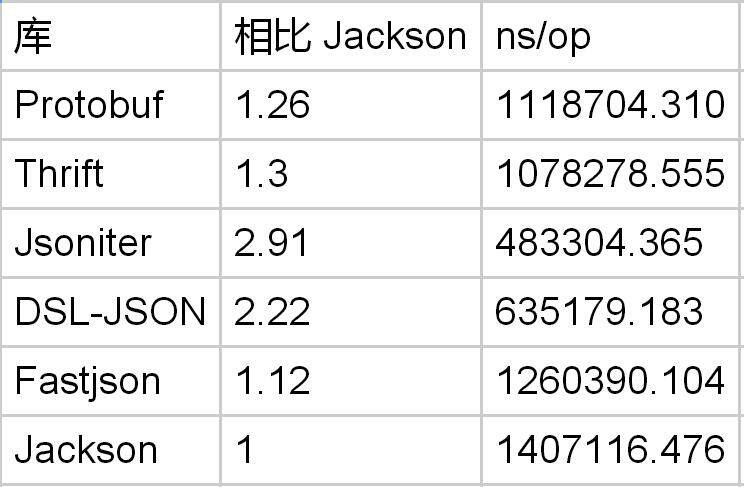
Protobuf 处理对象列表是 Jackson 的 1.3 倍。但是不及 DSL-JSON。
Encode Object List
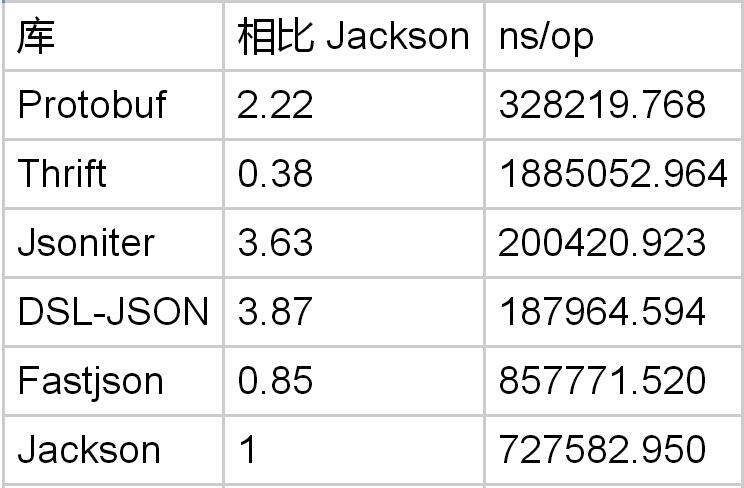
Protobuf 处理对象列表的编码速度是 Jackson 的 2 倍。但是 DSL-JSON 仍然比 Protobuf 更快。似乎 Protobuf 在处理列表的编码解码方面优势不明显。
Decode Double Array
Java 的数组有点特殊,double[] 是比 List
message PbTestObject { repeated double field1 = 1 [packed=true]; }
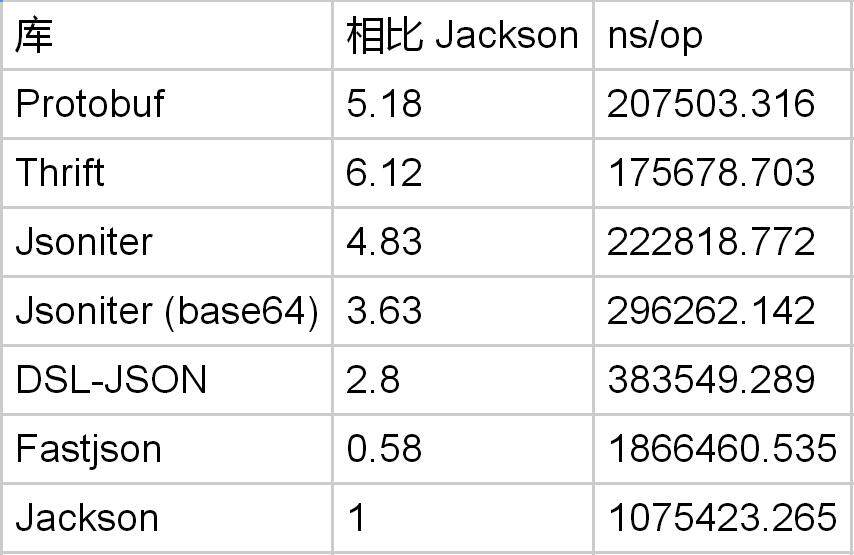
Protobuf 在处理 double 数组方面,Jackson 与之的差距被缩小为 5 倍。Protobuf 与 DSL-JSON 相比,优势已经不明显了。所以如果你有很多的 double 数值需要处理,这些数值必须是在对象的字段上,才会引起性能的巨大差别,对于数组里的 double,优势差距被缩小。
在 Jsoniter 里,处理数组的循环也是被展开的。
public static java.lang.Object decode_(com.jsoniter.JsonIterator iter) throws java.io.IOException { ... // abbreviated nextToken = com.jsoniter.CodegenAccess.nextToken(iter); if (nextToken == ']') { return new double[0]; } com.jsoniter.CodegenAccess.unreadByte(iter); double a1 = iter.readDouble(); if (!com.jsoniter.CodegenAccess.nextTokenIsComma(iter)) { return new double[]{ a1 }; } double a2 = iter.readDouble(); if (!com.jsoniter.CodegenAccess.nextTokenIsComma(iter)) { return new double[]{ a1, a2 }; } double a3 = iter.readDouble(); if (!com.jsoniter.CodegenAccess.nextTokenIsComma(iter)) { return new double[]{ a1, a2, a3 }; } double a4 = (double) iter.readDouble(); if (!com.jsoniter.CodegenAccess.nextTokenIsComma(iter)) { return new double[]{ a1, a2, a3, a4 }; } double a5 = (double) iter.readDouble(); double[] arr = new double[10]; arr[0] = a1; arr[1] = a2; arr[2] = a3; arr[3] = a4; arr[4] = a5; int i = 5; while (com.jsoniter.CodegenAccess.nextTokenIsComma(iter)) { if (i == arr.length) { double[] newArr = new double[arr.length * 2]; System.arraycopy(arr, 0, newArr, 0, arr.length); arr = newArr; } arr[i++] = iter.readDouble(); } double[] result = new double[i]; System.arraycopy(arr, 0, result, 0, i); return result; }
这避免了数组扩容的开销。
Encode Double Array
再来看看 double 数组的编码
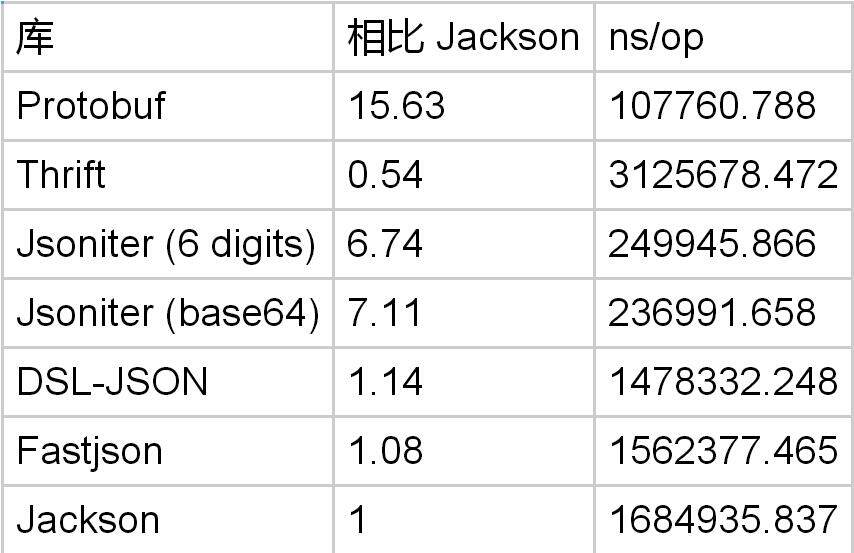
Protobuf 可以飞快地对 double 数组进行编码,是 Jackson 的 15 倍。在牺牲精度的情况下,Protobuf 只是 Jsoniter 的 2.3 倍。所以,再次证明了,JSON 处理 double 非常慢。如果用 base64 编码 double,则可以保持精度,速度和牺牲精度时一样。
Decode String
JSON 字符串包含了转义字符的支持。Protobuf 解码字符串仅仅是一个内存拷贝。理应更快才对。被测试的字符串长度是 160 个字节的 ascii。
syntax = "proto3"; option optimize_for = SPEED; message PbTestObject { string field1 = 1; }
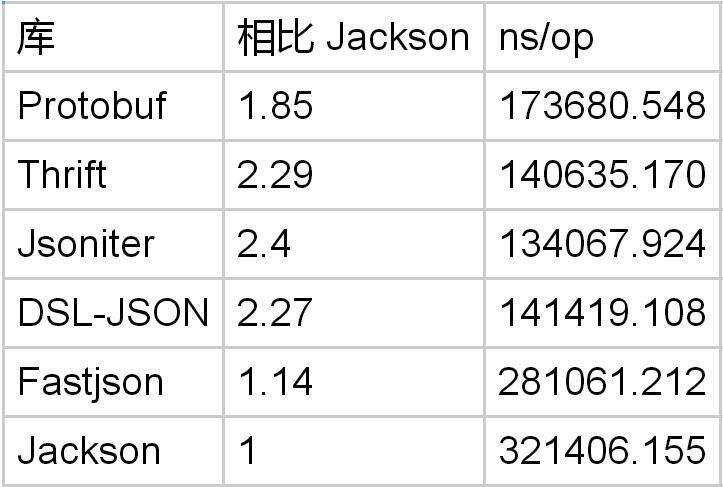
Protobuf 解码长字符串是 Jackson 的 1.85 倍。然而,DSL-Json 比 Protobuf 更快。这就有点奇怪了,JSON 的处理负担更重,为什么会更快呢?
先尝试捷径
DSL-JSON 给 ascii 实现了一个捷径: https://github.com/ngs-doo/dsl-json/blob/master/library/src/main/java/com/dslplatform/json/JsonReader.java
for (int i = 0; i < chars.length; i++) { bb = buffer[ci++]; if (bb == '"') { currentIndex = ci; return i; } // If we encounter a backslash, which is a beginning of an escape sequence // or a high bit was set - indicating an UTF-8 encoded multibyte character, // there is no chance that we can decode the string without instantiating // a temporary buffer, so quit this loop if ((bb ^ '\\') < 1) break; chars[i] = (char) bb; }
这个捷径里规避了处理转义字符和 utf8 字符串的成本。
JVM 的动态编译做了特殊优化
在 JDK9 之前,java.lang.String 都是基于 char\[\] 的。而输入都是 byte[] 并且是 utf-8 编码的。所以这使得,我们不能直接用 memcpy 的方式来处理字符串的解码问题。
但是在 JDK9 里,java.lang.String 已经改成了基于byte\[\]的了。从 JDK9 的源代码里可以看出:
@Deprecated(since="1.1") public String(byte ascii[], int hibyte, int offset, int count) { checkBoundsOffCount(offset, count, ascii.length); if (count == 0) { this.value = "".value; this.coder = "".coder; return; } if (COMPACT_STRINGS && (byte)hibyte == 0) { this.value = Arrays.copyOfRange(ascii, offset, offset + count); this.coder = LATIN1; } else { hibyte <<= 8; byte[] val = StringUTF16.newBytesFor(count); for (int i = 0; i < count; i++) { StringUTF16.putChar(val, i, hibyte | (ascii[offset++] & 0xff)); } this.value = val; this.coder = UTF16; } }
使用这个虽然被废弃,但是还没有被删除的构造函数,我们可以使用 Arrays.copyOfRange 来直接构造 java.lang.String 了。然而,在测试之后,发现这个实现方式并没有比 DSL-JSON 的实现更快。
似乎 JVM 的 Hotspot 动态编译时对这段循环的代码做了模式匹配,识别出了更高效的实现方式。即便是在 JDK9 使用 +UseCompactStrings 的前提下,理论上来说本应该更慢的 byte[] => char[] => byte[] 并没有使得这段代码变慢,DSL-JSON 的实现还是最快的。
如果输入大部分是字符串,这个优化就变得至关重要了。Java 里的解析艺术,还不如说是字节拷贝的艺术。JVM 的 java.lang.String 设计实在是太愚蠢了。在现代一点的语言中,比如 Go,字符串都是基于 utf-8 byte[] 的。
Encode String
类似的问题,因为需要把 char[] 转换为 byte[],所以没法直接内存拷贝。
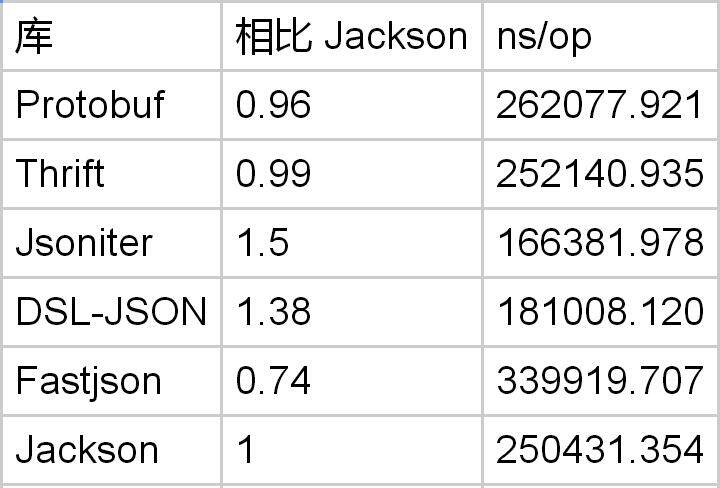
Protobuf 在编码长字符串时,比 Jackson 略微快一点点。一切都归咎于 char[]。
跳过数据结构
JSON 是一个没有 header 的格式。因为没有 header,JSON 需要扫描每个字节才可以定位到所需的字段上。中间可能要扫过很多不需要处理的字段。
message PbTestWriteObject { repeated string field1 = 1; message Field2 { repeated string field1 = 1; repeated string field2 = 2; repeated string field3 = 3; } Field2 field2 = 2; string field3 = 3; } message PbTestReadObject { string field3 = 3; }
消息用 PbTestWriteObject 来编码,然后用 PbTestReadObject 来解码。field1 和 field2 的内容应该被跳过。
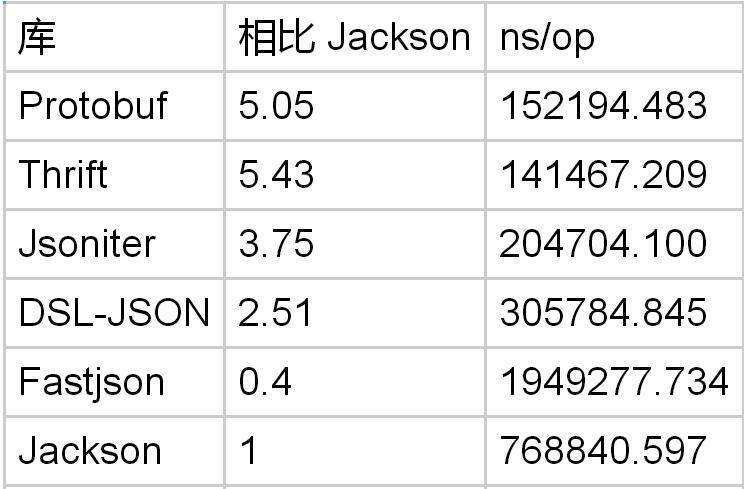
Protobuf 在跳过数据结构方面,是 Jackson 的 5 倍。但是如果跳过长的字符串,JSON 的成本是和字符串长度线性相关的,而 Protobuf 则是一个常量操作。
总结
最后,我们把所有的战果汇总到一起。
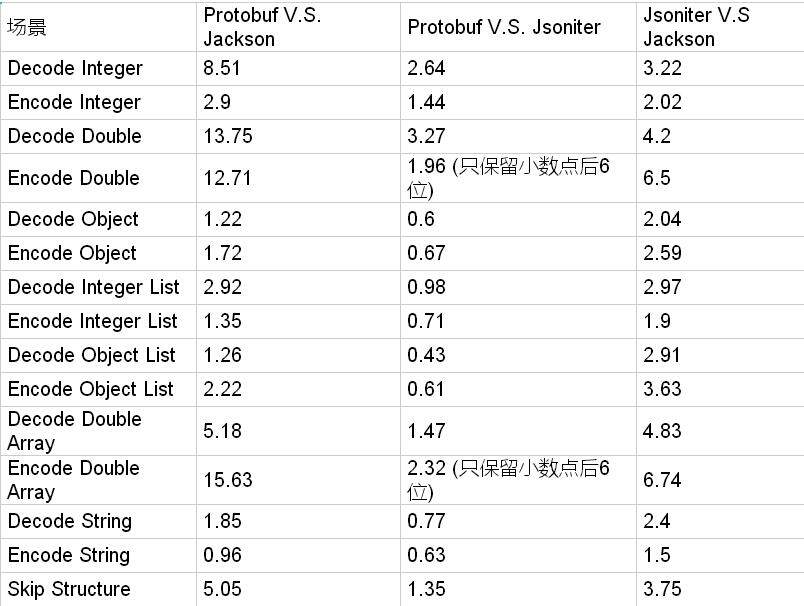
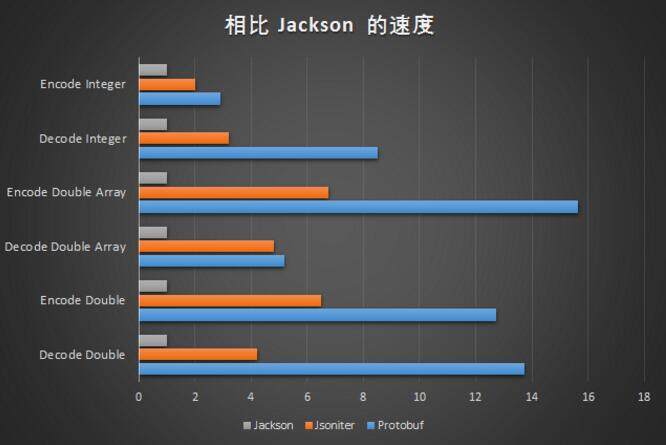
编解码数字的时候,JSON 仍然是非常慢的。 Jsoniter 把这个差距从 10 倍缩小到了 3 倍多一些。
JSON 最差的情况是下面几种:
- 跳过非常长的字符串:和字符串长度线性相关。
- 解码 double 字段:Protobuf 优势明显,是 Jsoniter 的 3.27 倍,是 Jackson 的 13.75 倍。
- 编码 double 字段:如果不能接受只保留 6 位小数,Protobuf 是 Jackson 的 12.71 倍。如果接受精度损失,Protobuf 是 Jsoniter 的 1.96 倍。
- 解码整数:Protobuf 是 Jsoniter 的 2.64 倍,是 Jackson 的 8.51 倍。
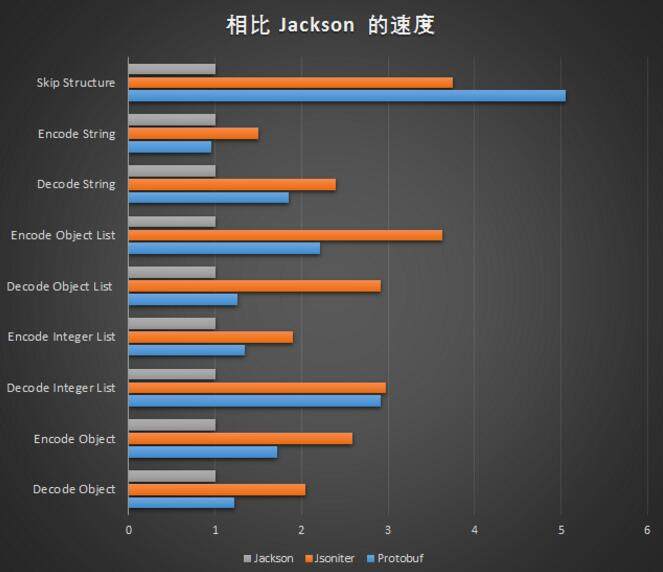
如果你的生产环境中的 JSON 没有那么多的 double 字段,都是字符串占大头,那么基本上来说替换成 Protobuf 也就是仅仅比 Jsoniter 提高一点点,肯定在 2 倍之内。如果不幸的话,没准 Protobuf 还要更慢一点。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...










评论 4 条评论