


介绍
随机梯度下降(SGD)由于其极高的效率,成为目前大多数机器学习应用中最常见的训练方法。在考虑计算效率时,mini-batch SGD 同时计算多个随机梯度,似乎不符合计算效率的要求。但是 mini-batch SGD 可以在不同网络之间并行化,所以它是现代分布式深度学习应用的更好选择。有以下两个原因:(1)mini-batch SGD 可以利用在 GPU 上的局部计算并行性;(2)降低参数更新频率有助于减轻不同设备间的通信瓶颈,这对于大型模型的分布式设置是十分重要的。
目前有些方法为了减少训练时间,使用大批量的 SGD。但是这一选择是错误的,因为它没有正确考虑设备的局部并行化以及设备间的通信效率。尤其是当设备的数量增加时,每台设备的并行化程度会严重约束通信效率。
为了解决这个问题,我们提出在每个网络上使用局部 SGD 的一种新变体。局部 SGD 在几次迭代后(无通信)对网络的平均来更新参数。我们发现,调整通信间隔中的迭代次数可以成功地将局部并行性与通信延迟分离。
我们进一步将该想法推广到去中心化和异质的系统上。如下图所示的层次化网络结构推动了局部 SGD 的层次化扩展。

图 1 数据中心某集群的层次化网络结构示意图。
除此之外,端用户的设备,例如移动手机,组成了巨大的异质网络。在这里,机器学习模型的分布式计算和数据局部训练具有极大的优势。
论文贡献
我们提出了一个新的局部 SGD 的层次化扩展训练框架,进一步提高了局部 SGD 对实际应用中异质分布系统的适应性。对于实际情况下多服务器或数据中心的训练,层次结构的局部 SGD 比局部 SGD 和 mini-batch SGD 均提供了更好的表现性能,尤其是在达到同样准确率的情况下,层次结构的 SGD 提高了通信效率。
我们在多个计算机视觉模型上进行了局部 SGD 训练方法的实证研究,实验显示了该方法相比于 mini-batch SGD 有明显优势。结果显示局部 SGD 在保证预测准确率的前提下大大降低了通信需求。在 ImageNet 上,局部 SGD 的表现超出了现有的大批量训练方法约 1.5 倍。
分布式训练
我们主要考虑标准的求和结构的优化问题:

其中 w 是模型(神经网络)的参数,fi 是第 i 个训练样本的损失函数。
Mini-batch SGD 表达式为:
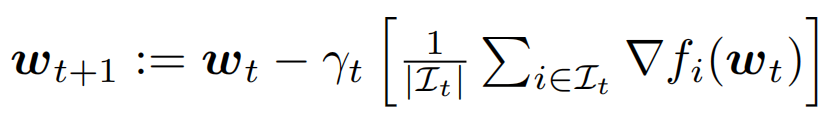

在分布式设置中,数据样本被划分到 K 个设备上,每个设备只能访问局部的训练数据。在这种情况下的 mini-batch SGD 算法表达式为:

这里第 k 个设备的 mini-batch 来自本地数据,这 K 个设备并行计算梯度,然后通过平均来同步局部梯度。
局部 SGD
与 mini-batch SGD 相比,局部 SGD 先在每个设备上进行局部的序列更新,然后累积 K 个设备之间的参数更新,如下图所示。

图 2 一轮局部 SGD(左)与一次 mini-batch SGD(右)对比。每个设置中批尺寸 B_loc 均为 2,对于局部 SGD,进行 H=3 次局部迭代。局部参数更新由红色箭头表示,而全局平均(同步)由紫色箭头表示。
每个网络 k 反复地从局部数据中提取固定数量的样本,批尺寸为 B_loc,然后进行 H 次局部参数更新,在此之后再与其他设备进行全局参数累积。因此,每一次同步(通信),局部 SGD 在每一台设备上已经访问了 B_glob=H x B_loc 个训练样本(亦为梯度计算次数)。
一轮局部 SGD 可以描述为:
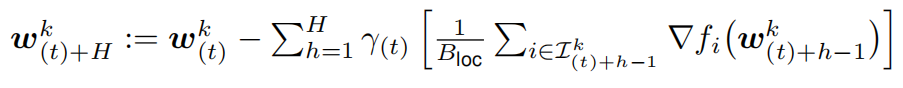

其中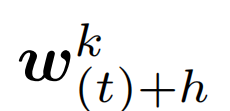 表示设备 k 上的局部模型在 t 次全局同步以及 h 次局部更新之后的参数。在 H 次局部更新后,同步的全局模型
表示设备 k 上的局部模型在 t 次全局同步以及 h 次局部更新之后的参数。在 H 次局部更新后,同步的全局模型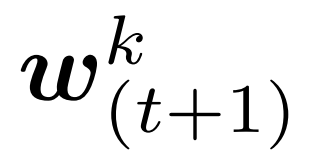 通过平均 K 个模型得到:
通过平均 K 个模型得到:

层次化局部 SGD
实际的系统都会有不同的通信带宽,因此我们提出将局部 SGD 部署在不同层级上,使之适应相应层级的计算能力与通信效率的平衡。层次化局部 SGD 在系统适应性和表现性能上均具有显著优势。
下图是层次化局部 SGD 的示意图:
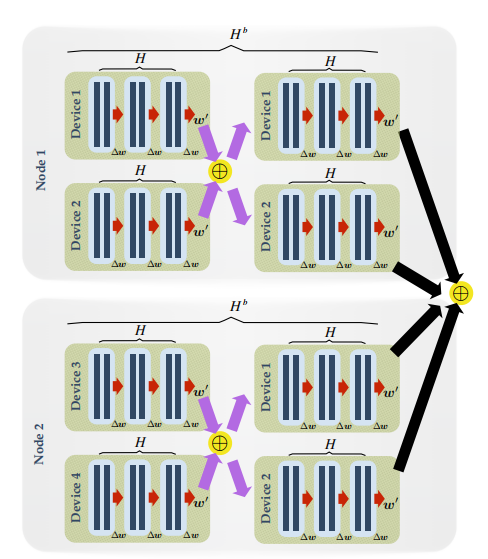

图 3 层次化局部 SGD 示意图。设批尺寸 B_loc=2,局部迭代次数为 H=3,区块迭代次数 H_b=2。局部参数更新用红色箭头表示,而区块和全局同步分别用紫色和黑色箭头表示。
我们以 GPU 计算集群为例,将大量 GPU 成组分布于几个机器上,将每组称为一个 GPU 区块。层次化的局部 SGD 连续更新每块 GPU 上的局部模型,在 H 次局部更新之后,会在 GPU 区块内部进行一次快速同步。在外层,在 H_b 次区块更新后,会对所有的 GPU 区块进行全局的同步。完整的过程可以表达如下:
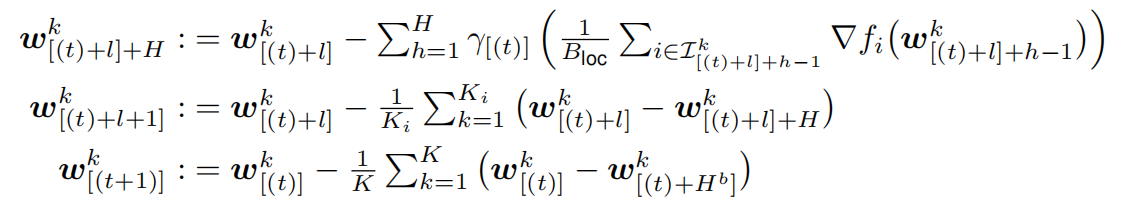

实验结果
在这一部分,我们通过实验分析对比 mini-batch SGD 和我们提出的层次化局部 SGD 的性能。
数据集
- CIFAR-10/100。训练集包含 50K 张彩色图像,测试集包含 10K 张彩色图像,大小均为 32 x 32,分别具有 10 个和 100 个类别标签。我们采用标准数据增强方法和预处理方法处理数据集。
- ImageNet。ILSVRC2012 图像分类数据集包含 128 百万张训练图像,50K 张验证图像,具有 1000 个类别标签。网络输入图像大小为 224 x 224。
模型选择
我们用 ResNet-20 来测试(层次化)局部 SGD 在 CIFAR-10/100 上的表现,然后用 ResNet-50 来测试(层次化)局部 SGD 在 ImageNet 上的准确率和可扩展性。我们也用 DenseNet 和 WideResNet 进行了实验,验证局部 SGD 对不同模型的泛化能力。
CIFAR-10/100 实验
- 局部 SGD 训练
对于 CIFAR-10,我们在 2 个服务器上进行局部 SGD 训练,每个服务器有 1 块 GPU。
保证准确率的同时提高通信效率
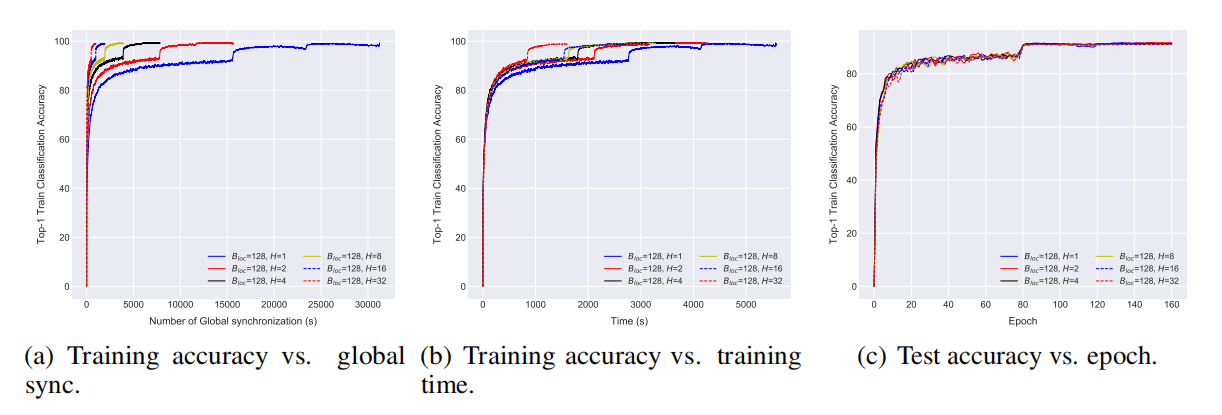

图 4 通过局部 SGD 在 CIFAR-10 数据集上训练 ResNet-20。批尺寸 B_loc=128,局部更新次数从 1 到 32。
从图 4 中可以看出,局部 SGD 在保证了准确率的同时,极大提高了通信效率,并且具有更快的收敛速度。在实验中,mini-batch SGD 是局部 SGD 的一种特殊形式,(局部迭代次数)H=1。从图 4(a) 可以看出,对于同样数量的样本,局部 SGD 缓解了通信瓶颈的问题。图 4(b) 给出了局部 SGD 对于整体训练时间的影响:局部迭代次数 H 越大,影响越大,H=32 时局部 SGD 至少比 mini-batch SGD 快 3 倍。从图 4(c) 中可以看出,对于不同的 H 值,最终的准确率会趋于稳定,并且与测试准确率并无大的差异。
比“大批量训练”更好的泛化能力

表 1 通过局部 SGD 在 CIFAR-10 数据集上训练 ResNet-20。给出了固定访问数据量 B_glob 时,mini-batch SGD 和局部 SGD 的 top-1 测试准确率。
从表 1 中可以看出当访问同样的样本数时,局部 SGD 比 mini-batch SGD 具有更好的泛化能力。大批量训练方法提出了很多技巧来克服收敛问题,包括改变学习率和逐渐开始。Mini-batch SGD 如果采用大批量训练方法仍然会有很多问题,而局部 SGD 通过局部迭代次数很自然的解决了这个问题。
- 层次化的局部 SGD 训练
下面我们在分布式异质系统上测试我们提出的训练方法。我们模仿真实情况的设定,即计算设备(GPU)在不同的服务器上的集群,网络带宽限制了大型模型更新所需的通信效率。

表 2 随机 SGD 在 CIFAR-10 数据集上训练 ResNet-20 模型(5 x 2GPU 集群)。在局部批尺寸 B_loc 和区块迭代次数 H_b 固定的情况下,我们给出了 H 从 1 到 1024,训练时间的变化情况。
训练时间 vs 局部迭代步数
表 2 给出了局部 SGD 与训练时间的关系。通信需求主要来自于 5 个节点的全局同步,每个节点有 2 个 GPU。我们发现过大的局部更新迭代次数甚至会降低局部更新带来的通信优势。这一性能降级或许是由于独立的局部过程增加了同步时间。
层次化局部 SGD 对网络延迟的高容忍度

图 5 层次化局部 SGD 在 CIFAR-10 数据集上训练 ResNet-20 模型(2 x 2GPU 集群)表现性能。局部迭代次数 H=2(a)训练准确率 vs 时间(b)每次全局同步有 1 秒延迟情况下的训练准确率 vs 时间(c)每次全局同步有 50 秒延迟情况下的训练准确率 vs 时间.
层次化的局部 SGD 对网络延迟具有鲁棒性。例如,对于固定的 H=2,通过减少在所有模型上进行全局同步的次数,我们可以减少一定的训练时间,如图 5(a) 所示。图 5(b) 进一步展示了网络对于较慢的通信的影响,其中每个全局通信都增加了 1 秒的延时。图 5(c) 显示增加区块内迭代次数能够克服通信瓶颈的问题,而不会对表现造成影响。
层次化局部 SGD 能够进行更大的扩展并且具有更好的表现


表 3 层次化局部 SGD 在 CIFAR-10 数据集上训练 ResNet-20 模型(10GPU Kubernetes 集群)表现性能。
表 3 对比了 mini-batch SGD 和层次化的局部 SGD。我们可以发现,具有足够区块迭代次数的层次化局部 SGD 可以有效缓解准确率降低的问题。并且,内节点同步次数更多的层次化局部 SGD 的表现也超过了局部 SGD。结合表 2 和表 3 可以发现,层次化的局部 SGD 的表现超过了局部 SGD 和 mini-batch SGD 的训练速度和模型表现。
ImageNet-1K 实验
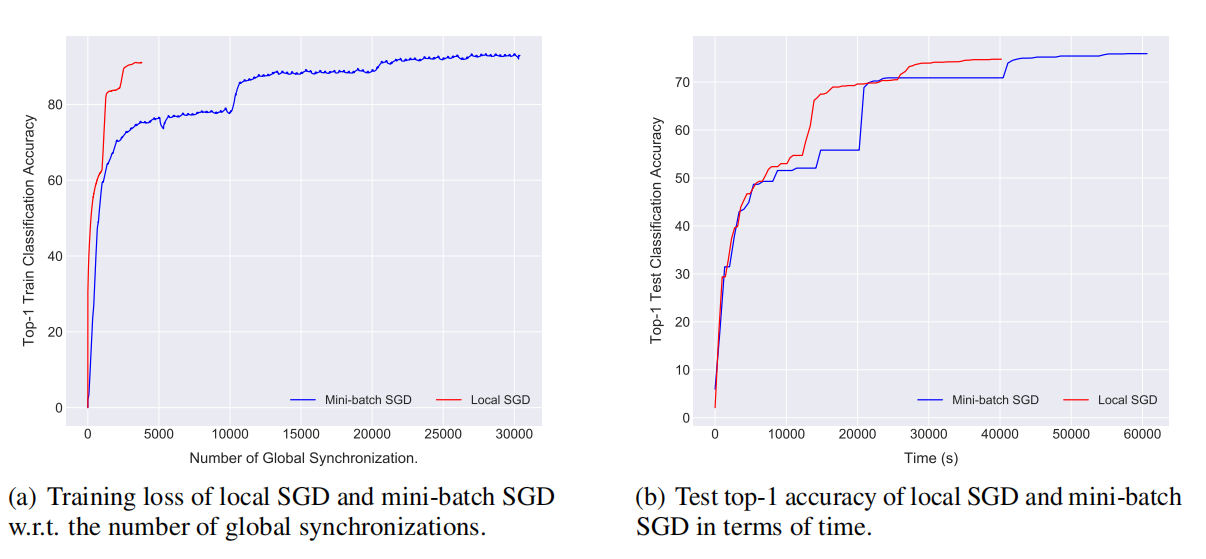

图 6 局部 SGD 在 ImageNet-1k 数据集上训练 ResNet-50 模型(15 x 2GPU 集群)表现性能。
图 6 显示我们可以通过局部 SGD 在 15 x 2GPU 集群上有效训练(快 1.5 倍)ResNet-50。在达到同样准确率时,局部 SGD 只需要很少的时间和同步次数,节省了计算量,并且提高了通信效率。
结论
在这篇文章中,我们利用局部 SGD 的思想,将其扩展至去中心化和异质的系统环境。我们提出了层次化的局部 SGD,能够有效适应于实际情况中的异质系统。此外,我们实证研究了局部 SGD 在不同的计算机视觉模型上的表现,实验显示算法在整体性能和通信效率方面均有显著提高。
查看论文原文: Don't Use Large Mini-Batches, Use Local SGD
感谢蔡芳芳对本文的审校。

暂无签名

中国开发者画像洞察研究报告 2024
分析开发者的行为模式、工作价值、职业发展等内容,帮助整个行业生态更深入地理解开发者,为他们提供更精准...













评论