如果你的团队正设法将现存应用从单件嵌套设计转为依赖注入(DI),但事实证明很困难的话,你会对这篇文章倍感亲切。如果不用触及大部分源码就能完成修改,那自然再好不过,但当你把大型应用程序翻新为 DI 的时候,做到这一点着实不易。本文同样适用于将遗留系统转为 DI 的一般情况,也适用于 Java、.Net、Python、Ruby 等语言,尽管文章是以 Google 的 Java DI 容器(Guice)命名的。这里有点标题党的意思,PicoContainer、Spring 之类放在这个标题里不如 Guice 那么合适。
单件出现
单件和静态状态已经因问题重重而被指责了多年。
毫无疑问,使用 DI 的应用要比东一块西一块的单件应用有更可测、更清晰的架构。尽管在时间压力下,通常情况是用简单的单件来连接各种各样的组件比较容易。但应用中的单件数目,会从开始的一两个变成最后的数十甚至数百个,直至整个团队表明代码是不可维护的。老板不允许重新编写应用却期望有 DI 的特性,如此看来,朝着 DI 的方向重构当前的代码集是务实的做法。
 一旦你决定改变方向、想进入 DI 的天堂,你就必须要知道该走哪条路。当然,你可以停止功能开发、缺陷修复,一门心思地去实现 DI,但这并不是正确的做法。相反,你希望能同时交付新的功能,而且经验表明,在一两周之内使用起来 Guice(或 Spring 等)的承诺往往会在好几个月之后才能兑现。即便仅在一个分支上进行 DI 重构的工作,这跟仍然在进行功能开发和缺陷修复的其他分支也是背道而驰的,当 DI 重构完成时就会有合并错误的风险。
一旦你决定改变方向、想进入 DI 的天堂,你就必须要知道该走哪条路。当然,你可以停止功能开发、缺陷修复,一门心思地去实现 DI,但这并不是正确的做法。相反,你希望能同时交付新的功能,而且经验表明,在一两周之内使用起来 Guice(或 Spring 等)的承诺往往会在好几个月之后才能兑现。即便仅在一个分支上进行 DI 重构的工作,这跟仍然在进行功能开发和缺陷修复的其他分支也是背道而驰的,当 DI 重构完成时就会有合并错误的风险。
而且从哪里开始着手也不清晰。你是先在 main() 方法中插入一个空的 DI 容器吗?还是从 Web 层开始,从那里接近 DI?抑或是先用单件查找的结果填充 DI 容器,写上 TODO 注释表示以后再完善吗?无论哪种方法都是杂乱并令人生厌的。
用“Service Locator”作为到依赖注入的垫脚石
Martin Fowler 在 2003 年写了一篇关于依赖注入的权威文章。当时DI 领域尚不成熟,Martin 论述了服务定位器是一个比较有价值的替代选择。当然,对不同的人来说,服务定位器意味着不同的东西,我们先假设它表示一个带有像下面一样方法的类(更确切地说它本身是一个单件)……
public Object getService(String serviceName) {<br></br> // etc<br></br>}<p> 或 </p><p>public T getService(Class<t> serviceType);<br></br> // etc<br></br>}</t></p>其思想是在程序的入口(main 方法?),把与服务名对应的实例填充进服务定位器,单元测试的时候可以混合使用真实或模拟的实例来填充。凡是在遗留代码集中出现单件查找的地方,稍加修改即可换用服务定位器来查找同样的组件。这种方法只适用于“作用域范围为整个应用(application scoped)”的服务 / 组件。现代 Web 框架还有会话、请求等不同作用域范围的组件,框架会在进入作用域的时候相应地处理依赖注入。既然你正在朝着 DI 方向前进,那么显然你的应用中还没使用任何现代的 Web 框架,那就只好将就一下了。服务定位器需要在启动的时候填充……
public void setService(String serviceName, Object implementation) {<br></br> // etc<br></br>}为了安全,你需要用一种机制来锁定服务定位器并使之只读。应该在 main 方法结束的地方、调用任何启动生命周期方法之前调用 lock() 方法锁定服务定位器,这样可以有效地防止误用。
把服务定位器放进来仅仅是一个开始。接下来逐步用服务定位器的 getService() 方法替换掉单件的 getInstance() 方法。实际上这些单件现在已经变成了“被管理的单一实例”。你可能会发现这是分离组件的接口和实现的好时机。分离组件的接口和实现的一个原因是为了使模拟更容易(具体请 Google 搜索 EasyMock、JMock 或 Mockito),因为很显然,你可以趁机提高应用的测试覆盖率。
当你把单件消灭完毕之后,应该重新检查一遍所有调用服务定位器的代码片段。每当需要组件 / 服务的时候,都会出现 getService 调用,甚至可能在一个类中出现多次(而且每次超出作用域范围的时候组件都被垃圾回收)。如果出现这种情况,那么聪明的做法是只在构造函数中调用一次 getService,然后将结果储存为成员变量。
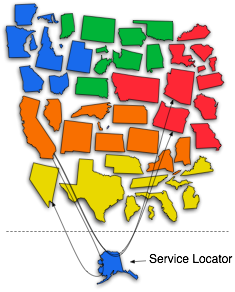 在上面那个花俏的服务定位器组件图中,California(负责农业和高科技产业的组件)需要 Nevada 提供赌博游戏机的功能,还需要 Oregon 的榛果和 Arizona 的高科技。其他的没有依赖关系没画出来,你明白意思就行了。
在上面那个花俏的服务定位器组件图中,California(负责农业和高科技产业的组件)需要 Nevada 提供赌博游戏机的功能,还需要 Oregon 的榛果和 Arizona 的高科技。其他的没有依赖关系没画出来,你明白意思就行了。
如前所述,最好分成一系列小的提交来完成这些改动。小的改动更容易与其他改动合并。团队可以一边改进功能、修复缺陷,一边完成重构。回退的风险会很低。如果你同时乘机给新分离的组件增加小的单元测试,回退的风险会变得更低。
首先是有依赖性最小、被依赖最多的那个组件
迈向服务定位器设计、摆脱单件血统的第一个组件是不依赖于其它单件、但被其它单件依赖的组件。
这个组件是最容易摘到的果子——依赖性最小、被依赖最多。
它也会是小的单元测试最容易获得高覆盖率的那个组件。这个时候可能要让模拟库参与进来。由于你是处理一个就提交一个,其它的组件接着就会成为“依赖性最小、被依赖最多”的组件。
回过头来再看看 Guice
既然你的应用由许多通过单一服务定位器访问的组件组成,那就该是时候使用 Guice(或者你喜欢的 DI 容器)了。下一步开始把组件从服务定位器中移出、转入 Guice 的模块(或者你喜欢的容器中对应的东西)。
做这件事情最有条理的方法是在组件的构造函数中找到执行服务定位器查找的语句,把该语句移到实例化该组件的类中。同时给构造函数加上相应的参数,给构造函数的调用者加上一个成员变量来体现依赖关系。就这样一个个组件改下去,迟早沿着依赖树到达 main 方法。到那个时候,它们就能安全地变为由 Guice 管理的了。
当所有一切都由 DI 容器管理之后,服务定位器就可以完成它的历史使命并被删除了。
 有些类 / 组件可能会出现参数列表变得太长的现象。这很可能意味着程序的设计存在问题。这个时候 Facade 模式常常是正确的选择。
有些类 / 组件可能会出现参数列表变得太长的现象。这很可能意味着程序的设计存在问题。这个时候 Facade 模式常常是正确的选择。
许多公司用这一有序的方法已经取得了一些成功。原先单件套单件重重叠叠的数百个组件,现在变成了轻量级的依赖注入。如果 EJB 3.0 是你的目标,这一方法也适用。还有一点经验就是,这种重构可以和正常编码同时发生,根本不需要为了方便合并而冻结代码。
脚注
依赖注入只是控制反转(作为模式现在已经有 10 年历史了)的一部分。控制反转的另外两个方面是配置和生命周期。其含义是,类应该从外界获得配置(更多的注入),生命周期状态变换同样也应该从外部进行控制。它们不应该在构造函数中配置自己、创建新线程或监听 Sockets,在静态初始化时做这些事情就更糟了。
关于作者
Paul Hammant 自 2000 年以来一直在推进控制反转的发展,最初是 Apache 的 Avalon 框架,然后在 2003 年首倡 PicoContainer 中的构造函数注入。他在 San Francisco 就职于 ThoughtWorks 公司。
查看英文原文: Drinking your Guice too quickly?
译注:Guice 发音为“juice”。




