目前,京东到家库存系统经历两年多的线上考验与技术迭代,现服务着万级商家、十万级店铺的规模,在需求变更与技术演进中,如何做到系统的稳定性与高可用?下面将会给你揭晓答案。
库存系统技术架构
(点击放大图像)

上图如果进行总结下,主要体现出以下几个方面:
完善的基础设施
强大的基础服务平台让应用、JVM、Docker、物理机所有健康指标一目了然,7*24 小时智能监控告警让开发无须一直盯着监控;
数据驱动
数据与业务相辅相成,用数据验证业务需求,迭代业务需求,让业务需求都尽可能的收益最大化,库存系统的开发同学只需要关注业务需求;
健全的测试团队
大版本上线前相应的测试同学会跟进压测,防止上线后潜在的性能瓶颈。
库存系统技术架构图解释说明
Portal
通过提供商家 PC 端、App 端解决大部分中小商家的日常运营需求,另外提供开放平台满足大中型商家系统对接与数据共享互通的问题。
Service
这个板块涵盖了整个库存最核心的 C&B 数据业务。
1、业务类
- C 正常流程:用户下单 - 商家拣货 - 快递员妥投
- C 异常流程 - 缺货:用户下单 - 商家缺货 - 用户协商 - 调整订单缺货商品 - 商家拣货 - 快递员妥投
- C 异常流程 - 取消:用户下单 - 用户反悔 - 订单取消
- C 异常流程 - 风控:用户下单 - 风控拦截 - 订单锁定 - 客服审核 - 订单取消 / 继续生产
- B 正常流程:商家维护可售库存数量,即时或者定时生效
2、数据类
除了业务类需求外,京东到家还提供了大量有商业价值的数据供商家作业务决策,比如:
- 商品销量 Top 榜 - 支持分城市分类目筛选
- 热销商品库存不足预警 - 商家 App 版本 Push 通知及待办事项中可以醒目识别这部分商品并进行维护
- 红黄线自动下架 - 近七日订单量大于 5 单,并且被踩率大于等于 20% 的商品,进行下架操作,每日执行。
- 库存交易流水
3、中间件类
古人行军打仗,兵马未动,粮草先行,对于系统来说亦是如此,编码未动架构先行,架构的技术选型非常重要,在这里给大家分享京东技术体系上万码农都在使用的几个中间件。
- JSF,类似于 DUBBO, 是一款非常优秀的 RPC 层框架,可以解决应用间的数据通信问题,它最主要的优势是长连接的实现以及高效的序列化组件。
- JMQ,JMQ 是京东自主研发的一款消息中间件系统,具有高可用、数据高可靠等特性。广泛应用于公司内部系统,包括订单、支付、库房、交易等场景。在库存系统中会优先更新 Redis 缓存数据,并发送变更 MQ,供 MySQL 及 ES 异步更新。
- O2OWORKER,早期淘宝开源的一款产品 TBSCHEDULE,不这个只适用于单项目管理,多个系统使用的话权限无法隔离,另外参数配置过于繁琐,结合这两点进行了重构,从而形成了现在的整个京东到家都在使用的任务管理平台。
DB
1、MySQL
京东到家库存系统使用的关系型数据库是 MySQL,低成本、低耦合、轻量级,总之优势多多。
2、Redis
丰富的数据结构 & 众多的原子性命令支持,非常适合库存系统进行缓存查询及扣减操作。
3、ES
库存系统的数据量非常大,首先 MySQL 数据库通过水平扩容来解决单表数据量过大的问题,水平扩容的规则采取的是按门店维度进行分表(1. 目前京东到家还没有到分库的阶段,2. 按门店维度进行分表数据量会相对均衡一些,所以没有按照商家维度进行划分)。
那么在商家 PC 端上查询所有商品库存及维护库存时带来了难度,比如查询该商家下所有的商品有多少条,同时处于上架状态的商品有哪些……,为了解决这一难题,引入了 ES,将数据统一存储在 ES 集群中,解决一些涉及到聚合查询的场景。
库存系统数据流转
(点击放大图像)

库存系统数据流转图
库存系统数据流转图解释说明:
库存系统的数据流转,指的都是销售库存的数据流转,在京东到家还有自营类业务板块,即上图中提到的城市仓,由于它涉及到采购入库及盘盈盘亏等问题, 所以会由一套 WMS 系统来支撑。
京东到家设计初衷就是希望商家下的商品各门店共享,带来的问题就是商家新建一个商品时,需要推送到商家下所有的门店中,即所有的门店均可以看到这个商品。或者商家新建一个门店时,需要将商家下所有的商品均推送到这个新建的门店中,所以这采用了 MQ 技术进行异步化批量处理。
写到这里,相信对大家对库存系统有了初步的了解,从上图来看功能上其实并不复杂,但是他面临的技术复杂度却是相当高的,比如秒杀品在高并发的情况下如何防止超卖。
另外库存系统还不是一个纯技术的系统,需要结合用户的行为特点来考虑,比如下文中提到什么时间进行库存的扣减最合适,我们先抛出几个问题和大家一起探讨下,如有不妥之处,欢迎大家拍砖。
库存什么时候进行预占 (或者扣减) 呢
商家销售的商品数量是有限的,用户下单后商品会被扣减,我们可以怎么实现呢?
举个例子: 一件商品有 1000 个库存,现在有 1000 个用户,每个用户计划同时购买 1000 个。
- 实现方案 1:如果用户加入购物车时进行库存预占,那么将只能有 1 个用户将 1000 个商品加入购物车。
- 实现方案 2:如果用户提交订单时进行库存预占,那么将也只能有 1 个用户将 1000 个商品提单成功,其它的人均提示“库存不足,提单失败”。
- 实现方案 3:如果用户提交订单 & 支付成功时进行库存预占,那么这 1000 个人都能生成订单,但是只有 1 个人可以支付成功,其它的订单均会被自动取消。
京东到家目前采用的是 方案 2,理由如下:
用户可能只是暂时加入购物车,并不表示用户最终会提单并支付。
所以在购物车进行库存校验并预占,会造成其它真正想买的用户不能加入购物车的情况,但是之前加车的用户一直不付款,最终损失的是公司。
方案 3 会造成生成 1000 个订单,无论是在支付前校验库存还是在支付成功后再检验库存,都会造成用户准备好支付条件后却会出现 99.9% 的系统取消订单的概率,也就是说会给 99.9% 的用户体验到不爽的感觉。
数据表明用户提交订单不支付的占比是非常小的(相对于加入购物车不购买的行为),目前京东到家给用户预留的最长支付时间是 30 分钟,超过 30 分钟订单自动取消,预占的库存自动释放。
综上所述,方案 2 也可能由于用户下单预占库存但最终未支付,造成库存 30 分钟后才能被其它用户使用的情况,但是相较于方案 1,方案 3 无疑是折中的最好方案。
重复提交订单的问题?
重复提交订单造成的库存重复扣减的后果是比较严重的。比如商家设置有 1000 件商品,而实际情况可能卖了 900 件就提示用户无货了,给商家造成无形的损失
可能出现重复提交订单的情况:
- 1、用户善意行为:app 上用户单击“提交订单”按钮后由于后端接口没有返回,用户以为没有操作成功会再次单击“提交订单”按钮
- 2、用户恶意行为:黑客直接刷提单接口,绕过 App 端防重提交功能
- 3、提单系统重试:比如提单系统为了提高系统的可用性,在第一次调用库存系统扣减接口超时后会重试再次提交扣减请求
好了,既然问题根源缕清楚了,我们一一对症下药
- 1、用户善意行为:App 侧在用户第一次单击“提交订单”按钮后对按钮进行置灰,禁止再次提交订单
- 2、用户恶意行为:采用令牌机制,用户每次进入结算页,提单系统会颁发一个令牌 ID(全局唯一),当用户点击“提交订单”按钮时发起的网络请求中会带上这个令牌 ID, 这个时候提单系统会优先进行令牌 ID 验证,令牌 ID 存在 & 令牌 ID 访问次数 =1 的话才会放行处理后续逻辑,否则直接返回
- 3、提单系统重试:这种情况则需要后端系统(比如库存系统)来保证接口的幂等性,每次调用库存系统时均带上订单号,库存系统会基于订单号增加一个分布式事务锁。
伪代码如下:
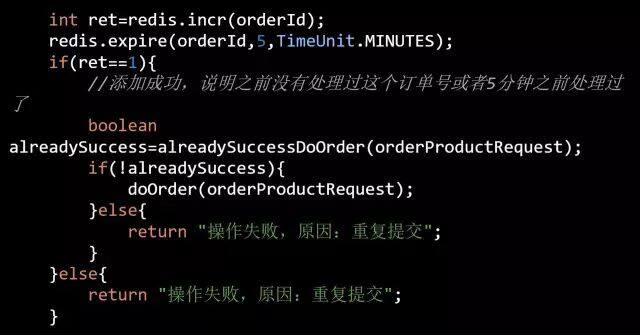
库存数据的回滚机制如何做?
需要库存回滚的场景也是比较多的,比如:
- 1、用户未支付:用户下单后后悔了
- 2、用户支付后取消:用户下单 & 支付后后悔了
- 3、风控取消:风控识别到异常行为,强制取消订单
- 4、耦合系统故障:比如提交订单时提单系统 T1 同时会调用积分扣减系统 X1、库存扣减系统 X2、优惠券系统 X3,假如 X1、X2 成功后,调用 X3 失败,需要回滚用户积分与商家库存。
其中场景 1、2、3 比较类似,都会造成订单取消,订单中心取消后会发送 MQ 出来,各个系统保证自己能够正确消费订单取消 MQ 即可。
而场景 4 订单其实尚未生成,相对来说要复杂些,如上面提到的,提单系统 T1 需要主动发起库存系统 X2、优惠券系统 X3 的回滚请求(入参必须带上订单号),X2、X3 回滚接口需要支持幂等性。
其实针对场景 4,还存在一种极端情况,如果提单系统 T1 准备回滚时自身也宕机了,那么库存系统 X2、优惠券系统 X3 就必须依靠自己来完成回滚操作了,也就是说具备自我数据健康检查的能力,具体来说怎么实现呢?
可以利用当前订单号所属的订单尚未生成的特点,可以通过 worker 机制,每次捞取 40 分钟(这里的 40 一定要大于容忍用户的支付时间)前的订单,调用订单中心查询订单的状态,确保不是已取消的,否则进行自我数据的回滚。
多人同时购买 1 件商品,如何安全地库存扣减?
现实中同一件商品可能会出现多人同时购买的情况,我们可以如何做到并发安全呢?
伪代码片段 1:
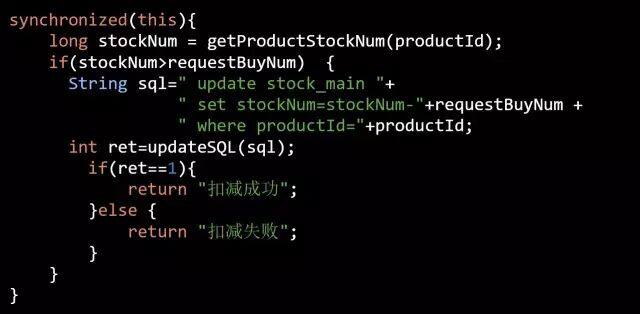
伪代码片段 1 的设计思想是所有的请求过来之后首先加锁,强制其串行化处理,可见其效率一定不高。
伪代码片段 2:
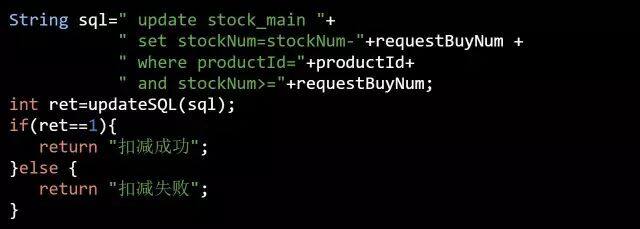
这段代码只是在 where 条件里增加了 **and stockNum>="+requestBuyNum** 即可防止超卖的行为,达到了与上述伪代码 1 的功能。
如果商品是促销品(比如参与了秒杀的商品)并发扣减的机率会更高,那么数据库的压力会更高,这个时候还可以怎么做呢?
海量的用户秒杀请求,本质上是一个排序,先到先得。但是如此之多的请求,注定了有些人是抢不到的,可以在进入上述伪代码 Dao 层之前增加一个计数器进行控制,比如有 50% 的流量将直接告诉其抢购失败,伪代码如下:
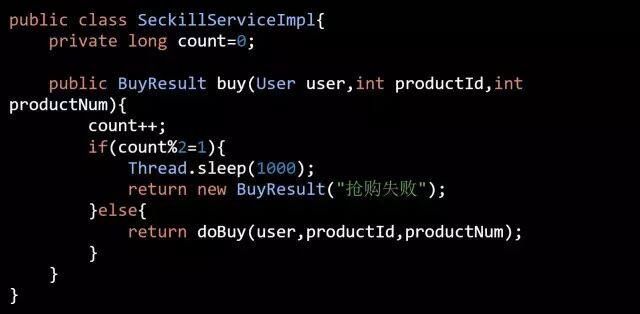
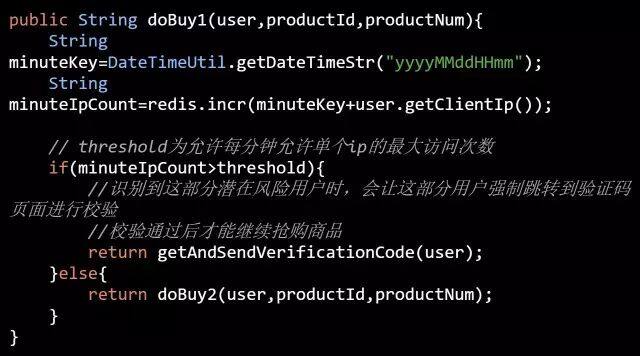
另外同一个用户,不允许多次抢购同一件商品,我们又该如何做呢?
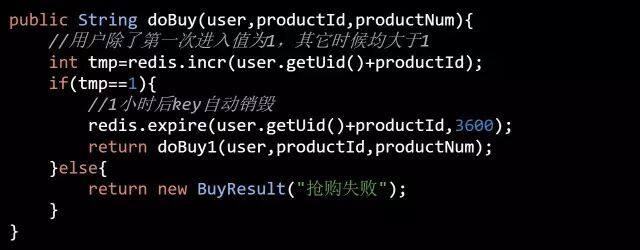
如果同一个用户拥有不同的帐号,来抢购同一件商品,上面的策略就失效了。一些公司在发展早期几乎是没有限制的,很容易就可以注册很多个账号。也即是网络所谓的“僵尸账号”,数量庞大,如果我们使用几万个“僵尸号”混进去抢购,这样就可以大大提升我们中奖的概率,那我们如何应对呢?
库存系统的核心表结构设计
下面列出了库存系统的核心表结构,提供出来供大家在工作中能够有所参考。
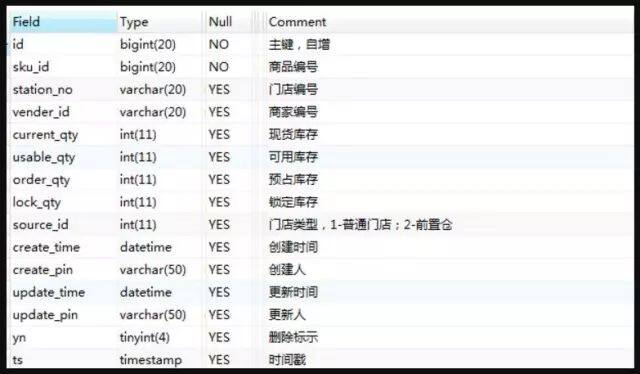
库存主表,命名规则:stock_center_00~99 库存主表
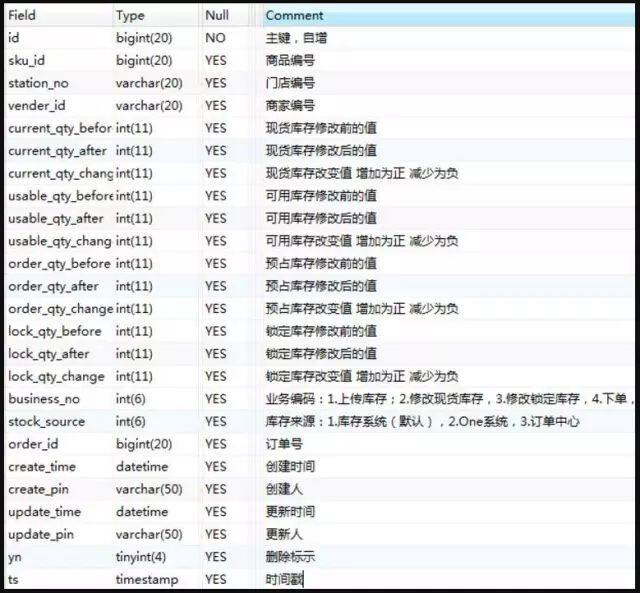
库存流水表,命名规则:stock_center_flow_00~99 库存流水表
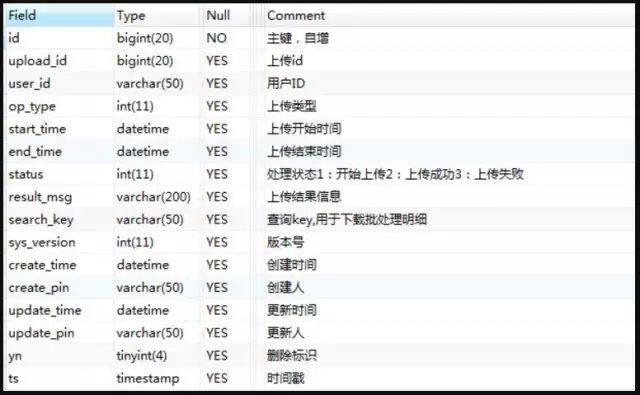
库存批量操作日志表,命名规则:batch_upload_log 库存批量操作日志表
作者介绍
柳志崇,2008 年计算机专业毕业,一直从事于移动互联网及 O2O 新零售业务领域的工作,参与过京东到家多个亿级 PV 系统的研发与架构,对高并发有着丰富的实战经验。
感谢雨多田光对本文的审校。




