使用了 O/R Mapping 工具的典型 J2EE 应用都会面临这样一个问题:如何通过最精简的 SQL 查询获取所需的数据。很多时候这可不是轻而易举的事情。默认情况下,O/R Mapping 工具会按需加载数据,除非你改变了其默认设置。延迟加载行为保证了依赖的数据只有在真正请求时才会被加载进来,这样就可以避免创建无谓的对象。有时我们的业务并不会使用到依赖的那些组件,这时延迟加载就派上用场了,同时也无需加载那些用不上的组件了。
典型情况下,我们的业务很清楚需要哪些数据。但由于使用了延迟加载,在执行大量 Select 查询时数据库的性能会降低,因为业务所需的数据并不是一下子获得的。这样,对于那些需要支持大量请求的应用来说可能会产生瓶颈(可伸缩性问题)。
来看个例子吧,假设某个业务流程想要得到一个 Person 及其 Address 信息。我们将 Address 组件配置成延迟加载,这样要想得到所需的数据就需要更多的 SQL 查询,也就是说首先查询 Person,然后再查询 Address。这增加了数据库与应用之间的通信成本。解决办法就是在一个单独的查询中将 Person 和 Address 都得到,因为我们知道这两个组件都是业务流程所需的。
如果在 DAO/Repository 及底层 Service 开发特定于业务的 Fetching-API,对于那些拥有不同数据集的相同领域对象来说,我们就得编写不同的 API 进行抓取并组装了。这么做会使 Repository 及底层 Service 过于膨胀,最终变成维护的梦魇。
延迟抓取的另一个问题就是在获取到请求的数据前要一直打开数据库连接,否则应用就会抛出一个延迟加载异常。
说明:如果在查询中使用预先抓取来获取二级缓存中的数据时,我们将无法解决上面提出的问题。对于 Hibernate 来说,如果我们使用预先抓取来获取二级缓存中的数据,那么它将从数据库而不是缓存中去获取数据,哪怕是二级缓存中已经存在该数据。这就说明 Hibernate 也没有解决这个问题,从而表明我们不应该在查询中通过预先抓取来获得二级缓存中的对象。
对于那些可以让我们调节查询以获取缓存对象的 O/R Mapping 工具来说,如果缓存中有对象就会从缓存中获取,否则采取预先抓取的方式。这就解决了上面提到的事务 /DB 连接问题,因为在查询的执行过程中会同时获取缓存中的数据而不是按需读取(也就是延迟加载)。
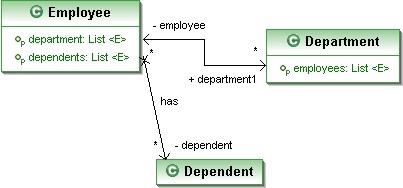
通过下面的示例代码来了解一下延迟加载所面对的问题及解决办法。考虑如下场景:某领域中有 3 个实体,分别是 Employee、Department 及 Dependent。
这三个实体之间的关系如下:
- Employee 有 0 或多个 dependents。
- Department 有 0 或多个 employees。
- Employee 属于 0 或 1 个 department。
我们要执行三个操作:
- 获取 employee 的详细信息。
- 获取 employee 及其 dependent 的详细信息。
- 获取 employee 及其 department 的详细信息。
以上三个操作需要获取并呈现不同的数据。使用延迟加载有如下弊端:
- 如果对实体 employee 所关联的 dependent 和 department 这两个实体使用延迟加载,那么在操作 2 和 3 中就会生成更多的 SQL 查询语句。
- 在多个查询语句的执行过程中需要保持数据库连接,否则会抛出一个延迟加载异常,这将导致数据出现问题。
但另一方面,使用预先抓取也存在如下弊端:
- 对 employee 所对应的 dependents 和 department 采取预先抓取会产生不必要的数据。
- 无法在特定的场景下对查询进行调优。
在 Repository/DAO 或底层服务中使用特定于操作的 API 可以解决上述问题,但却会导致如下问题:
- 代码膨胀——不管是 Service 还是 Repository/DAO 类都无法幸免。
- 维护的梦魇——不管是 Service 还是 Repository/DAO 层,只要有新的操作都需要增加新的 API。
- 代码重复——有时底层服务需要在获取的实体上增加某些业务逻辑,与之类似,还要在数据返回前检查 DAO/Repository 层的查询响应以验证数据可用性。
为了解决上面这些问题,Repository/DAO 层需要根据不同的业务情况执行不同的查询来获取实体。就像 Aspect 类所定义的那样,我们可以根据特定的操作使用不同的抓取机制来覆盖 Repository/DAO 类所定义的默认抓取模式。所有的抓取模式类都实现了相同的接口。
Repository 类使用了上述的抓取模式来执行查询,如下代码所示:
public Employee findEmployeeById(int employeeId) {
List employee = hibernateTemplate.find(fetchingStrategy.queryEmployeeById(),
new Integer(employeeId));
if(employee.size() == 0)
return null;
return (Employee)employee.get(0);
}
Repository 类中的 employee 的抓取策略需要根据实际情况进行调整。我们决定将 Repository 层的抓取策略调整到 Repository 和 Service 层外,放在一个 Aspect 类中,这样当需要增加新的业务逻辑时只需修改 Aspect 类并增加一个针对于 Repository 的抓取策略实现即可。这里我们使用了面向方面的编程(Aspect Oriented Programming)以根据业务的不同使用不同的抓取策略。
什么是面向方面的编程?
面向方面的编程(AOP)可以通过模块化的形式实现实际应用中的横切关注点,如日志、追踪、动态分析、错误处理、服务水平协议、策略增强、池化、缓存、并发控制、安全、事务管理以及业务规则等等。对这些关注点的传统实现方式需要我们将这些实现融合到模块的核心关注点中。凭借AOP,我们可以在一个叫做方面(aspect)的独立模块中实现这些关注点。模块化的结果就是设计简化、易于理解、质量提升、开发时间降低以及对系统需求变更的快速响应。
接下来读者朋友们可以参考 Ramnivas Laddad 所著的《 AspectJ in Action 》一书以详细了解 AspectJ 的概念以及编程方式,还可以了解一下 AspectJ 的开发工具。
Aspect 在抓取策略实现上扮演着重要角色。抓取策略是个业务层的横切关注点,它会随着业务的变化而变化。Aspect 对于特定的业务逻辑下使用何种抓取策略起到了至关重要的作用。这里我们将对抓取策略的管理放在了底层服务和 Respository 层之外。任何新的业务都可能需要不同的抓取策略,这样我们就无需修改底层服务或是 Respository 层的 API 就能应用新的抓取策略了。
FetchingStrategyAspect.aj
/**
Identify the getEmployeeWithDepartmentDetails flow where you need to change the fetching
strategy at repository level
*/
pointcut empWithDepartmentDetail(): call(* EmployeeRepository.findEmployeeById(int))
&& cflow(execution(* EmployeeDetailsService.getEmployeeWithDepartmentDetails(int)));
/**
When you are at the specified poincut before continuing further update the fetchingStrategy in
EmployeeRepositoryImpl to EmployeeWithDepartmentFetchingStrategy
*/
before(EmployeeRepositoryImpl r): empWithDepartmentDetail() && target(r) {
r.fetchingStrategy = new EmployeeWithDepartmentFetchingStrategy();
}
/**
Identify the getEmployeeWithDependentDetails flow where you need to change the fetching
staratergy at repository level
*/
pointcut empWithDependentDetail(): call(* EmployeeRepository.findEmployeeById(int))
&& cflow(execution(* EmployeeDetailsService.getEmployeeWithDependentDetails(int)));
/**
When you are at the specified poincut before continuing further update the fetchingStrategy in
EmployeeRepositoryImpl to EmployeeWithDependentFetchingStrategy
*/
before(EmployeeRepositoryImpl r): empWithDependentDetail() && target(r) {
r.fetchingStrategy = new EmployeeWithDependentFetchingStrategy();
}
这样,Repository 到底要执行何种查询就不是由 Service 和 Repository 层所决定了,而是由外面的 Aspect 决定,纵使增加了新的业务也无需修改底层服务和 Repository 层。决定执行何种查询的逻辑就成为一个横切关注点了,它被放在 Aspect 中。Aspect 会根据业务规则的不同在 Service 层调用 Repository 层的 API 之前将抓取策略注入到 Repository 中。这样我们就可以使用相同的 Service 和 Repository 层 API 来满足各种不同的业务规则了。
来看个具体示例吧,该示例会同时抓取一个 employee 的 Department 和 Dependent 的详细信息。我们需要对业务层进行一些变更,增加一个方法:getEmployeeWithDepartmentAndDependentsDetails(int employeeId)。实现新的抓取策略类 EmployeeWithDepartmentAndDependentFetchingStaratergy,后者又实现了 EmployeeFetchingStrategy 并重写了 queryEmployeeById 方法,该方法会返回优化后的查询,可以在一个 SQL 语句中获取所需数据。
由 Aspect 将上述的抓取策略注入到相关的业务中,如下所示:
pointcut empWithDependentAndDepartmentDetail(): call(* EmployeeRepository.findEmployeeById(int))
&& cflow(execution(* EmployeeDetailsService.getEmployeeWithDepartmentAndDependentsDetails(int)));
before(EmployeeRepositoryImpl r): empWithDependentAndDepartmentDetail() && target(r) {
r.fetchingStrategy = new EmployeeWithDepartmentAndDependentFetchingStaratergy();
}
如你所见,我们并没有修改底层业务与 Repository 层而是使用 Aspect 和一个新的 FetchingStrategy 实现就完成了上述新增的业务。
现在我们来谈谈关于二级缓存的查询优化问题。在上面的示例代码中,我们对 department 实体进行一些修改并配置在二级缓存中。如果对 department 实体采取预先抓取,那么对于同样的 department 实例,纵使它位于二级缓存中,每次也都需要查询数据库。如果不在查询中获取 department 实体,那么业务层就需要参与到事务当中,因为我们并没有将 department 实体缓存起来而是通过延迟加载的方式得到它。
这样,事务声明就从底层移到了业务层,虽然我们知道该业务需要哪些数据,但 O/R Mapping 工具却没有提供相应的机制来解决上面遇到的问题,即预先抓取缓存中的数据。
对于那些没有缓存的数据来说这种方式没什么问题,但对于缓存数据来说,这就依赖于 O/R Mapping 工具了,因为只有它才能解决缓存数据问题。
该示例附带的源代码详细解释了抓取策略。该zip 文件含有一个工程示例,阐述了上面谈到的所有场景。你可以使用任何IDE 或是使用aspectj 编译器从命令行执行代码。在执行前请确保jdbc.properties 文件与你机器上的信息一致并创建示例应用所需的表。
你可以使用 Eclipse IDE 以及 AJDT 插件运行代码,请按照下面的步骤进行:
- 解压缩下载好的代码并将工程导入到 Eclipse 中。
- 配置 Resources/dbscript 目录下的 jdbc.properties 文件中的数据库信息。
- 完成上面的步骤后请执行 resources\dbscript\tables.sql 脚本,这将创建该示例应用所需的表。
- 以 AspectJ/Java 应用的方式运行 Main.java 文件来创建默认数据并测试上面的抓取策略实现。
结论
本文介绍了如何通过不同的抓取策略从后端系统中获取数据,这是以模块化的方式根据业务需求实现的,同时又不会导致底层服务或 Repository 层过度膨胀。
关于作者:Manjunath R Naganna 目前供职于阿尔卡特朗讯公司,担任高级软件工程师一职,尤其专注基于 Java/J2EE 的企业应用设计与实现。他感兴趣的领域包括 Spring Framework、领域驱动设计、事件驱动架构以及面向方面的编程。对于 Hemraj Rao Surlu 对本文所做的编辑与排版工作,Manjunath 表达了自己的谢意,同时他也很感谢自己的领导 Ramana 与 Saurabh Sharma 在百忙之中抽出时间对本文进行审阅并提出很多重要的反馈信息。
查看英文原文: Fetching strategy implementation in a J2EE application using AOP 。
感谢宋玮对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家加入到 InfoQ 中文站用户讨论组中与我们的编辑和其他读者朋友交流。




