
海豚浏览器于 2010 年 2 月正式发布 Android 版本,在正式发布的近一年之后从一个纯客户端的产品开始迭代式地进化,逐渐加入各种云端服务的功能,海豚浏览器的云端之路也因此而启程。在创业之初,因为资源、人手的各种紧缺,自然而然的云端服务的部署也就成为首选。当时在国外的创业型小公司中,亚马逊云平台(Amazon AWS)备受青睐,因此我们也毫不犹豫的选择了AWS 做为服务商,并且在海豚阅读(Dolphin Webzine)的第一次发布里做了大规模的尝试,随后又相继推出了海豚同步,海豚声纳等云服务。
起初接触云平台其实更多地仍然是把云平台当成普通的IDC 主机租用服务在用,体验到的优势是相对于物理主机而言,云主机(instance)上线/ 下线都比较方便。而且不像国内很多主机服务是预充值或者预付款的消费模式,AWS 平台的付款直接与信用卡挂钩,用多少就付多少,非常灵活。随着时间的推移,对云平台认识的浅显和不充分,导致我们吃了不少的苦头,当然也积累了不少经验教训。到现在,整个AWS 云平台(见图1)的大部分服务我们都有实际使用的经验。
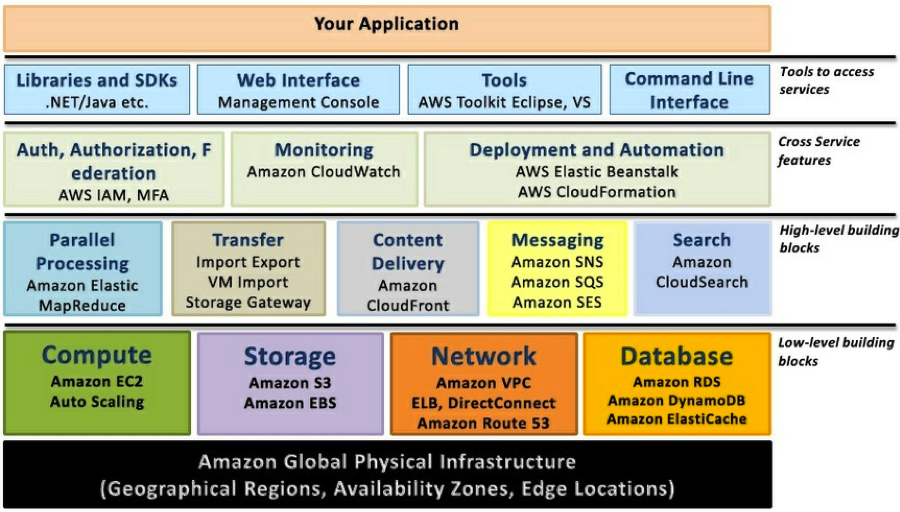
图1:AWS 服务栈
云平台上的扩展性
说到云平台的使用就不得不先说说水平扩展(scale out)。之前我们的做法是在服务正式对外发布之前,部署多套同角色的机器(比如前端机器和应用服务器),就为了保证能够应对突发的流量增长。这些备用机器的部署和使用在云平台上其实是没有多大必要的。在AWS 上完全可以通过 ELB 这样的一个弹性负载均衡器来自动实现服务的水平扩展,ELB 支持多种协议,并且可以自定义水平扩展的条件,对于服务的开发者来说,这省了不少开发的活,而且对于普通的负载均衡应用场景来说,它完全可以替代 Nginx 或者 HAProxy 。
对于垂直扩展(scale up)来说,有两点比较重要,一是对云主机升降级时类型的选择,二是了解云主机的生命周期。 EC2 上的云主机有固定的好几种类型,首选一般都是64 位机器,这样方便内存扩容,如果对于CPU 消耗比较高(比如HTTPS 连接),那么优先选High-CPU 型的,如果是对内存要求比较大(比如MongoDB),那么优先选High-Memory 型的。海豚的大多数机器选型集中在micro/small 用作监控和前端,small/medium 部署应用服务、消息队列,medium/large 做数据库和离线计算。xlarge 再往上用得很少,基本上都靠水平扩展解决了。对于云主机的生命周期来说,restart 和stop/start 是有区别的,升降级的时候必须要stop 云主机,升降级完毕再启动的时候,机器的内部IP 会发生变化(IP 通过DHCP 分配的),这一点经常会给依赖IP 的服务配置造成问题。解决的办法有两个,一个是通过 VPC 来自己控制 IP 地址分配,另外一个就是使用 Elastic IP 这样的静态地址。
云平台上的存储
和计算资源一样,存储资源是一个云平台的核心要素之一。云平台上的存储按照使用场景分为三大类型:
- 临时存储。AWS 的 instance storage 就是临时存储的一种,主要用来存放缓存和一些中间结果等内容。要注意的是临时存储的内容在云主机 stop 以后就会被清空,因为通过 df 命令往往看不出来这一点,所以之前有过把 instance storage 当成持久化存储的经历,损失就很惨重。
- 持久化存储。持久化存储最常指的就是物理硬盘,在 AWS 平台上, EBS 就是这样的一个可以以任意大小被挂载的“硬盘”,实际上它的实现是一个网络文件系统,因此它的访问速率受限于网络带宽,而且不是那么稳定。通常可以通过在 EBS 标准的 volume 上做 RAID 或者使用最新推出的 Provisioned IOPS volume 来解决 I/O 速率问题。另外尽管 EBS 是持久化存储,并不意味着它就不会发生数据的丢失,EBS 的年化不良率有 0.1%-0.5%,因此对于单存储节点来说需要定期的去做 EBS 的镜像和备份,以防止意外的发生。
- 大规模冗余存储。 S3 就是这种存储类型的样例。S3 不是一个文件系统的架构,I/O 速率和延迟也不及 EBS,但它的好处在于一方面可以在一个比较低的价格(和 EBS 差不多)提供 99.999999999% 的可靠性,另外一方面可以存取非常大规模,比如 PB 级别的数据,这些数据可以在不限于 AWS 的任何地方使用。海豚就用 S3 存储了几乎所有的镜像、数据备份和各种日志。除此之外,S3 和 CloudFront (AWS 的 CDN 解决方案)集成程度很高,因此海豚也通常使用 S3 作为 APK 等内容分发的渠道。
云平台上的服务高可用
虽然云平台有着一个好听的名字,但它绝对不是完美的。那些认为在云平台上部署了服务就能自动保证高可用、高扩展的念头都是不切实际的幻想。就拿 AWS 来说,它的问题就不少,其中最突出的当属数据中心本身的可靠性经常有突发的挑战。比如 AWS 的美东区(US-East Region)就是一个事故高发区,在 2012 年 4 月和 6 月已经各发生了一次大规模的服务中断,导致很多依赖于 AWS 的知名服务在一段时间内不可用,比如 Instagram 、 Pinterest 等。事故一方面有外在原因(比如电力供应不足),另外一方面和 AWS 本身的发展历史也有关系。因为美东区建立得比较早,基础设施相对陈旧,再加上有很长一段时间相对于其它区的云主机要便宜一些,因此很容易因为各种瓶颈制约产生问题。所以海豚现在新上线的云服务都尽量放在 AWS 的其它 region(比如美西区,用 CloudPing 可以测试你访问 AWS 各个区的延迟),而且从数据部署结构上尽量采用跨 zone 和跨 region 的方案,如图 2 所示,三个 DB 服务器部署在两个不同的 region,另外两个服务器在同一个 region 但在不同的 zone,然后三台服务器之间做一个同步复制。
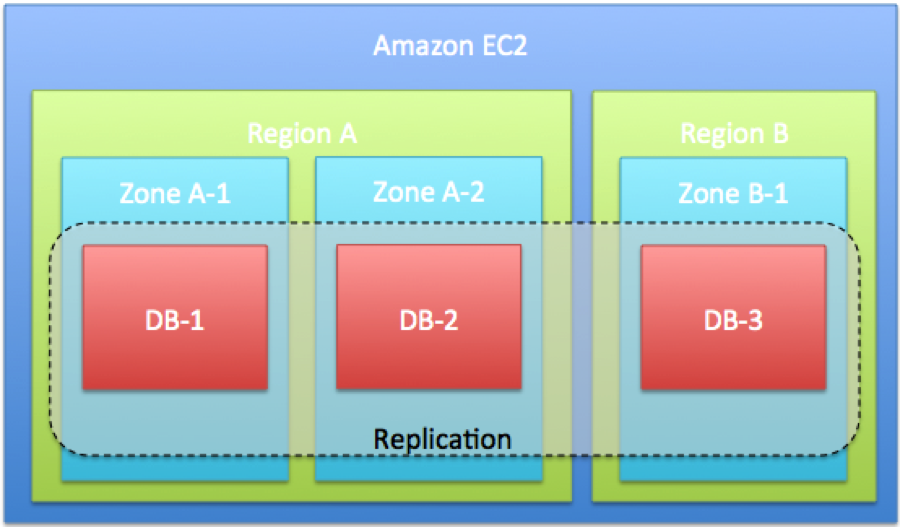
图 2:高可用的部署方案
云平台的开放性
对于一个好的云平台来说,它的开放性首先体现在其对外提供的 API 上。AWS 平台支持 Java/PHP/Python/Ruby/.NET 等 SDK,通过这些 SDK 就能够直接完成 web 界面上做的事情。海豚各种服务的上线和部署都通过 Fabric 结合这些 API 来完成,包括 AWS EC2 API 和 AWS 的 Python 接口 boto 。整个上线和部署的过程不需要人工干预,因此既提高了速度、降低了维护成本,又减少了人工出差错的可能。
其次,大多数云平台都会对安全考虑的比较多。举一个例子,EC2 上的云主机是通过安全组(Security Group)来控制端口的访问策略,这样安全组就做了最外层的一个“访问防火墙”,完全可以取代 iptables 或者 ufw 配置的一些策略。另外 IAM 对云平台用户和资源访问权限的管理做了很细粒度的控制,这么精细的控制使得公司内部运维和开发的角色不再那么明显,很好地促进了运维和开发人员之间的协作和交流。迄今为止,海豚正式的全职运维人员还不到 3 人,他们和开发人员一起管理和使用着几百台机器。
除了这些以外,AWS 还提供了免费的基础监控功能 CloudWatch ,不过这个基础的监控还远远满足不了我们的需求,再加上国内国外两套不一样的基础设施(国内租用的机房),我们还是选择了监控宝加上自己的监控,双重覆盖来达到比较好的监控效果。
在云平台上节省开支
对于初创企业来说,开源节流是一个好的习惯。利用云平台本身其实就已经节省和分摊了固定基础设施投入的开销。在云平台之上,依据每个云平台的特点,其实还有不少可以优化的地方。
- EC2 上使用 reserved instance 预定一定比例的特定类型机器或者使用 spot instance 来做一些临时的事情都比启动 on demand instance 要划算,一般来说可以节省 1/3 甚至更多的开销。海豚就利用了 EMR (间接启动 spot instance)来做大数据的分析和计算。
- 用 LVM 来提高 EBS 的使用率。EBS 的计费是按照分配的大小而不是实际使用的大小来计算的,比如创建了一个 50G 大小的 EBS,但实际只使用了 5G,那么费用仍然按照 50G 来算。我们通过 LVM 可以将底层的 EBS 挂载透明化,这样 EBS 可以按需来小块挂载,不需要提前分配一个比较大的空间,使用率也因此得到较大的提升。
- 在 terminate 云主机时记得及时清理并删除与之相关联的 EBS store、Elastic IP 或者镜像,所有这些都是不会自动删除并且会造成隐性开销的地方。
- 动态调整机器在不同时段的使用数目。EC2 的云主机是按照在线小时计费的,用户使用服务通常都具有一定的模式,比如早上、中午和晚上分别有一次访问的高峰,那么其它时段机器的数量就可以做相应的缩减。通过使用 ELB 可以实现一部分,也可以通过 AWS 的 API 加上 cron jobs 或者 Quartz 来自己实现动态调整机器数量的功能。
- 网络带宽是一个不小的开销,这一点最容易被忽视,因为在传统的 IDC 机房和国内不少的云主机服务都是租用的固定带宽。而在 AWS 上,带宽的使用是没有限制的,计费按照实际的传输量,所以其开销很容易就超过你的想象。对于那些访问量比较大的网站或者服务来说,压缩、客户端缓存等都是必不可少的减少带宽消耗的手段。另外注意跨 region 的数据传输也是要收费的,这还包括一台机器通过外网 IP 访问在同一内网的另外一台机器。
- 对每日的费用做监控和分析。投入产出的优化是一个持续的过程,所以很有必要对费用情况做日常的统计和分析,有必要时还可以设定开销的报警来及时处理一些异常的行为。
寄语
海豚的云端之路一直在探索,还会继续的走下去。随着云平台技术的进一步发展,相信未来会有更多形式,更多创新的点子直接影响到更多创业型公司的成长,也希望这篇文章能够引导大家步向云端的步伐。
感谢张龙对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ )或者腾讯微博( @InfoQ )关注我们,并与我们的编辑和其他读者朋友交流。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论