

8 月 10 日,网易数帆正式对外宣布流式湖仓服务 Arctic 开源。Arctic 是在 Iceberg 和 Hive 之上添加了更多实时场景的能力,并且面向 DataOps 提供流批统一,开箱即用的元数据服务。
Arctic 百分之百兼容 lceberg 和 Hive 的表格式语法,支持 Spark 和 Flink 读写数据,支持 Trino 和 Impala 查询数据,目前 Impala 主要用到 Hive 的兼容特性,可以把 Arctic 表作为一个 Hive 做查询,从而支持 Impala。
网易数帆大数据实时计算技术专家、湖仓一体项目负责人马进表示,通过与业务沟通,企业希望整个数据中台层能够用一套规范的流程,实现数据业务的全场景覆盖。马进表示,Arctic 的定位就是流式湖仓服务,其中流式强调向实时能力的拓展,服务则强调管理、标准化度量,以及其他可以抽象到基础软件中的湖仓一体能力。
根据介绍,Arctic 有 AMS、optimizer 和 dashboard 三个组件,其中 AMS 和 optimizer 是核心。
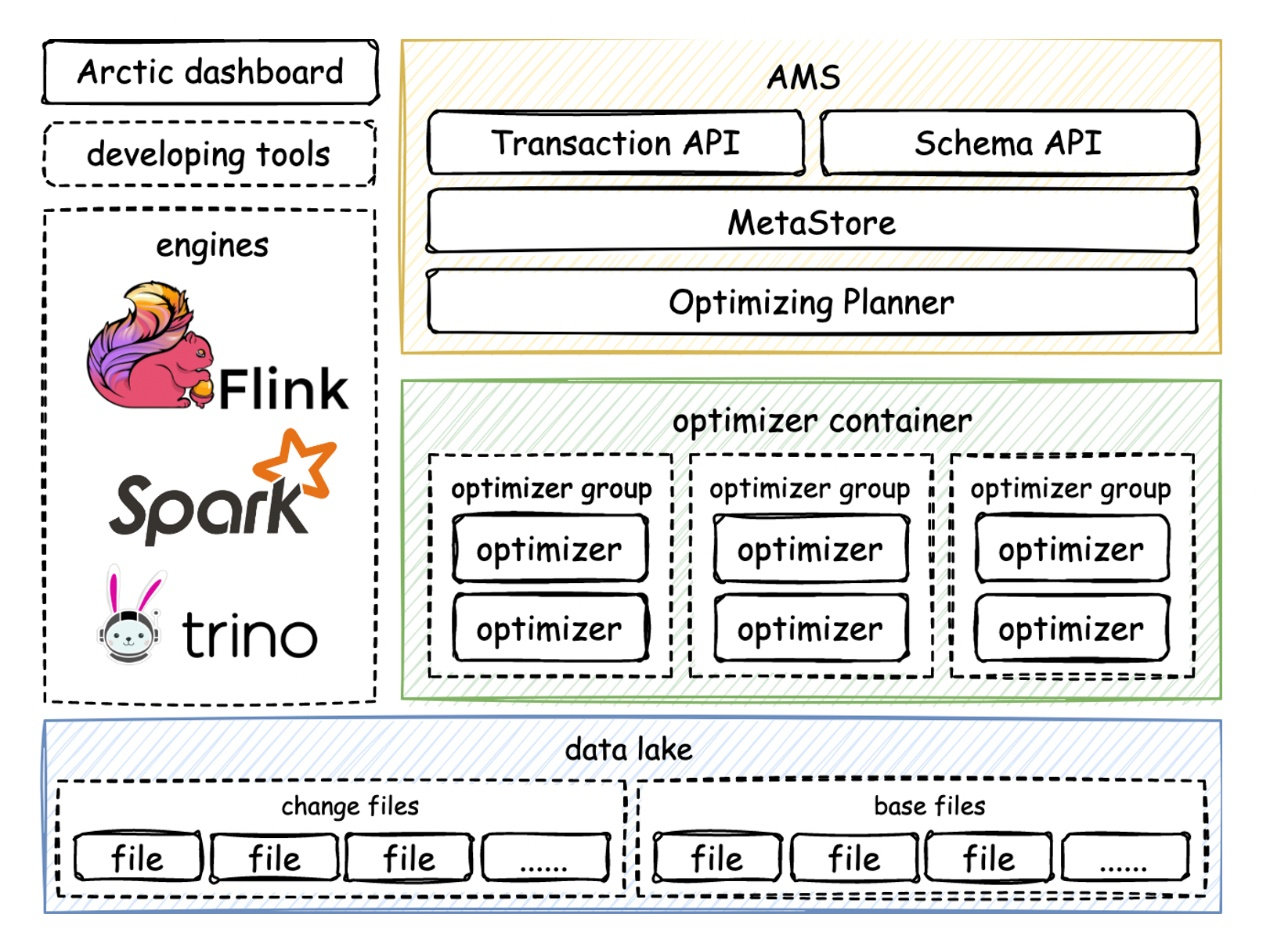
AMS 是 Arctic 中所谓流式湖仓服务中,服务这一层重点强调的组件,是面向 catalog、table、db 三元组的元数据中心,提供事务和冲突解决的 API,还可以与 HMS 同步数据。Optimizer 本质上是平台调度任务的组件,Arctic 有一整套完整的扩展机制和管理机制,用户可以通过 container 接口扩展调度框架,Optimizer group 可以在 container 内部做资源隔离。Dashboard 是单独配置的管理界面。
性能方面,马进分享了一组网易数帆内部的测试结果。研发团队先用 TPC-C 跑数据库,再跑一个 Flink CDC 任务,然后把数据库实施流式同步到 Arctic 数据湖中,用 Arctic 数据湖构建一个分钟级别数据新鲜度的流式湖仓,在此基础上再跑 CHbenchmark 中的 TPC-H 部分,这样得到流式湖仓的性能数据。马进表示,整个测试流程和相关配置将在后续公开。
团队对测试时间进行了分组,分成 0-30 分钟、30-60 分钟、60-90 分钟和 90-120 分钟四组,结果显示,在有了持续 Optimizer 性能后,Arctic 性能基本上稳定在 20 秒左右。具体结果见下图:
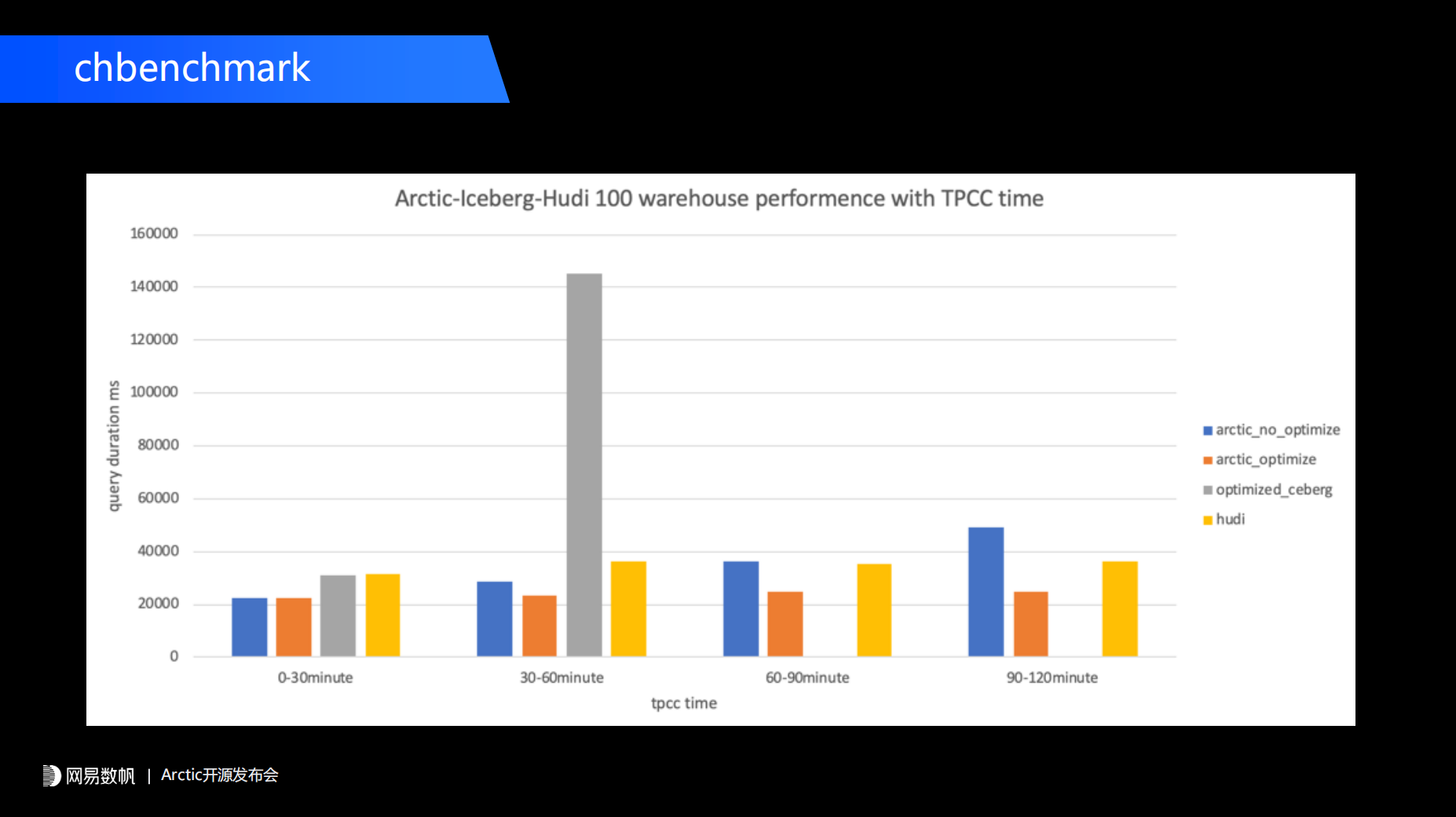
另外,团队对比了原生的 Iceberg upsert 方案,测试结果显示 Iceberg 在 0-30 分钟是 30 秒左右,到了 30-60 分钟时性能急剧下降。经过分析,团队认为导致 Iceberg 性能急剧下降的原因是 Iceberg 本身没有 insert 数据和 delete 数据的精细化数据映射,由于每一个 insert file 都与 delete file 有非常多的关联,所以当团队持续写入流式文件时,导致在 Trino 中做 merge-on-read 性能急剧下降,后面 60-90 分钟、90-120 分钟时直接无法测试。
团队还对比了 Hudi,结果显示,Arctic 和 Hudi 一样,通过后台能够保证数据分析的性能,维持在一个比较平稳的数字。
在服务方面,Arctic 主要强调管理上的功能:支持将数据湖和消息队列封装成统一的表,实现流批表的统一;提供流式湖仓标准化度量,如 dashboard 和相关管理工具;解决并发写入冲突,实现事务一致性语义。
不过,马进也表示 Arctic 在管理层面还有很长的路要走,比如表的实时性如何量化,怎样在时效性、成本、性能之间给用户提供 trade off 方案,数据优化的资源该怎样量化等都有待解决。
在去年,网易决心以一种更加专注的方式做开源。Arctic 便是此思想下的一个开源项目。“一个好的开源项目应该是比较纯粹的。”马进以 Iceberg 为例解释道,Iceberg 早期从 Netflix 内部需求孵化出来,然后开源给更多企业使用,没有哪个功能是内部使用而不对外开放的,或者跟自家的某些东西做深度绑定,这更符合开源气质。
“未来,Arctic 也将秉承这一理念,不会做任何商业隐藏。我们团队推进开源也是非常独立的过程,商业化可能会由其他的团队推进。”马进说道。
Arctic 文档地址:https://arctic.netease.com/ch/
GitHub 地址:https://github.com/NetEase/arctic

分布式云行业实践指南(2023)
业内首个分布式云行业实践方法论、工具箱。







评论