编者按:Hadoop 于 2006 年 1 月 28 日诞生,至今已有 10 年,它改变了企业对数据的存储、处理和分析的过程,加速了大数据的发展,形成了自己的极其火爆的技术生态圈,并受到非常广泛的应用。在 2016 年 Hadoop 十岁生日之际,InfoQ 策划了一个 Hadoop 热点系列文章,为大家梳理 Hadoop 这十年的变化,技术圈的生态状况,回顾以前,激励以后。
1. Hadoop YARN 生态系统介绍
为了能够对集群中的资源进行统一管理和调度,Hadoop 2.0 引入了数据操作系统 YARN。YARN 的引入,大大提高了集群的资源利用率,并降低了集群管理成本。首先,YARN 允许多个应用程序运行在一个集群中,并将资源按需分配给它们,这大大提高了资源利用率,其次,YARN 允许各类短作业和长服务混合部署在一个集群中,并提供了容错、资源隔离及负载均衡等方面的支持,这大大简化了作业和服务的部署和管理成本。
YARN 总体上采用 master/slave 架构,如图 1 所示,其中,master 被称为 ResourceManager,slave 被称为 NodeManager,ResourceManager 负责对各个 NodeManager 上的资源进行统一管理和调度。当用户提交一个应用程序时,需要提供一个用以跟踪和管理这个程序的 ApplicationMaster,它负责向 ResourceManager 申请资源,并要求 NodeManger 启动可以占用一定资源的 Container。由于不同的 ApplicationMaster 被分布到不同的节点上,并通过一定的隔离机制进行了资源隔离,因此它们之间不会相互影响。
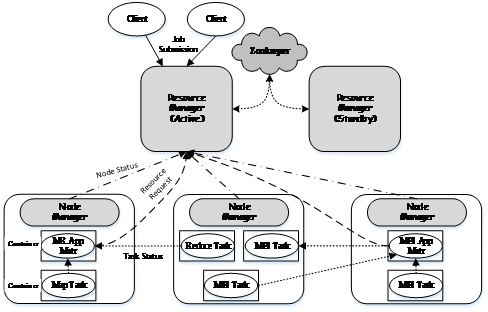
图 1 Apache YARN 的基本架构
YARN 中的资源管理和调度功能由资源调度器负责,它是 Hadoop YARN 中最核心的组件之一,是 ResourceManager 中的一个插拔式服务组件 。YARN 通过层级化队列的方式组织和划分资源,并提供了多种多租户资源调度器,这种调度器允许管理员按照应用需求对用户或者应用程序分组,并为不同的分组分配不同的资源量,同时通过添加各种约束防止单个用户或者应用程序独占资源,进而能够满足各种 QoS 需求,典型代表是 Yahoo!的 Capacity Scheduler 和 Facebook 的 Fair Scheduler。
YARN 作为一个通用数据操作系统,既可以运行像 MapReduce、Spark 这样的短作业,也可以部署像 Web Server、MySQL Server 这种长服务,真正实现一个集群多用途,这样的集群,我们通常称为轻量级弹性计算平台,说它轻量级,是因为 YARN 采用了 cgroups 轻量级隔离方案,说它弹性,是因为 YARN 能根据各种计算框架或者应用的负载或者需求调整它们各自占用的资源,实现集群资源共享,资源弹性收缩。
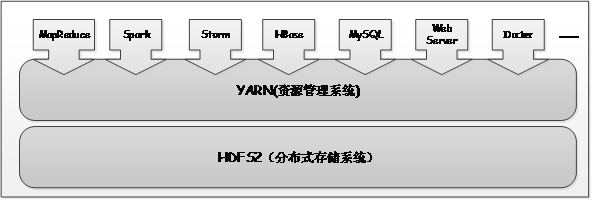
图 2 以 YARN 为核心的生态系统
2. Hadoop YARN 在异构集群中的应用
从 2.6.0 版本开始,YARN 引入了一种新的调度策略:基于标签的调度机制。该机制的主要引入动机是更好地让 YARN 运行在异构集群中,进而更好地管理和调度混合类型的应用程序。
2.1 什么是基于标签的调度
故名思议,基于标签的调度是一种调度策略,就像基于优先级的调度一样,是调度器中众多调度策略中的一种,可以跟其他调度策略混合使用。该策略的基本思想是:用户可为每个 NodeManager 打上标签,比如 highmem,highdisk 等,以作为 NodeManager 的基本属性;同时,用户可以为调度器中的队列设置若干标签,以限制该队列只能占用包含对应标签的节点资源,这样,提交到某个队列中的作业,只能运行在特定一些节点上。通过打标签,用户可将 Hadoop 分成若干个子集群,进而使得用户可将应用程序运行到符合某种特征的节点上,比如可将内存密集型的应用程序(比如 Spark)运行到大内存节点上。
2.2 Hulu 应用案例
基于标签的调度策略在 Hulu 内部有广泛的应用。之所以启用该机制,主要出于以下三点考虑:
(1)集群是异构的。在 Hadoop 集群演化过程中,后来新增机器的配置通常比旧机器好,这使得集群最终变为一个异构的集群。Hadoop 设计之初众多设计机制假定集群是同构的,即使发展到现在,Hadoop 对异构集群的支持仍然很不完善,比如 MapReduce 推测执行机制尚未考虑异构集群情形。
(2)应用是多样化的。Hulu 在 YARN 集群之上同时部署了 MapReduce、Spark、Spark Streaming、Docker Service 等多种类型的应用程序 。当在异构集群混合运行多类应用程序时,经常发生由于机器配置不一导致并行化任务完成时间相差较大的情况,这非常不利于分布式程序的高效执行。此外,由于 YARN 无法进行完全的资源隔离,多个应用程序混合运行在一个节点上容易相互干扰,对于低延迟类型的应用通常是难以容忍的。
(3)个性化机器需求。由于对特殊环境的依赖,有些应用程序只能运行在大集群中的特定节点上。典型的代表是 spark 和 docker,spark MLLib 可能用到一些 native 库,为了防止污染系统,这些库通常只会安装在若干节点上;docker container 的运行依赖于 docker engine,为了简化运维成本,我们 只会让 docker 运行在若干指定的节点上。
为了解决以上问题,Hulu 在 Capacity Scheduler 基础上启用了基于标签的调度策略。如图 3 所示,我们根据机器配置和应用程序需求,为集群中的节点打上了多种标签,包括:
- spark-node:用于运行 spark 作业的机器,这些机器通常配置较高,尤其是内存较大;
- mr-node:运行 MapReduce 作业的机器,这些机器配置是多样的;
- docker-node:运行 docker 应用程序的机器,这些机器上装有 docker engine;
- streaming-node:运行 spark streaming 流式应用的机器。
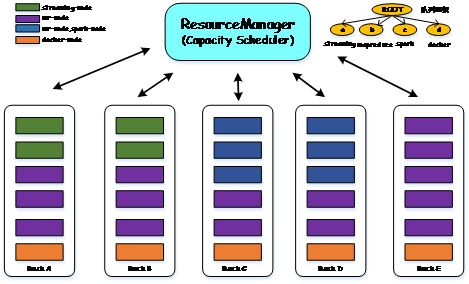
图 3 YARN 部署示例
需要注意的是,YARN 允许一个节点同时存在多个标签,进而实现一台机器混合运行多类应用程序(在 hulu 内部,我们允许一些节点是共享的,同时可以运行多种应用程序)。表面上看来,通过引入标签将集群分成了多个物理集群,但实际上,这些物理集群跟传统意义上完全隔离的集群是不同的,这些集群既相互独立又相互关联,用户可非常容易地通过修改标签动态调整某个节点的用途。
3. Hadoop YARN 应用案例及经验总结
3.1 Hadoop YARN 应用案例
Hadoop YARN 作为一个数据操作系统,提供了丰富的 API 供用户开发应用程序。Hulu 在 YARN 应用程序设计方面进行了大量探索和实践,开发了多个可直接运行在 YARN 上的分布式计算框架和计算引擎,典型的代表是 voidbox 和 nesto。
(1)基于 Docker 的容器计算框架 voidbox
Docker 是近两年非常流行的容器虚拟化技术,可以自动化打包部署绝大部分应用,它使得任何程序能够运行在资源隔离的容器环境,从而提供了一套更加优雅的项目构建、发布、运行的解决方案。
为了整合 YARN 和 Docker 各自的独特优势,Hulu 北京大数据团队开发了 Voidbox。Voidbox 是一个分布式的计算框架,利用 YARN 作为资源管理模块,用 Docker 作为执行任务的引擎,从而让 YARN 既可以调度传统的 MapReduce 和 Spark 等类型的应用程序,也可以调度封装在 Docker 镜像中的应用程序。
Voidbox 支持基于 Docker Container 的 DAG(有向无环图)任务和长服务(比如 web service),提供命令行方式与 IDE 方式等多种应用程序提交方式,满足了生产环境和开发环境的需求。此外,Voidbox 可以配合 Jenkins,GitLab,私有的 Docker 仓库完成一整套开发、测试、自动发布的流程。
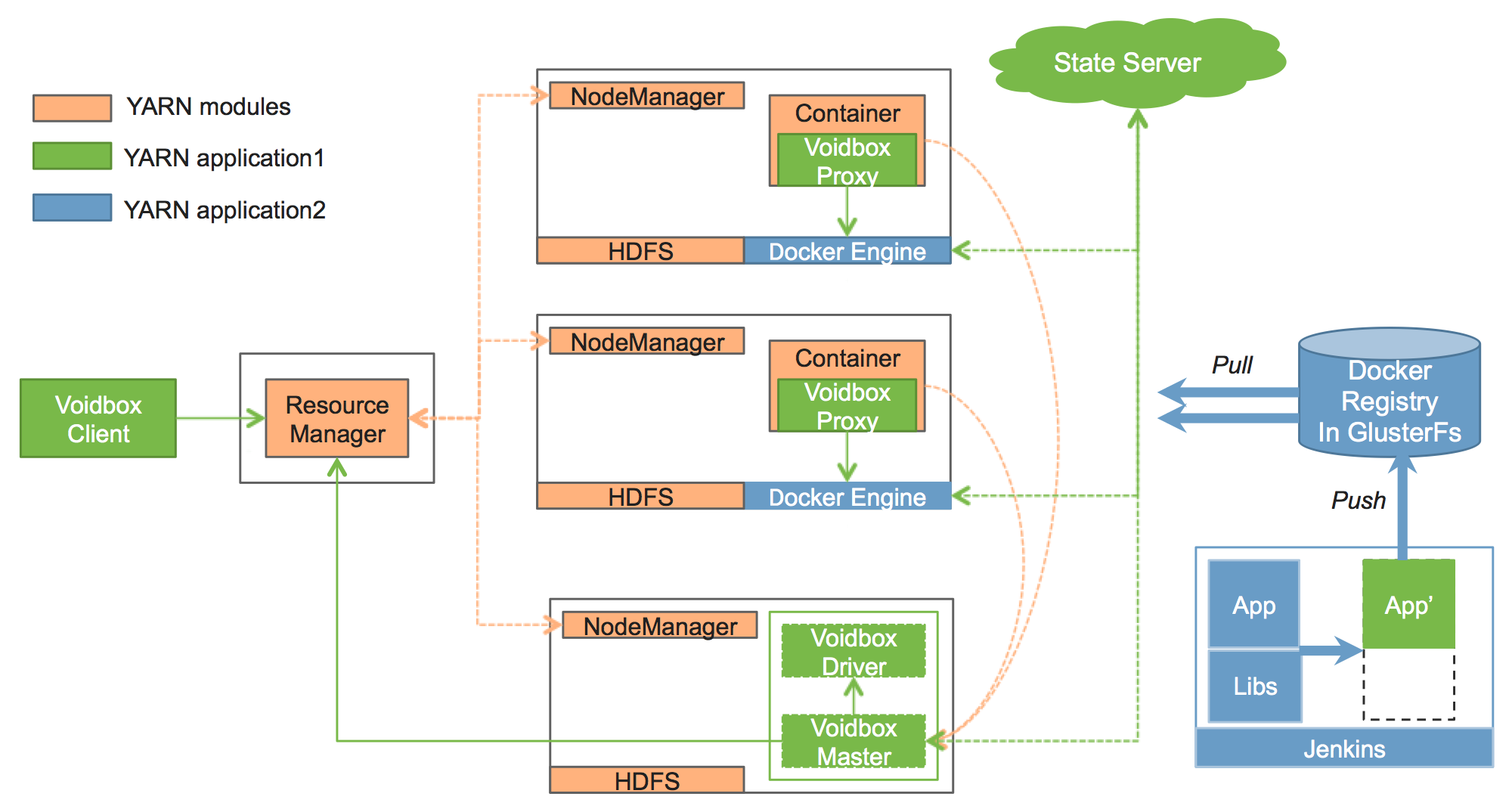
图 4 Voidbox 系统架构
在 Voidbox 中,YARN 负责集群的资源调度,Docker 作为一个执行引擎,从 Docker Registry 中拉取镜像执行。Voidbox 负责为基于容器的 DAG 任务申请资源,运行 Docker 任务。如图 4 所示,每个黑线框代表一台机器,上面运行着几个模块,具体如下:
- Voidbox 组件:
- VoidboxClient:客户端程序。用户可通过该组件管理 Voidbox 应用程序 (Voidbox 应用程序包含一个或多个 Docker 作业,一个作业包含一个或多个 Docker 任务),比如提交和杀死 Voidbox 应用程序等。
- VoidboxMaster:实际上是一个 YARN 的 Application Master,负责向 YARN 申请资源,并将得到的资源进一步分配给内部的 Docker 任务。
- VoidboxDriver:负责单个 Voidbox 应用程序的任务调度。Voidbox 支持基于 Docker Container 的 DAG 任务调度并且在任务之间可以插入其他用户代码,Voidbox Driver 负责处理 DAG 任务之间的依赖顺序调度以及运行用户代码。
- VoidboxProxy:是 YARN 与 Docker 引擎之间的桥梁,负责中转 YARN 发向 Docker 引擎的命令,比如启动或杀死 Docker 容器等。
- StateServer:维护各个 Docker 引擎的健康状况信息,向 Voidbox Master 提供可运行 Docker Container 的机器列表,使得 Voidbox Master 可以更有效地申请资源。
- Docker 组件:
- DockerRegistry:存储 Docker 镜像,作为内部 Docker 镜像的版本管理工具。
- DockerEngine: Docker Container 执行的引擎,从 Docker Registry 获取相应的 Docker 镜像,执行 Docker 相关命令。
- Jenkins:配合 GitLab 进行应用程序的版本管理,当应用版本更新时,Jenkins 负责编译打包,生成 Docker 镜像,上传至 Docker Registry,从而完成应用程序自动发布的流程。
类似于 spark on yarn,Voidbox 也提供两种应用程序运行模式,分别是 yarn-cluster 模式和 yarn-client 模式。yarn-cluster 模式中应用程序的控制组件和资源管理组件都运行在集群中,Voidbox 应用程序提交成功后,客户端可以随时退出而不影响集群中应用程序的运行。yarn-cluster 模式适合生产环境提交应用程序;yarn-client 模式中应用程序的控制组件运行在客户端,其他组件运行在集群中,客户端可以看到关于应用程序运行状态的更多信息,客户端退出后,在集群中运行的应用程序也随即退出,yarn-client 模式可以方便用户进行调试。
(2)并行计算引擎 nesto
nesto 是 hulu 内部一个类似于 presto/impala 的 MPP 计算引擎,它是专门为处理复杂的嵌套式数据而设计的,支持复杂的数据处理逻辑(SQL 难以表达),其采用了列式存储、code generation 等优化技术以加速数据处理效率。Nesto 架构类似于 presto/impala,它是无中心化的,多个 nesto server 通过 zookeeper 进行服务发现。
为了简化 nesto 部署和管理成本,hulu 直接将 nesto 部署到 YARN 上。这样,nesto 安装部署过程将变得非常简单:Nesto 安装程序(包括配置文件和 jar 包)被打成一个独立的压缩包存放到 HDFS,用户可通过运行一个提交命令,并指定启动的 nesto server 数目、每个 server 需要的资源等信息,即可快速部署一套 nesto 集群。
Nesto on yarn 程序由一个 ApplicationMaster 和多个 Executor 构成,其中 ApplicationMaster 负责像 YARN 申请资源,并启动 Executor,而 Executor 的作用是启动 nesto server,关键设计点在 ApplicationMaster,它的功能包括:
- 与 ResourceManager 通信,申请资源,这些资源需保证来自不同的结点,以达到每个节点只启动一个 Executor 的目的;
- 与 NodeManager 通信,启动 Executor,并监控这些 Executor 健康状况,一旦发现某个 Executor 出现故障,则重新在其他节点上启动一个新的 Executor;
- 提供一个嵌入式 web server,以便展示各个 nesto server 中任务运行状况。
3.2 Hadoop YARN 开发经验总结
(1)巧用资源申请 API
Hadoop YARN 提供了较为丰富的资源表达语义,用户可以申请特定节点 / 机架上的资源,也可以通过黑名单的方式不再接受某个节点上的资源。
(2)注意 memory overhead
一个 container 的内存是由 java heap,jvm overhead 和 non-java memory 三部分构成的,如果用户为应用程序设置的内存大小为 X GB(-xmxXg),则 ApplicationMaster 为其申请的 container 内存大小应为 X+D,其中 D 为 jvm overhead,否则可能会因总内存超出限制被 YARN 杀死。
(3) log rotation
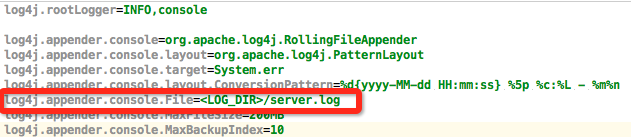
对于长服务而言,服务日志会越积攒越多,因而 log rotation 显得尤为重要。由于启动之前,应用程序是无法知道日志具体存放位置(比如哪个节点的哪个目录下)的,为了方便用户操作日志目录,YARN 提供了宏 <LOG_DIR>,当该宏出现在启动命令中时,YARN 会自动将其替换为具体的日志目录,比如:
echo $log4jcontent > $PWD/log4j.properties && java -Dlog4j.configuration=log4j.properties …
com.example.NestoServer 1>><LOG_DIR>/server.log 2>><LOG_DIR>/server.log
其中变量 log4jcontent 内容如下:
(4)调试技巧
NodeManager 启动 Container 之前,会将该 Container 相关的环境变量、启动命令等信息写入一个 shell 脚本,并通过启动该脚本的方式启动 Container。有些情况下,Container 启动失败可能是由于启动命令写错的缘故(比如某些特殊字符被转义了),为此,可通过查看最后执行脚本内容判断启动命令是否存在问题,具体方法是,在 container 执行命令之前添加打印脚本内容的命令。

(5)共享集群带来的性能问题
当在 YARN 集群中同时运行多种应用程序时,可能造成节点负载不一,进而导致某些节点上的任务运行速度慢于其他节点,这对于 OLAP 需求的应用是不能接受的。为了解决该问题,通常有两种解决方式:1)通过打标签的方式将这类应用运行到一些独享的节点上 2)在应用程序内部实现类似于 MapReduce 和 Spark 的推测执行机制,为慢任务额外启动一个或多个同样的任务,以空间换时间的方式,避免慢任务拖慢整个应用程序的运行效率。
4. Hadoop YARN 发展趋势
对于 YARN,会朝着通用资源管理和调度方向发展,而不仅仅限于大数据处理领域,包括对 MapReduce、Spark 短作业的支持,以及对 Web Service 等长服务的支持。
作者介绍
董西成, 就职于 Hulu,专注于分布式计算和资源管理系统等相关技术。《Hadoop 技术内幕:深入解析 MapReduce 架构设计与实现原理》和《Hadoop 技术内幕:深入解 析 YARN 架构设计与实现原理》作者,dongxicheng.org 博主。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




