
前言
经过本系列的上半部分 JDK1.8 AbstractQueuedSynchronizer 的实现分析(上)的解读,相信很多读者已经对 AbstractQueuedSynchronizer(下文简称 AQS) 的独占功能了然于胸, 那么这次我们通过对另一个工具类:CountDownLatch 的分析来解读 AQS 的另外一个功能:共享功能。
AQS 共享功能的实现
在开始解读 AQS 的共享功能前,我们再重温一下 CountDownLatch,CountDownLatch 为 java.util.concurrent 包下的计数器工具类,常被用在多线程环境下,它在初始时需要指定一个计数器的大小,然后可被多个线程并发的实现减 1 操作,并在计数器为 0 后调用 await 方法的线程被唤醒,从而实现多线程间的协作。它在多线程环境下的基本使用方式为:
//main thread // 新建一个 CountDownLatch,并指制定一个初始大小 CountDownLatch countDownLatch = new CountDownLatch(3); // 调用 await 方法后,main 线程将阻塞在这里,直到 countDownLatch 中的计数为 0 countDownLatch.await(); System.out.println("over"); //thread1 // do something //........... // 调用 countDown 方法,将计数减 1 countDownLatch.countDown(); //thread2 // do something //........... // 调用 countDown 方法,将计数减 1 countDownLatch.countDown(); //thread3 // do something //........... // 调用 countDown 方法,将计数减 1 countDownLatch.countDown();
注意,线程 thread 1,2,3 各自调用 countDown 后,countDownLatch 的计数为 0,await 方法返回,控制台输入“over”, 在此之前 main thread 会一直沉睡。
可以看到 CountDownLatch 的作用类似于一个“栏栅”,在 CountDownLatch 的计数为 0 前,调用 await 方法的线程将一直阻塞,直到 CountDownLatch 计数为 0,await 方法才会返回,
而 CountDownLatch 的 countDown() 方法则一般由各个线程调用,实现 CountDownLatch 计数的减 1。
知道了 CountDownLatch 的基本使用方式,我们就从上述 DEMO 的第一行 new CountDownLatch(3)开始,看看 CountDownLatch 是怎么实现的。
首先,看下 CountDownLatch 的构造方法:

和 ReentrantLock 类似,CountDownLatch 内部也有一个叫做 Sync 的内部类,同样也是用它继承了 AQS。
再看下 Sync:

如果你看过本系列的上半部分,你对 setState 方法一定不会陌生,它是 AQS 的一个“状态位”,在不同的场景下,代表不同的含义,比如在 ReentrantLock 中,表示加锁的次数,在 CountDownLatch 中,则表示 CountDownLatch 的计数器的初始大小。
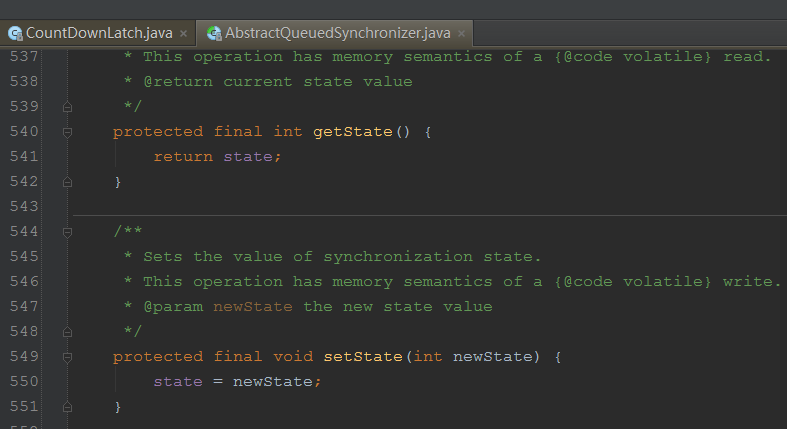
设置完计数器大小后 CountDownLatch 的构造方法返回,下面我们再看下 CountDownLatch 的 await() 方法:

调用了 Sync 的 acquireSharedInterruptibly 方法,因为 Sync 是 AQS 子类的原因,这里其实是直接调用了 AQS 的 acquireSharedInterruptibly 方法:

从方法名上看,这个方法的调用是响应线程的打断的,所以在前两行会检查下线程是否被打断。接着,尝试着获取共享锁,小于 0,表示获取失败,通过本系列的上半部分的解读, 我们知道 AQS 在获取锁的思路是,先尝试直接获取锁,如果失败会将当前线程放在队列中,按照 FIFO 的原则等待锁。而对于共享锁也是这个思路,如果和独占锁一致,这里的 tryAcquireShared 应该是个空方法,留给子类去判断:

再看看 CountDownLatch:
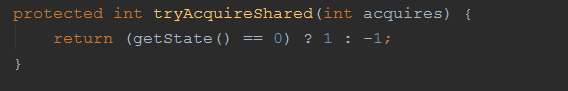
如果 state 变成 0 了,则返回 1,表示获取成功,否则返回 -1 则表示获取失败。
看到这里,读者可能会发现, await 方法的获取方式更像是在获取一个独占锁,那为什么这里还会用 tryAcquireShared 呢?
回想下 CountDownLatch 的 await 方法是不是只能在主线程中调用?答案是否定的,CountDownLatch 的 await 方法可以在多个线程中调用,当 CountDownLatch 的计数器为 0 后,调用 await 的方法都会依次返回。 也就是说可以多个线程同时在等待 await 方法返回,所以它被设计成了实现 tryAcquireShared 方法,获取的是一个共享锁,锁在所有调用 await 方法的线程间共享,所以叫共享锁。
回到 acquireSharedInterruptibly 方法:

如果获取共享锁失败(返回了 -1,说明 state 不为 0,也就是 CountDownLatch 的计数器还不为 0),进入调用 doAcquireSharedInterruptibly 方法中,按照我们上述的猜想,应该是要将当前线程放入到队列中去。
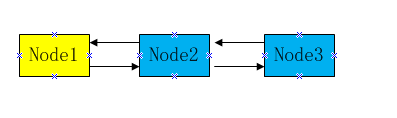
在这之前,我们再回顾一下 AQS 队列的数据结构:AQS 是一个双向链表,通过节点中的 next,pre 变量分别指向当前节点后一个节点和前一个节点。其中,每个节点中都包含了一个线程和一个类型变量:表示当前节点是独占节点还是共享节点,头节点中的线程为正在占有锁的线程,而后的所有节点的线程表示为正在等待获取锁的线程。如下图所示:

黄色节点为头节点,表示正在获取锁的节点,剩下的蓝色节点(Node1、Node2、Node3)为正在等待锁的节点,他们通过各自的 next、pre 变量分别指向前后节点,形成了 AQS 中的双向链表。每个线程被加上类型(共享还是独占)后便是一个 Node, 也就是本文中说的节点。
再看看 doAcquireSharedInterruptibly 方法:
private void doAcquireSharedInterruptibly(int arg) throws InterruptedException { final Node node = addWaiter(Node.SHARED); // 将当前线程包装为类型为 Node.SHARED 的节点,标示这是一个共享节点。 boolean failed = true; try { for (;;) { final Node p = node.predecessor(); if (p == head) { // 如果新建节点的前一个节点,就是 Head,说明当前节点是 AQS 队列中等待获取锁的第一个节点, // 按照 FIFO 的原则,可以直接尝试获取锁。 int r = tryAcquireShared(arg); if (r >= 0) { setHeadAndPropagate(node, r); // 获取成功,需要将当前节点设置为 AQS 队列中的第一个节点,这是 AQS 的规则 // 队列的头节点表示正在获取锁的节点 p.next = null; // help GC failed = false; return; } } if (shouldParkAfterFailedAcquire(p, node) && // 检查下是否需要将当前节点挂起 parkAndCheckInterrupt()) throw new InterruptedException(); } } finally { if (failed) cancelAcquire(node); } }
这里有几点需要说明的:
1. setHeadAndPropagate 方法:
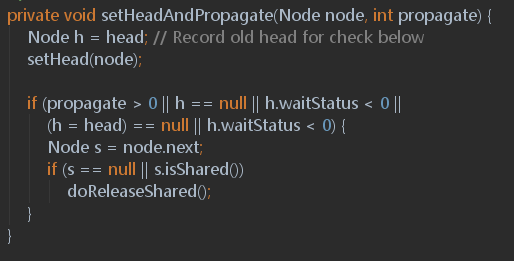
首先,使用了 CAS 更换了头节点,然后,将当前节点的下一个节点取出来,如果同样是“shared”类型的,再做一个"releaseShared"操作。
看下 doReleaseShared 方法:
for (;;) { Node h = head; if (h != null && h != tail) { int ws = h.waitStatus; if (ws == Node.SIGNAL) { if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0)) // 如果当前节点是 SIGNAL 意味着,它正在等待一个信号, // 或者说,它在等待被唤醒,因此做两件事,1 是重置 waitStatus 标志位,2 是重置成功后, 唤醒下一个节点。 continue; // loop to recheck cases unparkSuccessor(h); } else if (ws == 0 && !compareAndSetWaitStatus(h, 0, Node.PROPAGATE)) // 如果本身头节点的 waitStatus 是出于重置状态(waitStatus==0)的,将其设置为“传播”状态。 // 意味着需要将状态向后一个节点传播。 continue; // loop on failed CAS } if (h == head) // loop if head changed break; }
为什么要这么做呢?这就是共享功能和独占功能最不一样的地方,对于独占功能来说,有且只有一个线程(通常只对应一个节点,拿 ReentantLock 举例,如果当前持有锁的线程重复调用 lock() 方法,那根据本系列上半部分我们的介绍,我们知道,会被包装成多个节点在 AQS 的队列中,所以用一个线程来描述更准确),能够获取锁,但是对于共享功能来说。
共享的状态是可以被共享的,也就是意味着其他 AQS 队列中的其他节点也应能第一时间知道状态的变化。因此,一个节点获取到共享状态流程图是这样的:
比如现在有如下队列:
当 Node1 调用 tryAcquireShared 成功后,更换了头节点:
Node1 变成了头节点然后调用 unparkSuccessor() 方法唤醒了 Node2、Node2 中持有的线程 A 出于上面流程图的 park node 的位置,
线程 A 被唤醒后,重复黄色线条的流程,重新检查调用 tryAcquireShared 方法,看能否成功,如果成功,则又更改头节点,重复以上步骤,以实现节点自身获取共享锁成功后,唤醒下一个共享类型节点的操作,实现共享状态的向后传递。
2. 其实对于 doAcquireShared 方法,AQS 还提供了集中类似的实现:
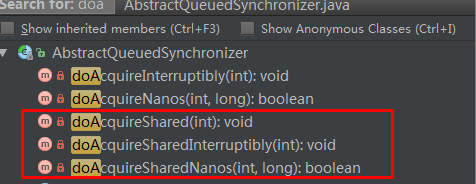
分别对应了:
- 带参数请求共享锁。 (忽略中断)
- 带参数请求共享锁,且响应中断。(每次循环时,会检查当前线程的中断状态,以实现对线程中断的响应)
- 带参数请求共享锁但是限制等待时间。(第二个参数设置超时时间,超出时间后,方法返回。)
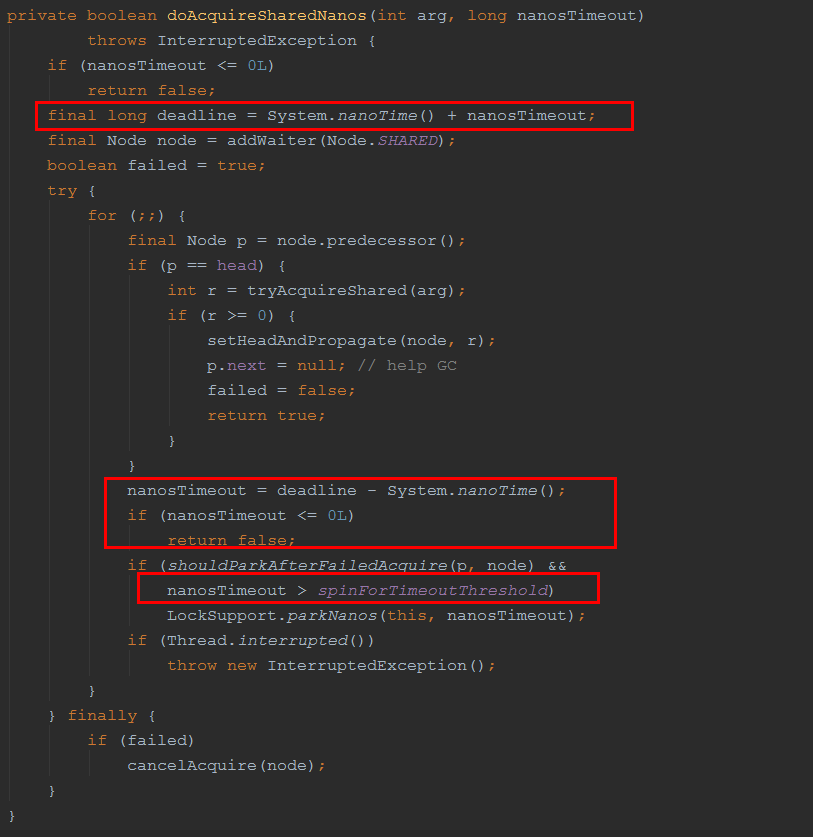
比较特别的为最后一个 doAcquireSharedNanos 方法,我们一起看下它怎么实现超时时间的控制的。
因为该方法和其余获取共享锁的方法逻辑是类似的,我用红色框圈出了它所不一样的地方,也就是实现超时时间控制的地方。
可以看到,其实就是在进入方法时,计算出了一个“deadline”,每次循环的时候用当前时间和“deadline”比较,大于“dealine”说明超时时间已到,直接返回方法。
注意,最后一个红框中的这行代码:
nanosTimeout > spinForTimeoutThreshold
从变量的字面意思可知,这是拿超时时间和超时自旋的最小作比较,在这里 Doug Lea 把超时自旋的阈值设置成了 1000ns, 即只有超时时间大于 1000ns 才会去挂起线程,否则,再次循环,以实现“自旋”操作。这是“自旋”在 AQS 中的应用之处。
看完 await 方法,我们再来看下 countDown() 方法:
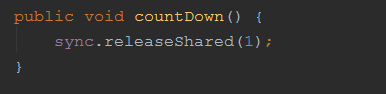
调用了 AQS 的 releaseShared 方法, 并传入了参数 1:
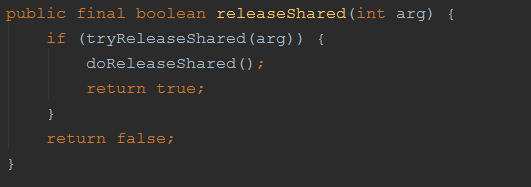
同样先尝试去释放锁,tryReleaseShared 同样为空方法,留给子类自己去实现,以下是 CountDownLatch 的内部类 Sync 的实现:

死循环更新 state 的值,实现 state 的减 1 操作,之所以用死循环是为了确保 state 值的更新成功。
从上文的分析中可知,如果 state 的值为 0,在 CountDownLatch 中意味:所有的子线程已经执行完毕,这个时候可以唤醒调用 await() 方法的线程了,而这些线程正在 AQS 的队列中,并被挂起的,
所以下一步应该去唤醒 AQS 队列中的头节点了(AQS 的队列为 FIFO 队列),然后由头节点去依次唤醒 AQS 队列中的其他共享节点。
如果 tryReleaseShared 返回 true, 进入 doReleaseShared() 方法:
private void doReleaseShared() { for (;;) { Node h = head; if (h != null && h != tail) { int ws = h.waitStatus; if (ws == Node.SIGNAL) { if (!compareAndSetWaitStatus(h, Node.SIGNAL, 0)) // 如果当前节点是 SIGNAL 意味着,它正在等待一个信号, // 或者说,它在等待被唤醒,因此做两件事,1 是重置 waitStatus 标志位,2 是重置成功后, 唤醒下一个节点。 continue; // loop to recheck cases unparkSuccessor(h); } else if (ws == 0 && !compareAndSetWaitStatus(h, 0, Node.PROPAGATE)) // 如果本身头节点的 waitStatus 是出于重置状态(waitStatus==0)的,将其设置为“传播”状态。 // 意味着需要将状态向后一个节点传播。 continue; // loop on failed CAS } if (h == head) // loop if head changed break; } }
当线程被唤醒后,会重新尝试获取共享锁,而对于 CountDownLatch 线程获取共享锁判断依据是 state 是否为 0,而这个时候显然 state 已经变成了 0,因此可以顺利获取共享锁并且依次唤醒 AQS 队里中后面的节点及对应的线程。
总结
本文从 CountDownLatch 入手,深入分析了 AQS 关于共享锁方面的实现方式:
如果获取共享锁失败后,将请求共享锁的线程封装成 Node 对象放入 AQS 的队列中,并挂起 Node 对象对应的线程,实现请求锁线程的等待操作。待共享锁可以被获取后,从头节点开始,依次唤醒头节点及其以后的所有共享类型的节点。实现共享状态的传播。
这里有几点值得注意:
- 与 AQS 的独占功能一样,共享锁是否可以被获取的判断为空方法,交由子类去实现。
- 与 AQS 的独占功能不同,当锁被头节点获取后,独占功能是只有头节点获取锁,其余节点的线程继续沉睡,等待锁被释放后,才会唤醒下一个节点的线程,而共享功能是只要头节点获取锁成功,就在唤醒自身节点对应的线程的同时,继续唤醒 AQS 队列中的下一个节点的线程,每个节点在唤醒自身的同时还会唤醒下一个节点对应的线程,以实现共享状态的“向后传播”,从而实现共享功能。
以上的分析都是从 AQS 子类的角度去看待 AQS 的部分功能的,而如果直接看待 AQS,或许可以这么去解读:
首先,AQS 并不关心“是什么锁”,对于 AQS 来说它只是实现了一系列的用于判断“资源”是否可以访问的 API, 并且封装了在“访问资源”受限时将请求访问的线程的加入队列、挂起、唤醒等操作, AQS 只关心“资源不可以访问时,怎么处理?”、“资源是可以被同时访问,还是在同一时间只能被一个线程访问?”、“如果有线程等不及资源了,怎么从 AQS 的队列中退出?”等一系列围绕资源访问的问题,而至于“资源是否可以被访问?”这个问题则交给 AQS 的子类去实现。
当 AQS 的子类是实现独占功能时,例如 ReentrantLock,“资源是否可以被访问”被定义为只要 AQS 的 state 变量不为 0,并且持有锁的线程不是当前线程,则代表资源不能访问。
当 AQS 的子类是实现共享功能时,例如:CountDownLatch,“资源是否可以被访问”被定义为只要 AQS 的 state 变量不为 0,说明资源不能访问。
这是典型的将规则和操作分开的设计思路:规则子类定义,操作逻辑因为具有公用性,放在父类中去封装。
当然,正式因为 AQS 只是关心“资源在什么条件下可被访问”,所以子类还可以同时使用 AQS 的共享功能和独占功能的 API 以实现更为复杂的功能。
比如:ReentrantReadWriteLock,我们知道 ReentrantReadWriteLock 的中也有一个叫 Sync 的内部类继承了 AQS,而 AQS 的队列可以同时存放共享锁和独占锁,对于 ReentrantReadWriteLock 来说分别代表读锁和写锁,当队列中的头节点为读锁时,代表读操作可以执行,而写操作不能执行,因此请求写操作的线程会被挂起,当读操作依次推出后,写锁成为头节点,请求写操作的线程被唤醒,可以执行写操作,而此时的读请求将被封装成 Node 放入 AQS 的队列中。如此往复,实现读写锁的读写交替进行。
而本系列文章上半部分提到的 FutureTask,其实思路也是:封装一个存放线程执行结果的变量 A, 使用 AQS 的独占 API 实现线程对变量 A 的独占访问,判断规则是,线程没有执行完毕:call() 方法没有返回前,不能访问变量 A,或者是超时时间没到前不能访问变量 A(这就是 FutureTask 的 get 方法可以实现获取线程执行结果时,设置超时时间的原因)。
综上所述,本系列文章从 AQS 独占锁和共享锁两个方面深入分析了 AQS 的实现方式和独特的设计思路,希望对读者有启发,下一篇文章,我们将继续 JDK 1.8 下 J.U.C (java.util.concurrent) 包中的其他工具类,敬请期待。
感谢郭蕾对本文的策划和审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论 2 条评论