Pablo 首先回顾了深度学习领域在 2016 年主要的进展。
深度学习在机器学习领域中一直是核心话题,在过去几年和2016 年也是如此。在本文中将阐述我们认为移动领域中最有贡献(或最有潜力)的进展,以及组织和社区如何确保这些强大的技术对所有人都有利。
历史上研究人员所努力的主要挑战之一是无监督学习 。我们认为2016 年对于这一领域来说是一个伟大的一年,主要是因为在生成模型上进行了大量工作。
此外,自然地与机器交流的能力也是梦想目标之一,并且诸如Google 和Facebook 之类的巨人已经提出了几种方法。在这方面,2016 年所有关于自然语言处理(Natural Language Processing,NLP)问题的创新,是实现这一目标的关键。
无监督学习
无监督学习是指从原始数据中提取模式和结构,无需额外信息的任务,而不是需要标签的监督学习。
对于这个问题,使用神经网络的经典方法是自动编码器(autoencoders)。基本版本由多层感知器(Multilayer Perceptron,MLP)组成,其中输入和输出层具有相同的尺寸大小,并训练较小的隐藏层以恢复输入。一旦训练完毕,从隐藏层的输出对应于可用于聚类、维数降低、改进监督分类甚至用于数据压缩的数据表示。
生成式对抗网络(GAN)
近年来出现了基于生成模型的新方法。所谓生成式对抗网络,它能够解决模型无监督学习的问题。GAN 是一场真正的革命,这种研究带来了深远的影响。在这个演示视频中, Yann LeCun (深度学习的创始人之一)说,GAN 在过去 20 年里,是机器学习最重要的思想。
虽然生成式对抗网络早在 2014 年由 Ian Goodfellow 提出,但直到 2016 年,GAN 才开始显示出真正的潜力。改进的技术帮助培训和改善体系架构(深卷积GAN ),据介绍,今年已经修正了以前的一些局限性。新的应用程序(我们稍后列出其中的一些)展现了它们的强大和灵活性。
直观的想法
想象一下,一个有抱负的画家,想做艺术赝品(G),还有人想通过鉴定画作来谋生(D)。你首先给D 展示了一些毕加索的画作。然后G 制作赝品,试图欺骗D,使其相信是毕加索的原作。有时候会得逞。然而,当D 开始熟悉更多毕加索风格(学习更多的样本),G 就越来越更难欺骗D,所以他必须做得更好。随着这个过程的持续,不仅D 能够很好地分辨出哪个是毕加索的风格,哪个不是;而且G 也能得以提高仿毕加索绘画的能力。这就是背后GAN 的设想。
技术上来说,GAN 由两个网络之间的持续推动(因此“对抗”):一个生成器( generator,G)和一个辨别器(discriminatory,D)。给定一组训练示例(如图像),我们可以想像,有一个底层分布 (x)来管理它们。使用 GAN,G 将产生输出,并且 D 将判断它们是否来自训练集合的相同分布。
G 将从一些噪声 z 开始,因此生成的图像是 G(z)。D 从分布(实际)和伪造的(从 G)采用图像和它们进行分类:D(x) 和 D(G(Z))。
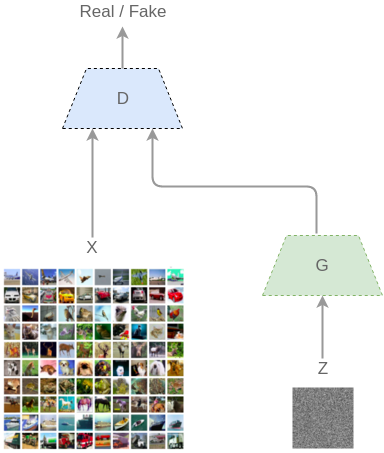
GAN 如何工作。
D 和 G 都在同时学习,并且一旦 G 被训练成它知道足够多的关于训练样本的分布,它可以产生新的样本,有着非常相似的属性:

由 GAN 生成的图像。
这些图像由 CIFAR-10 训练的 GAN 产生。如果你注意到细节,你可以看到它们确实不是真正的对象。但是,有些东西抓住了某些特征,使它们可以从远处来看很像真实的东西。
InfoGAN
最近的发展已经将 GAN 的想法不仅扩展到近似数据分布,还扩展到语义有解的学习、数据的有用向量表示。这些期望的向量表示需要捕获丰富的信息(与自动编码器中相同),并且也需要是可解释的,意味着我们可以区分部分向量,这些部分有助于在生成的输出中的特定类型的形状变换。
OpenAI 研究人员在 8 月提出的 InfoGAN 模型解决了这个问题。简而言之,InfoGAN 能够生成包含有关在无人监督的方式数据集信息表示。例如,当应用于 MNIST 数据集时,它能够推断数字的类型(1,2,3,…),所生成样本的旋转和宽度,而不需要手动标记数据。
有条件的 GAN
GAN 的另一扩展是称为条件 GAN(cGAN)的一类模型。这些模型能够考虑外部信息(类标签、文本、另一幅图像)来生成样本,使用它来强制 G 生成特定类型的输出。最近浮出水面的一些应用有:
-
文字到图像 采用文本描述(由字符级 CNN 或 LSTM 编码为向量)作为外部信息,并基于此生成图像。参见 Generative Adversarial Text to Image Synthesis (Jun 2016) 。

-
图像到图像 将输入图像映射到输出图像。参见 Image-to-Image Translation with Conditional Adversarial Nets (Nov 2016) 。
-
超分辨率技术
它采取降低采样的图像(细节较少),生成器尝试将它们复原接近更自然的未经删减压缩的原本。只要看过 CSI 的任何人都知道我们在说什么:)
参见 Photo-Realistic Single Image Super-Resolution Using a Generative Adversarial Network (Nov 2016) 。

你可以在这篇博客文章或Ian Goodfellow 的演讲中查看关于生成模型的更多信息。
自然语言处理
为了能够与机器进行流畅的对话,首先需要解决几个问题:文本理解、问答和机器翻译。
文本的理解
Salesforce MetaMind 已经构建了一个名为联合许可任务(Joint Many-Tasks,JMT)的新模型,目标是创建一个能够学习五个常见 NLP 任务的模型:
词性标记
将词性分配给每个词,例如名词、动词、形容词。
分块
也称为浅层句法分析。涉及一系列任务,比如寻找名词或动词组。
依存句法分析
识别单词之间的句法关系(例如修饰名词的形容词)。
语义相关性
测量两个句子之间的语义距离。结果是实值分数。
文本蕴涵
确定前提语句是否需要假设句子。可能的类:蕴涵、矛盾和中性。
这种模式背后的魔力是,终端到终端的可训练性(end-to-end trainable)。这意味着它允许不同层之间的协作,从而改进低层任务(不太复杂的任务),以及来自更高层(更复杂的任务)的结果。与旧的想法相比,这是一个新的想法,它只能使用低级别来改进高级别的想法,但不是相反。结果是,这个模型实现了除了 POS 标记(从第二位开始)之外的所有现有技术的结果。
问答
MetaMind 还为问答的问题提出了一个称为动态协同网络(Dynamic Coattention Network,DCN)的新模型,它建立在一个非常直观的想法上。
想象一下,我要给你一个长文本,并问你一些问题。你是否希望首先阅读文本,然后再问问题;或者在实际开始阅读文本之前给出问题?当然,提前知道什么问题将是一个条件,所以你知道该注意什么。如果没有,你必须同样重视和跟踪每一个细节和依赖关系,以涵盖所有可能的未来问题。
DCN 做同样的事情。首先,它生成文档的内部表示,以其试图回答的问题为条件,然后开始迭代收敛到最终答案的可能答案列表。
机器翻译
九月份, Google 展示了一种称为Google 神经机器翻译(Google Neural Machine Translation,GNMT)的翻译服务所使用的新模型。这种模型是为每对语言(如中文 - 英语)单独训练。
11 月宣布了一个新的GNMT 版本。它更进了一步,训练能够在多对语言之间翻译的单个模型。与先前模型的唯一区别是,现在GNMT 采用指定目标语言的新输入。它也使零翻译( zero-shot translation)得以能用,意味着它能够翻译一对它没有训练过的语言。
GNMT 结果表明,在多对语言上训练它比在单对训练更好,表明它能够将“翻译知识”从一个语言对转移到另一个语言对。
社区
为了讨论机器学习的未来,并确保这些令人印象深刻的技术得到正确使用,有利于社区,一些公司和企业家创造了非盈利性的合作伙伴关系。
OpenAI 是一个非盈利组织,旨在与研究和行业社区合作,并免费向公众发布结果。它创建于 2015 年年底,并于 2016 年开始提供第一个成果(像 InfoGAN 这样的出版物、像 Universe 这样的平台和像这样的会议)。其背后的动机是确保尽可能多的人得到AI 技术,避免出现AI 超级大国。
在另一方面,Amazon、DeepMind、Google、Facebook、IBM 和Microsoft 签署了AI 合作协议。目标旨在提高公众对该领域的理解,提供最佳实践并开发一个开放平台以进行讨论和参与。
另一个值得强调的方面是研究界的开放性。您不仅可以免费找到像 Arxiv (或 Arxiv-Sanity )这样的网站上的任何出版物,也可以使用同样的代码重复他们的实验。一个有用的工具是 GitXiv ,它将 Arxiv 文档与其开源项目存储库相链接。
开源工具无处不在(正如我们在 MLconf SF blogpost 发布的十大工具所强调的)。它们由研究人员和公司使用和创建。以下是 2016 年深度学习最受欢迎的工具列表:
- TensorFlow (Google 出品);
- Keras (François Chollet 出品);
- CNTK (Microsoft 出品);
- MXNET (分布式深度机器学习社区出品,适用于 Amazon);
- Theano (Université de Montréal 出品);
- Torch (Ronan Collobert、Koray Kavukcuoglu、Clement Farabet 出品,广泛应用于 Facebook)。
2016 年的总结
现在是机器学习发展最好的时机。正如你所见,今年特别令人兴奋,研究正在迅速发展,以致很难跟上最新进展的步伐。我们生活在 AI 已经民主化的时代,真的很幸运!
2017 年十大预测
接下来,就是 Carlos E. Perez 对深度学习的 2017 年十大预测,让我们不妨看一看。有兴趣的话,可以在一年之后回顾这篇文章,看看这十大预测有多少准确命中:)
1. 硬件将加速一倍摩尔定律(即 2017 年 2 倍)
如果你跟踪 Nvidia 和 Intel 的发展,这当然是显而易见的。Nvidia 将在整个 2017 年占据主导地位,只因为他们拥有最丰富的深度学习生态系统。没有头脑健全的人会跳到另一个平台,除非味深度学习开发了足够的生态系统。Intel® Xeon Phi™的解决方案胎死腹中,等 Nervana 芯片进入市场后,性能将在 2017 年中期赶上 Nvidia。
Intel 的 FPGA 解决方案可能只是因为经济性而被云提供商采纳。功耗是需要减少的第一个变量。Intel 的 Nervana 芯片可能会在 2017 年年中时达到 30 万亿次浮点运算。这是我的猜测,因为现在 Nvidia 已经达到了 20 万亿次浮点运算。我打赌 2018 年之前,Intel 不会产生重大影响。Intel 可能拥有的唯一的王牌是 3D XPoint 技术。这将有助于改善整个硬件堆栈,但不一定是核心加速器能力,考虑到 GPU 加速器的使用 HBM2 堆叠的芯片性能的原因。
Amazon 已经宣布他们的云实例基于FPGA 。这是基于Xilinx UltraScale + 技术,在单个实例上提供6,800 个DSP 片和64 GB 内存。然而,令人印象深刻的是产品的I/O 绑定不提供HBM 版本的UltraScale。与Nvidia、Intel 甚至AMD 相比,较低的内存带宽解决方案可能会让开发人员暂停投资更复杂的开发过程(即VHDL,Verilog 等)。
最近新闻报道,AMD 公司发布了新的 AMD Instinct line of Deep Learning accelerators 。这些规格与 Nvidia 硬件相比具有极强的竞争力。这次发行计划 2017 年初上市。这可能有充足的时间,使 AMD Rockm 软件成熟。但是,在 AMD 实际提供解决方案之前,不要期望从 Nvidia 进行大规模迁移。
2. 卷积网络 (CNN) 将主导,RNN/LSTM 将会被淘汰。
CNN 将是深度学习系统中流行的基本模型。具有其经常性配置和嵌入式存储器节点的 RNN 和 LSTM 将用得更少、更简单,因为它们将不具备基于 CNN 的解决方案的竞争性。就像 GOTO 在编程世界中消失一样,我估计 RNN/LSTM 的命运也如此。
可微分的内存网络会更加普遍。这只是一个自然结果或架构,其中内存将从核心节点中提取出来,并且只作为与计算机制分离的组件。我认为我们不需要刻意去忘却,输入和输出门的 LSTM,可以取代辅助可微型存储器。我们已经看到有关模块化 LSTM 解耦存储器的对话(参见 Augmented Memory RNN)。
3. 设计师将退出调整,取而代之的是依靠元学习
当我开始深度学习之旅时,我曾经认为优化算法,特别是那些二次优化算法将会带来巨大的改进。今天,显而易见,深度学习为你学习优化算法。这样做的一个主要原因是元学习能够基于其领域自适应地优化其学习。进一步与此相关的是反向传播的替代算法是否将开始出现并实践。
4. 强化学习只会变得更有创造力
对现实的观察总是不完美。有很多问题,SGD 不适用。这就使得任何实际部署的深度学习系统将需要某种形式的强化学习成为至关重要。除此之外,我们将在很多地方看到强化学习在深度学习训练中使用。例如,元学习将大量启用强化学习。
5. 对抗和合作学习将是王道
在过去,我们使用单解析目标函数的单片式深度学习系统。在新的世界,我期望看到具有两个或更多个网络的系统合作或竞争以获得可能不是分析形式的最优解决方案。参见 “ Game Theory reveals the future of Deep Learning ”。2017 年,将有很多尝试管理非平衡态(non-equilibrium)上下文的研究。
6. 预测学习和无监督学习不会取得很大进展
“预测学习”是Yann LeCun 提出的新流行语,取代了更常见的术语“无监督学习”。目前还不清楚这个新的术语是否可以更广泛地采用。问题是,预测学习是否会在2017 年取得长足进步。
如果阅读过“ 5 Capabilities of Deep Learning Intelligence ”,你将会觉得预测学习是一些完全未知的能力。预测学习就像宇宙的暗物质一样,我们知道它是存在的,但不知道如何观察到它。
7. 学习迁移导致工业化
Andrew Ng 认为这点很重要,我也这么认为!
8. 更多应用程序将使用深度学习作为组件
我们在 2016 年已经看到这一点,深度学习在更大的搜索算法中用作函数评估组件。AlphaGo 在其价值和政策评估中采用深度学习。Google 的 Gmail 自动回复系统将深度学习与定向搜索结合使用。我期待看到涌现更多的混合算法,而不是新的端到端训练的深度学习系统。
9. 设计模式将越来越多地被采纳
深度学习只是需要概念结构的复杂领域之一。尽管所有涉及到高等数学,有大量文字叙述和模糊的概念,最好不是由正规严谨的方法来捕获,而是提供一个业已证明在其他复杂的领域(如软件开发)有效的方法。我预测,从业者将最终“获得”关于深度学习和设计模式。
10. 工程将超越理论
研究人员的背景和他们所使用的数学工具,将会滋生他们研究方法中的偏见。深度学习系统和无监督学习系统可能是我们从未遇到的这些新事物。因此,没有证据表明我们的传统分析工具将帮助解开深度学习实际如何工作的谜团。在物理学中有很多动态系统,仍然困惑了几十年,我看到了与动态学习系统相同的情况。
然而,尽管我们缺乏对基本原理的理解,这种情况并不会阻止更高级的应用程序工程。深度学习就像生物技术或基因工程。我们创造了模拟学习机,但我们不知道它们是如何工作的,这并不妨碍任何人进行创新。
感谢杜小芳对本文的审校。
给InfoQ 中文站投稿或者参与内容翻译工作,请邮件至 editors@cn.infoq.com 。也欢迎大家通过新浪微博( @InfoQ , @丁晓昀),微信(微信号: InfoQChina )关注我们。




