
一、背景
雪球 ( http://xueqiu.com ) 是一家涉足证券行业的互联网金融公司,成立于 2010 年,去年获得 C 轮融资。雪球的产品形态包括社区、行情、组合、交易等,覆盖沪深港美市场的各个品种。
与传统社交网络的单一好友关系不同,雪球在用户、股票基金及衍生品、组合三个维度上都进行深度的相互连接。同时雪球的用户活跃度和在线时长极高,以致我们在进行技术方案选型和评估的时候必须提出更高的要求。
目前雪球的 DAU 为 1M,带宽为 1.5G,物理机数量为 200+,云虚拟机数量约 50 个。雪球采用了 Docker 容器作为线上服务的一个基本运行单元,雪球的容器数量近 1k。本文从创业公司的视角介绍雪球是如何引入 Docker 容器,并且逐步填坑和推广上线,然后实现跨机房部署的能力,并基于 Docker 实现发布流程及周边生态的自动化。
二、雪球对容器的选型
我们的服务面临的操作系统环境大致有五种:物理机、自建虚拟机、云虚拟机、LXC 容器、Docker 容器。

我们主要的考虑的选型指标包括“成本”、“性能”、“稳定性”三个硬性基础指标,以及“资源隔离能力”、“标准化能力”、“伸缩能力”这几个附加指标。这五类操作系统环境在雪球的实践如下:
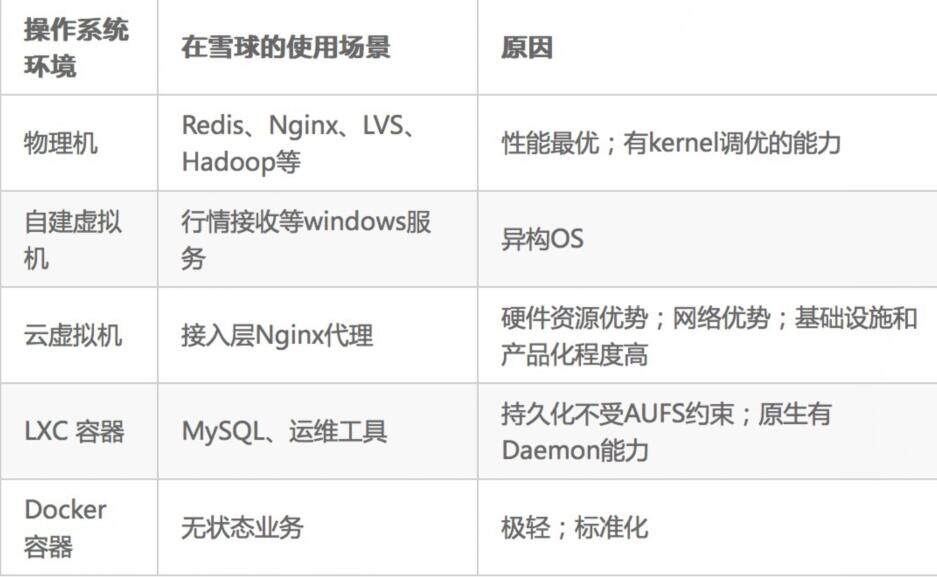
雪球的 SRE 团队借助 Docker 对整个公司的服务进行了统一的标准化工作,在上半年已经把开发测试、预发布、灰度、生产环境的所有无状态服务都迁移到了 Docker 容器中。
重要通知:接下来 InfoQ 将会选择性地将部分优秀内容首发在微信公众号中,欢迎关注 InfoQ 微信公众号第一时间阅读精品内容。

三、上 Docker、迁业务、填坑
雪球借助 Docker 对服务进行的标准化和迁移工作,主要是顺着 Docker 的 Build -> Ship -> Run 这三个流程进行的。同时在迁移过程中填了许多坑,算是摸着石头过河的阶段。
1) 构建
我们首先设计了自己的 Docker Image 层级体系。
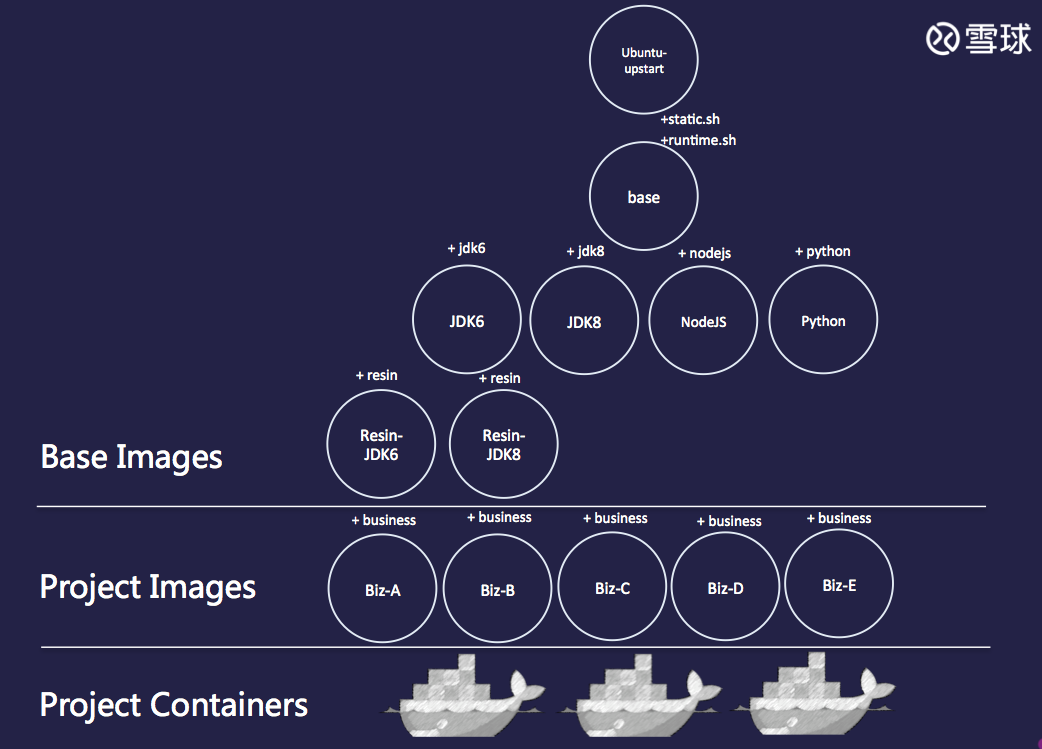
在 Base 这一层,我们从 ubuntu-upstart 镜像开始制作 base 镜像。这里做了动静分离,静态的部分(static.sh 和对应的 static 文件)和动态的部分 ( runtime.sh ) 都会被添加进 base 镜像,静态部分会在构建 base 镜像过程中被执行,而动态部分会在启动 project 镜像的过程中被执行。其中静态部分我们更推荐灵活的使用 shell 脚本来完成多个基础配置,而不是写冗长的 Dockerfile。下图是一个很好的例子

基于 base 镜像,我们又添加进入了 JDK、NodeJS 等运行环境,并在 JDK 的基础上进一步构建了 Resin 镜像。在上述镜像中再添加一层业务执行代码,则构成了业务镜像。不同的业务镜像是每个业务运行的最小单元。
在雪球我们大力的推进了服务化,去状态。这样的一个业务镜像就具备了迁移部署、动态伸缩的能力。
需要提醒的是 docker build 镜像的过程中会遇到临时容器的一些问题,主要涉及访问外网和 dameon 能力。
2) 分发
分发的过程痛点不多,主要是 Registry 的一些与删除相关的 Bug、Push 镜像的性能,以及高可用问题,而本质上高可用是存储的高可用。在雪球我们使用了硬件存储,接下来计划借助 Ceph 等分布式文件系统去解决。
3) 运行
Docker 运行的部分可以探讨的内容较多,这里分为网络模型、使用方式、运维生态圈三部分来介绍。
a. 网络模型
绝大多数对 Docker 的网络使用模型可以汇总为三类:
- Bridge 模式(NAT)
- Bridge 模式(去 NAT)
- 端口映射
Docker 默认的桥接是用的第一种 NAT 方式,也即是把命名空间中的 veth 网卡绑定到自己的网桥 docker0。然后主机使用 iptables 来配置 NAT,并使用 DHCP 服务器 dnsmasq 来分配 IP 地址。在雪球我们对 Bridge 模式去掉了 NAT,也即把宿主机的 IP 从物理网卡上移除,直接配置到网桥上去,并且使用静态的 IP 分配策略。这样的好处是 Docker 的 IP 可以直接暴露到交换机上。而端口映射方案不容易做服务发现,雪球并没有使用。
其中去 NAT 的 Bridge 模式需要在宿主机上禁用 iptables 和 ip_forward,以及禁用相关的内核模块,以避免网络流量毛刺风暴问题。
b. 使用方式
我们在 docker run 的时候通过 –mac-address 传入了静态 MAC 地址,并通过前述 runtime.sh 在运行时修改了 docker 的 eth0 IP。其中计算 MAC 地址的算法是:
IP="aa.bb.cc.dd" MAC_TXT=`echo "$IP" | awk -F'.' '{print "0x02 0x42 "$1" "$2" "$3" "$4}'` MAC=`printf "%.2x:%.2x:%.2x:%.2x:%.2x:%.2x" $MAC_TXT`
同时我们按照雪球统一的运维规范在运行时修改了容器 Hostname、Hosts、DNS 配置。
在交互上,我们在容器中提供了 sshd,以方便业务同学直接 ssh 方式进入容器进行交互。Docker 原生不提供 /sbin/init 来启动 sshd 这类后台进程的,一个变通的办法是使用带 upstart 的根操作系统镜像,并将 /sbin/init 以 entrypoint 参数启动,作为 PID=1 的进程,并且严禁各种其他 CMD 参数。这样其他进程就可以成为 /sbin/init 的子进程并作为后台服务跑起来。
c. 运维生态圈
首先我们对容器做了资源限制。一个容器默认分配的是 4 core 8 G 标准。CPU 上,我们对 share 这种相对配额方式和 cpuset 这种静态绑定方式都不满意,而使用了 period + quota 两个参数做动态绝对配额。在内存中我们禁用了 swap,原因是当一个服务 OOM 的时候,我们希望服务会 Fast Fail 并被监控系统捕捉到,而不是使用 swap 硬撑。死了比慢要好,这也是我们大力推进服务化和去状态的原因。
在日志方面,我们以 rw 方式映射了物理机上的一个与 Docker IP 对应的目录到容器的 /persist 目录,并把 /persist/logs 目录软连接为业务的相对 logs 目录。这样对业务同学而言,直接输出日志到相对路径即可,并不需要考虑持久化的事宜。这样做也有助于去掉 docker 的状态,让数据和服务分离。日志收集我们使用 logback appender 方式直接输出。对于少数需要 tail -F 收集的,则在物理机上实现。
在监控方面,分成两部分,对于 CPU、Mem、Network、BlkIO 以及进程存活和 TCP 连接,我们把宿主机的 cgroup 目录以及一个统一管理的监控脚本映射到容器内部,这个脚本定期采集所需数据,主动上报到监控服务器端;对于业务自身的 QPS、Latency 等数据,我们在业务中内嵌相关的 metrics 库来推送。不在宿主机上使用 docker exec API 采集的原因是性能太差。
四、混合云
通过采购硬件实现弹性扩容的,都是耍流氓。雪球活跃度与证券市场的热度大体成正相关关系,当行情好的时候,业务部门对硬件资源的需求增长是极其陡峭的。无法容忍硬件采购的长周期后,我们开始探索私有云 + 公有云混合部署的架构。
可以对本地机房和远端云机房的流量请求模型归类如下:
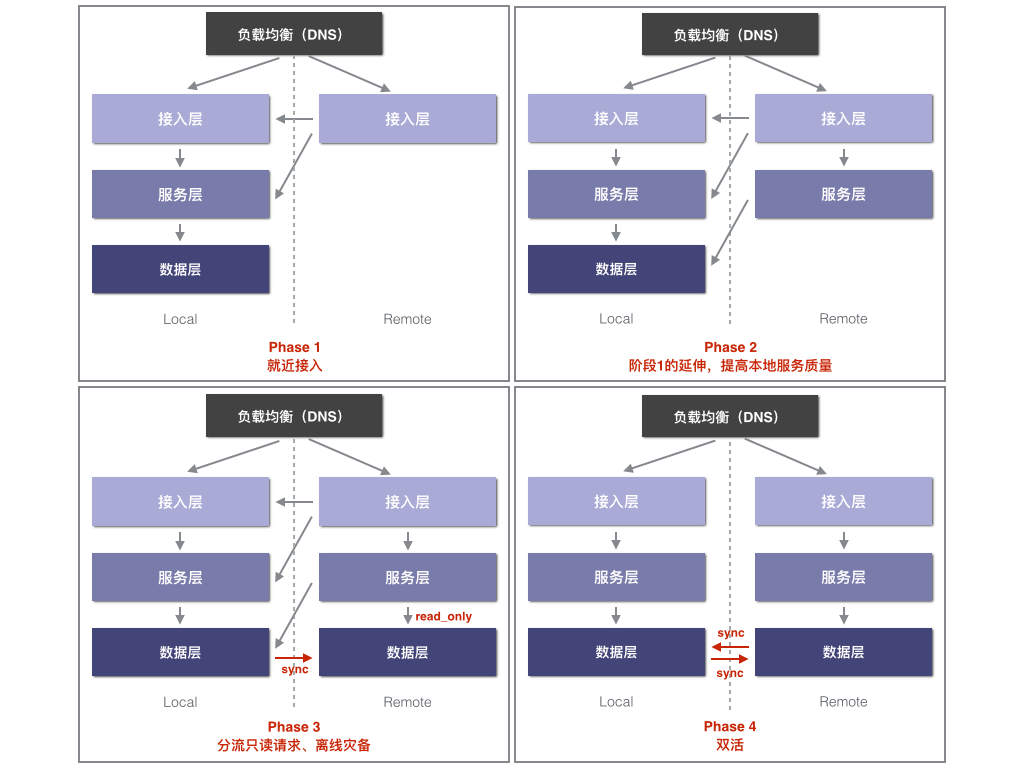
我们把服务栈分为接入层、服务层、数据层三层。其中第一个阶段只针对接入层做代理回源,目的可以是借助公有云全球部署的能力实现全球就近接入。第二个阶段,我们开始给远端的接入层铺设当地的服务层。演进到第三个阶段,远端的服务层开始希望直接请求本地数据。这里比较有趣的一点是,如果远端服务是只读逻辑,那么我们只需要把数据做单向同步即可。如果要考虑双向同步,也即演进到第四个阶段,也即我们所说的双活。其中不同机房之间的流量切换可以使用 DNS 做负载均衡,在雪球我们开发了一套 HTTP DNS 较完美的解决此问题。
目前雪球的混合云架构演进到第三个阶段,也即在公有云上部署了一定量的只读服务,获得一定程度的弹性能力。
在公有云上部署 Docker 最大的难题是不同虚拟机上的 Docker 之间的网络互通问题。我们与合作厂商进行了一些探索,采用了如下的 Bridge (NAT) 方案。
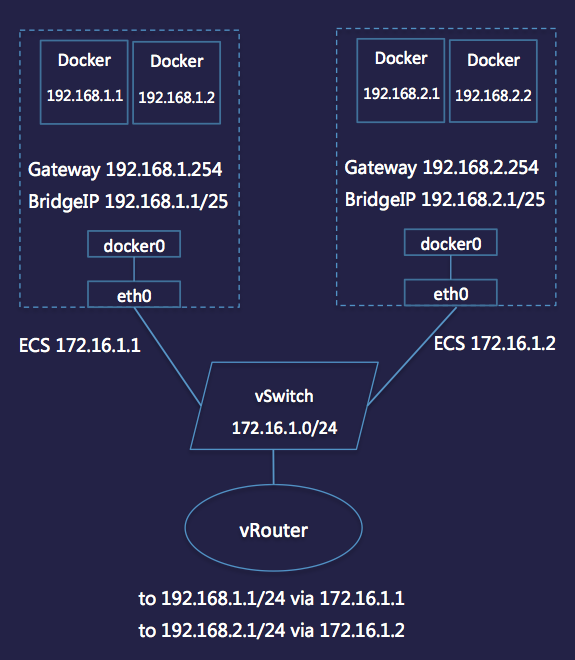
其基本思路与 Flannel 一致。首先虚拟机要部署在同一个 VPC 子网中,然后在虚拟机上开启 iptables 和 ip_forward 转发,并给每个虚拟机创建独立的网桥。网桥的网段是独立的 C 段。最后在 VPC 的虚拟路由器上设置对应的目标路由。
这个方案的缺点是数据包经过内核转发有一定的性能损失,同时在网络配置和网段管理上都有不小的成本。庆幸的是越来越多的云服务商都在将 Docker 的网络模型进行产品化。
五、发布系统 Rolling
当使用 Docker 对服务进行标准化后,我们认为有必要充分发挥 Docker 装箱模型的优势来实现对业务的快速发布能力,同时希望有一个平台能够屏蔽掉本地机房与远端公有云机房的部署差异,进而获得跨混合云调度的能力。于是我们开发了一套发布系统平台,命名为 Rolling,意喻业务系统如滚雪球般不断向前。
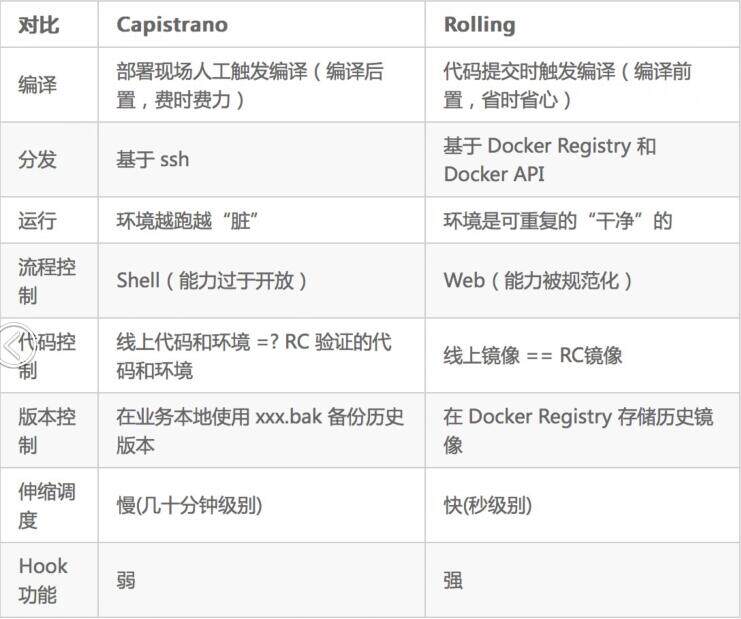
在此之前,雪球有一套使用开源软件 Capistrano 构建的基于 ssh 分发的部署工具,Rolling 平台与其对比如下:
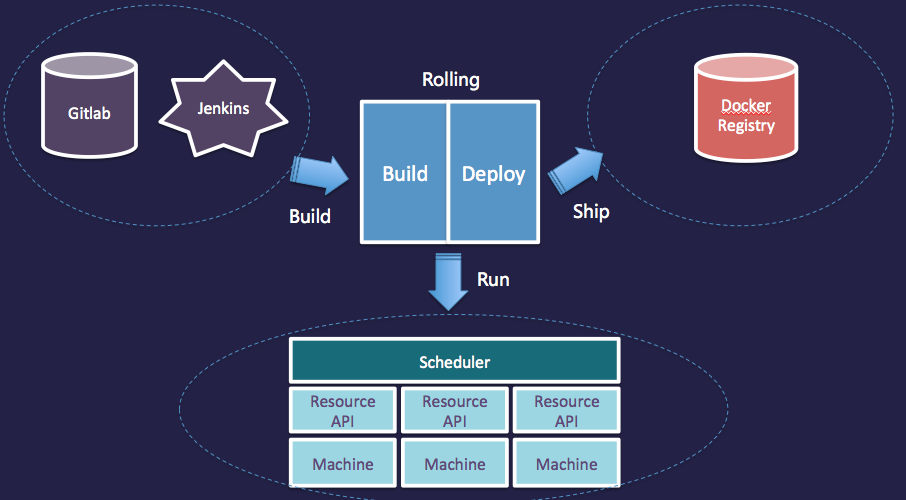
Rolling 的上下游系统如下图所示:
下面截取了几张 Rolling 平台在部署过程中的几个关键步骤截图:
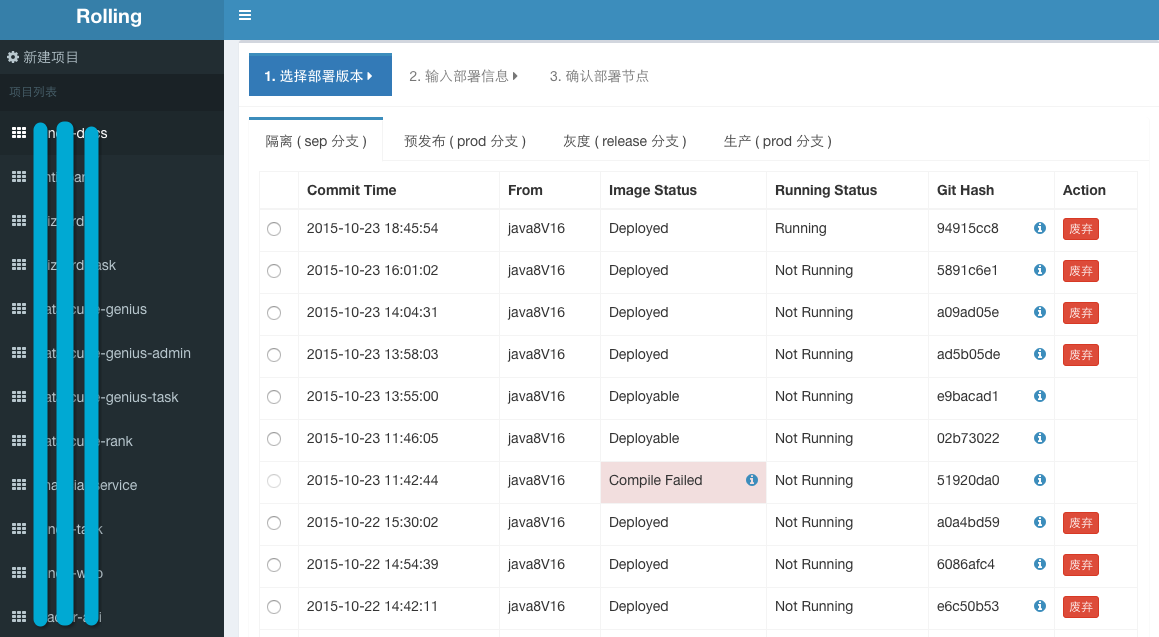
上图显示了 Rolling 在部署时的第一个步骤:镜像选择。根据设计,在开发同学将代码提交后到 Gitlab 后,Gitlab 中的 hook 就能直接触发 Rolling 进行代码编译和镜像构建。我们的设计思路是,每一次提交对应一次镜像构建。这样实际上镜像就代表代码,非常方便以最小粒度进行迭代升级以及回滚。
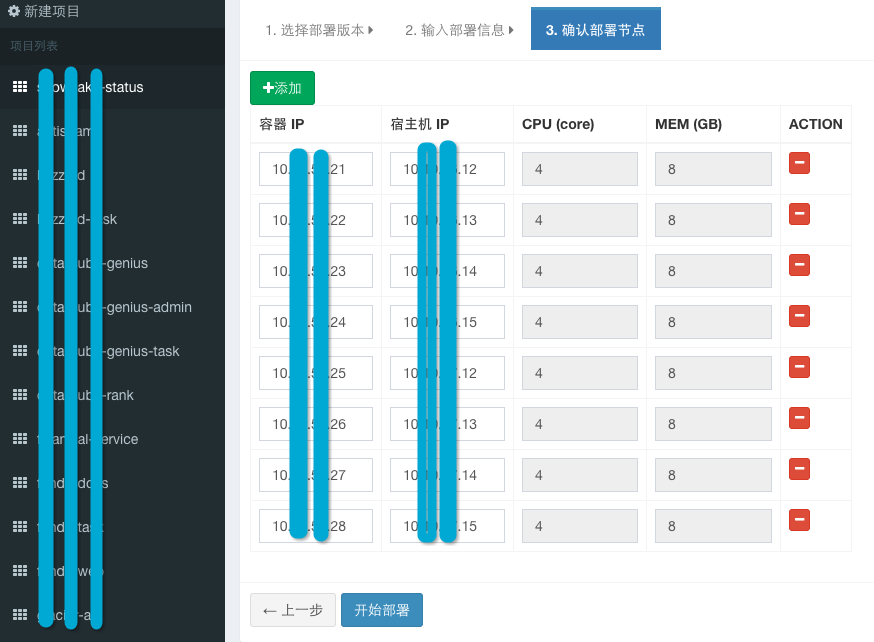
上图显示了 Rolling 在部署时的第三个步骤:资源选择。目前雪球仍然是靠人力进行调度配置,接下来会使用自动化的调度工具进行资源配置,而 Rolling 已经赋予我们这种可能性。在真正开始部署之后,还有一键暂停、强制回滚、灰度发布的功能。
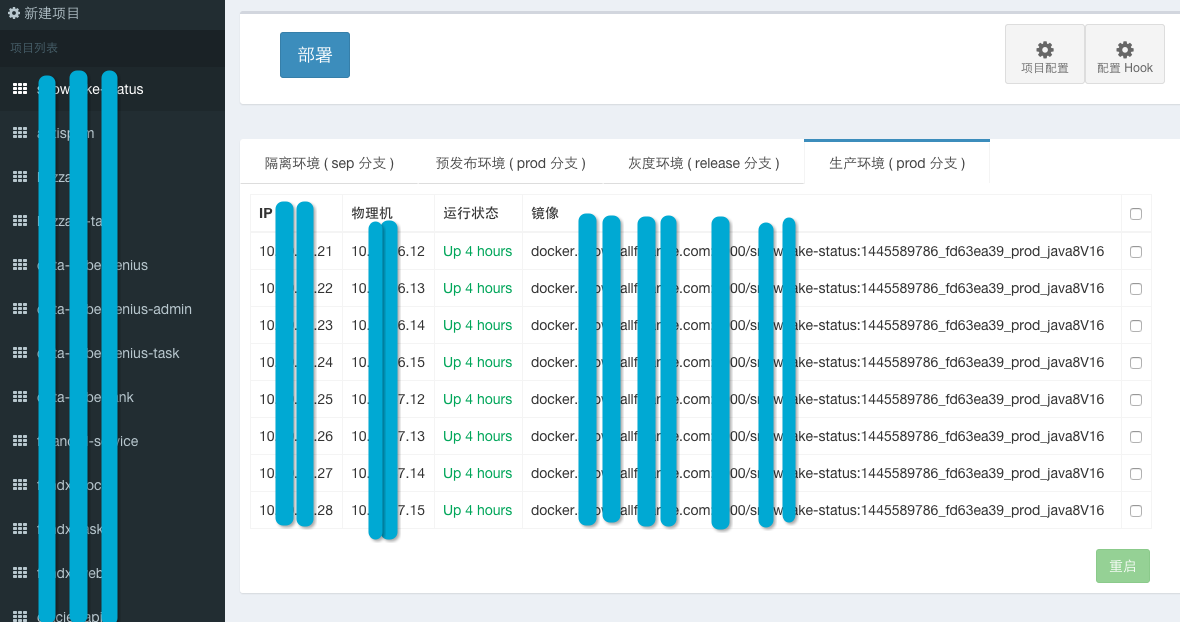
上图显示了某业务在使用 Rolling 部署后的运行状态。
Rolling 平台的带来的质变意义有两方面:
其一从运维同学的角度,Rolling 使得我们对服务的调度能力从静态跃迁为动态。而配合以大力推进的服务去状态化,Rolling 完全可以发展成为公司内部私有 PaaS 云平台的一款基石产品。
其二从业务同学的角度,其上线时不再是申请几台机器,而是申请多少计算和存储资源。理想情况下业务同学甚至可以评估出自己每个 QPS 耗费多少 CPU 和内存,然后 Rolling 平台能够借助调度层计算出匹配的 Docker 容器的数量,进而进行调度和部署。也即从物理机(或虚拟机)的概念回归到计算和存储资源本身。
六、接下来的工作
一方面,雪球会和合作厂商把公有云部署 Docker 的网络模型做到更好的产品化,更大程度的屏蔽底层异构差别。另一方面,我们考虑从资源层引入相对成熟的开源基础设施,进而为调度层提供自动化的决策依据。
感谢郭蕾对本文的策划和审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 (已满),InfoQ 读者交流群(#2))。
(已满),InfoQ 读者交流群(#2))。

Java 避坑指南:Java 高手笔记代码篇
本迷你书包括 86 个业务开发中常见踩坑点。每一个知识点都相当的实用,是程序员业务开发中的必备避坑指南...











评论