1. 文本指纹介绍
互联网网页存在大量的重复内容网页,无论对于搜索引擎的网页去重和过滤、新闻小说等内容网站的内容反盗版和追踪、还是社交媒体等文本去重和聚类,都需要对网页或者文本进行去重和过滤。
最简单的文本相似性计算方法可以利用空间向量模型,计算分词后的文本的特征向量的相似性,这种方法存在效率的严重弊端,无法针对海量的文本进行两两的相似性判断。模仿生物学指纹的特点,对每个文本构造一个指纹,来作为该文本的标识,从形式上来看指纹一般为固定长度较短的字符串,相同指纹的文本可以认为是相同文本。
最简单的指纹构造方式就是计算文本的 md5 或者 sha 哈希值,除非输入相同的文本,否则会发生“雪崩效应”,极小的文本差异通过 md5 或者 sha 计算出来的指纹就会不同(发生冲撞的概率极低),那么对于稍加改动的文本,计算出来的指纹也是不一样。
因此,一个好的指纹应该具备如下特点:
- 指纹是确定性的,相同的文本的指纹是相同的;
- 指纹越相似,文本相似性就越高;
- 指纹生成和匹配效率高。
业界关于文本指纹去重的算法众多,如 k-shingle 算法、google 提出的 simhash 算法、Minhash 算法、top k 最长句子签名算法等等,本文接下来将简单介绍各个算法以及达观指纹系统的基本架构和思路。
2. 常用的指纹算法
2.1 k-shingle 算法
shingle 在英文中表示相互覆盖的瓦片。对于一段文本,分词向量为 [w1, w2, w3, w4, … wn], 设 k=3,那么该文本的 shingle 向量表示为 [(w1,w2,w3), (w2,w3,w4), (w3,w4,w5), …… (wn-2,wn-1,wn)],计算两个文本的 shingle 向量的相似度(jarccard 系数)来判断文本是否重复。由于 k-shingle 算法的 shingle 向量空间巨大(特别是 k 特别大时),相比 vsm 更加耗费资源,一般业界很少采用这类算法。
2.2 Simhash 算法
Simhash 是 google 用来处理海量文本去重的算法,同时也是一种基于 LSH(locality sensitive hashing) 的算法。简单来说,和 md5 和 sha 哈希算法所不同,局部敏感哈希可以将相似的字符串 hash 得到相似的 hash 值,使得相似项会比不相似项更可能的 hash 到一个桶中,hash 到同一个桶中的文档间成为候选对。这样就可以以接近线性的时间去解决相似性判断和去重问题。
simhash 算法通过计算每个特征(关键词)的哈希值,并最终合并成一个特征值即指纹。
simhash 算法流程
- 首先基于传统的 IR 方法,将文章转换为一组加权的特征值构成的向量。
- 初始化一个 f 维的向量 V,其中每一个元素初始值为 0。
- 对于文章的特征向量集中的每一个特征,做如下计算: a) 利用传统的 hash 算法映射到一个 f-bit(一般设成 32 位或者 64 位)的签名。对于这个 f- bit 的签名,如果签名的第 i 位上为 1,则对向量 V 中第 i 维加上这个特征的权值,否则对向量的第 i 维减去该特征的权值;
b) 整个特征向量集合迭代上述运算后,根据 V 中每一维向量的符号来确定生成的 f-bit 指纹的值,如果 V 的第 i 维为正数,则生成 f-bit 指纹的第 i 维为 1,否则为 0。
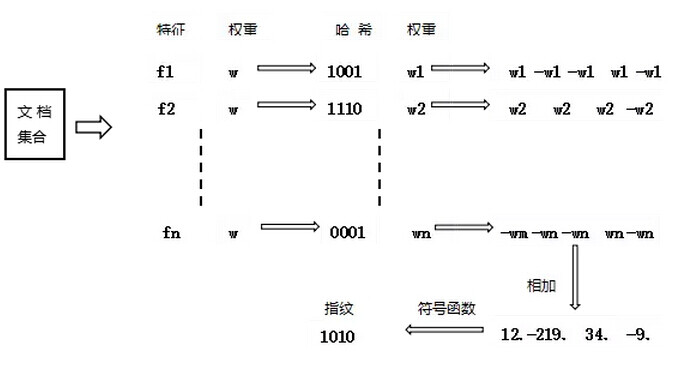
图 1 simhash 算法示意图
Simhash 指纹匹配过程经过 simhash 指纹生成算法生成的指纹是一个 f 位的二进制字符串,如一个 32 位的指纹,‘101001111100011010100011011011’。对于两个文本的 f 位 0-1 字符串,simhash 算法采用 hamming distance 来计算两个指纹之间的相似度,但是对于海量文本,如何从千万级别(甚至更多)的指纹集合中,找出最多只有 k 位不同的指纹呢?
一个简单的思想就是以空间换时间,对于一个 32 位的指纹来说,将该指纹划分成 4 段,即 4 个区间,每个区间 8 位,如果两个指纹至多存在 3(设 k=3)位差异,那么至少有一段的 8 位是完全相同的,因此可以考虑利用分段来建立索引,来减少需要匹配的候选指纹数量。
Simhash 指纹匹配算法
- 首先对于指纹集合 Q 构建多个表 T1,T2…Tt,每一个表都是采用对应的置换函数π(i) 将 32-bit 的 fingerprint 中的某 p(i) 位序列置换换到整个序列的最前面。即每个表存储都是整个 Q 的 fingerprint 的复制置换;
- 对于给定的 F,在每个 Ti 中进行匹配,寻找所有前 pi 位与 F 经过π(i) 置换后的前 pi 位相同的 fingerprint。
- 对于所有在上一步中匹配到的置换后的 fingerprint,计算其是否与π(i)(F) 至多有 k-bit 不同。
Simhash 算法比较高效,比较适用于对于长文本。
2.3 Minhash 算法
Minhash 也是一种 LSH 算法,同时也是一种降维的方法。Minhash 算法的基本思想是使用一个随机的 hash 函数 h(x) 对集合 A 和 B 中的每个元素进行 hash,hmin(A)、hmin(B) 分别表示 hash 后集合 A 和集合 B 的最小值,那么 P(hmin(A) == hmin(B)) = Jaccard(A, B)。这是 minhash 算法的核心,其中 hmin(A) 为哈希函数 h(x) 对集合 A 的最小哈希值。
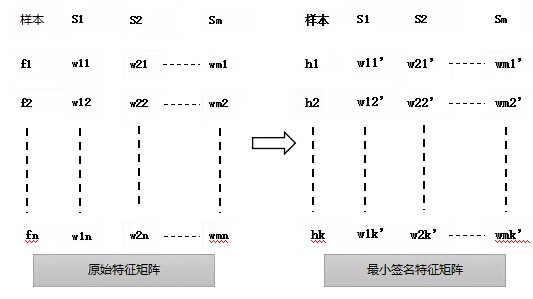
图 2: 最小签名矩阵生成示意图
Minhash 算法采用最小哈希函数族(一组随机的最小哈希函数)来构建文档的最小哈希签名。文档的最小哈希签名矩阵是对原始特征矩阵降维的结果。应用过程中,可以使用 k 个最小函数分别计算出集合的哈希最小值。设 hi 表示第 i 个最小 hash 函数,最小签名矩阵中列向量为样本 si 的最小签名向量,其中 wij 表示第 j 个最小 hash 函数对样本 i 的最小哈希值。
当 k 小于原始集合的长度(k << n)时,就相当于对数据降维,类比 PCA 等降维方法,minhash 避免了复杂的矩阵运算。由于最小签名矩阵中,样本 i,j 的某一行或某几行的子向量的相似度于样本 i,j 的 jarcarrd 距离相等,因此可以对最小签名矩阵运行行条化策略,经矩阵平均分为 b 个行条,每个行条由 r 条组成,当两个样本在任意一个行条中的向量相等,即是一个相似性候选对,并检查文档是否真正相似或者相等。
关于 minhash 的原理和推导,以及在大量文本及高维特征下如何快速进行最小签名矩阵的构建操作可以参考 https://en.wikipedia.org/wiki/MinHash 及《大数据 互联网大规模数据挖掘与分布式处理》,数学的奥妙就在于此。
经过 minhash 降维后的文本向量,从概率上保证了两个向量的相似度和降维前是一样的,结合 LSH 技术构建候选对可以大大减少空间规模,加快查找速度。
3. 内容型网页文本指纹算法
本节将给出我们在对内容型网页(小说、新闻等)去重任务中总结出来的算法和实践经验,特别在当前内容版权日益受到重视和保护的背景下,对于内容版权方来说,如何从网络上发现和追踪侵权和盗版行为日益重要。
从前文可以看出,指纹识别算法是实现指纹识别的关键,它直接决定了识别率的高低,是指纹识别技术的核心。特别是类似新闻类、小说类网页在转载或者盗版过程中,文字的个数、顺序上一般都保持一致,当然不排除个别字错误或者少一个字的情况。
指纹生成的过程主要包括将文本全部转换成拼音、截取每个字拼音的首字母、统计该粒度内字母的频率分布、通过和参考系比较,将结果进行归一化、按字母序,将数字表征转换成数字。
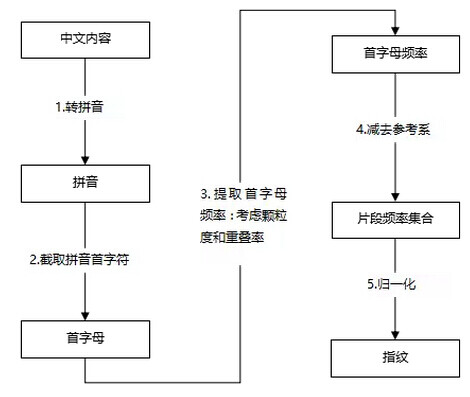
图 3 指纹生成算法
算法描述:
- 转拼音:可以解决字符集编码不一致的问题,可以利用成熟的英文指纹算法,减小分布空间,同时可以解决同音字替代问题;
- 截取拼音首字:减小存储长度和分布空间(26 个字母);
- 提取首字母频率:选择多少字来计算指纹,统计频率分布。需要设置颗粒度的大小(分段大小)以及重叠率。 大粒度容错性高,但是匹配率低;小粒度容错性低,但是误报率高且敏感度高。
重叠率是设置指纹计算片段移动的窗口大小:
假设拼音内容长为 2n,颗粒长度为 n,重叠率为 50%,则需要计算的指纹片段分别为 [1-n],[n/2,3*n/2],[n,2n]
4. 减去参考系:频率减去参考系
5. 归一化:将每个字母的数字特征归一化到一个闭区间内,如 [0,9], 按照字母顺序连接数字特征,变成一个数字,即指纹。
- 若空间为 [0,9], 即一个 20 位的整数,2^64,需要 8 byte
- 若空间为 [0,7], 可用一个 20 位的 8 进制数,8^20, 需要 8 byte
- 若空间为 [0,3], 只需要 4^20, 共 40 bit, 5 byte
- 若空间为 [0,1], 需要 2^20,20 bit,3 byte
归一化过程的算法步骤如下,假设颗粒长度为 m:
输入:片段频率集合 S:[s1,s2,s3,…sn]
参数:指纹集合 dnas:[]
计算基数 radix:=pow(2, log(m)/log(2) )
FOR 片段频率 s IN S
修正频率, 每个频率值:=max(频率,基数)
指纹 dna:= 空串
FOR tmp IN s[m-5:m]
将 tmp 转换成整数,基数为 radix
将 tmp 转换成字符串,基数为 radix
dna:=dna 连接 tmp
dnas:=dnas 添加 dna
END
输出:指纹集合 dnas
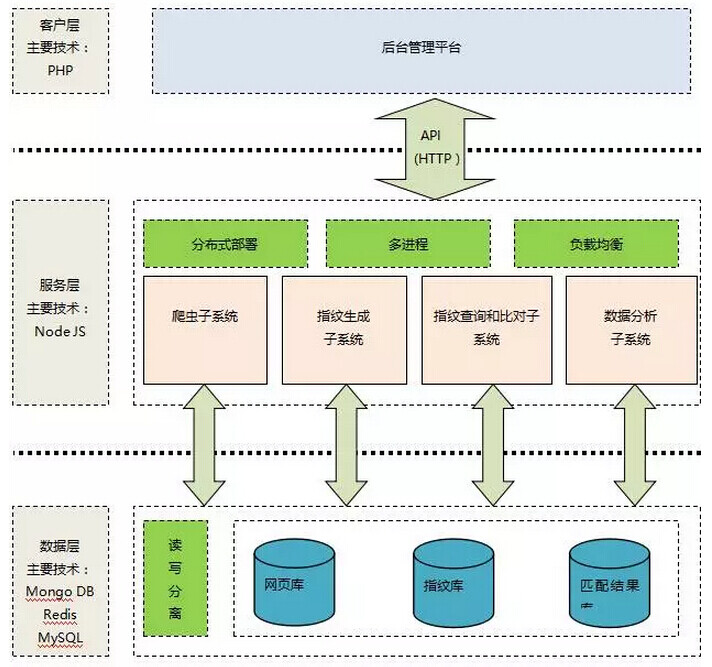
4. 达观指纹系统结构
4.1 基本架构
达观指纹追踪系统主要由爬虫系统、指纹生成系统、指纹存储、指纹查询和比对、数据分析、后台管理系统等几个主要模块构成,如图 4 所示。其中存储层包括匹配结果信息库、网页库以及指纹库。
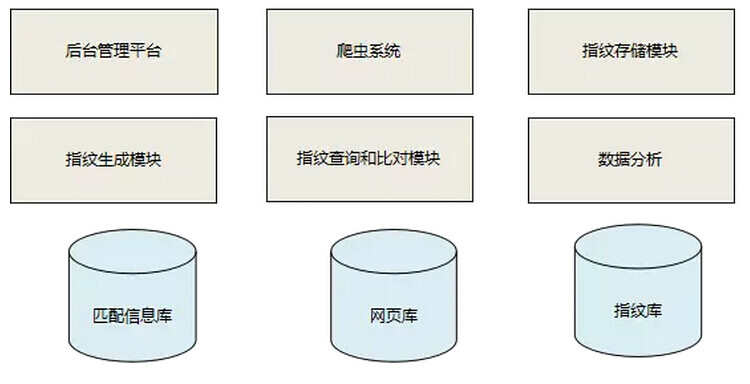
图 4 指纹追踪系统模块图
A. 爬虫系统
爬虫系统从目的上看主要在于抓取互联网上的特定领域的网页(如新闻类网页),爬虫系统是原始数据的唯一来源,只有通过爬虫系统才能从浩瀚的互联网中抓取相似的网页内容。爬虫系统需要拥有较高的抓取能力和反爬取能力,为整个系统提供大量的待检测页面。
B. 指纹存储模块
指纹存储模块计算母体(海量文本)的指纹,指纹可以理解为一行文本的向量表示,本系统的指纹存储系统采用 mongo DB 进行存储。
C. 指纹生成模块
指纹生成模块的输入是一行文本,其输出为该文本的指纹表示,为了达到较高的对比准确率,一个好的指纹生成系统至关重要。
D. 指纹查询和比对模块
指纹库中存储着大量的母体指纹,对于某一文本,指纹查询和比对模块要快速的判断该文本是否在母体库中存在重复。
E. 数据分析
数据分析系统需要对大量的文本及其对比结果进行统计数据分析。
F. 后台管理平台
提供数据分析的展示,并提供用户使用查询和输出分析报告等。
数据存储模块
A. 网页库
主要存放爬虫系统抓取的网页信息、站点信息,本系统网页库采用 mongo DB。
B. 指纹库
主要存放母体指纹,本系统采用 mongo DB 存放指纹。为了加快指纹的查询和比对,本系统采用 redis 来对指纹建立索引,加快匹配速度。
C. 匹配信息库
存储指纹匹配结果, 包括待匹配的两个指纹, 原始网页 id, 匹配相似度等。
4.2 系统架构
图 5 系统架构图
4.3 系统处理流程
本系统的处理流程如图 6 所示,系统支持每天自动化从母体库中调度新的任务进行去重操作。
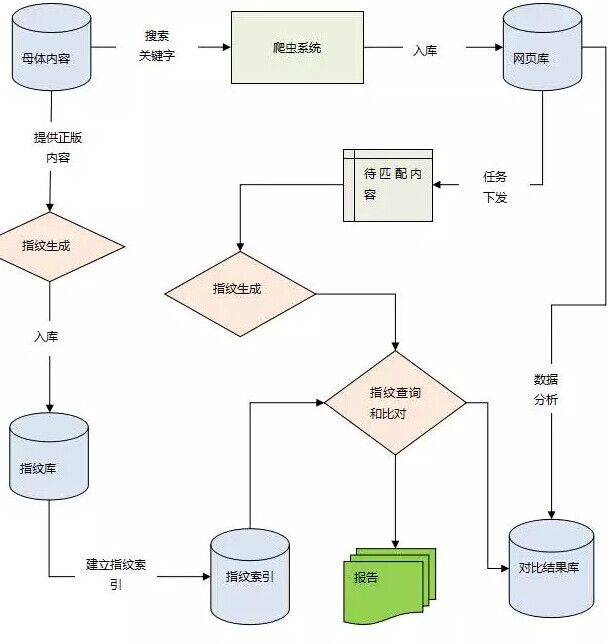
图 6 系统流程图
5 总结
对于网页去重、内容盗版追踪、内容聚类等应用来说,指纹模块都是极其重要的模块。本文介绍了一些比较常用的指纹算法,包括 k-shingle、simhash、minhash;同时介绍了达观数据自主开发的指纹追踪系统及其关键算法,没有最好的算法,只有合适的算法,在实际的使用过程中,需要根据具体业务场景,确定架构和算法。
作者介绍
文辉,同济大学计算机应用技术专业硕士,现任达观数据联合创始人,主要负责据推荐系统、数据采集系统、大数据平台架构等主要系统的研究和开发。曾就职于盛大文学数据中心部门,负责推荐系统、爬虫系统、数据挖掘和分析等大数据系统的研发工作,在数据挖掘和采集、Hadoop/Hive、Spark 等方面具备充足的研发和实践经验。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




