
【编者的话】据了解,在短短四年间, Uber 已经惊人地增长了38 倍。最近,Uber 的首席系统架构师 Matt Ranney 在他的报告“扩展Uber 的实时市场平台”中,对Uber 软件系统的工作原理进行了一个有趣而又详细的介绍。本文对Matt 的报告内容作了一个简单的总结。本文是一篇翻译稿,原文题目为“ How Uber Scales Their Real-Time Market Platform ”,已获得作者授权。
在 Matt 的报告中,给人印象最深刻的是 Uber 的快速增长。他们对于系统架构所做的很多选择都是基于公司规模的快速增长。很多技术都运行在后台,因为尽可能地让团队快速运转一直是他们的主要目标。
经过开始时期一个短暂的混乱阶段之后,Uber 已经从自身的业务中学习到了很多,包括成功所真正需要的东西。他们早期的调度系统主要是面向移动的人。而现在,除了人之外,Uber 的任务已经发展到处理箱子和杂货,他们的调度系统已经被抽象化,并且构建了非常坚实和智能化的基础架构。
虽然 Matt 认为,他们的架构可能有一些疯狂,但是使用附带 gossip 协议的一致性哈希 ring 的想法似乎正好符合他们的实际情况。
不被 Matt 的工作热情所吸引是很困难的。在谈到他们的调度系统 DISCO 的时候,他非常兴奋地说到,这实际上就像一个很酷的计算机科学问题,即旅行商问题。尽管该解决方案不是最佳的,但将其想象为一个真实世界中旅行商,他具有一个有趣的规模,而且是实时的,内置了容错可伸缩的组件。这多酷啊!
本文中,我们介绍了 Uber 的调度系统,他们是如何实现地理空间索引,他们是如何扩展他们的系统,他们是如何实现高可用性,以及他们如何处理系统故障,包括当出现数据中心故障的时候,通过将司机的手机作为一个外部分布式存储系统,Uber 采用了一种非常出色的系统恢复方式。
统计
- Uber 地理空间索引的目标是以每秒百万次的速度写入,以及以写入速度数倍的速度读出。
- 该调度系统具有数千个节点。
平台
- Node.js
- Python
- Java
- Go
- iOS 和 Android 系统上的本地应用程序
- Microservices
- Redis
- Postgres
- MySQL
- Riak
- Twitter Twemproxy
- Google 的 S2 Geometry Library
- ringpop —一致性哈希 ring
- TChannel —RPC 网络复用和成帧协议
- Thrift
架构概述
- 驱动这一切的是使用移动电话运行原生应用程序的乘客和司机。
- 后端主要为移动电话之间的信息处理服务。客户端与后端之间的通信是通过移动数据和尽力而为的互联网。
- 客户端连接到调度系统,以匹配乘客和司机之间的供应和需求。
- 调度系统几乎完全用 Node.js 编写。
- 过去计划将其移动到 io.js ,但之后 io.js 和 Node.js 合并所以放弃了。
- 你可以在 JavaScript 上做一些有趣的分布式系统工作。
- 整个 Uber 系统可能看起来很简单。但这种简单的方式就是成功的标志。只要它看起来足够简单,他们的工作就完成了。
- 地图 / ETA(预计到达时间)。在调度过程中,获取地图和路由信息对于最终做出明智的选择是非常必要的。
- 街道地图和历史出行时间被用来估计当前的出行时间。
- 使用的语言很大程度上取决于系统所要集成的内容。因此,语言包括 Python,C ++ 和 Java。
- 服务。存在大量的业务逻辑服务。
- 微服务。
- 大多用 Python 编写。
- 数据库
- 最早的系统是用 Postgres 编写。
- 使用 Redis。一些是在 Twemproxy 中,一些是在自定义集群系统中。
- MySQL
- Uber 正在构建自己分布式列存储,以存储 MySQL 实例。
- 一些调度服务保存状态在 Riak 中。
- 评论和反馈。一次出行完成之后还需要大量的处理。
- 收集评分。
- 发送电子邮件。
- 更新数据库。
- 计划付款。
- 用 Python 编写。
- 费用。Uber 集成了多种支付系统。
旧的调度系统
- 原来的调度系统中的不足已经开始限制公司的增长,所以它不得不改变。
- 系统的大部分都需要重写。
- 旧的系统是专为个人出行而设计,它做了很多假设:
- 每辆车只有一个乘客,这种假设不适合 Uber Pool。
- 只有移动的人被考虑到数据模型和接口中。这限制了公司进军新市场和新产品,如需要运输的食品和箱子。
- 最初的版本是按城市进行分片。这具有很好的可扩展性,因为每个城市可以独立运行。但随着越来越多城市的加入,它变得越来越难以管理。城市有大有小,不同城市的交通负荷也不同。
- 因为很多东西都是被快速构建起来,因此一旦出现故障,都会相互影响。
新的调度系统
- 为了解决城市分片问题以及支持更多类型的产品,供应和需求的概念必须被扩展,所以一个供应服务和一个需求服务应该被创建。
- 供应服务跟踪所有供应的数量,以及它们的状态。
- 跟踪车辆需要建模很多属性:座位数,车辆的类型,车辆是否有儿童专座,是否能容纳一个轮椅,等等。
- 车辆的容量需要被跟踪。例如一辆车辆,可能有三个席位,但其中两个已经被占用了。
- 需求服务跟踪所有请求和订单,以及方方面面的要求。
- 如果一个乘客需要一个汽车座位,那么请求必须与库存相匹配。
- 如果乘客不介意以一个更便宜的价格分享车辆座位,这种情况也需要被建模。
- 如果有箱子或食物需要运送怎么办?
- 匹配所有需求与供应的方法是一种被称为 DISCO 的服务(调度优化)
- 旧的系统仅仅是匹配现有的供应量,这意味着仅仅针对在路上等待工作的车辆。
- DISCO 支持对未来的预测,一旦车辆变成可用,系统就马上利用这些信息。
- 汽车地理位置索引(geo by supply)。DISCO 需要一个地理空间索引,以基于所有供应的位置以及它们预计所在的地点来进行决策。
- 需求地理位置索引(geo by demand)。需求也需要地理空间索引
- 一个更好的路由引擎需要利用所有这些信息。
调度
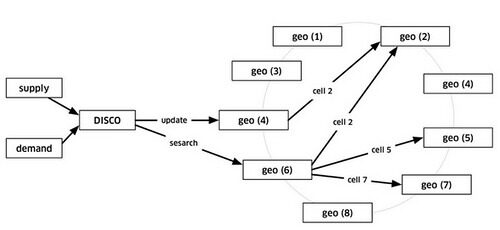
- 当车辆在周围移动的时候,位置更新将发送给 geo by supply。为了将乘客与司机进行匹配,或将汽车显示在地图上,DISCO 发送一个请求给 geo by supply。
- Geo by supply 进行一个简单的初步过滤,以获得附近的符合要求的候选车辆。
- 然后列表和要求被发送到路由 /ETA,以计算它们目前的距离有多近。距离并不是地理上的,而是通过道路系统计算得到。
- ETA 的排序结果被发送回供应系统,然后将结果提供给司机。
地理空间索引
- 必须有很高的可扩展性。设计目标是每秒处理百万次写入。当司机在移动的时候每 4 秒发送一次位置更新,写入速度由此计算出来。
- 对于读出来说,每秒读出的次数应该远多于每秒写入的次数,因为每个开放的 app 用户都在进行读出操作。大部分供应都处于繁忙状态,所以有效供应中只有一部分能够利用。
- 通过一个简单的假设,旧的地理空间索引运行良好,即它只追踪可调度的供应。大部分供应都处于繁忙状态,所以有效供应中只有一部分能够利用。在几个进程中存在一个全局索引存储在内存中。因此做一些简单的匹配是比较容易的。旧的地理空间索引只追踪可调度的供应。大部分供应都处于繁忙状态,所以有效供应中只有一部分能够利用。
- 在新的系统中,不同状态的所有供应都必须被跟踪。此外,它们的规划路由也必须被跟踪。
- 新的服务运行了数百个进程。
- 地球是一个球体。很难纯粹基于经度和纬度做计算和近似。所以 Uber 通过使用 Google S2 library 把地球分成小的单元。每个单元都有一个唯一的 ID 号。
- 使用一个 64 位数,地球上的每一平方厘米都可以被表示。对于每个单元的大小,Uber 分成了 12 个层次,从 3.31 平方公里到 6.38 平方公里,每个单元的形状和大小也不同,这些都取决于你在地球上的位置。
- S2 可以为一个具体的形状给出覆盖单元。如果你想在伦敦绘制一个半径为 1 公里的圆圈,S2 可以告诉你需要哪些单元来完全覆盖这个形状。
- 由于每个单元都有一个 ID 号,而 ID 号被用作一个分片密钥。当一个位置加入到供给中时,这个位置的 ID 就确定了。
- 当 DISCO 需要在位置附近找到供应的时候,以司机所在位置为中心进行画圈,计算不同位置的价值。使用圆圈区域内的单元 ID,集合所有相关的分片,然后返回供应数据。
- 所有都是可扩展的。通过增加更多的节点写入负载总是能被扩展。通过使用副本读出负载也能被扩展。如果需要更高的读出能力,可以增加更多的副本。
- 单元大小被固定在 12 个层次也存在不足。未来可能支持动态单元大小。
路由
- 存在几个高层次的目标:
- 减少额外的驾驶。理想的情况下,司机应该一直载着乘客,但现实中总是存在排队等事情,司机应该为所有事情获得报酬。
- 减少等待。司机应当等待的尽可能少。
- ETA 总量应该最小。
- 旧的系统按要求搜索当前可用的供应,然后找到最匹配的
- 仅仅查看当前可用的供应还不能做出好的选择。
- 我们的想法是,对于一个客户来说,问一个正载着乘客的司机比问一个闲置的但距离很远的司机要更好。
- 通过这个预测模型,动态条件能够被更好地处理。
- 例如,如果一个司机正好在一个顾客附近,但是另一个司机已经从远处被调度过来,没有办法改变这种调度决策。
- 举另一个例子,对于那些想分享车辆的顾客。在很多复杂的场景中,通过尽力地对未来进行预测,更多的优化是可能的。
- 当考虑箱子或食品的运输时,所有这些决策将变得更加有趣。
扩展调度
- 使用 Node.js 构建。
- 他们正在构建一个有状态的服务,因此无状态的扩展方法将无法正常工作。
- Node 是单进程运行的,因此需要设计方法让 Node 运行在一台机器的多个 cpu 上,以及运行在多台机器上。
- 使用 JavaScript 重新实现所有的 Erlang 是一个笑话。
- 扩展 Node 的解决办法是 ringpop,其是一个附带 gossip 协议的一致哈希 ring,实现一个可扩展的,容错的应用层分片。
- 在 CAP 术语中,ringpop 是一个 AP 系统, 牺牲一致性来换取可用性。这就容易解释偶尔出现些小的不一致比一个越变越差的服务要好。虽然偶尔犯错,但如果总体上越变越好,这是没关系的。
- ringpop 是一个可嵌入的模块,包含在每个 Node 进程中。
- Node 实例闲置在一个隶属集附近。
- 这是可伸缩的。通过添加更多的进程,可以完成更多的工作。添加的进程可以用来对数据进行分片,或者作为一个分布式锁定系统,或者为发布 / 订阅协调一个集合点。
- gossip 协议是基于 SWIM 。为减少收敛时间,有几个方面做了改进。
- 很多成员在周围闲置。通过加入越来越多的节点,它就实现了扩展的目标。SWIM 中的“S”代表可扩展。目前,它已经可以扩展到数千个节点。
- SWIM 结合了健康检查与成员变更作为同一协议的一部分
- 在 ringpop 系统中,存在包含 ringpop 模块的所有 Node 进程。他们闲置在当前的成员周围。
- 从外部看,如果 DISCO 要消耗地理空间,每个 Node 是等价的。一个健康节点是随机选择的。无论该请求出现在哪,都通过使用 hash ring 查询负责将请求转发到正确的节点。看起来像:
- 让所有这些 hop 和 peer 互相对话,可能听起来很疯狂。但它达到了非常不错的性能,例如,通过在任何机器上添加实例,服务可以被扩展。
- ringpop 是构建在 Uber 自己的 RPC 机制,称为 TChannel。
- 这是一个双向的请求 / 响应协议,它的灵感来自于 Twitter 的 Finagle 。
- 一个重要的目标是跨很多不同的语言控制性能。特别是在 Node 和 Python 中,很多现有的 RPC 机制工作得并不是很好。想要获取 Redis 级别的性能.TChannel 已经比 HTTP 快 20 倍。
- 希望获取一个高性能的转发路径,因此中间层可以让决策转发变得容易一些,而不必了解全部有效载荷。
- 希望获取合适的流水线,因此没有队头阻塞,请求和响应可以在任何时间往任何一个方向发送。
- 希望获取有效的载荷校验与跟踪,以及一流的功能。每个请求都应该是可追溯的。
- 希望获取一条迁移 HTTP 的清晰路径。HTTP 可以在 TChannel 中被自然封装。
- Uber 正在摆脱 HTTP 和 Json 业务。TChannel 上的所有技术正往 Thrift 上迁移。
- ringpop 基于持久连接处理所有 TChannel 中的 gossip。这些相同的持久连接用来扇出或转发应用数据。TChannel 也用于服务之间的对话。
调度可用性
- 可用性是相当重要的。Uber 有竞争对手,用户变更产品的成本是非常低的。如果 Uber 不行,利益就会流向其他竞争对手。
- 让一切可重试。如果有什么不能工作了,它必须是可重试的。这要求所有请求幂等。例如,重试一个调度,不能调度他们两次或刷取别人的信用卡两次。
- 使所有可关闭。故障是一种常见的情况。随机杀死进程不应该造成破坏。
- 崩溃。不存在正常关闭。正常关闭没有什么需要练习。需要练习的是当意外情况发生时。
- 小块。为了尽量减少故障的代价,将它们切为更小的块。在一个实例中处理全局业务是可能的,但是实例死亡的时候会发生什么呢?如果两个里面有一个失败,则能力会减少一半。因此,服务需要被切分。
- kill 一切。即使 kill 所有的数据库,也要确保出现故障时系统可以幸免。这需要对使用什么数据库做决策改变。他们选择 Riak 代替 MySQL。这也意味着使用 ringpop 代替 Redis。
- 将其切分成更小的块。通常,通过一个负载均衡器实现服务之间的对话。如果负载平衡器死去会怎么样?如果你没有实际处理过这种情况,你可能永远不知道。所以,你不得不 kill 负载平衡器。这时你怎么解决围绕负载均衡器关闭而出现的问题?负载均衡逻辑已经在服务中被采用以解决这个问题。客户端都被要求有一定的智能,以了解如何找到解决问题的途径。这在很大程度上类似于 Finagle 的工作方式。
- 为了扩展整个系统,并处理后端压力,基于一个 ringpop 节点集群,创建了一个服务发现和路由系统。
整个数据中心失效
- 这种事情并不会经常发生,但一些意想不到的级联故障是可能出现的,或者上游网络提供商也可能会不能工作。
- Uber 维护了一个备份数据中心,通过将所有工作转移到备份数据中心,可以实现及时切换。
- 问题是在进程中的出行数据可能还不在备份数据中心。代替数据副本,他们使用司机手机作为出行数据的来源。
- 当调度系统定期发送一个加密的状态摘要到司机的手机时,会发生什么。现在,让我们假设有一个数据中心失效。下一次,司机的手机发送一个位置更新到调度系统,调度系统会检测到它不知道这次出行的任何信息,这次就可以问状态摘要。
不足
- Uber 解决可扩展性和可用性问题的方法也存在不足,主要表现在 Node 进程在向彼此转发请求以及用大的扇出发送消息的过程中,存在潜在的高延迟。
- 在扇出系统中,很小的错误都有一个非常大的影响。一个系统的扇出越高,出现高时延请求的机会就越大。
- 一个好的解决办法是利用交叉服务器对请求进行备份。这作为第一等级的功能被融入到 TChannel 中。一个请求被发送到服务 B(1),同时也附带该请求被发送到服务 B(2)的信息。等待一些时间之后,请求被发送到服务 B(2)。当 B(1)完成请求时,它在 B(2)上取消这个请求。使用一些延迟意味着通常情况下 B(2)没有进行任何工作。但是,如果 B(1)失败了,则 B(2)将处理该请求,并以一个较低的延迟返回一个回应,如果 B(1)第一次尝试的过程中,发生超时,然后再让 B(2)尝试。
- 想了解更多,可以参考 Google On Latency Tolerant Systems: Making A Predictable Whole Out Of Unpredictable Parts 。
【编后语】
《他山之石》是 InfoQ 中文站新推出的一个专栏,精选来自国内外技术社区和个人博客上的技术文章,让更多的读者朋友受益,本栏目转载的内容都经过原作者授权。文章推荐可以发送邮件到 editors@cn.infoq.com 。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 )。
)。

暂无签名

腾讯大规模云原生技术实践案例集
本案例集详细阐释了 QQ、腾讯会议、和平精英、小红书、斗鱼、微盟等十多个亿级用户产品背后的大规模云原生...













评论