
2017 年 2 月 16 日,Google 正式对外发布 Google TensorFlow 1.0 版本,并保证本次的发布版本 API 接口完全满足生产环境稳定性要求。这是 TensorFlow 的一个重要里程碑,标志着它可以正式在生产环境放心使用。在国内,从 InfoQ 的判断来看,TensorFlow 仍处于创新传播曲线的创新者使用阶段,大部分人对于 TensorFlow 还缺乏了解,社区也缺少帮助落地和使用的中文资料。InfoQ 期望通过深入浅出 TensorFlow 系列文章能够推动 Tensorflow 在国内的发展。欢迎加入 QQ 群(群号:183248479)深入讨论和交流。下面为本系列的前四篇文章:
深入浅出Tensorflow(一):深度学习及TensorFlow 简介
深入浅出TensorFlow(二):TensorFlow 解决MNIST 问题入门
深入浅出Tensorflow(三):训练神经网络模型的常用方法
在前面的几篇文章已经介绍了如何使用原生态TensorFlow API 来实现各种不同的神经网络结构。虽然原生态的TensorFlow API 可以很灵活的支持不同的神经网络结构,但是其代码相对比较冗长,写起来比较麻烦。为了让TensorFlow 用起来更加方便,可以使用一些TensorFlow 的高层封装。
目前对TensorFlow 的主要封装有4 个:
第一个是TensorFlow-Slim;
第二个是tf.contrib.learn(之前也被称为skflow);
第三个是TFLearn;
最后一个是Keras。
本文将大致介绍这几种不同的高层封装的使用方法,并通过其中常用的三种方式在MNIST 数据集上实现卷积神经网络。
TensorFlow-Slim
TensorFlow-Slim 是一个相对轻量级的 TensorFlow 高层封装。通过 TensorFlow-Slim,定义网络结构的代码可以得到很大程度的简化,使得整个代码更加可读。下面的代码对比了使用原生态 TensorFlow 实现卷积层和使用 TensorFlow-Slim 实现卷积层的代码:
# 直接使用 TensorFlow 原生态 API 实现卷积层。 with tf.variable_scope(scope_name): weights = tf.get_variable("weight", …) biases = tf.get_variable("bias", …) conv = tf.nn.conv2d(…) relu = tf.nn.relu(tf.nn.bias_add(conv, biases)) # 使用 TensorFlow-Slim 实现卷积层。通过 TensorFlow-Slim 可以在一行中实现一个卷积层的 # 前向传播算法。slim.conv2d 函数的有 3 个参数是必填的。第一个参数为输入节点矩阵,第二参数 # 是当前卷积层过滤器的深度,第三个参数是过滤器的尺寸。可选的参数有过滤器移动的步长、 # 是否使用全 0 填充、激活函数的选择以及变量的命名空间等。 net = slim.conv2d(input, 32, [3, 3])
从上面的代码可以看出,使用 TensorFlow-Slim 可以大幅减少代码量。省去很多与网络结构无关的变量声明的代码。虽然 TensorFlow-Slim 可以起到简化代码的作用,但是在实际应用中,使用 TensorFlow-Slim 定义网络结构的情况相对较少,因为它既不如原生态 TensorFlow 的灵活,也不如下面将要介绍的其他高层封装简洁。但除了简化定义神经网络结构的代码量,使用 TensorFlow-Slim 的一个最大好处就是它直接实现了一些经典的卷积神经网络,并且 Google 提供了这些神经网络在 ImageNet 上训练好的模型。下表总结了通过 TensorFlow-Slim 可以直接实现的神经网络模型:
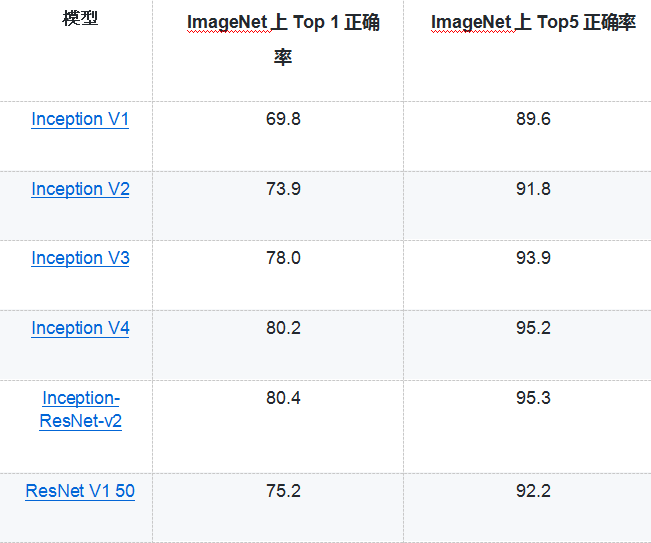
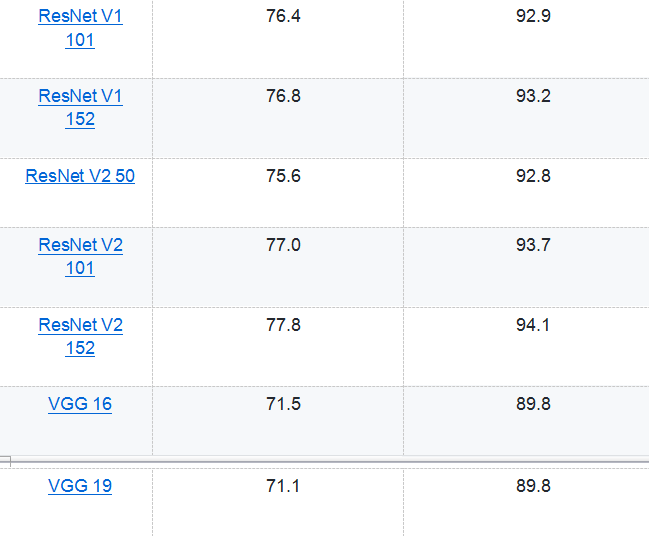
Google 提供的训练好的模型可以在 github 上 tensorflow/models/slim 目录下找到。在该目录下也提供了迁移学习的案例和代码。
tf.contrib.learn
tf.contrib.learn 是 TensorFlow 官方提供的另外一个对 TensorFlow 的高层封装,通过这个封装,用户可以和使用 sklearn 类似的方法使用 TensorFlow。通过 tf.contrib.learn 训练模型时,需要使用一个 Estimator 对象。Estimator 对象是 tf.contrib.learn 进行模型训练(train/fit)和模型评估(evaluation)的入口。
tf.contrib.learn 模型提供了一些预定义的 Estimator,例如线性回归(tf.contrib.learn.LinearRegressor)、逻辑回归(tf.contrib.learn.LogisticRegressor)、线性分类(tf.contrib.learn.LinearClassifier)以及一些完全由全连接层构成的深度神经网络回归或者分类模型(tf.contrib.learn.DNNClassifier、tf.contrib.learn.DNNRegressor)。
除了可以使用预先定义好的模型,tf.contrib.learn 也支持自定义模型,下面的代码给出了使用 tf.contrib.learn 在 MNIST 数据集上实现卷积神经网络的过程。更多关于 tf.contrib.learn 的介绍可以参考 Google 官方文档。
import tensorflow as tf from sklearn import metrics # 使用 tf.contrib.layers 中定义好的卷积神经网络结构可以更方便的实现卷积层。 layers = tf.contrib.layers learn = tf.contrib.learn # 自定义模型结构。这个函数有三个参数,第一个给出了输入的特征向量,第二个给出了 # 该输入对应的正确输出,最后一个给出了当前数据是训练还是测试。该函数的返回也有 # 三个指,第一个为定义的神经网络结构得到的最终输出节点取值,第二个为损失函数,第 # 三个为训练神经网络的操作。 def conv_model(input, target, mode): # 将正确答案转化成需要的格式。 target = tf.one_hot(tf.cast(target, tf.int32), 10, 1, 0) # 定义神经网络结构,首先需要将输入转化为一个三维举证,其中第一维表示一个 batch 中的 # 样例数量。 network = tf.reshape(input, [-1, 28, 28, 1]) # 通过 tf.contrib.layers 来定义过滤器大小为 5*5 的卷积层。 network = layers.convolution2d(network, 32, kernel_size=[5, 5], activation_fn=tf.nn.relu) # 实现过滤器大小为 2*2,长和宽上的步长都为 2 的最大池化层。 network = tf.nn.max_pool(network, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') # 类似的定义其他的网络层结构。 network = layers.convolution2d(network, 64, kernel_size=[5, 5], activation_fn=tf.nn.relu) network = tf.nn.max_pool(network, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') # 将卷积层得到的矩阵拉直成一个向量,方便后面全连接层的处理。 network = tf.reshape(network, [-1, 7 * 7 * 64]) # 加入 dropout。注意 dropout 只在训练时使用。 network = layers.dropout( layers.fully_connected(network, 500, activation_fn=tf.nn.relu), keep_prob=0.5, is_training=(mode == tf.contrib.learn.ModeKeys.TRAIN)) # 定义最后的全连接层。 logits = layers.fully_connected(network, 10, activation_fn=None) # 定义损失函数。 loss = tf.losses.softmax_cross_entropy(target, logits) # 定义优化函数和训练步骤。 train_op = layers.optimize_loss( loss, tf.contrib.framework.get_global_step(), optimizer='SGD', learning_rate=0.01) return tf.argmax(logits, 1), loss, train_op # 加载数据。 mnist = learn.datasets.load_dataset('mnist') # 定义神经网络结构,并在训练数据上训练神经网络。 classifier = learn.Estimator(model_fn=conv_model) classifier.fit(mnist.train.images, mnist.train.labels, batch_size=100, steps=20000) # 在测试数据上计算模型准确率。 score = metrics.accuracy_score(mnist.test.labels, list(classifier.predict(mnist.test.images))) print('Accuracy: {0:f}'.format(score)) ''' 运行上面的程序,可以得到类似如下的 Accuracy: 0.9901 '''
TFLearn
TensorFlow 的另外一个高层封装 TFLearn 进一步简化了 tf.contrib.learn 中对模型定义的方法,并提供了一些更加简洁的方法来定义神经网络的结构。和上面两个高层封装不一样,使用 TFLearn 需要单独安装,安装的方法为:
pip install tflearn
下面的代码介绍了如何通过 TFLearn 来实现卷积神经网络。更多关于 TFLearn 的用法介绍可以参考 TFLearn 的官方网站( http://tflearn.org/ )
import tflearn from tflearn.layers.core import input_data, dropout, fully_connected from tflearn.layers.conv import conv_2d, max_pool_2d from tflearn.layers.estimator import regression import tflearn.datasets.mnist as mnist # 读取 MNIST 数据。 trainX, trainY, testX, testY = mnist.load_data(one_hot=True) # 将图像数据 resize 成卷积卷积神经网络输入的格式。 trainX = trainX.reshape([-1, 28, 28, 1]) testX = testX.reshape([-1, 28, 28, 1]) # 构建神经网络。input_data 定义了一个 placeholder 来接入输入数据。 network = input_data(shape=[None, 28, 28, 1], name='input') # 定义一个深度为 5,过滤器为 5*5 的卷积层。从这个函数可以看出,它比 tf.contrib.learn # 中对卷积层的抽象要更加简洁。 network = conv_2d(network, 32, 5, activation='relu') # 定义一个过滤器为 2*2 的最大池化层。 network = max_pool_2d(network, 2) # 类似的定义其他的网络结构。 network = conv_2d(network, 64, 5, activation='relu') network = max_pool_2d(network, 2) network = fully_connected(network, 500, activation='relu', regularizer="L2") network = dropout(network, 0.5) network = fully_connected(network, 10, activation='softmax', regularizer="L2") # 定义学习任务。指定优化器为 sgd,学习率为 0.01,损失函数为交叉熵。 network = regression(network, optimizer='sgd', learning_rate=0.01, loss='categorical_crossentropy', name='target') # 通过定义的网络结构训练模型,并在指定的验证数据上验证模型的效果。 model = tflearn.DNN(network, tensorboard_verbose=0) model.fit(trainX, trainY, n_epoch=20, validation_set=([testX, testY]), show_metric=True) '''
运行上面的代码,可以得到类似如下的输出:
Run id: UY9GEP Log directory: /tmp/tflearn_logs/ --------------------------------- Training samples: 55000 Validation samples: 10000 -- Training Step: 860 | total loss: 0.25554 | time: 493.917s | SGD | epoch: 001 | loss: 0.25554 - acc: 0.9267 | val_loss: 0.24617 - val_acc: 0.9267 -- iter: 55000/55000 -- Training Step: 1054 | total loss: 0.28228 | time: 110.039s | SGD | epoch: 002 | loss: 0.28228 - acc: 0.9207 -- iter: 12416/55000 '''
Keras
Keras 是一个基于 TensorFlow 或者 Theano 的高层 API,在安装好 TensorFlow 之后可以通过以下命令可以安装:
下面的代码介绍了如何通过 Keras 来实现卷积神经网络。更多关于 Keras 的用法介绍可以参考 Keras 的官方网站( http://tflearn.org/ )
import keras from keras.datasets import mnist from keras.models import Sequential from keras.layers import Dense, Dropout, Flatten from keras.layers import Conv2D, MaxPooling2D from keras import backend as K batch_size = 128 num_classes = 10 epochs = 20 img_rows, img_cols = 28, 28 # 加载 MNIST 数据。 (trainX, trainY), (testX, testY) = mnist.load_data() # 根据系统要求设置输入层的格式。 if K.image_data_format() == 'channels_first': trainX = trainX.reshape(trainX.shape[0], 1, img_rows, img_cols) testX = testX.reshape(testX.shape[0], 1, img_rows, img_cols) input_shape = (1, img_rows, img_cols) else: trainX = trainX.reshape(trainX.shape[0], img_rows, img_cols, 1) testX = testX.reshape(testX.shape[0], img_rows, img_cols, 1) input_shape = (img_rows, img_cols, 1) # 将图像像素转化为 0 到 1 之间的实数。 trainX = trainX.astype('float32') testX = testX.astype('float32') trainX /= 255.0 testX /= 255.0 # 将标准答案转化为需要的格式。 trainY = keras.utils.to_categorical(trainY, num_classes) testY = keras.utils.to_categorical(testY, num_classes) # 定义模型。 model = Sequential() # 一层深度为 32,过滤器大小为 5*5 的卷积层。 model.add(Conv2D(32, kernel_size=(5, 5), activation='relu', input_shape=input_shape)) # 一层过滤器大小为 2*2 的最大池化层。 model.add(MaxPooling2D(pool_size=(2, 2))) # 一层深度为 64,过滤器大小为 5*5 的卷积层。 model.add(Conv2D(64, (5, 5), activation='relu')) # 一层过滤器大小为 2*2 的最大池化层。 model.add(MaxPooling2D(pool_size=(2, 2))) # 将上层最大池化层的输出在 dropout 之后提供给全连接层。 model.add(Dropout(0.5)) # 将卷积层的输出拉直后作为下面全连接层的输入。 model.add(Flatten()) # 全连接层,有 500 个节点。 model.add(Dense(500, activation='relu')) # 全连接层,得到最后的输出。 model.add(Dense(num_classes, activation='softmax')) # 定义损失函数、优化函数和评测方法。 model.compile(loss=keras.losses.categorical_crossentropy, optimizer=keras.optimizers.SGD(), metrics=['accuracy']) # 类似 TFLearn 中的训练过程,给出训练数据、batch 大小、训练轮数和验证数据, # Keras 可以自动完成模型训练过程。 model.fit(trainX, trainY, batch_size=batch_size, epochs=epochs, verbose=1, validation_data=(testX, testY)) # 在测试数据上计算准确率。 score = model.evaluate(testX, testY, verbose=0) print('Test loss:', score[0]) print('Test accuracy:', score[1]) '''
运行上面的代码,可以得到类似如下的输出:
60000/60000 [==============================] - 255s - loss: 1.3127 - acc: 0.5943 - val_loss: 0.3409 - val_acc: 0.9046 Epoch 2/20 60000/60000 [==============================] - 219s - loss: 0.3827 - acc: 0.8840 - val_loss: 0.2006 - val_acc: 0.9433 Epoch 3/20 35072/60000 [================>.............] - ETA: 82s - loss: 0.2752 - acc: 0.9163 '''
作者介绍
郑泽宇,才云首席大数据科学家,前谷歌高级工程师。从 2013 年加入谷歌至今,郑泽宇作为主要技术人员参与并领导了多个大数据项目,拥有丰富机器学习、数据挖掘工业界及科研项目经验。2014 年,他提出产品聚类项目用于衔接谷歌购物和谷歌知识图谱(Knowledge Graph)数据,使得知识卡片形式的广告逐步取代传统的产品列表广告,开启了谷歌购物广告在搜索页面投递的新纪元。他于 2013 年 5 月获得美国 Carnegie Mellon University(CMU)大学计算机硕士学位, 期间在顶级国际学术会议上发表数篇学术论文,并获得西贝尔奖学金。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论