TensorFlow 发展及使用简介
2015 年 11 月 9 日谷歌开源了人工智能系统 TensorFlow,同时成为 2015 年最受关注的开源项目之一。TensorFlow 的开源大大降低了深度学习在各个行业中的应用难度。TensorFlow 的近期里程碑事件主要有:
2016 年 11 月 09 日:TensorFlow 开源一周年。
2016 年 09 月 27 日:TensorFlow 支持机器翻译模型。
2016 年 08 月 30 日:TensorFlow 支持使用 TF-Slim 接口定义复杂模型。
2016 年 08 月 24 日:TensorFlow 支持自动学习生成文章摘要模型。
2016 年 06 月 29 日:TensorFlow 支持 Wide & Deep Learning。
2016 年 06 月 27 日:TensorFlow v0.9 发布,改进了移动设备的支持。
2016 年 05 月 12 日:发布 SyntaxNet,最精确的自然语言处理模型。
2016 年 04 月 29 日:DeepMind 模型迁移到 TensorFlow。
2016 年 04 月 14 日:发布了分布式 TensorFlow。
TensorFlow 是一种基于图计算的开源软件库,图中节点表示数学运算,图中的边表示多维数组(Tensor)。TensorFlow 是跨平台的深度学习框架,支持 CPU 和 GPU 的运算,支持台式机、服务器、移动平台的计算,并从 r0.12 版本开始支持 Windows 平台。Tensorflow 提供了各种安装方式,包括 Pip 安装,Virtualenv 安装,Anaconda 安装,docker 安装,源代码安装。 本文主要介绍 Pip 的安装方式,Pip 是一个 Python 的包安装及管理工具。Linux 系统下,使用 Pip 的安装流程如下:
yum install python-pip python-dev
export TF_BINARY_URL=https://storage.googleapis.com/tensorflow/linux/cpu/tensorflow-0.12.0rc0-cp27-none-linux_x86_64.whl
pip install --upgrade $TF_BINARY_URL
安装完毕后,TensorFlow 会安装到 /usr/lib/python2.7/site-packages/tensorflow 目录下。使用 TensorFlow 之前,我们需要先熟悉下常用 API。
tf.random_uniform([1], -1.0, 1.0):构建一个 tensor, 该 tensor 的 shape 为 [1],该值符合 [-1, 1) 的均匀分布。其中 [1] 表示一维数组,里面包含 1 个元素。
tf.Variable(initial_value=None):构建一个新变量,该变量会加入到 TensorFlow 框架中的图集合中。
tf.zeros([1]):构建一个 tensor, 该 tensor 的 shape 为 [1], 里面所有元素为 0。
tf.square(x, name=None):计算 tensor 的平方值。
tf.reduce_mean(input_tensor):计算 input_tensor 中所有元素的均值。
tf.train.GradientDescentOptimizer(0.5):构建一个梯度下降优化器,0.5 为学习速率。学习率决定我们迈向(局部)最小值时每一步的步长,设置的太小,那么下降速度会很慢,设的太大可能出现直接越过最小值的现象。所以一般调到目标函数的值在减小而且速度适中的情况。
optimizer.minimize(loss):构建一个优化算子操作。使用梯度下降法计算损失方程的最小值。loss 为需要被优化的损失方程。
tf.initialize_all_variables():初始化所有 TensorFlow 的变量。
tf.Session():创建一个 TensorFlow 的 session,在该 session 种会运行 TensorFlow 的图计算模型。
sess.run():在 session 中执行图模型的运算操作。如果参数为 tensor 时,可以用来求 tensor 的值。
下面为使用 TensorFlow 中的梯度下降法构建线性学习模型的使用示例:
#导入 TensorFlow python API 库
import tensorflow as tf
import numpy as np
#随机生成 100 点(x,y)
x_data = np.random.rand(100).astype(np.float32)
y_data = x_data * 0.1 + 0.3
#构建线性模型的 tensor 变量 W, b
W = tf.Variable(tf.random_uniform([1], -1.0, 1.0))
b = tf.Variable(tf.zeros([1]))
y = W * x_data + b
#构建损失方程,优化器及训练模型操作 train
loss = tf.reduce_mean(tf.square(y - y_data))
optimizer = tf.train.GradientDescentOptimizer(0.5)
train = optimizer.minimize(loss)
#构建变量初始化操作 init
init = tf.initialize_all_variables()
#构建 TensorFlow session
sess = tf.Session()
#初始化所有 TensorFlow 变量
sess.run(init)
#训练该线性模型,每隔 20 次迭代,输出模型参数
for step in range(201):
sess.run(train)
if step % 20 == 0:
print(step, sess.run(W), sess.run(b))
分布式 TensorFlow 应用架构
2016 年 4 月 14 日,Google 发布了分布式 TensorFlow,能够支持在几百台机器上并行训练。分布式的 TensorFlow 由高性能的 gRPC 库作为底层技术支持。TensorFlow 集群由一系列的任务组成,这些任务执行 TensorFlow 的图计算。每个任务会关联到 TensorFlow 的一个服务,该服务用于创建 TensorFlow 会话及执行图计算。TensorFlow 集群也可以划分为一个或多个作业,每个作业可以包含一个或多个任务。在一个 TensorFlow 集群中,通常一个任务运行在一个机器上。如果该机器支持多 GPU 设备,可以在该机器上运行多个任务,由应用程序控制任务在哪个 GPU 设备上运行。
常用的深度学习训练模型为数据并行化,即 TensorFlow 任务采用相同的训练模型在不同的小批量数据集上进行训练,然后在参数服务器上更新模型的共享参数。TensorFlow 支持同步训练和异步训练两种模型训练方式。
异步训练即 TensorFlow 上每个节点上的任务为独立训练方式,不需要执行协调操作,如下图所示:
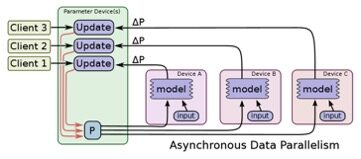
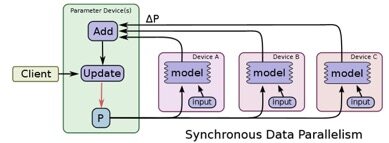
同步训练为 TensorFlow 上每个节点上的任务需要读入共享参数,执行并行化的梯度计算,然后将所有共享参数进行合并,如下图所示:
分布式 TensorFlow 应用开发 API 主要包括:
tf.train.ClusterSpec({“ps”: ps_hosts, “worker”: worker_hosts}): 创建 TensorFlow 集群描述信息,其中 ps,worker 为作业名称,ps_hosts,worker_hosts 为该作业的任务所在节点的地址信息。示例如下:
cluster = tf.train.ClusterSpec({"worker": ["worker0.example.com:2222", "worker1.example.com:2222", "worker2.example.com:2222"], "ps": ["ps0.example.com:2222", "ps1.example.com:2222"]})tf.train.Server(cluster, job_name, task_index):创建一个 TensorFlow 服务,用于运行相应作业上的计算任务,运行的任务在 task_index 指定的机器上启动。
tf.device(device_name_or_function):设定在指定的设备上执行 Tensor 运算,示例如下:
#指定在 task0 所在的机器上执行 Tensor 的操作运算
with tf.device("/job:ps/task:0"):
weights_1 = tf.Variable(...)
biases_1 = tf.Variable(...)
分布式 TensorFlow MNIST 模型训练
MNIST 是一个手写数字的图片数据库,可从网站 http://yann.lecun.com/exdb/mnist/ 下载相关数据,其中的每一张图片为 0 到 9 之间的手写数字灰度图片,大小为 28*28 像素,如下图所示:
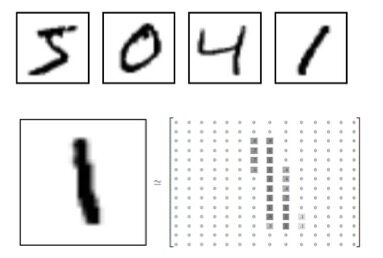
MNIST 数据集主要包含训练样本 60000 个,测试样本 10000 个。图像数据主要为图片的像素数据,图像数据标签主要表示该图片的类别。由以下四个文件组成:
train-images-idx3-ubyte.gz (训练图像数据 60000 个)
train-labels-idx1-ubyte.gz (训练图像数据标签 60000 个)
t10k-images-idx3-ubyte.gz (测试图像数据 10000 个)
t10k-labels-idx1-ubyte.gz (测试图像数据标签 10000 个)
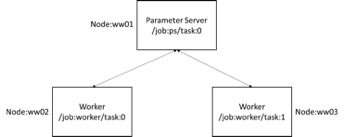
本文采用如下的结构对 MNIST 数据集进行分布式训练,由三个节点组成。ww01 节点为 Parameter Server,ww02 节点为 Worker0,ww03 节点为 Worker1。其中 Parameter Server 执行参数更新任务,Worker0,Worker1 执行图模型训练计算任务,如下图所示。分布式 MNIST 训练模型在执行十万次迭代后,收敛精度达到 97.77%。
在 ww01 节点执行如下命令,启动参数服务 /job:ps/task:0:
python asyncmnist.py --ps_hosts=ww01:2222 --worker_hosts=ww02:2222,ww03:2222 --job_name=ps --task_index=0
在 ww02 节点执行如下命令,启动模型运算 /job:worker/task:0:
python asyncmnist.py --ps_hosts=ww01:2222 --worker_hosts=ww02:2222,ww03:2222 --job_name=worker --task_index=0
在 ww03 节点执行如下命令,启动模型运算 /job:worker/task:1:
python asyncmnist.py --ps_hosts=ww01:2222 --worker_hosts=ww02:2222,ww03:2222 --job_name=worker --task_index=1
分布式 MNIST 的训练模型如下:
import math
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
# TensorFlow 集群描述信息,ps_hosts 表示参数服务节点信息,worker_hosts 表示 worker 节点信息
tf.app.flags.DEFINE_string("ps_hosts", "", "Comma-separated list of hostname:port pairs")
tf.app.flags.DEFINE_string("worker_hosts", "", "Comma-separated list of hostname:port pairs")
# TensorFlow Server 模型描述信息,包括作业名称,任务编号,隐含层神经元数量,MNIST 数据目录以及每次训练数据大小(默认一个批次为 100 个图片)
tf.app.flags.DEFINE_string("job_name", "", "One of 'ps', 'worker'")
tf.app.flags.DEFINE_integer("task_index", 0, "Index of task within the job")
tf.app.flags.DEFINE_integer("hidden_units", 100, "Number of units in the hidden layer of the NN")
tf.app.flags.DEFINE_string("data_dir", "MNIST_data", "Directory for storing mnist data")
tf.app.flags.DEFINE_integer("batch_size", 100, "Training batch size")
FLAGS = tf.app.flags.FLAGS
#图片像素大小为 28*28 像素
IMAGE_PIXELS = 28
def main(_):
#从命令行参数中读取 TensorFlow 集群描述信息
ps_hosts = FLAGS.ps_hosts.split(",")
worker_hosts = FLAGS.worker_hosts.split(",")
# 创建 TensorFlow 集群描述对象
cluster = tf.train.ClusterSpec({"ps": ps_hosts, "worker": worker_hosts})
# 为本地执行 Task,创建 TensorFlow 本地 Server 对象.
server = tf.train.Server(cluster, job_name=FLAGS.job_name, task_index=FLAGS.task_index)
#如果是参数服务,直接启动即可
if FLAGS.job_name == "ps":
server.join()
elif FLAGS.job_name == "worker":
#分配操作到指定的 worker 上执行,默认为该节点上的 cpu0
with tf.device(tf.train.replica_device_setter(worker_device="/job:worker/task:%d" % FLAGS.task_index, cluster=cluster)):
# 定义 TensorFlow 隐含层参数变量,为全连接神经网络隐含层
hid_w = tf.Variable(tf.truncated_normal([IMAGE_PIXELS * IMAGE_PIXELS, FLAGS.hidden_units], stddev=1.0 / IMAGE_PIXELS), name="hid_w")
hid_b = tf.Variable(tf.zeros([FLAGS.hidden_units]), name="hid_b")
# 定义 TensorFlow softmax 回归层的参数变量
sm_w = tf.Variable(tf.truncated_normal([FLAGS.hidden_units, 10], tddev=1.0 / math.sqrt(FLAGS.hidden_units)), name="sm_w")
sm_b = tf.Variable(tf.zeros([10]), name="sm_b")
#定义模型输入数据变量(x 为图片像素数据,y_ 为手写数字分类)
x = tf.placeholder(tf.float32, [None, IMAGE_PIXELS * IMAGE_PIXELS])
y_ = tf.placeholder(tf.float32, [None, 10])
#定义隐含层及神经元计算模型
hid_lin = tf.nn.xw_plus_b(x, hid_w, hid_b)
hid = tf.nn.relu(hid_lin)
#定义 softmax 回归模型,及损失方程
y = tf.nn.softmax(tf.nn.xw_plus_b(hid, sm_w, sm_b))
loss = -tf.reduce_sum(y_ * tf.log(tf.clip_by_value(y, 1e-10, 1.0)))
#定义全局步长,默认值为 0
global_step = tf.Variable(0)
#定义训练模型,采用 Adagrad 梯度下降法
train_op = tf.train.AdagradOptimizer(0.01).minimize(loss, global_step=global_step)
#定义模型精确度验证模型,统计模型精确度
correct_prediction = tf.equal(tf.argmax(y,1), tf.argmax(y_,1))
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
#对模型定期做 checkpoint,通常用于模型回复
saver = tf.train.Saver()
#定义收集模型统计信息的操作
summary_op = tf.merge_all_summaries()
#定义操作初始化所有模型变量
init_op = tf.initialize_all_variables()
#创建一个监管程序,用于构建模型检查点以及计算模型统计信息。
sv = tf.train.Supervisor(is_chief=(FLAGS.task_index == 0), logdir="/tmp/train_logs", init_op=init_op, summary_op=summary_op, saver=saver, global_step=global_step, save_model_secs=600)
#读入 MNIST 训练数据集
mnist = input_data.read_data_sets(FLAGS.data_dir, one_hot=True)
#创建 TensorFlow session 对象,用于执行 TensorFlow 图计算
with sv.managed_session(server.target) as sess:
step = 0
while not sv.should_stop() and step < 1000:
# 读入 MNIST 的训练数据,默认每批次为 100 个图片
batch_xs, batch_ys = mnist.train.next_batch(FLAGS.batch_size)
train_feed = {x: batch_xs, y_: batch_ys}
#执行分布式 TensorFlow 模型训练
_, step = sess.run([train_op, global_step], feed_dict=train_feed)
#每隔 100 步长,验证模型精度
if step % 100 == 0:
print "Done step %d" % step
print(sess.run(accuracy, feed_dict={x: mnist.test.images, y_: mnist.test.labels}))
# 停止 TensorFlow Session
sv.stop()
if __name__ == "__main__":
tf.app.run()
梯度下降法在分布式 TensorFlow 中的性能比较分析
2016 年谷歌在 ICLR(the International Conference on Learning Representations) Workshop 上发表了论文 REVISITING DISTRIBUTED SYNCHRONOUS SGD。基于 ImageNet 数据集,该论文对异步随机梯度下降法(Async-SGD)和同步随机梯度下降法(Sync-SGD)进行了比较分析。
Dean 在 2012 年提出了分布式随机梯度下降法,模型参数可以分布式地存储在不同的服务器上,称之为参数服务器(Parameter Server,PS),以及 Worker 节点可以并发地处理训练数据并且能够和参数服务通信获取模型参数。异步随机梯度下降法(Async-SGD),主要由以下几个步骤组成:
- 针对当前批次的训练数据,从参数服务器获取模型的最新参数。
- 基于上述获取到的模型参数,计算损失方程的梯度。
- 将上述计算得到的梯度发送回参数服务器,并相应地更新模型参数。
同步随机梯度下降法(Sync-SGD)与 Sync-SGD 的主要差异在于参数服务器将等待所有 Worker 发送相应的梯度值,并聚合这些梯度值,最后把更新后的梯度值发送回节点。
Async-SGD 的主要问题是每个 Worker 节点计算的梯度值发送回参数服务器会有参数更新冲突,一定程度影响算法的收敛速度。Sync-SGD 算法能够保证在数据集上执行的是真正的随机梯度下降法,消除掉了参数的更新冲突。但同步随机梯度下降法同时带来的问题是训练数据的批量数据会比较大,参数服务器上参数的更新时间依赖于最慢的 worker 节点。
为了解决有些 worker 节点比较慢的问题,我们可以使用多一点的 Worker 节点,这样 Worker 节点数变为 N+N*5%,N 为集群 Worker 节点数。Sync-SGD 可以设定为在接受到 N 个 Worker 节点的参数后,可以直接更新参数服务器上的模型参数,进入下一个批次的模型训练。慢节点上训练出来的参数是会被丢弃掉。我们称这种方法为 Sync-SGD with backups。
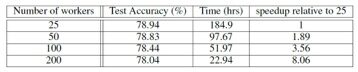
2015 年,Abadi 使用 TensorFlow 的 Async-SGD, Sync-SGD,Sync-SGD with backups 训练模型对 ImageNet 的 Benchmark 问题进行了实验分析。要对该训练数据进行 1000 种图片的分类训练,实验环境为 50 到 200 个的 worker 节点,每个 worker 节点上运行 k40 GPU。使用分布式 TensorFlow 后大大缩短了模型训练时间,Async-SGD 算法实验结果如下,其中 200 个节点的训练时间比采用 25 个节点的运算时间缩短了 8 倍,如下图所示。
下图为 50 个 Worker 节点的 Async-SGD, Sync-SGD,Sync-SGD with backups 模型训练结果的比较。
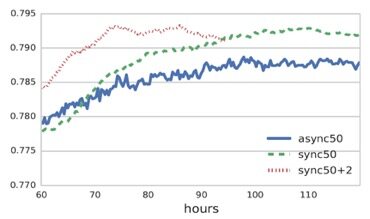
从结果中可以看出增加 2 个 backup 节点,Sync-SGD with backups 模型可以快速提升模型训练速度。同时 Sync-SGD 模型比 Async-SGD 模型大概提升了 25% 的训练速度,以及 0.48% 的精确度。随着数据集的增加,分布式训练的架构变得越来越重要。而分布式 TensorFlow 正是解决该问题的利器,有效地提升了大规模模型训练的效率,提供了企业级的深度学习解决方案。
作者简介
武维(微信:allawnweiwu):西安交通大学博士,现为 IBM Spectrum Computing 研发工程师。主要从事大数据,深度学习,云计算等领域的研发工作。




