
上周末,应邀在 Hacker News 上海聚会和 Ruby 上海活动上做了『风车』架构介绍的分享,在此感谢各位组织者和活动场地提供方。
风车这个项目开始于 2011 年 11 月份,之前叫做 Pragmatic.ly。从第一天开始我们基本上就定了大致的框架结构,在今天回头看,基本上整个架构都没有什么变化,可以算是个很成熟和很适合时代的方案,☺。
最近一两年,作为技术人员,我们都能很明显的感觉到前端技术的飞速发展,比如 HTML5 支持,移动端优先、响应式界面设计以及层出不穷的各种客户端框架。而所有这些,都是基于一点:浏览器的高速发展。Chrome、Firefox、Safari、Opera 甚至于 IE,最近几年发展的都很快,不夸张的说,这些浏览器已经不再是浏览器,而是成为开放平台,有各自的扩展插件机制。这些极大地改变了网站开发的方式,网站开始应用化。
风车即是如此,设计得非常接近桌面应用,比如下面这些特点:
- 重客户端,所有的业务逻辑都在客户端,响应非常迅速
- 单页系统,项目内操作不需要刷新页面,操作非常流畅
- 三栏布局,左中右栏自左向右各司其职,信息非常清晰
- 实时更新,项目内任何更新都会实时的同步到你的页面
而在这个设计的背后,就是其本身的技术栈。
总览
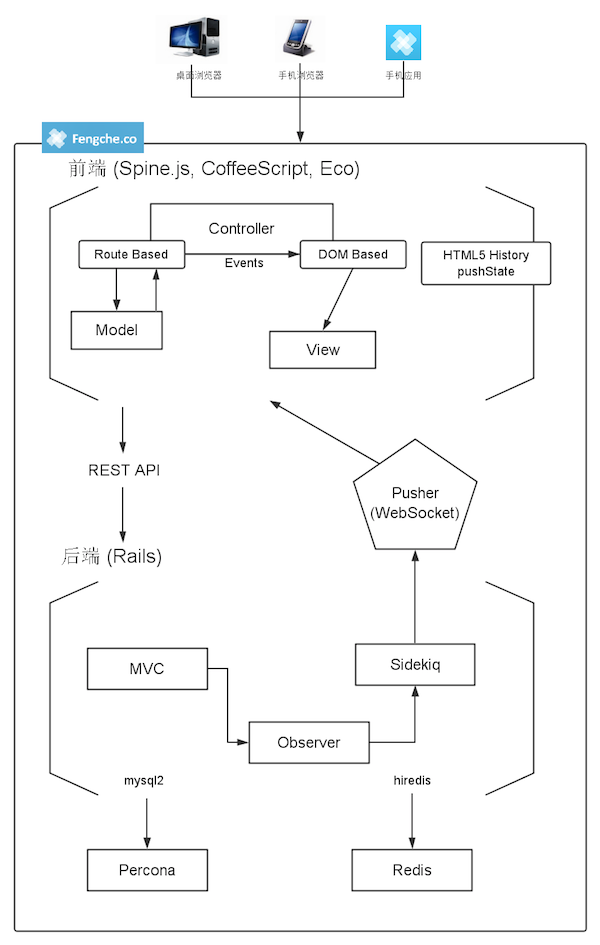
风车在客户端使用的是 Spine.JS,后端使用的是 Ruby on Rails。实时消息同步用的是 Pusher。(三个里面有两个因为莫名其妙的原因打不开… -.-)
Spine.js 是一个轻量级的 MVC JavaScript 库,由《Javascript Web Applications》的作者 Alex MacCaw 基于 Backbone.js 改良。Spine 库使用 CoffeeScript 编写,整体代码量仅一千行左右,比起 Angular.js, Ember.js 这些框架来说少的多,非常容易学习和上手。
Rails 目前我们在使用的还是 3.2 版本,基本上是用来做 API 服务器,只管数据,不做逻辑。上周活动有些朋友也问到基本只做 API 服务器,为啥不选用更轻量的方案如 Sinatra,Grape 之类。一是从开发上来说,Rails 默认这一套用起来比较舒服,我们除了 API 之外还有一些第三方应用的集成和管理性功能,所以整体建站更方便。二是我们目前还没遇到大的性能上问题,所以没必要去更换。如果下一阶段真有需要了,会把 RESTful API 专门独立出来。
Pusher 是一个基于 WebSocket 的实时消息推送服务,集成到应用中也非常方便。即使在不支持 WebSocket 的浏览器里(对,没错,说的就是 IE),也提供默认的备用方式,可选择 Flash Socket 或者 SockJS。整体体验来说,Pusher 算是一个很不错的解决方法,轻、快,给我们节省了大量开发时间,只需要关注产品的核心价值。不过如果你的应用对于实时性要求非常严格,比如交易系统,可能 Pusher 的稳定性还不够符合你要求,因为你懂的一些网络原因。
当浏览器刷新页面的时候,会向服务端发起一个请求。服务端收到这个请求后,会返回一个不带数据的纯 HTML 空模板。然后客户端渲染模板后,再次通过 RESTful API 向服务端请求项目的真实数据(JSON 格式),再由客户端对数据做处理并呈现,得到用户真正看到的页面。之后,会跟 Pusher 服务器建立一条 WebSocket 的长连接,接收推送信息。当服务端有任何更新的时候,会发送消息到 Pusher 服务器,再由 Pusher 服务器传输到客户端浏览器,页面同时也得到更新。以上,就是一个简单的过程。
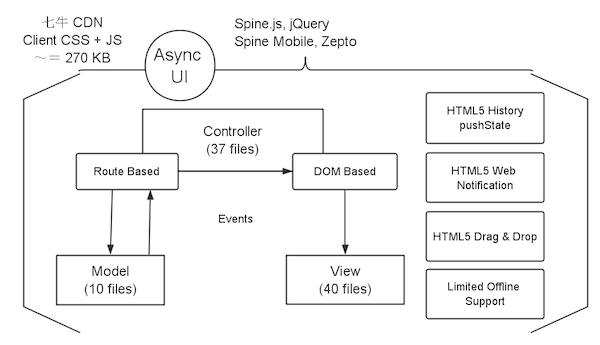
客户端
上面也介绍过了,风车的前端用的是 Spine.JS 和 jQuery。在移动端稍微有点不同,是 Spine.JS Mobile 和 Zepto。在目前这个时候,我计算了一下,压缩后的 JS 和 CSS,包括所有第三方的库,已经将近 270 KB。这里感谢一下七牛云存储,风车的这些静态文件因他们的 CDN 服务,能很快的下载到用户端,加速页面的加载。
Spine.JS
Spine 上面已经介绍了不少,这里再介绍一个我很喜欢的特性:_Asynchronous interfaces_。当我们决定把逻辑从服务端移到客户端的时候,就是要提高用户的整个使用体验,要能非常迅速的对用户行为做出响应。所以,当用户做了一个操作更新数据的时候,不要再显示个 loading spinner,让用户去等待数据更新完毕,而是应该立刻给出页面的变化。这就是异步 UI,通过解耦客户端 UI 交互跟服务端数据同步,保证了交互的流畅性。
CoffeeScript + Eco
这里真的很佩服 DHH,当时力排众难固执地在 Rails 3 里面默认加入了 CoffeeScript,让 CoffeeScript 迅速地流行起来。Coffee 是那种一用就能上瘾的东西,我们几乎所有的 JS 代码都是用 Coffee 写的,最后编译出来的纯 JS 代码也很具有可读性。即使是让人诟病的调试复杂度,对于熟悉代码结构和 Coffee 的人来说也从来不是问题,更不用说现在还提供了 Source Maps 的支持。 Eco 是 “Embedded CoffeeScript templates”,语法跟 ERB 很像,作为一个 Ruby 开发人员没法不喜欢,:)
Model-View-Controller
从 MVC 框架来说,Controller 层,主要负责接受请求并处理请求,对应到客户端,请求就是事件,所以 Controller 负责对 DOM 事件的处理和 Router 事件的处理。基于此,风车前端有两种类型的 Controller,一种是跟页面 DOM 打交道的,一种是跟路由打交道的。基于 DOM 的 Controller 是按照页面的结构设计,每个 Controller 对应于一个单独的 DOM 模块,比如风车里面的侧边栏对应一个 Controller,侧边栏里面的任务列表部分和团队成员部分又分别对应一个 Controller,等等。这些 DOM Controller 会监视 DOM 上事件的发生,以及 DOM 对应的数据的更新。而基于 Router 的 Controller 是按照 URL 来设计,用来监视页面 URL 的变化,比如每一项任务都对应于一个单独的 URL,那么点击行为会导致 URL 的变化,这个变化会被 Router Controller 捕捉到,执行相应的操作,整个过程跟 Dom 没有任何关系。
Model 层,负责所有跟数据有关的处理。绝大多数时候,数据是 URL 对应,所以 Model 层绝大多数时间只需要跟 Router Controller 交互。Router Controller 从 Model 准备好数据后,会触发一个事件,交由 DOM Controller 去渲染相应的页面。
除了 MVC 三层之外,风车在设计上还使用了很多 HTML5 的特性,除了之前介绍的 WebSocket 之外,还有 History、Web Notification、Drag & Drop 和 LocalStorage。
HTML5 History pushState
History 是 Router Controller 的实现基础。我们都已经很习惯了浏览器页面的前进后退来访问历史页面。而很多富客户端应用因为 URL 没有发生改变,就很难支持这点。HTML5 History 就是为了解决这个问题,而在 JavaScript 端提供的一个实现。当我们访问下一个页面的时候,会 push 这个 URL 到栈里,当我们按后退时,会 pop 出这个 URL。Router Controller 需要定义一系列要响应的 URL,这样一旦匹配,就会截获页面跳转,转而去执行相应的代码,渲染出对应数据。所以在风车里,每次页面的修改都是对应一个唯一的 URL,这样除了可以前进后退外,还有个额外的好处是刷新页面后,总是可以回到刷新前的 URL。当然,需要在客户端和服务端用同一套路由。
HTML5 桌面通知
Web Notification 是桌面端的通知,当一个跟用户相关的事件发生时,比如团队里有人分配了一个任务给你,或有人在讨论里 @ 了你,就会收到一个通知。目前 Chrome 和 Safari 已经直接支持 Web Notification,Firefox 最新版已经支持,老版本需要安装一个插件支持,而 IE 在 10 以上才支持,而且必须加入 pinned site 列表里。具体的可以参考我之前在风车官方博客里面写的这篇详细介绍 HTML5 Web Notification 的文章。
HTML5 拖放
Drag & Drop 之前已经有很多 JS 的实现了,比如 jQuery UI 里面就有 DnD 的支持,HTML5 在规范制定的时候,也把 DnD 加入了进来,做了标准化。风车里面是用的 HTML5 的规范,主要用于把任务拖到某个任务列表里,某个成员里和拖到同个列表不同的位置。
有限离线支持
上面也介绍了,Spine 里面有个特性是异步 UI,但是如果我们跟服务器之间的连接出现短暂的问题,比如网络断了,那么就会在客户端更新了,但是服务端却没有同步到,这样用户一刷新,就会发现丢数据了。我们针对这个情况,一般发现同步失败,就先把未同步的数据放到 LocalStorage 里面,每隔一段时间重试一下,直到同步成功。所以,在页面加载后,即使在离线情况下,短暂时间使用风车也不是问题。但是,因为我们目前实现的很有限,也没做版本控制系统,所以在极端情况下,比如团队里不同人对同一个任务做出了更新,后同步的数据会覆盖掉先同步的。因为这种情况很少发生,所以目前我们没花大时间去改进它。
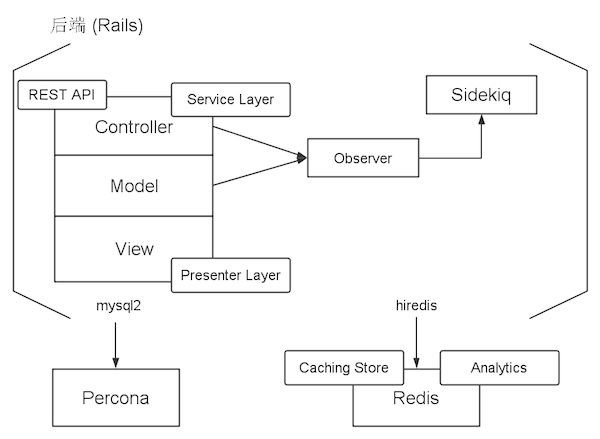
服务端
风车的整个服务端是基于 Ruby on Rails,前面也已经给了一些介绍。我在之前的重构 Rails 项目之最佳实践介绍了一些可以用来写出更好的代码结构的方法。在风车中,我们也在标准的 MVC 三层之外,加了 Service 层和 Presenter 层。
Service Layer
为了保持 Controller 结构的尽可能简单,对于一些复杂的又不仅属于某个 Model 的请求处理逻辑,我们在 Controller 和 Model 之间引入了新的一层:Service 层。举个例子,风车目前集成了 GitHub、GitLab 和 BitBucket 的 hook。当用户向远端推送提交的时候,GitHub/BitBucket 会向风车的服务器发起一个请求,包含这些提交的信息。在风车这边收到这些请求的时候,首先需要去做特征判断,查明是来自于哪一个服务。然后分析推判断送消息,是否绑定到具体的任务。最后根据消息,判断是否要更新状态和创建讨论。整个处理的逻辑比较复杂又相对独立,涉及多个 Model 并且有多种不同的策略,非常适合抽象成一个 Service。另外的一些场景比如 Analytics Service,Password Service,Email Handler Service 等。
Presenter Layer
熟悉 Rails 开发的朋友一般都知道,View 层应该仅仅是用来显示数据,我们应该避免在 View 里面有逻辑。但是,很多时候会不可避免的会有一些很难维护的 View。去年 RubyConf China 2013,来自台湾的讲师 xdite 就介绍了如何写出可维护的 View,详见这里。不过对于风车而言,大量的 View 是在客户端,服务端很少,只是提供了一些数据准备,所以没用多少技巧。只是因为数据准备涉及到了多个 Model 的数据以及来自于 Redis 数据库里面的数据,所以我们独立出了 Presenter Object,用来管理这些逻辑,而不是放在 View 里面。
Observer
Observer 一般而言是监控数据的,当数据创建、更新或者删除时,可以执行一些相应的操作,比如用户注册后可以发送注册邮件。但是风车里面的 Observer 有些许不同,除了监控数据以外,我们还监控 Controller,来了解数据变化相对应的请求信息,比如操作用户是谁。这里主要借鉴了 Rails 自带的 Caching Sweeper,后面我们会专门写一篇文章来介绍。
Sidekiq
Sidekiq 是一个简单强大的消息队列系统,目前可以说是 Ruby 世界里后台处理的首选。同类的选择还有 resque、delayed_job 等,但是 Sidekiq 之所以能迅速成为首选是基于两个特点,一是基于 Actor 模式的并行处理机制,二是基于 Redis 的 pubsub 模型,所以能用更少的内存资源来获得一样的处理能力。在风车里只要是能延迟的操作我们就会全放到后台执行,比如发送通知、数据统计、创建初始数据等等。这样子,我们就能让每个请求在最短的时间内完成,提高整个系统的吞吐量。Sidekiq 在收到消息后会在后台处理,即使失败了也会重试,更加可靠。
Percona
风车的主数据库还是使用了关系数据库 Percona,是基于 MySQL 的一个分支,但是因为使用了 Percona 公司自己研发的 XtraDB 存储引擎,具有更好的性能。另外一点好处是 Percona 号称是最接近官方 MySQL Enterprise 发行版的版本,可以完全与 MySQL 兼容,我可以很方便的做切换而不用修改代码。
Redis
Redis 在风车里面主要是两个用途:1. 用作 Caching Store,存储 View Cache 和 Record Cache 2. 加速数据访问,在内存中存储一些会频繁读写的数据,减少对 Percona 数据库的访问,比如 UID 映射表、统计信息之类。使用 Redis 而不是 Memcached 的原因是首先 Redis 的数据是持久的,不会因为重启而丢失,因为我们有一些无法立刻重建的数据,比如用户的在线状态,第二点是 Redis 可以用来存储一些复杂数据结构,比如 List 和 Set,对于统计信息来说非常合适。今年 Redis 3.0 有望正式发布,到时有 Redis Cluster 的支持,可以期待带来更好的性能。
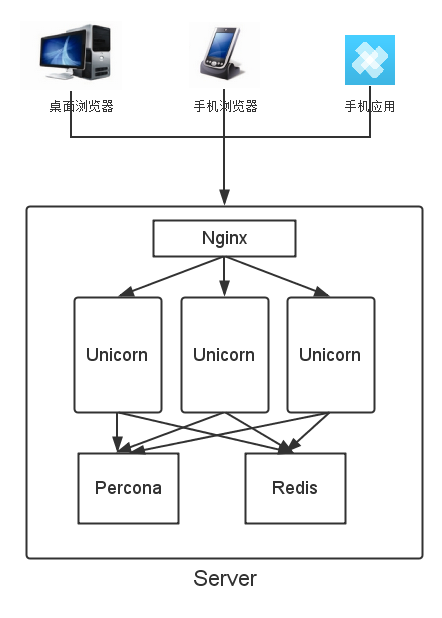
扩展性
以上但是风车整体的技术架构,不复杂,但是非常实用。目前我们只使用了 Linode 上的单台机器,因为业务逻辑主要在前端,后端以 API 为主,所以性能问题并不突出。但是还是得承认健壮性有所缺乏,一旦后台某点发生故障,比如数据库或者 Redis,都会影响到服务的正常运行。下面来谈谈后台架构的一些可扩展性,来源于我之前的工作,但并没有上风车实践。
Rails
Rails 一直被人诟病的是其的性能,最近也经常能看到不少类似 XX 应用从 Rails 迁移到 Node.js 后获得 YY 倍的性能之类的报道。上期 Teahour 跟朴灵也聊到,Node.js 是从框架上用事件驱动和非阻塞来保证高性能,减少程序员犯错。同样的效果,Ruby 也能做到,但是对程序员本身的要求会更高。几种可能的扩展方式。
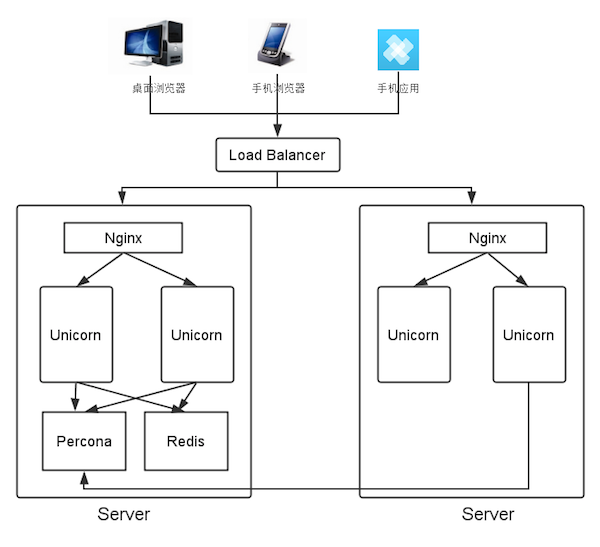
- Rails 应用本身很好水平扩展,我们目前用 Unicorn 作为应用服务器,使用 Nginx 作为前端服务器。Unicorn 是由 GitHub 开源的一个基于 Rack 的高性能 HTTP 服务器,Nginx 作为反向代理,通过 Unix Socket 或者 TCP 协议跟 Unicorn 通讯。所以,如果短期内流量增多,扩充机器性能是一个办法,也可以通过增加机器,在前端加负载均衡,后端加 Unicorn 进程数来提交系统吞吐量和处理能力。
- 从 Rails 应用中抽取 API 部分为独立的应用,因为前端和后端之间基本只有 API 通讯。API 部分可以使用更高性能的方案,比如 Ruby 世界里有 Goliath + Grape 。Goliath 跟 Node.js 的概念一样,都是异步非阻塞的高性能 HTTP 服务器。而 Grape 是非常轻量级的 API 框架。
- 当然也可以考虑用 JRuby 或者 Node.js 或者 Go,:p
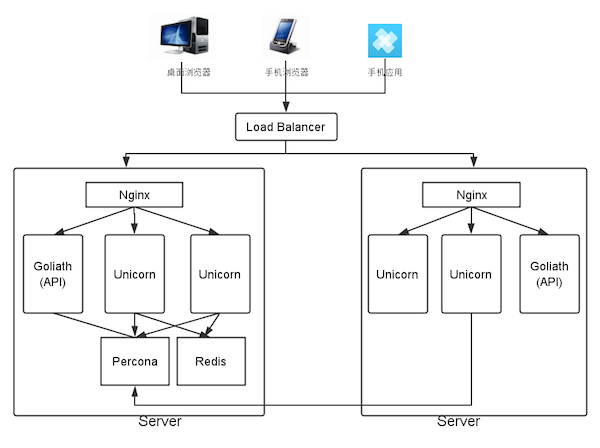
Percona
目前在数据库方便的优化不多,我们也只是在优化索引和尽量避免连表查询。不过风车这个应用性质决定了不会是大数据,尤其是我们有些数据还不通过 Percona 存储。惭愧的是目前风车只是做到了数据的备份,但是还没有做 Cluster、主从、读写分离这些,不过都是会在遇到瓶颈时去尝试的。跳出关系型数据库,也许可以尝试一些文档数据库如 Mongo,应该也蛮合适的。
Redis
Redis 对于风车最大的作用是用来存储分析数据,节省掉数据库的访问和运算。因为 Redis 在 2.X 版本的时候没有 Cluster 实现,目前要做扩展只能在上层通过一致性哈希来获得有限的支持。3.0 目前已经发布 beta 版,内建的 Cluster 功能还在测试中,值得期待。另外对于 Redis 的主从复制,针对不同的应用场景会有不同的问题,比如 Redis 持久化策略、主从间同步策略等。在百万级别以上的数据上,Redis 就必须要调优了,同时,每次重启的时候也很痛苦,重建库要花不少时间。所以,有可能的话,对数据进行分片,尽量只让新鲜数据或者常用数据留在内存里,陈旧数据可以存储到磁盘上。
Sidekiq
Sidekiq 本身是基于线程的单进程运行模式,使用 Redis 做为消息队列。所以,Sidekiq 的并行能力很容易提升,只要多起几个进程就可以了,前提是数据库和 Redis 都扛得住,当然还有内存这些硬件资源。
Pusher
这个就是使用在线服务的好处,花点钱把性能问题留给他们吧,价格也算合理,:)
结语
目前来说,我相信这套架构还能让我们撑不少时间,也可以很方便的做水平扩展。对于一个技术驱动型团队,这是我们的优势,也是对待事情应有的态度。感谢所有风车使用到的开源软件和在线服务,才能让我们这么"小"的一个团队,能有更好的时间专注在产品的核心价值上,节省时间去做"大"事。作为一个团队协作工具,风车也想帮助你们更好的工作。如果你懂得时间的价值,那么你应该使用风车来管理你的项目。风车,让协作更简单,让协作更高效。
有想法吗?现在就试试吧!
感谢丁雪丰对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论