Neo,这就是让我们心烦的问题
为什么 AWS 有这么多的数据存储选项?我应该用哪个?这些是客户常见的问题。在这分成三部分的博客系列中,我将试图做一些澄清。在第一部分,我会论述高可用性的基础,以及为什么冗余是实现高可用性的常用方法。我也简要地提到在数据层加入冗余会带来新的问题。在本博客系列的第二部分,我会讨论这其中的一些问题,以及在克服这些问题时你需要考虑的取舍。本博客系列的第三部分在这些信息的基础上,论述AWS 特定的数据存储选项,以及每个存储选项的优化所针对的是哪些工作负载。在你读完本博客系列的全部三部分之后,你就会赞同AWS 提供了丰富的数据存储产品,并学会针对正确的工作负载选择正确的选择。
关系型数据库到底有什么问题?
正如你们中的很多人可能已经知道的,关系型数据库(RDB)技术自从1970 年代就已经存在,直到1990 年代末一直是结构化存储的事实标准。RDB 几十年来很出色地支持了高度一致性事务的工作负载,并依然保持强劲。随着时间的推移,该项古老的技术为应对客户的需求获得了新的能力,比如BLOB 存储、XML/ 文档存储、全文检索、在数据库中执行代码、使用星形数据结构的数据仓库、以及地理空间扩展。只要一切都能挤进关系型数据结构的定义中,并且适合于单机,就可以在关系型数据库中实现。

然后,互联网的商业化发生了,并且彻底改变了一切,使得关系型数据库不再能够满足所有的存储需求。相比于一致性,可用性、性能和扩展正在变得同样重要--有时甚至更重要。
性能一直很重要,但是随着互联网商业化的出现,改变的是规模。事实证明,要达到规模化的性能,要求的技巧和技术是前互联网时代无法接受的。关系型数据库围绕着ACID(原子性Atomicity、一致性Consistency、隔离性Isolation 和持久性Durability) 的概念而建立,实现ACID 最简单的方法就是把一切保持在单机上。因此,传统的RDB 规模化的方法是垂直扩展(scale up),用白话说,就是使用更大的机器。
哦-哦,我想我需要一台更大的机器
使用一台更大的机器的解决方案一直很好,直到互联网带来的负载大到单机无法处理。这迫使工程师们想出巧妙的技术来克服单机的限制。有许多不同的方法,各有其优缺点:主—副、集群、表联合与分区(table federation and partitioning)、水平分区(sharding,可以认为是分区的特例)。
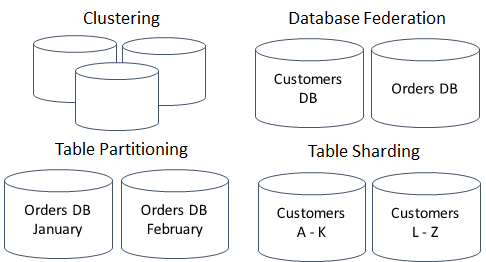
导致数据存储选项增加的另外一个因素是可用性。前互联网时代的系统,其用户通常是来自组织的内部,这就有可能在非工作时段设置有计划的停机时间,甚至计划外的宕机也只会造成有限的影响。商业化互联网也改变了这一点:现在每个能够访问互联网的人都是潜在用户,所以计划外的宕机会造成很可能更大的影响,而且互联网的全球性导致很难确定非工作时段,并安排有计划的停机。
在本博客系列的第一部分,我探讨了冗余在实现高可用性中所起的作用。不过,当应用到数据存储层时,冗余带来了一系列新的有趣的挑战。在数据库层应用冗余最常用的方式是主/副配置。
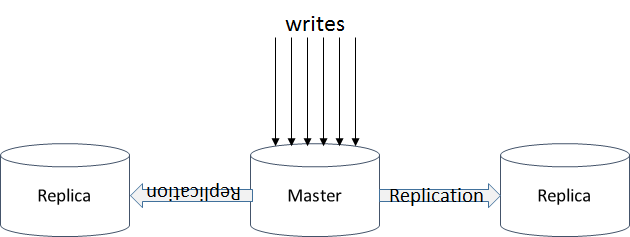
这个看似简单的设置,在与传统的单机关系型数据库比较时,有一个巨大的差异:我们现在有网络隔离的多台机器。当数据库的写操作发生时,我们现在要决定何时认为它完成了:只要保存到主数据库,或者只要保存到副数据库(或者甚至是n 个副数据库,如果我们想要获得更高的可用性--欲知增加另一台机器对整个可用性的影响,请参看本博客系列的第一部分)。如果我们决定保存到主数据库就足够了,在复制数据之前如果主数据库失效,我们要承担丢失数据的风险。如果我们决定等到数据复制完成,我们就要接受延迟的代价。在副数据库宕机的罕见情况下,我们需要决定是继续接受写操作的请求,还是拒绝它。
因此,我们从一个默认一致性的世界,进入了一个一致性是一种选择的世界。在这个世界里,我们可以选择接受所谓的最终一致性,即,状态在多个节点之间复制,但是并非每个节点都有整个状态的完整视图。在我们上面的示例配置中,如果我们选择认为达到主数据库就是写操作完成(或者到达主数据库和任一副数据库,但不一定是两个副数据库),那么我们就是选择了最终一致性。最终,因为每个写操作会被复制到每个副数据库。但是在任一时间点,如果我们查询某一个副数据库,我们无法保证它包含截止到那个时刻为止的所有写操作。
让我们试试新的CAP 理论
总而言之,当数据存储被复制(也称为分隔(partitioned))时,系统的状态被分散。这意味着我们离开了舒适的ACID 领域,进入CAP 的美丽新世界。CAP 理论是由加州伯克利分校的Eric Brewer 博士在2000 年提出的。它最简单的形式是这样的:一个分布式系统必须在一致性、可用性和分隔容忍度(Partition Tolerance)之间取舍,并且只能做到三者中的两者。
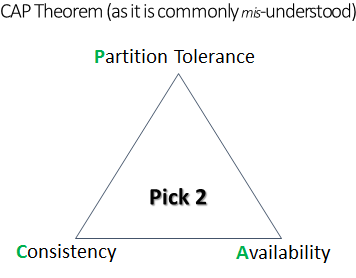
CAP 理论把关于数据存储的讨论扩展到超出 ACID 的范围,激发了许多非关系型数据库技术的诞生。在提出他的 CAP 理论的 10 年之后,Brewer 博士发表了一份声明,澄清他最初的“三选二”的观点被极大地简化,是为了引起讨论,并有助于超越 ACID。不过,这种极大的简化,引发了无数的曲解和误会。在对 CAP 更精细的解释中,所有三个维度应当理解为范围,而不是布尔值。此外,应当理解,分布式系统大部分时间工作在非分隔模式,在这种情况下,需要做出一致性和性能 / 延迟之间的折中。在分隔真的发生的罕见情况下,系统必须在一致性和可用性之间做出选择。
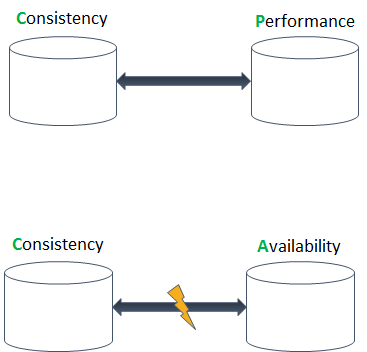
联系到我们之前的主/副例子,如果选择认为只有当数据在所有地方被复制(也称作同步复制)之后写操作才算完成,我们就是以写操作延迟为代价选择了一致性。另一方面,如果选择认为一旦数据保存到主数据库中,就认为写操作完成,并让复制在后台进行(也称作异步复制),我们就是以牺牲一致性为代价选择了性能。
当网络分隔发生时,分布式系统进入特殊的分隔模式,在一致性和可用性之间取舍。回到我们的例子:多个副数据库在失去与主数据库的连接之后,可能仍然继续提供查询服务,就是以牺牲一致性为代价选择了可用性。要么,我们可以选择,主数据库如果失去与副数据库的连接,就应当停止接受写操作的请求,因此就是以牺牲可用性为代价选择了一致性。在商业化互联网时代,选择一致性通常意味着收入的损失,所以很多系统选择可用性。在这种情况下,当系统恢复到正常状态时,它可以进入恢复模式,所有积累的不一致性得到解决和复制。
趁我们还在谈论恢复模式,值得说一说一种称为主—主(或主动—主动)的分布式数据存储配置。在这种设置中,写操作可以发送到多个节点,然后再互相复制。在这样的系统中,即使是正常的模式也变得复杂了。因为,如果对同一条数据的两个更新在大致相同的时间发生在两个不同的主节点上,要如何协调呢?不仅如此,如果这样的系统不得不从一个分隔的状态恢复,事情就变得更糟了。虽然有可能存在可行的主—主配置,而且也有一些产品使之更容易,我的建议是除非绝对必要,否则尽量避免。有很多方法可以实现性能和可用性的良好平衡,而不必需要负担主—主配置的高复杂度性的成本。
许多现代数据存储的常见模式
提供的性能 / 规模和可用性良好搭配的一种常见方法,是结合分隔和复制形成一种配置(或者说是模式)。这有时被称为分隔的副本集合(partitioned replica set)。
(点击放大图像)

不论是 Hadoop、Cassandra 或者 MongoDB 集群,所有这些基本上都符合这种模式,许多 AWS 数据服务也是如此。让我们了解一下分隔的副本集合的一些共同特征:
- 数据是跨多个节点(或者多个节点集群)分隔的(即,分开的)。没有单一分区拥有所有的数据。单个写操作只发送到一个分区。多个写操作有可能发送到多个分区,因此应当彼此独立。复杂的、事务性、多条记录(因此可能涉及多分区)的写操作应当避免,因为这样可能影响整个系统。
- 单个分区能够处理的最大数据量可能成为潜在的瓶颈。如果一个分区达到它的带宽上限,增加更多的分区以及拆分横跨其间的流量,有助于解决该问题。因此,可以通过增加更多的分区来扩展这种类型的系统。
- 一个分区的索引(key)用来分配各个分区的数据。你需要小心选择分区的索引,这样让读操作和写操作尽可能平均“分布”在所有的分区。如果读/写操作发生聚集,这些操作可能超出某个分区的带宽,进而影响整个系统的性能,而其它分区则并未充分利用。这被称为“热分区”问题。
- 数据在多台主机之间复制。这可以是,每个分区是完全分开的副本集合,或者在同一组主机之上的多个副本集合。一条数据被复制的次数通常被称为复制因子。
- 这样的配置拥有内置的高可用性:数据被复制到多个主机。理论上,若干小于复制因子数量的主机发生故障,不会影响整个系统的可用性。
所有这些好处,以及内置的可扩展性和高可用性,伴随着相应的代价:这不再是你的瑞士军刀,单机的关系型数据库管理系统(RDBMS)了。这是复杂的系统,有很多需要管理的可变动的部分和需要微调的参数。需要专业知识来设置、配置和维护这些系统。此外,需要监测和报警的基础设施来确保它们的正常运作。你当然可以自己做,但不容易,你可能短时间无法搞定。
为了帮助我们的客户无需管理开销,就获得高扩展性和高可用性的数据存储,AWS 提供各种托管的数据 / 存储服务。因为存在许多不同的优化目标,所以没有单一的魔法数据存储,而是一组服务,每个服务都针对某种特定的工作负载进行了优化。在下一篇博客文章中,我会讲述 AWS 提供的数据存储选项,讨论每种服务针对什么进行了(以及没有进行)优化。
丰富的数据存储,虽然引起一些选择困难,但其实是好事。我们只需超越传统的整个系统只有单个数据存储的想法,接受系统中使用多种数据存储、每个为它最适合的工作负载提供服务这样的思维方式。例如,我们可以使用下面的组合:
- 高性能摄入队列,来获取输入点击流量
- 基于 Hadoop 的点击流量处理系统
- 基于云的对象存储,用来低成本、长期地存储经过压缩的日常点击流量摘要
- 保存元数据的关系型数据库,可供我们用于充实点击流量的数据
- 用于分析的数据仓库集群
- 用于自然语言查询的搜索集群
上面所有这些都可以是某个单一子系统的组成部分,比如叫做网站分析平台。
总结
- 商业化互联网带来扩展和可用性的需求,而 RDBMS 这样的瑞士军刀再也无法满足这样的需求。
- 对数据存储增加水平扩展和冗余加大了系统复杂度,使得 ACID 更加难以保证,迫使我们按照 CAP 理论考虑取舍,创造了许多优化和专业化的有趣机会。
- 在系统中使用多个数据存储,每个为与其最适当的工作负载提供服务。
- 现代数据存储是复杂的系统,要求特殊的知识和管理开销。有了 AWS,你无需这样的开销,就能享受专用的数据存储的好处。
查看英文原文: Distributed Data Stores for Mere Mortals
感谢魏星对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们,并与我们的编辑和其他读者朋友交流(欢迎加入 InfoQ 读者交流群 )。
)。




